1.本技术实施例涉及数据处理技术领域,尤其涉及一种数据写入方法及装置。
背景技术:
2.随着网络技术的飞速发展,为了解决数据共享和数据信息孤岛的问题,许多企业和团体通过将各种应用系统收集到的各种类型的数据写入至数据湖(hudi)中。
3.然而,发明人发现,在现有技术中,在将数据写入至hudi中,采用的是文件滚动合并的方式进行数据的写入,具体而言,在当前将文件a写入至hudi中后,若再次需要将文件b写入至hudi中,则需要先将文件b读取出来,之后再将文件a和文件b写入至hudi中,以此类推,当需要再将文件c写入至hudi中时,则需要先读取出文件a和文件b,之后,才会将文件a、文件b和文件c写入至hudi中。现有技术中,由于采用文件滚动合并的方式进行数据的写入,导致需要消耗非常大的io读写性能。
技术实现要素:
4.本技术实施例的目的是提供一种数据写入方法、装置、计算机设备及计算机可读存储介质,可以用于解决在将文件写入至hudi中时,需要消耗非常大的io读写性能的问题。
5.本技术实施例的一个方面提供了一种数据写入方法,,所述方法包括:
6.确定从数据源中获取到的待写入数据所分配的数据桶;
7.将所述待写入数据写入至所述数据桶中;
8.在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至分布式文件系统hdfs中。
9.可选地,设定所述待写入数据的写入模式为所述追加模式,所述追加模式为通过hoodiecreatehandle方法将数据写入至所述hdfs中。
10.可选地,所述将所述待写入数据写入至所述数据桶中包括:
11.判断内存中是否存在所述数据桶;
12.若判断出内存中不存在所述数据桶时,在所述内存中创建所述数据桶;
13.将所述待写入数据写入至所述数据桶中。
14.可选地,所述在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至所述hdfs中包括:
15.在所述数据桶中写入的数据量达到预设容量后,通过预设的生产者
‑
消费者
‑
队列模型中的生产者将所述数据桶中的数据写入至队列中,其中,所述队列的容量与所述数据桶的容量相同;
16.通过所述生产者
‑
消费者
‑
队列模型中的消费者将所述队列中的数据消费出来;
17.采用追加模式将消费出来的数据写入至所述hdfs中。
18.可选地,所述在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至分布式文件系统hdfs中的步骤之前,还包括:
19.关闭所述生产者
‑
消费者
‑
队列模型中的限速模式。
20.可选地,所述方法还包括:
21.在每一次执行检测点checkpoint操作时,对所述hdfs中的小文件进行纵向合并操作,所述纵向合并操作为对在执行上一次checkpoint操作与当前checkpoint操作之间生成的小文件进行合并操作,所述小文件为文件大小小于预设值的文件。
22.可选地,所述对所述hdfs中的小文件进行纵向合并操作的步骤之后,还包括:
23.对所述hdfs中的小文件进行横向合并操作,所述横向合并操作为对执行当前checkpoint操作之前生成的所有小文件进行合并操作。
24.本技术实施例的再一个方面提供了一种数据写入装置,所述数据写入装置包括:
25.确定模块,用于确定从数据源中获取到的待写入数据所分配的数据桶;
26.第一写入模块,用于将所述待写入数据写入至所述数据桶中;
27.第二写入模块,用于在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至分布式文件系统hdfs中。
28.本技术实施例的再一个方面提供了一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,上述处理器执行上述计算机程序时用于实现如上任一项所述的数据写入方法的步骤。
29.本技术实施例的又一个方面提供了一种计算机可读存储介质,其上存储有计算机程序,上述计算机程序被处理器执行时用于实现如上任一项所述的数据写入方法的步骤。
30.本技术实施例提供的数据写入方法、装置、计算机设备及计算机可读存储介质,通过确定从数据源中获取到的待写入数据所分配的数据桶;将所述待写入数据写入至所述数据桶中;在所述数据桶中写入的数据量达到预设容量后,采用追加模式(append模式)将所述数据桶中的数据写入至所述hdfs中。。本技术在将数据写入至hudi中的hdfs时,一直通过append模式将数据写入至hdfs中,由于append模式是通过调用hoodiecreatehandle方法将数据写入至所述hdfs中,而通过hoodiecreatehandle方法进行数据的写入,无需先将数据从hdfs中读取出来,因此,采用本技术中的数据写入方法,可以降低io读写性能的消耗。
