1.本发明涉及人工智能技术领域,具体涉及一种语音识别方法。
背景技术:
2.近年来,随着人工智能的兴起,语音识别技术取得明显的进步,并应用 于我们生活的各个方面,例如苹果公司的siri、微软公司的小娜、小米公司 的小爱同学、百度公司的小度。语音智能助理的功能不断完善,可以与用户 聊天、操作智能设备、智能家居管理等等。
3.目前,普通话识别技术逐渐成熟,但对于方言的识别仍然非常欠缺。一 方面,中国的地区多,不同地区都有自己的方言,方言统计起来耗时耗力; 另一方面,方言口口相传,并没有确定的方言标准。所以,到目前为止,并 未有一个可以识别全国方言的语音识别系统。因此,如何解决语音识别中的 缺陷,完善语音识别功能是目前有待解决的问题。
4.
技术实现要素:
5.本发明要解决的技术问题是如何解决语音识别中的缺陷,完善语音识别 功能,提供一种方言识别方法。
6.本发明是通过下述技术方案来解决上述技术问题:
7.一种方言识别方法,所述识别方法包括:
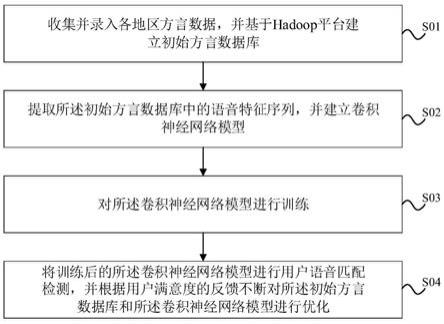
8.收集并录入各地区方言数据,并基于hadoop平台建立初始方言数据库;
9.提取所述初始方言数据库中的语音特征,并建立卷积神经网络模型;
10.对所述卷积神经网络模型进行训练;
11.将训练后的所述卷积神经网络模型进行用户语音匹配检测,并根据用户 满意度的反馈不断对所述初始方言数据库和所述卷积神经网络模型进行优 化。
12.进一步地,所述初始方言数据库中存储的数据包括:各方言所属的地区, 与方言对应的语音数据,与方言对应的文本数据,所述用户满意度。
13.进一步地,所述方言数据包括:语音数据和文本数据,所述语音数据和 所述文本数据存储于所述初始方言数据库的分布式文件系统中。
14.进一步地,所述提取所述方言数据库中的语音特征包括:
15.使用vad技术对录入的所述语音数据按频率进行分段处理;
16.对进行所述分段处理后的所述语音数据采用聚类方法进行降噪处理。
17.进一步地,所述进行用户语音匹配检测包括:
18.用户录入方言;
19.所述卷积神经网络模型对所述用户录入方言进行语音特征提取,获取用 户语音特征;
20.当所述用户语音特征存在于所述初始方言数据库中时,进行语音 征匹配,当语音
特征匹配成功时,则输出所述用户语音特征的匹配文 本,当语音特征匹配不成功时,所述初始方言数据库存储所述用户语 音特征并请用户输入所述用户语音特征对应的文本数据;
21.当所述用户语音特征不存在于所述初始方言数据库中时,所述初始方言 数据库存储所述用户语音特征并请用户输入所述用户语音特征对应的文本 数据。
22.在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发 明各较佳实例。
23.本发明的积极进步效果在于:本发明弥补了当前语音识别中方言识别欠 缺的缺陷;初始方言数据库可通过自我学习不断完善,当达到一定规模时, 其识别精度与普通话识别无异,使得语音识别系统可以应用的领域更加广泛。
附图说明
24.图1为本发明一种方言识别方法一实施例中的方法流程图。
具体实施方式
25.为了便于理解本申请,下面将参照相关附图对本申请进行更全面的描述。 附图中给出了本申请的首选实施例。但是,本申请可以以许多不同的形式来 实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使 对本申请的公开内容更加透彻全面。
26.除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技 术领域的技术人员通常理解的含义相同。本文中在本申请的说明书中所使用 的术语只是为了描述具体的实施例的目的,不是旨在于限制本申请。本文所 使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组 合。
27.s01:收集并录入各地区方言数据,并基于hadoop平台建立初始方言数 据库;
28.在一个示例中,收集大量的各个地区的方言资料,根据地区把这些语 音及其文本数据分地区全部录入,基于hadoop平台,建立初始方言数据库, 语音数据和文本数据均存储在hdfs(hadoop distributed file system,hadoop 分布式文件系统)中。初始方言数据库中需存储以下数据:一是该方言所属地 区;二是的该方言提取的声音特征;三是该方言的文本数据;四是用户满意 度信息。
29.s02:提取所述初始方言数据库中的语音特征,并建立卷积神经网络模 型;
30.在一个示例中,从语音波形中提取出语音特征序列,建立卷积神经网络 模型,首先使用基于模型的vad(voice activity detection,语音活动检测)技 术对录入的方言按照频率进行分段,然后采用聚类的方法对语音模型进行降 噪处理,排除不同人之间的口音特征,按照不同地区的方言进行聚类。主流 的特征域的处理方式包括vtln(vocal tract length normalization,声道长度 归一化)、hlda、特征域sat相关技术,较好的提取其声学特征。所建立的 卷积神经网络模型,使用大量的卷积层直接对整句语音信号进行建模,每个 卷积层使用3x3的小卷积核,并在多个卷积层之后再加上池化层。 cnn(convolutional neural network,卷积神经网络),最开始应用于图像处理, 当运用于语音识别中的频谱图时,可以克服传统语音识别中采样时间,频率 而导致的不稳定问题。
31.s03:对所述卷积神经网络模型进行训练;
32.在一个示例中,使用在初始方言数据库中与初筛数据集关联性大于设定 阈值的数据对卷积神经网络模型进行训练,从而确定卷积神经网络模型的参 数。
33.s04:将训练后的所述卷积神经网络模型进行用户语音匹配检测,并根 据用户满意度的反馈不断对所述初始方言数据库和所述卷积神经网络模型 进行优化。
34.在一个示例中,在录入端,用户录入方言,然后对用户录入的方言进行 语音特征提取,当提取的语音特征存在于初始方言数据库中时,与初始方言 数据库中的语音特征进行比对,若成功匹配,则输出匹配文本;若没有匹配 项,初始方言数据库储存其声音特征,并向录入模块进行反馈,用户自行输 入方言的文本数据,输入后的文本数据和语音特征共同存储在初始方言数据 库中。当提取的语音特征不存在于初始方言数据库中时,则初始方言数据库 暂时存储方言的语音特征,然后反馈给录入模块,录入模块给用户提供一个 输入文本数据的选项,用户根据自己所录入的方言语音,自行录入文本数据。 卷积神经网络模型可以将新增的用户输入的语音和文本数据输入神经网络 模型进行计算,得到预测结果集;建立每个预测结果与其时间维度上相邻数 据的关联映射,对预测结果进行调整,使关联映射全部收敛,不断调整优化 模型,以此提高方言数据库的识别精确度。并且,用户根据输出的文本信息 进行满意度的反馈,反馈的满意度越高,说明该方言识别的准确度越高。通 过对模型的不断优化,对用户反馈的识别满意度不高的方言重点进行优化, 更加高效迅速的提高方言识别系统的识别准确度。
35.虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理 解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领 域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式 做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

