1.本发明涉及的是声纹识别技术领域。声纹识别分为说话人辨认和说话人验证,本发明主要研究说话人辨认,具体来说是一种针对语言学习者的多任务说话人辨认方法。
背景技术:
2.语音作为语言的声音表现形式,不仅包含了语言语义信息,同时也传达了说话人语种、性别、年龄、情感、生理、心理等多种丰富的副语言语音属性信息。声纹识别作为生物识别的一种,是根据说话人的声波特性进行身份辨识,由于声纹作为一种行为特征,具有唯一性和独特性,以及在安全性、成本、便捷性等方面的应用优势,使得声纹识别被广泛应用于金融安全、国防安全、智能家居等领域。近年来,国内外学者对声纹识别进行了深入的分析研究,其中在已有的文献中最著名和效果最好的声纹识别方法主要包括:1.基于概率线性鉴别分析模型的文本无关声纹识别:2017年khosravani a,homayounpour m.a plda approach for language and text independent speaker recognition.computer speech&language,2017,45(5):457
‑
474.提出利用来自双语使用者的多语种数据训练概率线性鉴别分析模型,实现文本无关的多语言声纹识别,取得了较高的识别正确率。2.基于i
‑
vector概率线性鉴别分析模型的非并行语音转换研究:2017年tomi kinnunen,lauri juvela,paavo alku,junichi yamagishi.nonparallel voice conversion using i
‑
vector plda:towards unifying speaker verification and transformation[c]//2017ieee international conference on acoustics,speech and signal processing(icassp),new orleans,united states,2017:5535
‑
5539.提出采用i
‑
vector方法进行语音转换,将说话人验证和转换相统一,在任何阶段无需并行语段或时间对齐处理,其性能优于基于hmm
‑
gmm的方法。3.基于质心深度度量学习的说话人识别方法:2019年jixuan wang,kuan
‑
chieh wang,marc t.law,frank rudzicz,michael brudno.centroid
‑
based deep metric learning for speaker recognition[c]//2019ieee international conference on acoustics,speech and signal processing(icassp),brighton,england,2019:3652
‑
3656.提出使用原型网络损耗优化说话人嵌入模型,在说话人验证和识别任务中取得了相对较好的效果。4.一种基于自动语音识别的数据增强方法:2019年daniel s.park,william chan,yu zhang,chung
‑
cheng chiu,barret zoph,ekin d.cubuk,quoc v.le.specaugment:a simple data augmentation method for automatic speech recognition[c]//2019interspeech,graz,austria,2019:2613
‑
2617.提出在语音识别任务中对数据采用变形功能,频道屏蔽块和时间步长屏蔽块的增强策略。该方法在librispeech和switchboard等识别任务上大幅提升了语音识别率。5.基于新特征提取方法的非对称双向长短时记忆网络的说话人识别模型:2020年xingmei wang,fuzhao xue,wei wang,anhua liu.a network model of speaker identification with new feature extraction methods and asymmetric blstm.neurocomputing,2020,403:167
‑
181.提出将梅尔谱图和耳蜗图结合产生两个新特征,在短时间内获得更丰富的声纹功能,在此基础
