1.本发明涉及互联网技术领域,具体而言,涉及一种基于相似矩阵的音乐自动剪辑实现方法、装置及存储介质。
背景技术:
2.目前,除开普通用户对于音乐的需求以外,现兴起的短时频、直播行业同样对音乐有着很大的需求。因此,对于音乐售卖方,能够提供一个片段让用户进行试听选择的功能至关重要。但是,音乐行业还是一个偏传统的行业,音乐编辑仍然需要人工使用编辑软件对每一首歌试听后截取高潮片段;这不但增加了人工成本,而且效率也不高。所以需要提供一种方案以便于在提高音乐剪辑的效率和准确性的同时降低剪辑成本。
技术实现要素:
3.本发明的目的在于提供一种基于相似矩阵的音乐自动剪辑实现方法、装置及存储介质,用以实现在提高音乐剪辑的效率和准确性的同时降低剪辑成本的技术效果。
4.第一方面,本发明提供了一种基于相似矩阵的音乐自动剪辑实现方法,包括:
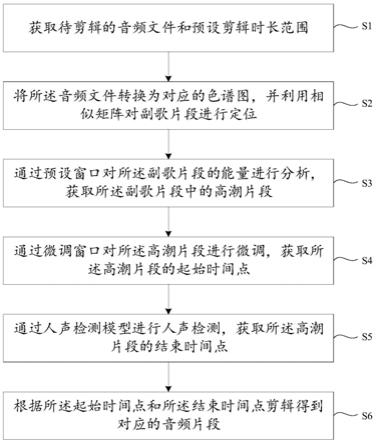
5.s1.获取待剪辑的音频文件和预设剪辑时长范围;
6.s2.将所述音频文件转换为对应的色谱图,并利用相似矩阵对副歌片段进行定位;
7.s3.通过预设窗口对所述副歌片段的能量进行分析,获取所述副歌片段中的高潮片段;
8.s4.通过微调窗口对所述高潮片段进行微调,获取所述高潮片段的起始时间点;
9.s5.通过人声检测模型进行人声检测,获取所述高潮片段的结束时间点;
10.s6.根据所述起始时间点和所述结束时间点剪辑得到对应的音频片段。
11.进一步地,所述s2包括:
12.以一帧为单位构建所述音频文件的色谱图;
13.根据所述色谱图分析各帧歌曲的相似度;
14.将所述相似度按照时间维度构建相似矩阵;
15.根据所述相似矩阵分析最优副歌片段。
16.进一步地,将所述相似度按照时间维度构建相似矩阵的步骤包括:
17.根据公式(1)计算两帧歌曲的相似度;根据公式(2)构建相似矩阵:
[0018][0019]
m[x][y]=similarity(x,y)
ꢀꢀ
(2)
[0020]
式中,x和y表示不同的两帧歌曲对应的音符向量;similarity表示相似度;m表示相似度矩阵。
[0021]
进一步地,根据所述相似矩阵分析最优副歌片段的步骤包括:
[0022]
根据所述相似度矩阵构建延时矩阵,将所述相似度矩阵中倾斜的对角线通过线性
变换转换为平铺的直线;
[0023]
根据设置的阈值对所述延时矩阵进行降噪平滑处理;
[0024]
将降噪平滑处理后的延时矩阵中的线条按照时间点进行统计;
[0025]
定义每一条直线的权重,根据各个时间点重叠的线条数进行加权求和,计算该直线的总权重;
[0026]
将总权重最大的直线对应的歌曲片段作为最优副歌片段。
[0027]
进一步地,根据所述相似度矩阵构建延时矩阵,将所述相似度矩阵中倾斜的对角线通过线性变换转换为平铺的直线的步骤通过公式(3)进行线性变换:
[0028]
t[x][y]=m[x][x
‑
y]=similarity(x,x
‑
y)
ꢀꢀ
(3)
[0029]
式中,t表示延时矩阵;m表示相似度矩阵;x和y表示不同的两帧歌曲对应的音符向量;similarity表示相似度。
[0030]
进一步地,所述s3包括:
[0031]
根据获取音频文件时的文件采样率和最小切片时长设置预设窗口;
[0032]
根据所述预设窗口将所述副歌片段划分为多个片段;
[0033]
计算各个所述片段中的平均能量值,并将平均能量值最高的片段作为高潮片段。
[0034]
进一步地,所述s4包括:
[0035]
获取高潮片段的起点作为初步起始时间点;
[0036]
根据设置的检测片段时间长度和所述文件采样率设置微调窗口;
[0037]