附图说明
31.图1示意性示出了实现本技术实施例的数据写入方法的应用环境示意图;
32.图2示意性示出了根据本技术一实施例的数据写入方法的流程图;
33.图3为意性示出了hudi的模块示意图;
34.图4示意性示出了将所述待写入数据写入至所述数据桶中的步骤细化流程图;
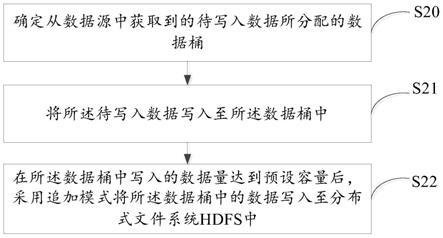
35.图5示意性示出了在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至所述hdfs中的步骤细化流程图;
36.图6示意性示出了根据本技术实施例的数据写入装置的程序模块图;以及
37.图7示意性示出了根据本技术实施例的适于实现数据写入方法的计算机设备的硬件架构示意图。
具体实施方式
38.为了使本技术实施例的目的、技术方案及优点更加清楚明白,以下结合附图及实
施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
39.需要说明的是,在本发明中涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
40.图1示意性示出了实现本技术实施例的数据写入方法的应用环境示意图,在示例性的实施方式中,该应用环境的系统可以包括以下几部分:数据源1、数据分发层2、数据存储层3等。
41.所述数据源1,可以是从客户端采集上来后,并写入至数据存储系统中的数据,比如存储至kafka集群中的数据。kafka集群是一种消息分发订阅系统,在存储数据时,可以起到数据削峰填谷的作用。不同重要性、优先级、数据吞吐量的数据流,可以被分流到kafka集群中的不同的topic(主题)中,以保障不同类型的数据流的价值,避免系统故障影响整体数据。
42.数据分发层2,可以由flink集群组成的流量分发系统(collector)实现,用于内容转换和分发存储,即保障数据流从数据源1中获取并写入到数据存储层3中对应的存储终端中。具体的,所述数据分发层2用于数据的分发落地,支持的分发场景包括hudi、hdfs(hadoop distributed file system,hadoop分布式文件系统)、kafka、hbase、es(elasticsearch)等。
43.所述数据存储层3,用于存储数据,各个终端可以由不同形式的数据库构成,所述数据库可以es、hive、kafka、hdfs和hbase、hudi等,本实施例中的数据存储层为hudi。
44.为了帮助理解所述数据写入系统的工作原理,下面对其提供的数据写入服务进行介绍:客户端通过http、rpc等协议将这些数据上报存储至数据存储系统中,以形成数据源1,数据源1经过数据分发层2的分发,以将数据源发到数据存储层3中的终端中进行存储。
45.图2示意性示出了根据本技术实施例一的数据写入方法的流程图。该数据写入方法应用于数据湖hudi中,参阅图3,所述hudi包括数据桶分配模块30、数据流写入模块31及分布式文件系统hdfs写入模块32。
46.其中,hudi是一个数据湖或是数据库,但它又不是数据湖或是数据库。众所周知,hive是一个计算框架,但是现在我们更多的是使用spark基于hive对hdfs中文件提供的schema信息和元数据进行计算,而hive作为计算引擎的功能逐渐被忽略,更多的是将hive视作一个“数据库”(尽管它并不是),而hudi则是完善了hive的这部分功能,甚至可以提供近实时的数据抽取与查询。
47.使用hudi对hdfs或是其他存储系统中的文件进行管理,使用hudi创建相应的表,一样可以使用hive或是spark对这些表进行计算。但是却解决了hadoop的小文件问题,查询缓慢问题等。
48.hudi具有以下特性:快速upsert、可插入索引、以原子方式操作数据并具有回滚功
能、写入器之间的快照隔离、savepoint用户数据恢复的保存点、管理文件大小,使用统计数据布局、数据行的异步压缩和柱状数据、时间轴数据跟踪血统。
49.可以理解,本方法实施例中的流程图不用于对执行步骤的顺序进行限定。下面以数据写入装置为执行主体进行示例性描述。如图2所示,该数据写入方法可以包括步骤s20~步骤s22,其中:
50.步骤s20,确定从数据源中获取到的待写入数据所分配的数据桶。
51.具体地,所述数据源可以为各种类型的数据存储系统,比如,kafka集群,hbase等。
