1.本发明涉及金融的量化分析领域,具体涉及一种基于遗传算法的量化投资的优化方法。
背景技术:
2.股票预测一直是金融市场研究中的热点问题,量化投资也并非最近才出现的新事物。长期以来被众多投资者所接受的是有效市场假说,但是有效市场假说仅仅是基于传统线性模型的一种假设。因为金融市场的复杂性和非线性,还受到各种政治事件、市场状况的影响。同时随着大数据与人工智能、机器学习的快速发展,许多学者们都证实了股票价格是可以预测的。这也使得许多研究人员期望提出一种最好的非线性模型来预测股价走势。
3.区别于定性投资,量化投资是利用数学知识及计算机技术决定交易时间、交易对象、交易金额的新型投资方式。量化投资并不寄希望于一两次的收益,而是采用长线策略获取大概率的高收益。量化投资可以和多领域进行结合,但是随着人工智能的发展,机器学习在量化投资中的应用越来越广泛。量化投资的核心是模型,通过对历史数据的建模,并且将其用在对未来市场的预测,从而形成交易策略。
4.股价预测是量化投资中的一个重要的方向。如果能在上涨之前买入股票,在下跌前卖出,这样投资人就可以获得高额收益,也消除了风险,当然这是理想的状态。由于金融市场十分复杂,影响其的因素众多,所以其数据噪声也很大。找到影响股价走势的因子并通过优秀的模型对股价进行正确的预测是一个非常困难的任务。在量化投资的发展历程中主要分为三种,分别是传统的技术分析、时间序列预测、数据挖掘以及机器学习。传统的技术分析现在已经无法再继续运用于拥有海量数据的市场中了。而机器学习却能很好的完成这个任务,其随着人工智能的发展而兴起,在量化投资策略的研究中具有重大的意义。
技术实现要素:
5.针对现有技术中的上述不足,本发明提供的一种基于遗传算法的量化投资的优化方法解决了对庞大和复杂的金融数据的识别学习的问题。
6.为了达到上述发明目的,本发明采用的技术方案为:
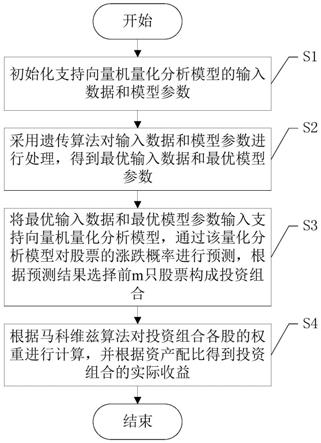
7.提供一种基于遗传算法的量化投资的优化方法,其包括以下步骤:
8.s1、初始化支持向量机量化分析模型的输入数据和模型参数;
9.s2、采用遗传算法对输入数据和模型参数进行处理,得到最优输入数据和最优模型参数;
10.s3、将最优输入数据和最优模型参数输入支持向量机量化分析模型,通过该量化分析模型对股票的涨跌概率进行预测,根据预测结果选择前m只股票构成投资组合;
11.s4、根据马科维兹算法对投资组合各股的权重进行计算,并根据资产配比得到投资组合的实际收益。
12.进一步地,步骤s1的具体方法包括以下子步骤:
13.s1
‑
1、选取股票的相关数据作为输入数据,同时设置参数搜索范围;
14.s1
‑
2、去除输入数据的空值并做标记,将输入数据分为样本内数据和样本外数据,并对所有分类后的输入数据依次进行归一化和标准化处理;其中样本内数据和样本外数据的比例为8:2。
15.进一步地:股票的相关数据包括涨跌幅、最高价、成交额、开盘价、最低价、日换手率、收盘价、成交量、市盈率、市净率、市销率、资产回报率、权益回报率、营业利润率、产权比率、流动比率、存货周转率、营业收入增长率、均真实区间、二十日成交金额的移动平均值、动态买卖气指标、相对强弱指标、成交量震荡、成交量量指数平滑异同移动平均线、股票二十日收益、同十日乖离率、十日顺势指标、钱德动量摆动指标、价量趋势指标、修正动量指标、五日收盘价三重指数平滑移动平均指标、上轨线指标、随机指标、十日移动均线、平滑异同移动平均线和动量指标中的至少一个数据。
16.进一步地,步骤s2的具体方法包括以下子步骤:
17.s2
‑
1、采用遗传算法,按照输入数据、支持向量机的惩罚因子和核函数带宽的顺序对初始化的输入数据和模型参数进行编码,生成染色体;
18.s2
‑
2、随机生成一个初始种群,其包含n个个体;
19.s2
‑
3、将种群中的个体输入到支持向量机量化分析模型进行训练;
20.s2
‑
4、匹配目标函数值,计算个体适应度,并根据轮盘赌算法选择个体遗传到下一代的概率;
21.s2
‑
5、对个体进行交叉、选择和变异操作,得到新的进化后的个体,将进化后的个体加入到下一代种群中;
22.s2
‑
6、判断目标函数值是否达到预设的迭代代数,若是则输出该情况下的支持向量机量化分析模型的最优输入数据和最优模型参数,并进入步骤s3;否则回到步骤s2