根据预设的滑动检测区域和所述初步起始时间点构建目标检测区域;
[0038]
根据所述微调窗口将所述目标检测区域划分为多个检测片段;
[0039]
计算各个所述检测片段中的平均能量值,并将平均能量值最小的检测片段对应的起点作为所述高潮片段的最终起始时间点。
[0040]
进一步地,所述s5包括:
[0041]
采用五个卷积层块和一个全连接层构建神经网络模型;
[0042]
利用含有人声和不含人声的环境音、噪音和纯音乐音频样本对所述神经网络模型进行训练得到对应的人声检测模型;
[0043]
根据所述起始时间点和所述剪辑时长范围的最小值计算剪辑结束的预估位置;
[0044]
从所述预估位置开始按照预设时间间隔获取所述音频文件中的数字信号对应的mel频谱图;
[0045]
利用所述人声检测模型对所述预估位置对应的mel频谱图进行分析,确认是否含有人声;若含有人声,则逐帧向后进行检测,直到连续多帧未检测到人声时以当前的时间点作为结束时间点。
[0046]
第二方面,本发明提供一种基于相似矩阵的音乐自动剪辑实现系统,包括:获取模块,用于获取待剪辑的音频文件和预设剪辑时长范围;
[0047]
副歌片段定位模块,用于将所述音频文件转换为对应的色谱图,并利用相似矩阵对副歌片段进行定位;
[0048]
高潮片段定位模块,用于通过预设窗口对所述副歌片段的能量进行分析,获取所述副歌片段中的高潮片段;
[0049]
起始时间点分析模块,用于通过微调窗口对所述高潮片段进行微调,获取所述高
潮片段的起始时间点;
[0050]
结束时间点分析模块,用于通过人声检测模型进行人声检测,获取所述高潮片段的结束时间点;
[0051]
剪辑模块,用于根据所述起始时间点和所述结束时间点进行剪辑得到对应的音频片段。
[0052]
第三方面,本发明提供一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被执行时实现上述方法的步骤。
[0053]
本发明能够实现的有益效果是:本发明首先通过相似度矩阵对副歌片段进行定位;其次,通过设置的窗口对高潮片段的起始时间点进行更为准确的微调;然后,实用人声检测模型对高潮片段的结束时间点进行分析;最后根据分析到的起始时间点和结束时间点自动剪辑得到对应的音频片段;在提高音乐剪辑的效率和准确性的同时降低剪辑成本。
附图说明
[0054]
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
[0055]
图1为本发明实施例提供的一种基于相似矩阵的音乐自动剪辑实现方法流程示意图;
[0056]
图2为本发明实施例提供的一种相似矩阵示意图;
[0057]
图3为本发明实施例提供的一种降噪后的延时矩阵示意图;
[0058]
图4为本发明实施例提供的一种基于相似矩阵的音乐自动剪辑实现系统拓扑结构示意图。
[0059]
图标:10
‑
音乐自动剪辑实现系统;100
‑
获取模块;200
‑
副歌片段定位模块;300
‑
高潮片段定位模块;400
‑
起始时间点分析模块;500
‑
结束时间点分析模块;600
‑
剪辑模块。
具体实施方式
[0060]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行描述。
[0061]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本发明的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
[0062]