52.数据源以kafka集群为例,数据写入装置可以从kafka集群的topic中消费数据,并将该消费出的数据作为所述待写入数据。
53.本实施例中,数据桶分配模块在获取到待写入数据之后,可以为所述待写入数据分配待写入的数据桶(bucket),以供数据流写入模块将该待写入数据写入至数据桶中。其中,数据桶的分配规则采用现有的分配策略,比如,使用基于时间的分桶策略,这种策略为每个小时创建一个新的数据桶,桶中包含的文件将记录所有该小时内从数据源中接收到的数据。
54.作为示例,假设为待写入数据a分配的数据桶为数据桶a。
55.在本实施例中,当为待写入数据分配好数据桶后,会生成一条record(记录)信息与该待写入数据关联,该record信息可以用于记录所述待写入数据所分配的数据桶。
56.在一示例性的实施方式中,为了区分所述待写入数据的数据写入模式与现有的数据写入模式(insert模式与upsert模式),所述方法还包括:
57.设定所述待写入数据的写入模式为所述追加模式。
58.具体地,数据桶分配模块在为待写入数据分配数据桶时,还可以设定该待写入数据的写入模式,具体而言,可以将该待写入数据的写入模式设定为追加模式(append模式)。作为示例,可以通过数据桶分配模块在record信息添加标记“a”的方式来设定所述待写入数据的写入模式为所述append模式。
59.其中,append模式指的是后续在将数据写入至分布式文件系统(hadoop distributed file system,hdfs)时,会一直采用hoodiecreatehandle方法将数据写入至所述hdfs中。
60.需要说明的是,分布式文件系统(hadoop distributed file system,hdfs)采用主从(master/slave)架构进行文件存储。一个hdfs集群由一个namenode(名字节点)和多个datanode(数据节点)组成。namenode是一个中心服务器,负责文件系统的名字空间的操作,比如打开、关闭、重命名文件或目录,它负责维护文件路径到数据块的映射,数据块到datanode的映射,以及监控datanode的心跳和维护数据块副本的个数。而namenode的元数据信息是放在主内存中的,一条记录大概占150个字节,它的结构主要包括:(1)文件列表信息;(2)每个文件对应的文件块的信息;(3)每个文件块对应的datanode的信息;(4)文件属性,如创建时间、创建这,副本个数等。datanode负责处理客户端的读写请求,它在namenode统一调度下进行数据块的创建、删除和复制,一般一个物理节点(机器)上部署一个。
61.步骤s21,将所述待写入数据写入至所述数据桶中。
62.具体地,数据流写入模块可以通过从与该待写入数据关联的record信息中获取所述待写入数据需要写入至哪个数据桶。
63.作为示例,假设所述待写入数据写入的数据桶为数据桶a,则所述流写入模块则会将所述待写入数据写入至数据桶a中。
64.在一示例性的实施方式中,参阅图4,所述将所述待写入数据写入至所述数据桶中可以包括:步骤s40,判断内存中是否存在所述数据桶;步骤s41,若判断出内存中不存在所述数据桶时,在所述内存中创建所述数据桶;步骤s42,将所述待写入数据写入至所述数据桶中。
65.具体地,数据流写入模块在将所述待写入数据写入至所述数据桶之前,内存中可能还没有创建所述数据桶。因此,为了可以将所述待写入数据写入至所述数据桶中,需要先判断当前内存中是否存在所述数据桶。具体而言,可以将record信息中包含的数据桶的名称与当前内存中包含的各个数据桶的名称进行比较,若在内存中存在record信息中包含的数据桶的名称所相同的数据桶名称,则可以判定内存中存在所述数据桶;若再内存中不存在record信息中包含的数据桶的名称所相同的数据桶名称,则可以判定内存中不存在所述数据桶。
66.在本实施例中,当判定出内存中不存在所述数据桶之后,即可以为内存中创建所述数据桶,之后,可以通过所述数据流写入模块将所述待写入数据写入至所述数据桶中。
67.步骤s22,在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至分布式文件系统hdfs中。
68.具体地,所述预设容量为设定的,其可以根据实际情况进行设定与修改,比如,所述预设容量为64mb。
69.作为示例,当所述预设容量为64mb时,则在数据桶中写入的数据达到64mb后,即会将该数据桶刷出去,以便可以通过所述分布式文件系统hdfs写入模块采用追加模式(append模式)将所述数据桶中的数据写入至分布式文件系统hdfs。其中,append模式指的是在将数据写入至hdfs时,会调用hoodiecreatehandle方法将数据写入至所述hdfs中。
