1.本发明属于语音识别和自然语言处理技术领域,具体涉及一种基于元音和谐的土耳其语的语音识别方法及系统。
背景技术:
2.语言模型(language model,lm)是描述词序列概率分布的数学模型,其在自然语言处理相关的应用中发挥着重要的作用。随着深度学习技术的发展,基于深度神经网络(deep neural network,dnn)的语言模型建模技术在语音识别、机器翻译、文本生成等一系列任务中展现出巨大的潜力。
3.benjio等人首先将dnn用于语言模型建模任务中。随后mikolov等人将递归神经网络(recurrent neural network,rnn)用于语言模型建模。相比于dnn模型,rnn模型中的递归结构可以有效地对历史信息进行压缩,从而有利于模型学习长时历史信息。
4.土耳其语是一种典型的黏着语,其特征是在词根的前后粘贴不同的词缀来体现不同的语法功能。一般来说,同一个词根在不同的需求下,可以灵活的产生相当数量的单词。因此,相同规模语料下,通常这类语言统计得到的词表会非常庞大;并且,这类语言的词表通常会随语料增大持续增加。因此,通常需要使用子词作为建模单元。
5.元音和谐是土耳其语以及其他所有突厥语都遵循的语音规则。土耳其语的元音和谐包括前后元音和谐以及圆唇非圆唇元音和谐。元音分类及元音和谐规则如表1所示:
6.表1土耳其语元音和谐示意表
[0007][0008][0009]
所谓和谐就是指一个词内或者与词相关的词缀内含有同一类型的元音。具体来说,前后元音和谐(大和谐)指前元音后跟前元音,后元音后跟后元音。圆唇元音、非圆唇元音和谐(小和谐)指非圆唇元音后跟非圆唇元音,圆唇元音后跟窄的圆唇元音或宽的非圆唇元音。
[0010]
因此,现有的针对土耳其语的语言方法中,存在当前子词的字母出现的情况会在很大程度上影响下一个词缀的选择的问题。以增加一个表示字母出现情况的特征,用来帮助语言模型预测下一个子词。
技术实现要素:
[0011]
本发明的目的在于,为解决现有的识别方法存在上述缺陷,本发明提出了一种基于元音和谐的土耳其语的语音识别方法,该方法包括:
[0012]
将待识别语音进行识别,得到多个候选语句,再将每个候选语句拆分成多个子词;
[0013]
将每个子词依次输入土耳其语子词级别神经网络语言模型,获得下一个子词的预测概率的对数值;
[0014]
根据该候选语句中所有子词的预测概率的对数值,获得该候选语句的概率的对数值;
[0015]
按照从大到小的顺序对各个候选语句的概率的对数值进行排序,将最大概率的对数值对应的候选语句作为语音识别结果。
[0016]
作为上述技术方案的改进之一,所述土耳其语子词级别神经网络语言模型的处理过程,具体包括:
[0017]
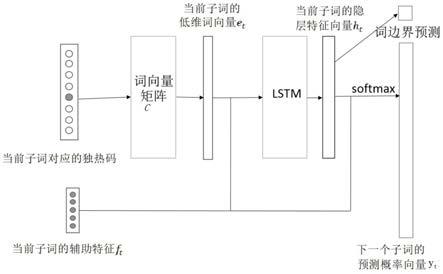
将当前子词对应的独热码输入至词向量矩阵,输出当前子词的低维词向量;
[0018]
截取到当前子词为止的最后一个元音和辅音,并抽取其对应的独热码作为当前子词的辅助特征;
[0019]
将当前子词的低维词向量与当前子词的辅助特征串联,并将其输入至长短时记忆神经网络单元的隐层,输出当前子词的隐层特征向量;
[0020]
将当前子词的隐层特征向量与当前子词的辅助特征串联,获得串联后的特征向量,并将其输入至长短时记忆神经网络单元的softmax层,依据softmax函数:
[0021]
y
t
=softmax(w
e
[h
t
;f
t
] b
e
)
[0022]
其中,y
t
为下一个子词的预测概率向量;w
e
为仿射矩阵,b
e
为偏置;h
t
为当前子词的隐层特征向量;f
t
为当前子词的辅助特征;其中,辅助特征f
t
表示为到当前子词为止的最后一个元音和辅音,其包含最后一个元音和辅音的独热码;具体来说,土耳其语字母表中包含8个元音21个辅音;因此,最后一个元音和辅音的独热码两部分的维度分别为8和21;最终的辅助特征为最后一个元音和辅音的独热码两部分的串联,即特征长度d=29;
[0023]
输出下一个子词的预测概率向量y
t
。
[0024]
作为上述技术方案的改进之一,所述方法还包括:土耳其语子词级别神经网络语言模型的训练步骤,具体包括:
[0025]
建立训练集,将训练集中的每个单词拆分成多个子词;
[0026]
对于当前子词w
t
,其输入为该当前子词的独热码;其中,v表示词汇表的大小;
[0027]
当前子词w
t
经过在词向量矩阵c的查表操作后,得到该当前子词w
t
的低维词向量e
t
;其中,c∈r
v
×
m
,e
t
∈r
m
中,v为词汇表的大小;m为子词级别神经网络语言模型的lstm单元的隐层单元个数;
[0028]
截取到当前子词为止的最后一个元音和辅音,并抽取其对应的独热码作为当前子词的辅助特征f
t
;
[0029]
将通过词向量矩阵c得到的低维词向量e
t
与辅助特征f
t
串联,送入长短时记忆神经网络单元中,得到的输出为当前子词的隐层特征向量h
t
;其中,h
t
∈r
m
;
[0030]