上,提出一种非对称的双向长短时记忆网络,提高了说话人识别的正确率。
[0003]
多任务学习是一种归纳迁移机制,主要是利用隐含在多个相关任务训练信号中的特定领域信息提高泛化能力,通过使用共享表示并行训练多个任务,并专注于将解决一个问题的知识应用到相关的问题中,从而提高学习的效率。因此,多任务学习作为提高神经网络学习能力的方法在越来越多的领域中广泛应用,其在已有的文献中最著名的多任务学习方法主要包括:1.基于多线性关系网络的多任务学习方法:2017年mingsheng long,zhangjie cao,jianmin wang,philip s.yu.learning multiple tasks with multilinear relationship networks.advances in neural information processing systems,2017,30:1594
‑
1603.提出多线性关系网络,它是基于一种新的张量正态先验来提取任务关系,通过共同学习可转移特征和任务与特征的多线性关系,有效缓解了特征层负转移和分类器层转移不足的问题。提出的多线性关系网络在office
‑
caltech,office
‑
home,imageclef
‑
da三个多任务学习数据集上取得了较好的效果。2.基于不确定性加权损失的几何与语义场景中多任务学习方法:2018年alex kendall,yarin gal,roberto cipolla.multi
‑
task learning using uncertainty to weigh losses for scene geometry and semantics[c]//2018proceedings of the ieee conference on computer vision and pattern recognition,utah,united states,2018:7482
‑
7491.提出一种新的多任务深度学习损失权重计算方法,利用同方差不确定性同时学习不同数量和单元的分类和回归损失,并建立统一的组合语义分割、定位分割和深度回归体系结构,证明了模型损失权重的重要性。3.基于注意力机制的端到端多任务学习方法:2019年liu s,johns e,davison a j.end
‑
to
‑
end multi
‑
task learning with attention[c]//2019proceedings of the ieee conference on computer vision and pattern recognition,california,united states,2019:1871
‑
1880.提出一种新颖的多任务学习体系结构,它由全局功能池的单个共享网络以及用于每个任务的软注意力模块组成,可以在任何前馈神经网络上构建。4.一种基于任务相关性的多任务学习框架研究:2020年trevor standley,amir zamir dawn chen,leonidas guibas,jitendra malik,silvio savarese.which tasks should be learned together in multi
‑
task learning?[c]//2020international conference on machine learning,online,2020:9120
‑
9132.通过分析研究不同学习环境中的任务合作与竞争,提出将任务分配给多个神经网络框架,使协作任务由同一神经网络计算,竞争任务由不同网络计算。该框架提供了时间与精确度的权衡,适用于单个大型多任务神经网络,以及多个单任务网络,以更少的推理时间获得更高的正确率。
技术实现要素:
[0004]
本发明的目的在于提供一种能更好的提高语言学习者声纹识别的正确率和泛化能力的基于多任务学习自注意力机制的语言学习者声纹识别方法。
[0005]
本发明在实现过程中包括如下步骤:
[0006]
步骤(1)对原始语音信号进行预处理:
①
对原始语音信号利用梅尔滤波器组提取功率谱声纹特征;
②
对声纹特征进行归一化处理;
[0007]
步骤(2)提出构建mt
‑
sanet模型:
①
分别构建多个自注意力网络模块,使得每个模块在不同的表示子空间里同时获取全局与局部信息的联系,解决对长期依赖的捕获受序列