请参看图1、图2和图3,图1为本发明实施例提供的一种基于相似矩阵的音乐自动剪辑实现方法流程示意图;图2为本发明实施例提供的一种相似矩阵示意图;图3为本发明实施例提供的一种降噪后的延时矩阵示意图。
[0063]
在一种实施方式中,为了在提高音乐剪辑的效率和准确性的同时降低成本,本发明实施例提供了一种基于相似矩阵的音乐自动剪辑实现方法,其具体内容如下所述。
[0064]
s1.获取待剪辑的音频文件和预设剪辑时长范围。
[0065]
在一种实施方式中,可以通过预设的程序接口获取待剪辑的音频文件和预设剪辑时长范围等参数。其中,预设剪辑时长范围可以设置为,但不限于,30到60秒之间。
[0066]
s2.将所述音频文件转换为对应的色谱图,并利用相似矩阵对副歌片段进行定位。
[0067]
在一种实施方式中,音频文件获取完毕后可以存储在对应的内存中,并将数字信号处理为色谱图。色谱图中横轴代表时间帧,纵轴代表音高,数字大小代表振幅。
[0068]
示例性地,可以先以0.2秒的音频文件为一帧构建该音频文件的色谱图;其次,根据所该色谱图分析各帧歌曲的相似度;然后,将相似度按照时间维度构建相似矩阵;最后,根据相似矩阵分析最优副歌片段。
[0069]
具体地,可以根据公式(1)计算两帧歌曲的相似度;根据公式(2)构建相似矩阵:
[0070][0071]
m[x][y]=similarity(x,y)
ꢀꢀ
(2)
[0072]
式中,x和y表示不同的两帧歌曲对应的音符向量;similarity表示相似度;m表示相似度矩阵。在相似度矩阵m中对角线对称相等,且对角线的值都是1,因为每一帧与自己的相似度都是是一样的。
[0073]
在根据相似矩阵分析最优副歌片段时,可以先根据相似度矩阵构建延时矩阵,将相似度矩阵中倾斜的对角线通过线性变换转换为平铺的直线;其次,根据设置的阈值对延时矩阵进行降噪平滑处理;再次,将降噪平滑处理后的延时矩阵中的线条按照时间点进行统计;然后,定义每一条直线的权重,根据各个时间点重叠的线条数进行加权求和,计算该直线的总权重;最后,将总权重最大的直线对应的歌曲片段作为最优副歌片段。通过上述方式,可以获取到更加合适的副歌片段。
[0074]
具体地,根据相似度矩阵构建延时矩阵,将相似度矩阵中倾斜的对角线通过线性变换转换为平铺的直线的步骤通过公式(3)进行线性变换:
[0075]
t[x][y]=m[x][x
‑
y]=similarity(x,x
‑
y)
ꢀꢀ
(3)
[0076]
式中,t表示延时矩阵;m表示相似度矩阵;x和y表示不同的两帧歌曲对应的音符向量;similarity表示相似度。
[0077]
进一步地,对于一条从a点开始到b点结束的直线,若每个时间点含有的重叠线条数为n∈[j,k],且每一条直线的权重为则该直线的总权重可以按照公式(4)进行计算:
[0078][0079]
s3.通过预设窗口对所述副歌片段的能量进行分析,获取所述副歌片段中的高潮片段。
[0080]
在一种实施方式中,在获取高潮片段时可以先根据获取音频文件时的文件采样率f
s
和最小切片时长t设置预设窗口。
[0081]
具体地,对于原始数字信号s,可以按照公式(5)进行划分:
[0082]
w
s
=t
×
α
×
f
s
ꢀꢀ
(5)
[0083]
其中,α是一个大于1的常量,这里可以设置为1.5,也就是说窗口大小应该大于剪辑限制因为后续还需要对起始位置进行微调。
[0084]
然后,根据预设窗口将副歌片段划分为多个片段;
[0085]
最后,计算各个片段中的平均能量值,并将平均能量值最高的片段作为高潮片段。
[0086]
具体地,可以按照公式(6)计算每一个窗口中的平均能量值:
[0087][0088]