将当前子词的隐层特征向量h
t
通过一层只有一个节点线性层和sigmoid层得到结果z
t
;其中,该结果z
t
为该子词级别神经网络语言模型的词边界预测分支的结果;
[0031]
词边界预测标签g
t
∈{0,1}为下一子词是否为单词第一个子词;其中,1表示下一次是单词第一次,0表示不是;t时刻对应的损失函数l1为:
[0032]
l1=-g
t
log(z
t
)-(1-g
t
)log(1-z
t
)
[0033]
其中,z
t
为该长短时记忆神经网络单元的词边界预测分支的结果;g
t
为词边界预测标签;
[0034]
将当前子词的隐层特征向量h
t
与辅助特征f
t
串联,通过一层节点个数为子词词表大小的线性层和softmax层,得到下一个子词的预测概率;对应的损失函数l2:
[0035][0036]
其中,v为词汇表的大小;w
(t 1)v
为序列第(t 1)子词是否为词表中第vg个单词,是为1,否为0;;(y
tv
)为输出yt向量中第v个元素;
[0037]
则最优目标函数l为:
[0038]
l=αl1 (1-α)l2[0039]
其中,α为长短时记忆神经网络单元的损失函数的权重;其中,0≤α≤1;
[0040]
采用随机梯度下降的方式进行训练,得到土耳其语子词级别神经网络语言模型的参数。
[0041]
作为上述技术方案的改进之一,所述根据该候选语句中所有子词的预测概率的对数值,获得该候选语句的概率的对数值;具体包括:
[0042]
依次获得所有子词的预测概率后,分别取对数并依次相加:
[0043][0044]
其中,p
s
为第s个候选语句的概率的对数值;|s|为语句中所包含的子词个数;
[0045]
得到每个候选语句的概率的对数值。
[0046]
一种基于元音和谐的土耳其语的语音识别系统,该系统包括:
[0047]
拆分模块,用于将待识别语音进行识别,得到多个候选语句,再将每个候选语句拆分成多个子词;
[0048]
识别模块,用于将每个子词依次输入土耳其语子词级别神经网络语言模型,输出下一个子词的预测概率的对数值;
[0049]
对数获取模块,用于根据该候选语句中所有子词的预测概率的对数值,获得该候选语句的概率的对数值;和
[0050]
语音获取模块,用于按照从大到小的顺序对各个候选语句的概率的对数值进行排序,将最大概率的对数值对应的候选语句作为语音识别结果。
[0051]
本发明还提供了一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述方法。
[0052]
本发明还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述方法。
[0053]
本发明与现有技术相比的有益效果是:
[0054]
1)本发明中采用子词级别语言模型,降低输出层单元个数,减少参数量及计算时间;
[0055]
2)本发明采用的词边界辅助任务,可在训练阶段促使模型学习词边界相关特征的提取,但该模块并不需要在预测阶段使用,即可以在提升性能的情况下,并不增加预测阶段计算量。
附图说明
[0056]
图1是本发明的一种基于元音和谐的土耳其语的语音识别方法的流程图。
具体实施方式
[0057]
现结合附图对本发明作进一步的描述。
[0058]
如图1所示,本发明提供了一种基于元音和谐的土耳其语的语音识别方法,该方法通过建立子词级别语言模型,该模型使用字母出现信息作为特征,即增加一个表示字母出现情况的特征,用来帮助该语言模型预测下一个子词,进而提示当前子词所使用的元音类型信息,并使用词边界任务作为辅助任务,帮助该模型提高词边界相关信息的提取,从而提高语言模型的性能。
[0059]
如图1所示,该方法包括:
[0060]
将待识别语音进行识别,得到多个候选语句,再将每个候选语句拆分成多个子词;
[0061]
具体地,根据语音规则,将待识别语音送入传统的识别模块进行识别,得到多个候选语句,再将每个候选语句拆分成多个子词。
[0062]
按顺序将每个子词依次输入土耳其语子词级别神经网络语言模型,获得下一个子词的预测概率的对数值;
[0063]
具体地,按顺序依次抽取该候选语句中每个子词的对应的独热码,
[0064]
将每个子词对应的独热码输入土耳其语子词级别神经网络语言模型,输出下一个子词的预测概率向量y
t
;对下一个子词的预测概率向量y
t
取对数,获得下一个子词的预测概率的对数值。
[0065]
其中,所述土耳其语子词级别神经网络语言模型的处理过程,具体包括:
[0066]
将当前子词对应的独热码输入至词向量矩阵,输出当前子词的低维词向量;
[0067]
截取到当前子词为止的最后一个元音和辅音,并抽取其对应的独热码作为当前子词的辅助特征;
[0068]
将当前子词的低维词向量与当前子词的辅助特征串联,并将其输入至长短时记忆神经网络单元的隐层,输出当前子词的隐层特征向量;
[0069]
将当前子词的隐层特征向量与当前子词的辅助特征串联,获得串联后的特征向量,并将其输入至长短时记忆神经网络单元的softmax层,依据softmax函数:
[0070]
y
t
=softmax(w
e
[h
t
;f
t
] b
e
)
[0071]
其中,y
t
为下一个子词的预测概率向量;w
e
为仿射矩阵,b
e
为偏置;h
t
为当前子词的隐层特征向量;f
t
为当前子词的辅助特征;其中,辅助特征f
t
表示为到当前子词为止的最后一个元音和辅音,其包含最后一个元音和辅音的独热码;具体来说,土耳其语字母
表中包含8个元音21个辅音;因此,最后一个元音和辅音的独热码两部分的维度分别为8和21;最终的辅助特征为最后一个元音和辅音的独热码两部分的串联,即特征长度d=29;
[0072]
输出下一个子词的预测概率向量y
t
。
[0073]
根据该候选语句中所有子词的预测概率的对数值,获得该候选语句的概率的对数值;具体包括:
[0074]
依次获得所有子词的预测概率后,分别取对数并依次相加:
[0075][0076]
其中,p
s
为第s个候选语句的概率的对数值;|s|为语句中所包含的子词个数;
[0077]
得到每个候选语句的概率的对数值。
[0078]
按照从大到小的顺序对各个候选语句的概率的对数值进行排序,将最大概率的对数值对应的候选语句作为语音识别结果。
[0079]
所述方法还包括:土耳其语子词级别神经网络语言模型的训练步骤,具体包括:
[0080]
建立训练集,将训练集中的每个单词拆分成多个子词;
[0081]
对于当前子词w
t
,其输入为该当前子词的独热码;其中,v表示词汇表的大小;
[0082]
当前子词w
t
经过在词向量矩阵c的查表操作后,得到该当前子词w
t
的低维词向量e
t
;其中,c∈r
v
×
m
,e
t
∈r
m
中,v为词汇表的大小;m为子词级别神经网络语言模型的lstm单元的隐层单元个数;
[0083]
截取到当前子词为止的最后一个元音和辅音,并抽取其对应的独热码作为当前子词的辅助特征f
t
;
[0084]
将通过词向量矩阵c得到的低维词向量e
t
与辅助特征f
t
串联,送入长短时记忆神经网络单元中,得到的输出为当前子词的隐层特征向量h
t
;其中,h
t
∈r
m
;
[0085]
将当前子词的隐层特征向量h
t
通过一层只有一个节点线性层和sigmoid层得到结果z
t
;其中,该结果z
t
为该子词级别神经网络语言模型的词边界预测分支的结果;
[0086]
词边界预测标签g
t
∈{0,1}为下一子词是否为单词第一个子词;其中,1表示下一次是单词第一次,0表示不是;t时刻对应的损失函数l1为:
[0087]
l1=-g
t
log(z
t
)-(1-g
t
)log(1-z
t
)
[0088]
其中,z
t
为该长短时记忆神经网络单元的词边界预测分支的结果;g
t
为词边界预测标签;
[0089]
将当前子词的隐层特征向量h
t
与辅助特征f
t
串联,通过一层节点个数为子词词表大小的线性层和softmax层,得到下一个子词的预测概率;对应的损失函数l2:
[0090][0091]
其中,v为词汇表的大小;w
(t 1)v
为序列第(t 1)子词是否为词表中第vg个单词,是为1,否为0;;(y
tv
)为输出yt向量中第v个元素;
[0092]
则最优目标函数l为:
[0093]
l=αl1 (1-α)l2[0094]
其中,α为长短时记忆神经网络单元的损失函数的权重;其中,0≤α≤1;
[0095]
采用随机梯度下降的方式进行训练,得到土耳其语子词级别神经网络语言模型的参数,
[0096]
完成对子词级别神经网络语言模型训练,在训练完成后,在测试阶段,无需计算词边界预测部分,仅需计算输出下一个子词的预测概率向量y
t
,作为待预测下一个子词w
t 1
的概率。
[0097]
本发明还提供了一种基于元音和谐的土耳其语的语音识别系统,该系统包括:
[0098]
拆分模块,用于将待识别语音进行识别,得到多个候选语句,再将每个候选语句拆分成多个子词;具体地,将待识别语音送入传统的识别模块,得到多个候选语句,再将每个候选语句拆分成多个子词;
[0099]
识别模块,用于将每个子词依次输入土耳其语子词级别神经网络语言模型,输出下一个子词的预测概率的对数值;
[0100]
对数获取模块,用于根据该候选语句中所有子词的预测概率的对数值,获得该候选语句的概率的对数值;和
[0101]
语音获取模块,用于按照从大到小的顺序对各个候选语句的概率的对数值进行排序,将最大概率的对数值对应的候选语句作为语音识别结果。
[0102]
本发明还提供了一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述方法。
[0103]
本发明还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述方法。
[0104]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