长度限制的问题;
②
合并所有自注意力网络模块构成多头自注意力网络,进行多任务学习以获取任务之间的相关性知识;
[0008]
步骤(3)提出从新的角度将学习语言过程中的不同学习阶段纳入辅助任务;
[0009]
步骤(4)完成基于多任务自注意力机制的语言学习者声纹识别:
①
语言学习者的学习阶段特征向量,与其他辅助任务特征向量经初始化后共同嵌入声纹特征首部,并与位置信息编码融合后,将融合特征矩阵作为mt
‑
sanet模型的输入;
②
提取多任务特征向量,利用多任务分类器对不同任务进行处理,最终完成语言学习者声纹识别。
[0010]
本发明还可以包括:
[0011]
1、在步骤(1)中对原始语音信号进行预加重、分帧、加窗、快傅里叶变换后,利用梅尔滤波器组滤波并取对数,提取功率谱作为原始语音的声纹特征。
[0012]
2、所述步骤(1)中对声纹特征进行去均值操作,并对其长度进行裁剪,分段成标准长度,将小于标准长度的片段进行填充,完成归一化处理。
[0013]
3、在步骤(2)中根据语音信号数据的特点,提出构建的mt
‑
sanet模型包括3个隐藏层,每层的多头自注意力网络包含8个自注意力网络模块。其隐藏层由多头自注意力网络和ffn合并组成。
[0014]
4、所述步骤(2)中将mt
‑
sanet模型的输入分别乘以权重矩阵w
q
、w
k
和w
v
得到query矩阵q,key矩阵k和value矩阵v,并根据注意力机制运算规则构建多个自注意力网络模块,使得每个模块在不同的表示子空间里获取全局与局部信息的联系,其中d
k
表示矩阵k的维度。
[0015]
5、所述步骤(2)中根据多个独立计算的自注意力网络模块,合并构成多头自注意力网络,multihead(q,k,v)=concat(head1,
…
,head
h
)w
o
,head
i
=attention(qw
iq
,kw
ik
,vw
iv
),将每个自注意力网络模块捕获的信息进行加权融合,使网络学习到更丰富的信息。
[0016]
6、所述步骤(2)中利用ffn增加非线性的表达能力,具体由2层全连接层和relu激活函数构成,表示为ffn(z)=relu(zw1 b1)w2 b2,relu激活函数的映射范围为0~∞,即输出值为任意非负实数。
[0017]
7、所述步骤(2)中对ffn的输入和输出分别进行残差连接和层标准化处理,具体表示为α和β为可学习参数,μ
l
和分别为层均值和方差,ε为无穷小量,能保证分母不为0。
[0018]
8、在步骤(3)中从新的角度将学习语言过程中的不同学习阶段作为语音属性信息纳入辅助任务,与性别、口音、学习语言共同组成辅助任务集。
[0019]
9、在步骤(4)中对每个多任务特征向量,在取值范围[0,1]之间的均匀分布中随机采样,采样次数与每一帧声纹特征维度相同,组成初始化多任务特征向量,并将其嵌入声纹特征首部。
[0020]
10、所述步骤(4)中位置信息编码采用正余弦函数编码方式,在偶数位置采用正弦编码方式,在奇数位置采用余弦编码方式,具体表示为pe(pos,2i)=sin(pos/10000
2i/d
)和
pe(pos,2i 1)=cos(pos/10000
2i/d
),pos表示声纹特征帧在时间序列中的位置,d表示pe的维度,与声纹特征帧的维度相同。
[0021]
11、所述步骤(4)中根据识别任务的不同,将提取到的多任务特征向量分别输入到对应的多任务分类器中,多任务分类器由1层全连接层和归一化指数函数构成,若输入的x
i
值是x中的最大值,此映射的分量趋近于1,其他x则趋近于0。模型损失函数表示为其中1{
·
}表示的是示性函数,当y
(i)
=d为真时,返回1,否则返回0。由此计算损失值,并反向传递训练模型以实现精确的语言学习者声纹识别。
[0022]
与现有技术相比,本发明的有益效果是:a.由于传统的单任务语言学习者的声纹识别正确率与模型泛化能力较低,本发明提出构建mt
‑
sanet模型,通过多任务自注意力机制,使得模型同时获取全局与局部信息的联系,解决对长期依赖的捕获受序列长度限制的问题,并学习多任务之间的相关性知识,以此来提高语言学习者声纹识别的正确率以及模型的泛化能力;b.针对语言学习者在学习过程中,不同的学习阶段会表现出不同的声纹特征,本发明提出从新的角度将语言学习者的学习阶段作为语音属性信息,与性别、口音、学习语言共同组成辅助任务集,进行多任务学习,提高声纹识别的效果;c.为使多任务特征向量在声纹特征中获取更丰富的知识,提出在取值范围[0,1]之间的均匀分布中随机采样初始化多任务特征向量,并将其嵌入到声纹特征首部,与位置信息编码融合后,将融合特征矩阵输入到mt
