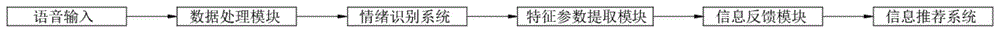
本发明涉及语音识别技术领域,具体为一种基于语音识别情绪反馈信息推荐系统及方法。
背景技术:
语音识别是计算语言学的跨学科子领域,利用其开发方法和技术,能够通过计算机识别和翻译口语。也被称为自动语音识别技术(asr),计算机语音识别或语音到文本(stt)技术。它融合了语言学、计算机科学和电气工程领域的知识和研究,随着科技的发展,语音识别的应用越来越普及,现阶段的语音识别交互技术多为解决用户在日常生活中的便利问题,例如沟通便利、交流便利、办公便利等,伴随着科学技术的飞速发展和人们对计算机依赖性的不断增加,如何使计算机对气氛和环境等因素具有更强的感知能力,从而分析说话人的情绪和态度,将成为计算机语音情绪识别技术发展的新目标。
但是,现有的语音识别系统无法捕捉说话人所表达的情绪差异,感知较差,从而影响信息传递效果;因此,不满足现有的需求,对此我们提出了一种基于语音识别情绪反馈信息推荐系统及方法。
技术实现要素:
本发明的目的在于提供一种基于语音识别情绪反馈信息推荐系统及方法,以解决上述背景技术中提出的现有的语音识别系统无法捕捉说话人所表达的情绪差异,感知较差,从而影响信息传递效果的问题。
为实现上述目的,本发明提供如下技术方案:一种基于语音识别情绪反馈信息推荐系统,包括语音输入、数据处理模块、情绪识别系统、特征参数提取模块、信息反馈模块和信息推荐系统,所述语音输入的输出端与数据处理模块的输入端连接,所述数据处理模块的输出端与情绪识别系统的输入端连接,所述情绪识别系统的输出端与特征参数提取模块的输入端连接,所述特征参数提取模块的输出端与信息反馈模块的输入端连接,所述信息反馈模块的输出端与信息推荐系统的输入端连接。
优选的,所述数据处理模块包括语音信号预处理、情绪模板数据库、算法分析系统和结果输出模块。
优选的,所述语音信号预处理的输出端与情绪模板数据库的输入端连接,所述情绪模板数据库的输出端与算法分析系统的输入端连接,所述算法分析系统的输出端与结果输出模块的输入端连接。
优选的,所述信息推荐系统包括电视前端子系统、智能语音音响和智能声控灯。
优选的,所述信息推荐系统的输出端与电视前端子系统的输入端连接,所述信息推荐系统的输出端与智能语音音响的输入端连接,所述信息推荐系统的输出端与智能声控灯的输入端连接。
优选的,所述语音信号预处理包括采样、预滤波、量化、端点检测、加窗、预加重。
优选的,所述特征参数提取模块包括动态特征提取和频谱特征提取。
一种基于语音识别情绪反馈信息推荐系统的方法,包括如下步骤:
步骤一:用户说话进行语音输入,数据处理模块对语音进行语音信号预处理,进行采样、预滤波、量化、端点检测、加窗、预加重,算法分析系统将用户输入语音的矢量序列与情绪模板数据库中的模板数据进行相似度的比对,将匹配出的相似度最高的模板数据所在的情绪类别当做情绪识别结果,结果输出模块进行数据的保存和输出;
步骤二:特征参数提取模块进行动态特征提取和频谱特征提取,消除背景噪音和不重要的信息,对用户的语音进行端点检测,判断语音的起始位置即有效范围,对语音信号进行分帧和预加重处理,提取出计算语音的声学相关参数,进行情绪特征的计算;
步骤三:信息反馈模块将情绪特征的数据实时反馈至信息推荐系统;
步骤四:信息推荐系统控制电视前端子系统、智能语音音响和智能声控灯感知用户当前的语音情绪,并相应的调节电视节目推荐、歌曲推荐和适当的光源。
与现有技术相比,本发明的有益效果是:
1、本发明对系统中的语音进行预处理和特征参数提取,预处理包括采样、预滤波、量化、端点检测、加窗、预加重等部分,特征参数提取模块的提取包括动态特征提取和频谱特征提取,达到了去除掉背景噪声和不重要的信息的目的,对用户的语音进行端点检测,判断语音的起始位置即有效范围,对语音信号进行分帧和预加重处理,动态特征提取主要指特征幅度、能量、过零率、共振峰频率的提取,提取出计算语音的声学相关参数,来进行情绪特征的计算,以保证语音情绪识别的实时实现,并相应的建立特征情绪模板数据库,当模板库建立完成后,在对用户的语音进行情绪识别时,可将用户输入语音的矢量序列与情绪模板数据库中的模板数据进行相似度的比对,从而将匹配出的相似度最高的模板数据所在的情绪类别当做情绪识别结果,进行数据的保存和输出;
2、本发明通过信息反馈模块将情绪特征的数据实时反馈至信息推荐系统,信息推荐系统控制电视前端子系统、智能语音音响和智能声控灯感知用户当前的语音情绪,能够捕捉说话人所表达的情绪差异,感知情绪,并相应的调节电视节目推荐、歌曲推荐以及适当的光源,从而提高信息传递效果以及信息传递质量,能够在第一时间反馈信息安抚和回应用户的情绪特征。
附图说明
图1为本发明的一种基于语音识别情绪反馈信息推荐系统的工作原理图;
图2为本发明的数据处理模块的工作原理图;
图3为本发明的信息推荐系统的工作原理图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
请参阅图1-3,本发明提供的一种实施例:一种基于语音识别情绪反馈信息推荐系统,包括语音输入、数据处理模块、情绪识别系统、特征参数提取模块、信息反馈模块和信息推荐系统,所述语音输入的输出端与数据处理模块的输入端连接,所述数据处理模块的输出端与情绪识别系统的输入端连接,所述情绪识别系统的输出端与特征参数提取模块的输入端连接,所述特征参数提取模块的输出端与信息反馈模块的输入端连接,所述信息反馈模块的输出端与信息推荐系统的输入端连接,用户说话进行语音输入,数据处理模块对语音进行语音信号预处理,进行采样、预滤波、量化、端点检测、加窗、预加重,提取出计算语音的声学相关参数,进行情绪特征的计算,信息反馈模块将情绪特征的数据实时反馈至信息推荐系统,信息推荐系统控制电视前端子系统、智能语音音响和智能声控灯感知用户当前的语音情绪,并相应的调节电视节目推荐、歌曲推荐和适当的光源。
进一步,所述数据处理模块包括语音信号预处理、情绪模板数据库、算法分析系统和结果输出模块,结果输出模块进行数据的保存和输出。
进一步,所述语音信号预处理的输出端与情绪模板数据库的输入端连接,所述情绪模板数据库的输出端与算法分析系统的输入端连接,所述算法分析系统的输出端与结果输出模块的输入端连接,算法分析系统将用户输入语音的矢量序列与情绪模板数据库中的模板数据进行相似度的比对,将匹配出的相似度最高的模板数据所在的情绪类别当做情绪识别结果。
进一步,所述信息推荐系统包括电视前端子系统、智能语音音响和智能声控灯,进行信息推荐。
进一步,所述信息推荐系统的输出端与电视前端子系统的输入端连接,所述信息推荐系统的输出端与智能语音音响的输入端连接,所述信息推荐系统的输出端与智能声控灯的输入端连接,信息推荐系统控制电视前端子系统、智能语音音响和智能声控灯感知用户当前的语音情绪,能够捕捉说话人所表达的情绪差异,感知情绪,并相应的调节电视节目推荐、歌曲推荐以及适当的光源,从而提高信息传递效果以及信息传递质量,能够在第一时间反馈信息安抚和回应用户的情绪特征。