70.在本实施例中,hoodiecreatehandle方法是hudi中的用于将数据写入至hdfs中的一个固有函数,通过该hoodiecreatehandle方法将数据写入至hdfs中时,无需从hdfs中读取出之前写入至hdfs中的数据,而是可以直接将数据写入至hdfs中。
71.本技术中的数据写入方法,通过确定从数据源中获取到的待写入数据所分配的数据桶;将所述待写入数据写入至所述数据桶中;在所述数据桶中写入的数据量达到预设容量后,采用追加模式(append模式)将所述数据桶中的数据写入至所述hdfs中。。本技术在将数据写入至hudi中的hdfs时,一直通过append模式将数据写入至hdfs中,由于append模式是通过调用hoodiecreatehandle方法将数据写入至所述hdfs中,而通过hoodiecreatehandle方法进行数据的写入,无需先将数据从hdfs中读取出来,因此,采用本技术中的数据写入方法,可以降低io读写性能的消耗。
72.经过实测,采用本实施例中的数据写入方法在纯insert场景下,数据入湖的性能可以提升5倍。
73.在一示例性的实施方式中,参阅图5,所述在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至所述hdfs中可以包括:步骤s50,在所述数据桶中写入的数据量达到预设容量后,通过预设的生产者
‑
消费者
‑
队列模型中的生产者将所述数据桶中的数据写入至队列中,其中,所述队列的容量与所述数据桶的容量相同;
步骤s51,通过所述生产者
‑
消费者
‑
队列模型中的消费者将所述队列中的数据消费出来;步骤s52,采用追加模式将消费出来的数据写入至所述hdfs中。
74.具体地,生产者
‑
消费者
‑
队列模型是hudi中的boundedinmemoryexecutor模块用于对从数据桶中获取到的数据进行处理的一个固有模型,通过该模型中的生产者可以将数据桶中的数据写入至模型中包含的队列(queue)中,之后,可以通过该模型中消费者将队列中的数据消费出来,最后,通过所述分布式文件系统hdfs写入模块采用append模式将消费出来的数据写入至所述hdfs中。
75.在本实施例中,可以预先设置队列的容量与数据桶的容量相同,这样,在通过生产者将数据桶中的数据写入至模型中包含的队列(queue)中时,可以将数据桶中的所有数据都写入至同一个队列中,从而可以节省队列所需要消耗的存储资源。
76.在一示例性的实施方式中,所述在所述数据桶中写入的数据量达到预设容量后,通过追加模式将所述数据桶中的数据写入至所述hdfs中的步骤之前,还包括:
77.关闭所述生产者
‑
消费者
‑
队列模型中的限速模式。
78.具体地,在现有的hudi中的生产者
‑
消费者
‑
队列模型中具有一个用于对队列进行写入限速的限速单元(ratelimiter),以防止现有的数据写入模式会因为写入队列中的数据量太大导致出故障的问题。通过在模型中增加限速单元,即可以控制写入至队列的数据量,避免队列中故障。
79.然而,由于本技术中采用append模式实现数据的写入,其不会存在数据写入过量的问题,因此,在本实施例中,为了避免限速单元对数据写入的速率的限制,可以通过所述分布式文件系统hdfs写入模块关闭所述生产者
‑
消费者
‑
队列模型中的限速模式。
80.在一示例性的实施例中,所述方法还包括:
81.在每一次执行检测点checkpoint操作时,对所述hdfs中的小文件进行纵向合并操作,所述纵向合并操作为对在执行上一次checkpoint操作与当前checkpoint操作之间生成的小文件进行合并操作,所述小文件为文件大小小于预设值的文件。
82.具体地,检测点操作(checkpoint操作),又称检测点机制,通过该机制可以保证分布式文件系统hdfs写入模块(例如,flink集群)在某个算子因为某些原因出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。具体而言,通过该检测点操作可以将正在运行的任务的状态保存下来,这个状态包括任务中每个算子的state(状态),数据源中的消息的offset(偏移量)等。