‑
sanet模型中,训练生成多任务特征向量,通过多任务分类器实现较精确的语言学习者声纹识别。
[0023]
本发明提出的基于多任务自注意力机制的语言学习者声纹识别方法,能更好的提高声纹识别的正确率和泛化能力,具有一定的有效性。
附图说明
[0024]
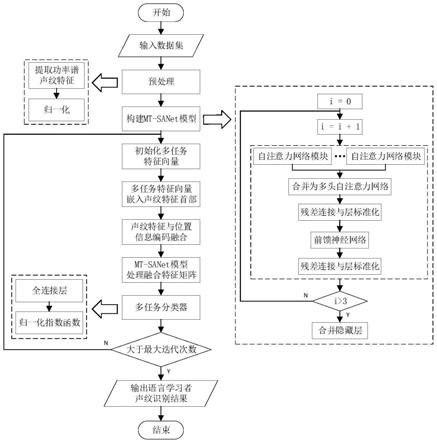
图1是本发明方法的流程图;
[0025]
图2(a)
‑
(j)是随机选取10名说话人在原始语音信号中随机抽取的一条3秒钟语音的音频波形图和提取功率谱声纹特征结果图,图2(a)是1号女性说话人的音频波形图和提取功率谱声纹特征结果图,图2(b)是2号女性说话人的音频波形图和提取功率谱声纹特征结果图,图2(c)是3号女性说话人的音频波形图和提取功率谱声纹特征结果图,图2(d)是4号女性说话人的音频波形图和提取功率谱声纹特征结果图,图2(e)是5号女性说话人的音频波形图和提取功率谱声纹特征结果图,图2(f)是1号男性说话人的音频波形图和提取功率谱声纹特征结果图,图2(g)是2号男性说话人的音频波形图和提取功率谱声纹特征结果图,图2(h)是3号男性说话人的音频波形图和提取功率谱声纹特征结果图,图2(i)是4号男性说话人的音频波形图和提取功率谱声纹特征结果图,图2(j)是5号男性说话人的音频波形图和提取功率谱声纹特征结果图;
[0026]
图3是本发明提出的mt
‑
sanet模型结构图;
[0027]
图4是自注意力机制结构图;
[0028]
图5是多头自注意力机制结构图;
[0029]
图6是各模型迭代100次的识别正确率;
[0030]
图7是各模型迭代100次的损失精度变化图;
[0031]
图8是30次实验各模型的识别正确率。
具体实施方式
[0032]
下面结合附图与具体实施方式对本发明作进一步详细描述。
[0033]
结合图1,本发明的具体步骤如下:
[0034]
(1)对原始语音信号进行预处理
[0035]
本发明的数据集采用leap corpus数据集,包括英语和德语两部分非母语语言学习者的语料库,从中选取126名说话人的语音数据作为实验数据。每段语音数据属性标签有:说话人id、性别、口音、学习阶段、学习语言,其中每位说话人平均3分钟语音数据。由于数据集录音质量较高,说话人音频清晰且无噪音,考虑到声纹识别任务在真实环境下会受到环境噪音的影响,本发明在音频数据中按照5db信噪比加入高斯白噪音,以模拟真实环境音效并提高模型对噪声的鲁棒性。
[0036]
对原始语音信号进行预加重、分帧、加窗、快速傅里叶变换后,利用梅尔滤波器组滤波并取对数,提取功率谱作为原始语音的声纹特征。
[0037]
快速傅里叶变换表示为:
[0038][0039]
式中:x(t)是原始语音信号,m
s
是傅里叶变换的点数。
[0040]
梅尔滤波器组表示为:
[0041][0042]
式中:q表示滤波器的个数,表示第i个滤波器的临界点。三角滤波器的频率响应trg
i
(k)定义为:
[0043][0044]
表示滤波器的边缘点,有:
[0045][0046]
式中:f
s
表示采样频率,f
max
和f
min
分别表示滤波器组的频率上界与频率下界。
[0047]
梅尔尺度f
mel
定义为:
[0048][0049][0050]
对提取功率谱声纹特征进行去均值操作,均衡频谱,提升信噪比,并以3秒钟为标准长度对其进行裁剪,将小于标准长度的片段进行填充,完成归一化处理。共得到7377段声纹特征,其中训练集6913段,验证集232段,测试集232段。图2是随机选取10名说话人在原始语音信号中随机抽取的一条3秒钟语音的音频波形图和提取功率谱声纹特征结果图。
[0051]
(2)提出构建mt
‑
sanet模型
[0052]
传统的单任务语言学习者的声纹识别正确率与模型泛化能力较低,因此提出构建mt
‑
sanet模型,通过多任务自注意力机制,使得模型同时获取全局与局部信息的联系,解决对长期依赖的捕获受序列长度限制的问题,并学习多任务之间的相关性知识,以此来提高声纹识别的正确率以及模型的泛化能力。mt
‑