‑
3。
23.进一步地,步骤s2
‑
1中编码的具体方法包括以下子步骤:
24.s2
‑1‑
1、将编码设定为(f,c,σ);其中f、c和σ均为基因单位,f为输入特征,即输入数据,c为支持向量机的惩罚因子,以及σ为核函数的带宽;
25.s2
‑1‑
2、从位点到对输入数据进行编码,通过位点的值1或0来分别表示该输入数据是否被采用;从位点到对支持向量机的惩罚因子进行编码;从位点到对核函数的带宽进行编码。
26.进一步地,步骤s4的具体方法为:
27.根据公式:
[0028][0029]
得到投资组合的实际收益r
t
′
;其中,ω
i
为对投资组合各股进行马科维兹算法计算后的权重,r
t
(s
i,t
)为股票i在时间t的实际收益,s
i,t
为在时间t预测的排名为i的股票,m为股票支数。
[0030]
本发明的有益效果为:能够在降低计算成本的情况下实现对庞大且复杂的金融数据的识别学习,比起以往的模型,本发明能够实现更高的回报,且拥有更好的风险控制能力和恢复能力。
附图说明
[0031]
图1为本发明的主要流程图;
[0032]
图2为本发明步骤s2的流程图;
[0033]
图3为本法明步骤s2中的编码图;
[0034]
图4为投资组合股票数量为10的月区间收益率图;
[0035]
图5为投资组合股票数量为20的月区间收益率图;
[0036]
图6为投资组合股票数量为40的月区间收益率图;
[0037]
图7为指数走势图;
[0038]
图8为2015年高风险局部测试图;
[0039]
图9为2018年高风险局部测试图。
具体实施方式
[0040]
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
[0041]
该基于遗传算法的量化投资的优化方法包括以下步骤:
[0042]
s1、初始化支持向量机量化分析模型的输入数据和模型参数;
[0043]
s2、采用遗传算法对输入数据和模型参数进行处理,得到最优输入数据和最优模型参数;
[0044]
s3、将最优输入数据和最优模型参数输入支持向量机量化分析模型,通过该量化分析模型对股票的涨跌概率进行预测,根据预测结果选择前m只股票构成投资组合;
[0045]
s4、根据马科维兹算法对投资组合各股的权重进行计算,并根据资产配比得到投资组合的实际收益。
[0046]
进一步地,步骤s1的具体方法包括以下子步骤:
[0047]
s1
‑
1、选取股票的相关数据作为输入数据,同时设置参数搜索范围;
[0048]
s1
‑
2、去除输入数据的空值并做标记,将输入数据分为样本内数据和样本外数据,并对所有分类后的输入数据依次进行归一化和标准化处理;其中样本内数据和样本外数据的比例为8:2。
[0049]
股票的相关数据包括涨跌幅、最高价、成交额、开盘价、最低价、日换手率、收盘价、成交量、市盈率、市净率、市销率、资产回报率、权益回报率、营业利润率、产权比率、流动比率、存货周转率、营业收入增长率、均真实区间、二十日成交金额的移动平均值、动态买卖气指标、相对强弱指标、成交量震荡、成交量量指数平滑异同移动平均线、股票二十日收益、同十日乖离率、十日顺势指标、钱德动量摆动指标、价量趋势指标、修正动量指标、五日收盘价三重指数平滑移动平均指标、上轨线指标、随机指标、十日移动均线、平滑异同移动平均线和动量指标中的至少一个数据。
[0050]
步骤s2的具体方法包括以下子步骤:
[0051]
s2
‑
1、采用遗传算法,按照输入数据、支持向量机的惩罚因子和核函数带宽的顺序对初始化的输入数据和模型参数进行编码,生成染色体;
[0052]
s2
‑
2、随机生成一个初始种群,其包含n个个体;
[0053]
s2
‑
3、将种群中的个体输入到支持向量机量化分析模型进行训练;
[0054]
s2
‑
4、匹配目标函数值,计算个体适应度,并根据轮盘赌算法选择个体遗传到下一代的概率;
[0055]
s2
‑
5、对个体进行交叉、选择和变异操作,得到新的进化后的个体,将进化后的个体加入到下一代种群中;
[0056]
s2
‑
6、判断目标函数值是否达到预设的迭代代数,若是则输出该情况下的支持向量机量化分析模型的最优输入数据和最优模型参数,并进入步骤s3;否则回到步骤s2
‑
3。
[0057]
