1.本发明涉及人工智能领域,具体涉及计算机视觉中的一种基于深度学习的学生视点估计方法。
背景技术:
2.在人工智能的迅速发展中,针对新兴技术和教育行业需求的不断更新发展态势下,多领域融合、深度学习等成为解决传统教学管理的不二选择。现如今,各个级别的学校教室都安装有摄像头,如何利用这些视频信息解决课堂问题成为了一大挑战。现有技术中,陈平等在文献“基于单幅图像pnp头部姿态估计的学习注意力可视化分析”中提出通过求解pnp问题得到人脸的旋转矩阵r和平移矩阵t,再通过三角形相似边成正比几何推导的方式计算学生视点在黑板上的投影坐标;高巧萍等在公开号为cn202110289021.x的中国专利中提出通过图像采集模块采集脸部图像,然后通过中控单元确定学生黑眼球中心位置,将实际视线角度与预设视线角度进行比较以确定学生注意力;郭赟等在文献“基于头部姿态的学习注意力判别研究”中提出通过卷积神经网络对面部特征点进行检测,接着采用比例正交投影迭代变换(posit)求解头部姿态的旋转和平移矩阵,最后通过判断头部的旋转角度是否在指定的阈值范围来确定注意力是否集中。但是,现有技术存在的缺陷有:传统的机器学习方法对头部姿态的估计过程中,对相机的外部参数过分依赖、估计的结果准确率较低;通过几何公式推导计算学生视点的投影坐标,对相机参数过于依赖、对头部姿态的容错能力较低,在应用上缺少鲁棒性,将严重影响最终的结果;只考虑头部姿态对视点坐标的影响,对于不同个体在教室中的位置因素缺少分析。本方法利用监控摄像头拍摄的视频数据,尝试对学生的视点位置进行估计。
技术实现要素:
3.本发明的目的是针对现有技术的不足,而提供一种基于深度学习的学生视点估计方法。这种方法利用监控摄像头拍摄的视频数据,对学生的视点位置进行估计,能提高实际应用的鲁棒性,对复杂教室环境下的学生视点估计有较高的准确率,采用估计学生的视点位置,进一步分析学生的注意力,从而对课堂学生听课质量进行统计分析,为实现智慧课堂管理提供技术支持。
4.实现本发明目的的技术方案是:
5.一种基于深度学习的学生视点估计方法,包括如下步骤:
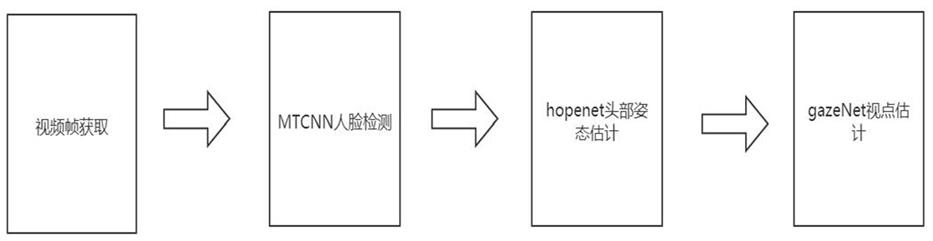
6.1)视频帧获取:依据布置在教室内的摄像头获取学生的视频帧,然后依次将采集的所有学生视频帧输入人脸检测网络模型mtcnn;
7.2)人脸检测:人脸检测网络模型mtcnn对步骤1)获得的视频帧进行特征提取,检测出每个学生视频帧中的人脸区域,并记录人脸的左上角坐标(x_min,y_min)和右下角坐标(x_max,y_max),最后,根据左上角坐标(x_min,y_min)和右下角坐标(x_max,y_max)对人脸进行裁剪,得到单张人脸图片,人脸的中心坐标(x人脸,y人脸)如公式(1)所示:
[0008][0009]
3)hopenet头部姿态估计:将步骤2)裁剪的单张人脸图片输入头部姿态估计网络hopenet中,hopenet网络是nataniel ruiz等在文献“fine
‑
grained head pose estimation without keypoints”中提出的无关键点的精细头部姿态估计模型,头部姿态估计网络hopenet对人脸进行特征提取,根据最终的特征图估计人脸的俯仰角pitch、偏航角yaw和滚转角roll;
[0010]
4)学生视点估计:将步骤3)得到的人脸俯仰角pitch、偏航角yaw和滚转角roll及步骤2)得到的人脸中心坐标(x人脸,y人脸)5个参数输入学生视点估计网络gazenet中,学生视点估计网络gazenet经过线性回归得到学生在黑板区域的视点坐标(x视点,y视点),gazenet网络的神经元线性计算如公式(2)所示,其中ω是gazenet网络学习得到的网络参数,x是输入的特征参数,b是偏移量,y是计算值,其次,神经元的激活函数采用leakyrelu,如公式(3)所示,其中x是公式(2)的计算值,leak是系数常量,y是神经元的输出值:
[0011]
y=ω
t
x b
ꢀꢀꢀ
(2),
[0012]
y=max(0,x) leak*min(0,x)
ꢀꢀꢀ
(3)。
[0013]
步骤4)中所述的学生视点估计网络gazenet采用深度学习框架pytorch或tensorflow进行搭建,并采集大量数据进行标注学习,学生视点估计网络gazenet设有顺序连接的输入层、隐藏层和输出层,其中,输入层共计五个参数:人脸的中心坐标(x人脸,y人脸)、人脸俯仰角(pitch)、偏航角(yaw)和滚转角(roll),隐藏层设有3个全连接层,每一个全连接层有12个神经元,神经元对上一层的输出值进行公式(2)计算,并用公式(3)激活输出,第1个全连接层的12个神经元采用公式(2)对输入层的5个参数进行计算,并将计算结果采用公式(3)激活输出;第2、3个全连接层对各自上一层的12个神经元的输出结果进行公式(2)的线性计算以及公式(3)的激活,并输出。