sanet模型包括3个隐藏层,每层的多头自注意力网络包含8个自注意力网络模块。其隐藏层由多头自注意力网络和ffn合并组成。图3是本发明提出的mt
‑
sanet模型结构图。
[0053]
①
自注意力网络模块
[0054]
利用自注意力机制解决循环神经网络(recurrent neural network,rnn)对长期依赖的捕获受序列长度限制的问题,其矩阵运算的并行性优势使每一步的计算不依赖于上一步的计算结果,提高了模型的训练速度,并且相比于卷积神经网络(convolutional neural networks,cnn)和rnn具有更少的模型参数,因此,本发明根据自注意力机制构建自注意力网络模块,自注意力机制结构图如图4所示。
[0055]
注意力机制运算规则,有:
[0056][0057]
式中:mt
‑
sanet模型的输入分别乘以权重矩阵w
q
,w
k
,w
v
得到query矩阵q,key矩阵k和value矩阵v,d
k
表示矩阵k的维度。
[0058]
将矩阵运算结果转换为取值范围在[0,1]之间和为1的概率分布,并与矩阵v相乘构成自注意力网络模块。
[0059]
②
合并所有自注意力网络模块构成多头自注意力网络
[0060]
由于单个自注意力网络模块学习空间中的特征是不全面的,因此构建多个自注意力网络模块,形成多个子空间,使不同的自注意力网络模块关注不同方面的信息,获取全局与局部信息的联系,将自注意力网络模块合并为多头自注意力网络,使其具有更大的容量,学习到更加丰富的信息,更有利于获取多任务之间的相关性知识。图5是多头自注意力网络结构图。
[0061]
多头自注意力网络的运算规则,有:
[0062]
multihead(q,k,v)=concat(head1,
…
,head
h
)w
o
[0063]
式中:head
i
=attention(qw
iq
,kw
ik
,vw
iv
),代表第i个独立的自注意力网络模块运算结果。
[0064]
③
ffn增加非线性的表达能力
[0065]
由于自注意力机制以矩阵乘法为基本运算规则,对非线性的表达能力不强,利用ffn增加非线性的表达能力,ffn由两层全连接层和relu激活函数构成,具体有:
[0066]
ffn(z)=relu(zw1 b1)w2 b2[0067][0068]
式中:relu激活函数的映射范围为0~∞,即输出值为任意非负实数。
[0069]
为尽可能避免过拟合以及反向传递过程中梯度消散或梯度爆炸,对ffn的输入和输出分别进行残差连接和层标准化处理,层标准化具体为:
[0070][0071]
式中:α,β为可学习参数,μ
l
,为层均值与方差,ε为无穷小量,保证分母不为0。
[0072]
(3)提出从新的角度将学习语言过程中的不同学习阶段纳入辅助任务
[0073]
在语言学习领域,语言学习者在学习过程中的个体差异显著,具体表现在语言水平,语言技能,认知风格等方面的变化,使不同的学习阶段会表现出不同的声纹特征,因此,本发明将不同学习阶段作为语音属性信息,与性别、口音、学习语言共同组成辅助任务集。
[0074]
(4)完成基于多任务自注意力机制的语言学习者声纹识别
[0075]
①
初始化多任务特征向量并嵌入声纹特征首部
[0076]
将多任务特征向量在取值范围[0,1]之间的均匀分布中随机采样,采样次数与每一帧声纹特征维度相同,组成初始化多任务特征向量,并嵌入声纹特征首部。均匀分布的累积分布函数表示为:
[0077][0078]
②
声纹特征与位置信息编码融合
[0079]
由于声纹特征具有时序性的特点,注意力机制并不能捕获时序信息,因此采用正余弦位置信息编码方式表示声纹特征帧在时间序列中的位置信息,偶数位置采用正弦编码方式,奇数位置采用余弦编码方式,具体为:
[0080]
pe(pos,2i)=sin(pos/10000
2i/d
)
[0081]
pe(pos,2i 1)=cos(pos/10000
2i/d
)
[0082]
式中:pos表示声纹特征帧在时间序列中的位置,d表示pe的维度,与声纹特征帧的维度相同。
[0083]
对于声纹特征帧之间的位置偏移k,pe(pos k)可以表示为pe(pos)和pe(k)组合的形式,因此正余弦位置信息编码方式能够表达声纹特征帧的相对位置信息。将声纹特征与位置信息编码融合后,作为融合特征矩阵输入到mt
‑
sanet模型进行多任务学习。
[0084]
③
多任务分类器实现较精确的语言学习者声纹识别
[0085]