其中,
[0089]
s4.通过微调窗口对所述高潮片段进行微调,获取所述高潮片段的起始时间点。
[0090]
在一种实施方式中,当获取到高潮片段后,就可以先获取高潮片段的起点作为初步起始时间点;其次,根据设置的检测片段时间长度和文件采样率设置微调窗口;再次,根据预设的滑动检测区域和初步起始时间点构建目标检测区域;然后,根据微调窗口将目标检测区域划分为多个检测片段;最后,计算各个检测片段中的平均能量值,并将平均能量值最小的检测片段对应的起点作为高潮片段的最终起始时间点。
[0091]
具体地,微调窗口可以按照公式(7)进行设置:
[0092]
w
q
=β
×
f
s
ꢀꢀ
(7)
[0093]
式中,β表示检测片段时间长度,f
s
为文件采样率。
[0094]
s5.通过人声检测模型进行人声检测,获取所述高潮片段的结束时间点。
[0095]
在一种实施方式中,可以先采用五个卷积层块(每个卷积层块均含有卷积层、池化层和dropout层)和一个全连接层构建神经网络模型;其次,利用含有人声和不含人声的环境音、噪音和纯音乐音频样本对神经网络模型进行训练得到对应的人声检测模型;再次,根据起始时间点和剪辑时长范围的最小值计算剪辑结束的预估位置;然后,从预估位置开始按照预设时间间隔获取音频文件中的数字信号对应的mel频谱图;最后,利用人声检测模型对预估位置对应的mel频谱图进行分析,确认是否含有人声;若含有人声,则逐帧向后进行检测,直到连续多帧未检测到人声时以当前的时间点作为结束时间点。
[0096]
通过上述方式,可以防止将一句完整的歌词截断,使剪辑的音频片段更加完整。
[0097]
s6.根据所述起始时间点和所述结束时间点剪辑得到对应的音频片段。
[0098]
请参看图4,图4为本发明实施例提供的一种基于相似矩阵的音乐自动剪辑实现系统拓扑结构示意图。
[0099]
在一种实施方式中,本发明实施例还提供了一种基于相似矩阵的音乐自动剪辑实现系统10。该音乐自动剪辑实现系统10包括:
[0100]
获取模块100,用于获取待剪辑的音频文件和预设剪辑时长范围;
[0101]
副歌片段定位模块200,用于将音频文件转换为对应的色谱图,并利用相似矩阵对副歌片段进行定位;
[0102]
高潮片段定位模块300,用于通过预设窗口对副歌片段的能量进行分析,获取副歌片段中的高潮片段;
[0103]
起始时间点分析模块400,用于通过微调窗口对高潮片段进行微调,获取高潮片段的起始时间点;
[0104]
结束时间点分析模块500,用于通过人声检测模型进行人声检测,获取高潮片段的结束时间点;
[0105]
剪辑模块600,用于根据起始时间点和结束时间点进行剪辑得到对应的音频片段。
[0106]
在一种实施方式中,本发明实施例还提供一种存储介质,该存储介质存储有计算机程序,计算机程序被执行时实现方法的步骤。
[0107]
综上所述,本发明实施例提供一种基于相似矩阵的音乐自动剪辑实现方法、装置及存储介质,包括s1.获取待剪辑的音频文件和预设剪辑时长范围;s2.将所述音频文件转换为对应的色谱图,并利用相似矩阵对副歌片段进行定位;s3.通过预设窗口对所述副歌片段的能量进行分析,获取所述副歌片段中的高潮片段;s4.通过微调窗口对所述高潮片段进行微调,获取所述高潮片段的起始时间点;s5.通过人声检测模型进行人声检测,获取所述高潮片段的结束时间点;s6.根据所述起始时间点和所述结束时间点剪辑得到对应的音频片段。通过上述方式,提高了音频剪辑的效率和准确性,降低了剪辑成本。
[0108]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