[0014]
本技术方案针对传统几何方法中估计学生视点位置不具备鲁棒性的问题,选用深度神经网络对人脸的检测和头部姿态的估计,提高了人脸检测和头部姿态估计的准确性,通过搭建浅层神经网络对学生视点的估计,提高了在复杂教室环境下应用的鲁棒性。
[0015]
这种方法利用监控摄像头拍摄的视频数据,对学生的视点位置进行估计,能提高实际应用的鲁棒性,对复杂教室环境下的学生视点估计有较高的准确率,采用估计学生的视点位置,进一步分析学生的注意力,从而对课堂学生听课质量进行统计分析,为实现智慧课堂管理提供技术支持。
附图说明
[0016]
图1实施例的方法流程示意图;
[0017]
图2为实施例中的浅层神经网络gazenet结构示意图;
[0018]
图3为实施例中方法的原理示意图。
具体实施方式
[0019]
下面结合附图和实施例对本发明的内容作进一步的阐述,但不是对本发明的限定。
[0020]
实施例:
[0021]
参照图1,图3,一种基于深度学习的学生视点估计方法,包括如下步骤:
[0022]
1)视频帧获取:依据布置在教室内的摄像头获取学生的视频帧,本例采用opencv进行视频帧的获取,然后依次将采集的所有学生视频帧输入人脸检测网络模型mtcnn,mtcnn是多任务卷积神经网络人脸检测器,该检测器在大规模人脸数据集上训练并得到最优的模型,该模型将对视频帧进行提取特征,将提取的特征进行筛选分类,得到视频帧中人脸的区域;
[0023]
2)人脸检测:人脸检测网络模型mtcnn对步骤1)获得的视频帧进行特征提取,检测出每个学生视频帧中的人脸区域,并记录人脸的左上角坐标(x_min,y_min)和右下角坐标(x_max,y_max),最后,根据左上角坐标(x_min,y_min)和右下角坐标(x_max,y_max)对人脸进行裁剪,得到单张人脸图片,人脸的中心坐标(x人脸,y人脸)如公式(1)所示:
[0024][0025]
3)hopenet头部姿态估计:将步骤2)裁剪的单张人脸图片输入头部姿态估计网络hopenet中,hopenet网络是nataniel ruiz等在文献“fine
‑
grained head pose estimation without keypoints”中提出的无关键点的精细头部姿态估计模型,头部姿态估计网络hopenet对人脸进行特征提取,根据最终的特征图估计人脸的俯仰角pitch、偏航角yaw和滚转角roll;
[0026]
4)学生视点估计:将步骤3)得到的人脸俯仰角pitch、偏航角yaw和滚转角roll及步骤2)得到的人脸中心坐标(x人脸,y人脸)5个参数输入学生视点估计网络gazenet中,学生视点估计网络gazenet经过线性回归得到学生在黑板区域的视点坐标(x视点,y视点),gazenet网络的神经元线性计算如公式(2)所示,其中ω是gazenet网络学习得到的网络参数,x是输入的特征参数,b是偏移量,y是计算值,其次,神经元的激活函数采用leakyrelu,如公式(3)所示,其中x是公式(2)的计算值,leak是系数常量,y是神经元的输出值:
[0027]
y=ω
t
x b
ꢀꢀꢀ
(2),
[0028]
y=max(0,x) lea k*min(0,x)
ꢀꢀꢀ
(3)。
[0029]
如图2所示,步骤4)中所述的学生视点估计网络gazenet采用深度学习框架pytorch或tensorflow进行搭建,并采集大量数据进行标注学习,学生视点估计网络gazenet设有顺序连接的输入层、隐藏层和输出层,其中,输入层共计五个参数:人脸的中心坐标(x人脸,y人脸)、人脸俯仰角(pitch)、偏航角(yaw)和滚转角(roll),隐藏层设有3个全连接层,每一个全连接层有12个神经元,神经元对上一层的输出值进行公式(2)计算,并用公式(3)激活输出。第1个全连接层的12个神经元采用公式(2)对输入层的5个参数进行计算,并将计算结果采用公式(3)激活输出;第2、3个全连接层对各自上一层的12个神经元的输出结果进行公式(2)的线性计算以及公式(3)的激活,并输出。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。