根据识别任务的不同,将模型学习后的多任务特征向量分别输入到对应的多任务分类器中,多任务分类器结构根据具体的下游任务确定,本专利共包含声纹识别、性别分类、口音识别、学习阶段识别、学习语言识别5项多分类任务,多任务分类器全部由1层全连接层和归一化指数函数构成。归一化指数函数表示为:
[0086][0087]
若输入的x
i
值是x中的最大值,映射的分量逼近于1,其他x则逼近于0。
[0088]
采用回归算法作为模型损失函数,有:
[0089][0090]
式中:1{
·
}表示的是示性函数,当y
(i)
=d为真时,返回1,否则返回0。由此计算损失值,并反向传递训练模型以实现精确的语言学习者声纹识别。
[0091]
为验证本发明提出的一种基于多任务自注意力机制的语言学习者声纹识别方法的有效性,给出leap corpus数据集的实验。图6是本发明提出的语言学习者声纹识别方法(mt
‑
sanet),与同样采用梅尔滤波器组提取功率谱作为声纹特征输入的单任务自注意力网络(single
‑
task self
‑
attention network,st
‑
sanet)模型、非对称双向长短时记忆网络(asymmetric bi
‑
directional long short time memory network,ablstm)模型、长短时记忆网络(long short time memory network,lstm)模型,以及cnn模型分别迭代100次的验证集识别正确率。从图6中可以得出,本发明提出的mt
‑
sanet模型识别正确率最高。相比较于st
‑
sanet模型、ablstm模型、lstm模型和cnn模型,提出的mt
‑
sanet模型更适用于语言学习者声纹识别。而由于传统cnn模型在使用梅尔滤波器组提取功率谱进行声纹识别的过程中,忽略了部分分布在时域上的声纹特征,造成了特征损失,因此识别正确率较低。对于语言学习者声纹识别而言,其识别结果不仅与上文相关,还与下文相关,lstm模型只能考虑到上文信息,不能利用下文信息。ablstm模型虽然同时考虑到上下文信息,以及正向传播的lstm模型具有更多的声纹特征,但仍未解决长期依赖的捕获受序列长度限制的问题。对于引入自注意力机制的st
‑
sanet模型可以有效改善上述问题,在语言学习者声纹识别任务中取得了相对好的实验效果,验证了自注意力机制的有效性。
[0092]
为了进一步验证本发明提出的mt
‑
sanet模型将语言学习者声纹识别与性别、口音、学习阶段、学习语言这些辅助任务,通过硬参数共享机制进行多任务学习具有一定的有效性,表1给出5次不同的随机种子下,极大迭代次数为100次时的消融实验在测试集的平均识别正确率,以验证不同辅助任务对实验效果的影响。
[0093]
表1平均识别正确率(消融实验)
[0094][0095][0096]
从表1的分析研究看出,多任务学习的识别正确率均好于单任务学习,其中以性别、学习阶段、学习语言作为辅助任务取得了最好的实验效果,模型通过获取任务之间的相关性知识,提高了语言学习者声纹识别的正确率。通过第1,4实验组,以及第13,16实验组的对比实验看出,语言学习者学习阶段的引入有助于提高语言学习者的声纹识别正确率。因此,本发明提出构建的mt
‑
sanet模型具有一定的有效性,并且对于语言学习者的声纹识别任务,其语言学习阶段可以作为一种新的角度来考虑多任务建模。
[0097]
在此基础上,表2给出5次不同的随机种子下,极大迭代次数为100次时mt
‑
sanet模型与st
‑
sanet模型、ablstm模型、lstm模型和cnn模型在测试集的平均识别正确率。
[0098]
表2各模型平均识别正确率
[0099]
声纹识别模型mt
‑
sanetst
‑
sanetablstmlstmcnn平均识别正确率92.07%90.16%79.58%79.11%71.88%
[0100]
从表2可以看出,在极大迭代次数为100次时,本发明提出的mt
‑
sanet模型,与st
‑
sanet模型、ablstm模型、lstm模型和cnn模型的平均识别正确率分别为92.07%,90.16%,79.20%,79.11和71.88%。因此,语言学习者的声纹识别任务中引入自注意力机制进行建模的mt
‑
sanet模型和st
‑
sanet模型均好于ablstm模型、lstm模型和cnn模型的效果,同时,本发明提出的mt