83.需要说明的是,检测点是分布式文件系统hdfs写入模块中实现容错机制最核心的功能,它能够根据配置周期性地基于stream中各个operator/task的状态来生成snapshot(快照),从而将这些状态数据定期持久化存储下来,当程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。快照的核心概念之一是barrier。这些barrier被注入数据流并与数据流中的数据(或者称为记录)一起作为数据流的一部分向下流动。barriers永远不会超过记录,数据流严格有序,barrier将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。每个barrier都带有快照的id,并且barrier之前的记录都进入了该快照。
84.其中,所述预设值为设定的值,该预设值可以根据实际情况进行设定与调整,比
如,所述预设值为2mb。
85.本实施例中,为了避免hdfs中的小文件数量过多,可以在执行checkpoint操作时,将在执行上一次checkpoint操作与当前checkpoint操作之间生成的小文件进行合并操作,以生成大文件,其中,所述大文件为文件大小处于预设范围的文件,比如,所述大文件为文件大小位于64mb~128mb的文件。
86.在一示例性的实施方式中,为了进一步减少小文件的数量,所述对所述hdfs中的小文件进行纵向合并操作的步骤之后,还包括:
87.对所述hdfs中的小文件进行横向合并操作,所述横向合并操作为对执行当前checkpoint操作之前生成的所有小文件进行合并操作。
88.本实施例中,在每一次执行检测点checkpoint操作时,首先通过执行纵向合并操作后对上一次checkpoint操作与当前checkpoint操作之间生成的小文件进行合并操作。一般来说,纵向合并操作并不能对在这期间产生的所有小文件进行合并,因此,在本实施例中,为了进一步减少小文件的数量,可以进一步通过横向合并操作对执行当前checkpoint操作之前所生成的所有小文件进行合并操作。
89.图6示出了根据本技术实施例的数据写入装置的程序模块图,该数据写入装置600可以被分割成一个或多个程序模块,一个或者多个程序模块被存储于存储介质中,并由一个或多个处理器所执行,以完成本技术实施例。本技术实施例所称的程序模块是指能够完成特定功能的一系列计算机程序指令段,以下描述将具体介绍本实施例中各程序模块的功能。如图6所示,数据写入装置600可以包括:确定模块601、第一写入模块602及第二写入模块603。
90.确定模块601,用于确定从数据源中获取到的待写入数据所分配的数据桶;
91.第一写入模块602,用于将所述待写入数据写入至所述数据桶中;
92.第二写入模块603,用于在所述数据桶中写入的数据量达到预设容量后,采用追加模式将所述数据桶中的数据写入至分布式文件系统hdfs中。
93.在一示例性的实施方式中,数据写入装置600还包括设定模块。
94.所述设定模块,用于设定所述待写入数据的写入模式为所述追加模式,所述追加模式为通过hoodiecreatehandle方法将数据写入至所述hdfs中。
95.在一示例性的实施方式中,所述第一写入模块602,还用于判断内存中是否存在所述数据桶;若判断出内存中不存在所述数据桶时,在所述内存中创建所述数据桶;将所述待写入数据写入至所述数据桶中。
96.在一示例性的实施方式中,第二写入模块603,还用于在所述数据桶中写入的数据量达到预设容量后,通过预设的生产者
‑
消费者
‑
队列模型中的生产者将所述数据桶中的数据写入至队列中,其中,所述队列的容量与所述数据桶的容量相同;通过所述生产者
‑
消费者
‑
队列模型中的消费者将所述队列中的数据消费出来;采用追加模式将消费出来的数据写入至所述hdfs中。
97.在一示例性的实施方式中,数据写入装置600还包括关闭模块。
98.所述关闭模块,用于关闭所述生产者
‑
消费者
‑
队列模型中的限速模式。
99.在一示例性的实施方式中,数据写入装置600还包括合并模块。
100.所述合并模块,用于在每一次执行检测点checkpoint操作时,对所述hdfs中的小
文件进行纵向合并操作,所述纵向合并操作为对在执行上一次checkpoint操作与当前checkpoint操作之间生成的小文件进行合并操作,所述小文件为文件大小小于预设值的文件。
101.在一示例性的实施方式中,所述合并模块,还用于对所述hdfs中的小文件进行横向合并操作,所述横向合并操作为对执行当前checkpoint操作之前生成的所有小文件进行合并操作。