如图3所示,步骤s2
‑
1中编码的具体方法包括以下子步骤:
[0058]
s2
‑1‑
1、将编码设定为(f,c,σ);其中f、c和σ均为基因单位,f为输入特征,即输入数据,c为支持向量机的惩罚因子,以及σ为核函数的带宽;
[0059]
s2
‑1‑
2、从位点到对输入数据进行编码,通过位点的值1或0来分别表示该输入数据是否被采用;从位点到对支持向量机的惩罚因子进行编码;从位点到对核函数的带宽进行编码。
[0060]
步骤s4的具体方法为:
[0061]
根据公式:
[0062][0063]
得到投资组合的实际收益r
t
′
;其中,ω
i
为对投资组合各股进行马科维兹算法计算后的权重,r
t
(s
i,t
)为股票i在时间t的实际收益,s
i,t
为在时间t预测的排名为i的股票,m为股票支数。
[0064]
在本发明的一个实施例中,仿真过程如下:
[0065]
根据公式:
[0066][0067][0068]
得到股票的累计复合收益率r
c
,并根据该收益率进行仿真;其中,为预测的前m只股票的对应的平均实际收益,s
i,t
为在时间t排名为i的股票,r
t
(s
i,t
)为股票i在时间t的对应的实际收益,n为时间长度,单位为月。
[0069]
如图4、图5和图6所示,本发明测试的时间区间为2017年1月到2019年12月,总共36个月。本发明采用的基准收益为深证成指,其主要成分股为格力电器、五粮液、一汽轿车等,它可以基本上反映整个a股市场的整体情况。
[0070]
其中,accumative return为累计复合收益率,benchmark为基准收益率,svm model return为量化分析模型收益率,optimization model return为传统模型收益率。
[0071]
本发明提出的量化分析模型相对于基准收益和传统模型拥有更高的投资回报。根据以上三图的结果显示,在18年9月之前本发明模型和基准收益还有传统模型相比并没有太大的优势。但是在18年9月后,本发明模型的投资组合模型收益率开始显著提升。在18年9
月之后,本发明的量化模型的收益率始终高于另外两个的收益。图4中,本发明量化分析模型的最终收益率约为基准的1.8倍,图5中,投资组合中的股票数量达到20只时,也能保持基准1.6倍的收益。但是随着投资组合中证券数量的增加,模型的收益率也随着降低。该现象表明当投资模型中的股票数量增加时,模型预测的误差也加大了,所以也最终导致收益率降低。
[0072]
如图7、图8和图9所示,为了进一步测试本发明量化分析模型的抗风险能力,本发明将针对市场的高风险区间进行测试。2015年是中国证券市场最为动荡的一年,以深证成指为例,2015年上半年时指数达到最高点,但是到达最高点后整个市场急转直下。故本发明采用2015年左右近两年的数据来测试发明量化分析模型的抗风险能力。同时本发明还增加了2018年数据进行测试防止模型出现偶然性。
[0073]
其中,10
‑
stocks、20
‑
stocks和40
‑
stocks分别表示本发明量化分析模型中投资组合股票数量为10、20和40的情况。
[0074]
图7中虚线的范围是本发明测试的时间区间,本发明将对虚线内的数据进行抗风险测试。图8中,本发明模型在遇到大幅度下跌的时候也会伴随着下跌。但是随着市场的回暖,本发明模型拥有更好的上升趋势,能够快速盈利。在2016年2月后本发明模型净值快速回升,然而基准模型仍然维持一个较低的收益水平,且长期低迷。图9同理,所以综上,在极端的市场情况下,本发明模型拥有更好的风险控制和恢复能力。
[0075]
同时本发明模型的机器学习相关仿真结果如表1所示。
[0076]
表1模型机器学习评价结果
[0077][0078]
根据以上结果可以注意到,本发明的预测准确率只能保持在58%左右,但这也是一个好的准确率。由于金融数据的随机性和噪音过大的特点,所以会存在大量的误报,同时国内市场庞大,能做到很高的准确率本就是一件很困难的事,因此本发明具备有效性。
[0079]
本发明能够在降低计算成本的情况下实现对庞大且复杂的金融数据的识别学习,比起以往的模型,本发明能够实现更高的回报,且拥有更好的风险控制能力和恢复能力。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。