‑
sanet模型的识别正确率高于st
‑
sanet模型,与各模型相比正确率最高。
[0101]
由于在语言学习者声纹识别任务中,模型的泛化能力同样是重要的评价指标,因此,表3给出本发明提出的mt
‑
sanet模型,与st
‑
sanet模型、ablstm模型、lstm模型和cnn模型在5次不同的随机种子下100次迭代过程中验证集准确率的均方差。
[0102]
表3各模型的均方差
[0103]
声纹识别模型mt
‑
sanetst
‑
sanetablstmlstmcnn均方差1.566e
‑42.720e
‑45.248e
‑44.403e
‑48.998e
‑4[0104]
从表3可以看出,本发明提出的mt
‑
sanet模型在各对比模型中均方差最小,泛化能
力最强。结合表2分析可得,cnn模型由于忽略了部分分布在时域上的声纹特征,造成了特征损失,实验结果不佳且波动最大,ablstm模型和lstm模型虽然考虑到声纹特征时序性的特点,但由于长期依赖的捕获受序列长度限制,实验结果仍波动较大,而自注意力机制的引入使得模型同时学习到全局与局部信息的联系,解决了长期依赖的捕获受序列长度限制的问题,因此表现出更好的实验效果,同时相比于ablstm模型、lstm模型和cnn模型具有更强的泛化能力。
[0105]
为验证本发明提出mt
‑
sanet模型的收敛性,图7是本发明提出的mt
‑
sanet模型,与st
‑
sanet模型、ablstm模型、lstm模型和cnn模型分别迭代100次的损失精度变化情况。从实验结果可以看出,当迭代次数为20时,各个模型的损失值都趋于稳定,接近收敛,收敛速度基本相同。
[0106]
为了比较本发明提出的mt
‑
sanet模型,与st
‑
sanet模型、ablstm模型、lstm模型和cnn模型在leap corpus数据集上的识别性能,表4给出30次实验的测试集识别正确率结果。为了获得更清晰直观的比较结果,图8是表4对应的曲线图。
[0107]
表4 30次实验各种模型的识别正确率
[0108]
[0109][0110]
从表4和图8可以看到,在30次实验过程中,本发明提出的mt
‑
sanet模型的平均识别正确率最高。自注意力机制的引入有效地解决了长期依赖的捕获受序列长度限制的问题,在语言学习者声纹识别任务中效果提升较为明显。在此基础上,对于语言学习者,本发明提出的mt
‑
sanet模型的多任务学习方式,将语言学习阶段作为语音属性信息纳入辅助任务,通过硬参数共享机制进行建模具有一定的有效性,模型可以通过获取任务之间的相关性知识,提高语言学习者声纹识别的识别正确率。
[0111]
综上,本发明提供的是一种基于多任务自注意力机制的语言学习者声纹识别方法。包括如下步骤:(1)对原始语音信号进行预处理;(2)提出构建多任务自注意力网络(multi
‑
task self
‑
attention network,mt
‑
sanet)模型;(3)提出从新的角度将学习语言过程中的不同学习阶段纳入辅助任务;(4)完成基于多任务自注意力机制的语言学习者声纹识别。本发明为了取得更好的语言学习者的声纹识别效果,提出一种基于多任务自注意力机制的语言学习者声纹识别方法。即原始语音信号经过梅尔滤波器组提取功率谱声纹特征,通过归一化完成预处理;为提高传统单任务语言学习者的声纹识别正确率,提出构建mt
‑
sanet模型,通过多任务自注意力机制,使得模型同时获取全局与局部信息的联系,解决对长期依赖的捕获受序列长度限制的问题,并学习多任务之间的相关性知识,以此来提高声纹识别的正确率以及模型的泛化能力;针对语言学习者在学习过程中,不同的学习阶段会表现出不同的声纹特征,提出从新的角度将语言学习者的学习阶段作为语音属性信息纳入辅助任务进行多任务学习,提高声纹识别的效果;在此基础上,为使多任务特征向量在声纹特征中获取更丰富的知识,提出在均匀分布中随机采样初始化多任务特征向量,并将其嵌入到声纹特征首部,与位置信息编码融合后,作为融合特征矩阵输入到mt
‑
sanet模型中,训练生成多任务特征向量,通过多任务分类器实现较精确的语言学习者声纹识别。本发明提出的基于多任务自注意力机制的语言学习者声纹识别方法,能更好的提高声纹识别的正确率和泛化能力,具有一定的有效性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