102.本实施例通过确定从数据源中获取到的待写入数据所分配的数据桶;将所述待写入数据写入至所述数据桶中;在所述数据桶中写入的数据量达到预设容量后,采用追加模式(append模式)将所述数据桶中的数据写入至所述hdfs中。。本技术在将数据写入至hudi中的hdfs时,一直通过append模式将数据写入至hdfs中,由于append模式是通过调用hoodiecreatehandle方法将数据写入至所述hdfs中,而通过hoodiecreatehandle方法进行数据的写入,无需先将数据从hdfs中读取出来,因此,采用本技术中的数据写入方法,可以降低io读写性能的消耗。
103.图7示意性示出了根据本技术实施例的适于实现数据写入方法的计算机设备的硬件架构示意图。本实施例中,计算机设备20是一种能够按照事先设定或者存储的指令,自动进行数值计算和/或信息处理的设备。例如,可以是网关等数据转发设备。如图7所示,计算机设备20至少包括但不限于:可通过系统总线相互通信连接存储器21、处理器22、网络接口23。其中:
104.存储器21至少包括一种类型的计算机可读存储介质,可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,存储器21可以是计算机设备20的内部存储模块,例如该计算机设备20的硬盘或内存。在另一些实施例中,存储器21也可以是计算机设备20的外部存储设备,例如该计算机设备20上配备的插接式硬盘,智能存储卡(smart media card,简称为smc),安全数字(secure digital,简称为sd)卡,闪存卡(flash card)等。当然,存储器21还可以既包括计算机设备20的内部存储模块也包括其外部存储设备。本实施例中,存储器21通常用于存储安装于计算机设备20的操作系统和各类应用软件,例如数据写入方法的程序代码等。此外,存储器21还可以用于暂时地存储已经输出或者将要输出的各类数据。
105.处理器22在一些实施例中可以是中央处理器(central processing unit,简称为cpu)、控制器、微控制器、微处理器、或其他数据处理芯片。该处理器22通常用于控制计算机设备20的总体操作,例如执行与计算机设备20进行数据交互或者通信相关的控制和处理等。本实施例中,处理器22用于运行存储器21中存储的程序代码或者处理数据。
106.网络接口23可包括无线网络接口或有线网络接口,该网络接口23通常用于在计算机设备20与其他计算机设备之间建立通信连接。例如,网络接口23用于通过网络将计算机设备20与外部终端相连,在计算机设备20与外部终端之间的建立数据写入通道和通信连接等。网络可以是企业内部网(intranet)、互联网(internet)、全球移动通讯系统(global system of mobile communication,简称为gsm)、宽带码分多址(wideband code division multiple access,简称为wcdma)、4g网络、5g网络、蓝牙(bluetooth)、wi
‑
fi等无线或有线
网络。
107.需要指出的是,图7仅示出了具有部件21
‑
23的计算机设备,但是应理解的是,并不要求实施所有示出的部件,可以替代的实施更多或者更少的部件。
108.在本实施例中,存储于存储器21中的数据写入方法还可以被分割为一个或者多个程序模块,并由一个或多个处理器(本实施例为处理器22)所执行,以完成本发明。
109.本实施例还提供一种计算机可读存储介质,计算机可读存储介质其上存储有计算机程序,计算机程序被处理器执行时实现实施例中的数据写入方法的步骤。
110.本实施例中,计算机可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,计算机可读存储介质可以是计算机设备的内部存储单元,例如该计算机设备的硬盘或内存。在另一些实施例中,计算机可读存储介质也可以是计算机设备的外部存储设备,例如该计算机设备上配备的插接式硬盘,智能存储卡(smart media card,简称为smc),安全数字(secure digital,简称为sd)卡,闪存卡(flash card)等。当然,计算机可读存储介质还可以既包括计算机设备的内部存储单元也包括其外部存储设备。本实施例中,计算机可读存储介质通常用于存储安装于计算机设备的操作系统和各类应用软件,例如实施例中的数据写入方法的程序代码等。此外,计算机可读存储介质还可以用于暂时地存储已经输出或者将要输出的各类数据。
111.显然,本领域的技术人员应该明白,上述的本发明实施例的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明实施例不限制于任何特定的硬件和软件结合。
112.以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。