进一步,所述语音信号预处理包括采样、预滤波、量化、端点检测、加窗、预加重,语音信号滤波、采样以及量化是通过计算机对语音数据进行分析,并把用户输入语音转换成数字信号,预加重是为了提高语音中的高频部分,使语音信号的频谱更加平滑,这样能够保证从低频到高频这段频带中,采用相同的信噪比来计算频谱,使频谱的分析和声道参数的分析更加的方便快捷,端点检测是将除噪声后的语音分离出来,确定语音的开始和结束部分,短时能量可用于区分浊音和轻音,用于区分无声和有声的分界,用于区分声母和韵母的分界,短时平均过零率是语音信号中的一帧语音在波形穿过零电平时的次数,离散信号的过零是指相邻的取样值发生了符号的改变,过零分析是关于时域分析中最容易的一种方式,针对比较连续的语音信号,过零就说明是时域波形穿过了时间轴,所谓的过零率就是指样本改变符号的次数,产生过零的速率是信号频率量的一个简单度量。
进一步,所述特征参数提取模块包括动态特征提取和频谱特征提取,动态特征指单维的短时特征有幅度、过零率和共振峰频率,频谱特征频率倒谱系数可用于反映人耳的听觉特性,语音信号滤波、采样以及量化是通过计算机对语音数据进行分析,并且把用户输入的语音信号转换成数字信号。
一种基于语音识别情绪反馈信息推荐系统的方法,包括如下步骤:
步骤一:用户说话进行语音输入,数据处理模块对语音进行语音信号预处理,进行采样、预滤波、量化、端点检测、加窗、预加重,算法分析系统将用户输入语音的矢量序列与情绪模板数据库中的模板数据进行相似度的比对,将匹配出的相似度最高的模板数据所在的情绪类别当做情绪识别结果,结果输出模块进行数据的保存和输出;
步骤二:特征参数提取模块进行动态特征提取和频谱特征提取,消除背景噪音和不重要的信息,对用户的语音进行端点检测,判断语音的起始位置即有效范围,对语音信号进行分帧和预加重处理,提取出计算语音的声学相关参数,进行情绪特征的计算;
步骤三:信息反馈模块将情绪特征的数据实时反馈至信息推荐系统;
步骤四:信息推荐系统控制电视前端子系统、智能语音音响和智能声控灯感知用户当前的语音情绪,并相应的调节电视节目推荐、歌曲推荐和适当的光源。
工作原理:使用时,用户说话进行语音输入,数据处理模块对语音进行语音信号预处理,进行采样、预滤波、量化、端点检测、加窗、预加重,算法分析系统将用户输入语音的矢量序列与情绪模板数据库中的模板数据进行相似度的比对,将匹配出的相似度最高的模板数据所在的情绪类别当做情绪识别结果,结果输出模块进行数据的保存和输出,特征参数提取模块进行动态特征提取和频谱特征提取,消除背景噪音和不重要的信息,对用户的语音进行端点检测,判断语音的起始位置即有效范围,对语音信号进行分帧和预加重处理,提取出计算语音的声学相关参数,进行情绪特征的计算,动态特征指单维的短时特征有幅度、过零率和共振峰频率,频谱特征频率倒谱系数可用于反映人耳的听觉特性,语音信号滤波、采样以及量化是通过计算机对语音数据进行分析,并把用户输入语音转换成数字信号,预加重是为了提高语音中的高频部分,使语音信号的频谱更加平滑,这样能够保证从低频到高频这段频带中,采用相同的信噪比来计算频谱,使频谱的分析和声道参数的分析更加的方便快捷,端点检测是将除噪声后的语音分离出来,确定语音的开始和结束部分,短时能量可用于区分浊音和轻音,用于区分无声和有声的分界,用于区分声母和韵母的分界,短时平均过零率是语音信号中的一帧语音在波形穿过零电平时的次数,离散信号的过零是指相邻的取样值发生了符号的改变,过零分析是关于时域分析中最容易的一种方式,针对比较连续的语音信号,过零就说明是时域波形穿过了时间轴,所谓过零率就是指样本改变符号的次数,产生过零的速率是信号频率量的一个简单度量,信息反馈模块将情绪特征的数据实时反馈至信息推荐系统,信息推荐系统控制电视前端子系统、智能语音音响和智能声控灯感知用户当前的语音情绪,能够捕捉说话人所表达的情绪差异,感知情绪,并相应的调节电视节目推荐、歌曲推荐以及适当的光源,从而提高信息传递效果以及信息传递质量,能够在第一时间反馈信息安抚和回应用户的情绪特征。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

