1.本发明涉及将对图像、声音进行视听的功能佩戴到头部来使用的头戴式信息处理装置。
背景技术:
2.在专利文献1中,示出了一种便携终端,具备:判定部,根据从至少1个麦克风输入的声音信号,判定是否应将周围音输出到耳机;以及声音输出控制部,在判定为应将周围音输出到耳机的情况下,将从至少1个麦克风输入的声音信号输出到耳机。
3.现有技术文献
4.专利文献1:日本特开2015
‑
211267号公报
技术实现要素:
5.一般而言,头戴式信息处理装置能够在用户佩戴于头部的显示部中显示现实空间、虚拟空间(虚拟对象)。在这样的头戴式信息处理装置中,近年来能够使现实世界和虚拟世界实时并且无缝地融合,使用户获得犹如当场存在虚拟的物体那样的体验。以往,在将头戴式耳机等声音输出部与显示部一起佩戴到头部来使用的头戴式信息处理装置中,通过声音输出部将从头戴式信息处理装置内部输出的声音信号变换为声音并放音,将声音信号传达给用户。
6.在声音输出部之中,在收听通过空气的振动来传递的气导音的气导型头戴式耳机中以与耳朵的表面接触的方式佩戴,特别是在开耳(open ear)型的头戴式耳机中还有时并非将耳朵完全堵住而佩戴,周围的声音经由头戴式耳机的周围而进入到耳朵,有时拾取并听到周围音。另外,在收听通过骨的振动来传递的骨导音的骨传导型头戴式耳机中,以完全不堵住耳朵的形式佩戴,周围音直接进入到耳朵而听得到。
7.但是,在周围音中,有对于用户而言需要的声音(例如来自其他人的招呼、紧急车辆的警报器等)以及对于用户而言不需要的声音(电车、车辆的行驶音、其他人之间的对话、烟花、雷声等较大的嘈杂的声音、强风、大雨的声音等)。针对这样的周围音,在专利文献1中示出如下方式:在将耳机佩戴到耳朵的状态下,判定用麦克风集音的周围音对于用户而言是否为必要性高的周围音,使用户利用耳机能够听见必要性高的周围音。
8.但是,在专利文献1中,虽然记载了收听对于用户而言必要性高的周围音,但并未启示任何针对对于用户而言不必要的周围音的处置等,存在从头戴式信息处理装置内部输出的声音信号的视听被对于用户而言不必要的周围音所妨碍这样的课题。特别是在用语言来表示从头戴式信息处理装置内部输出的声音信号的情况下,存在如下课题:由于不必要的周围音,无法顺利地听取由语言构成的向用户的招呼、警告等这样的辅助用户的声音,而导致漏听。
9.本发明是鉴于这样的情形而完成的,提供一种头戴式信息处理装置,即使存在对于用户而言不必要的周围音,也能够使用户准确地听取期望的声音。
10.如果简单地说明在本技术中公开的发明之中的代表性的发明的概要则如下所述。
11.一个实施方式所涉及的头戴式信息处理装置是具有对图像或者声音进行视听的功能且佩戴于头部的装置,具备声音输入部、声音输出部以及对头戴式信息处理装置的动作进行控制的控制部。声音输入部佩戴于用户的耳部附近,对在头戴式信息处理装置的外部发生并进入耳朵的周围音进行集音并变换为输入声音信号。声音输出部生成输出声音信号,将所生成的输出声音信号变换为输出用声音并向用户进行放音。控制部根据来自声音输入部的输入声音信号的音量等级和来自声音输出部的输出声音信号的音量等级,判别是否是周围音妨碍输出用声音的听取的状态,并根据判别的结果来控制声音输出部的放音动作。
12.另外,一个实施方式所涉及的头戴式信息处理装置具备显示部、声音输出部、传感器设备、用户状态判别部以及对头戴式信息处理装置的动作进行控制的控制部。显示部向用户显示包括虚拟空间信息或者现实空间信息的预定的信息。声音输出部生成输出声音信号,将所生成的输出声音信号变换为输出用声音并向用户进行放音。传感器设备探测用户的状态或者用户的周边的状态。用户状态判别部根据传感器设备的探测结果,判别用户的状态或者用户的周边的状态是否是适合听取输出用声音的状态。控制部根据用户状态判别部的判别结果,在是适合听取输出用声音的状态的情况下使声音输出部进行放音,在是不适合听取输出用声音的状态的情况下对声音输出部指示放音的中断。
13.通过使用本发明的头戴式信息处理装置,即使存在对于用户而言不必要的周围音,也能够使用户准确地听取期望的声音。
14.另外,上述以外的课题、结构以及效果通过以下的实施方式的说明会变得清楚。
附图说明
15.图1是示出本发明的实施方式1所涉及的头戴式信息处理装置的外观结构的一个例子的示意图。
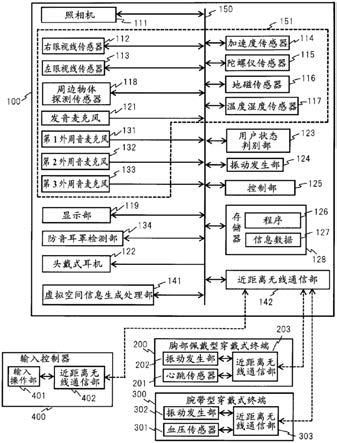
16.图2是示出图1的头戴式信息处理装置的概略结构例的框图。
17.图3是示出图2的控制部中的详细的处理内容的一个例子的流程图。
18.图4是示出在图2中与声音输入有关的控制部周围的主要部分的结构例的框图。
19.图5是示出图3中的放音动作的控制处理的详细的处理内容的一个例子的流程图。
20.图6是示出在图2中与声音输出有关的控制部周围的主要部分的结构例的框图。
21.图7是示出在图4中在放音的再次开始时附加延迟时间时的动作例的说明图。
22.图8是示出图3中的放音动作的控制处理的与图5不同的详细的处理内容的一个例子的流程图。
23.图9是示出图3中的放音动作的控制处理的与图8不同的详细的处理内容的一个例子的流程图。
24.图10是示出在本发明的实施方式2所涉及的头戴式信息处理装置中图2的控制部的详细的处理内容的一个例子的流程图。
25.图11是说明在图10中用户不适状态的一个例子的图。
26.图12是示出本发明的实施方式3所涉及的头戴式信息处理装置的概略结构例的框图。
27.(符号说明)
28.100:头戴式信息处理装置主体(头戴式显示器);111:照相机;112:右眼视线传感器;113:左眼视线传感器;114:加速度传感器;115:陀螺仪传感器;116:地磁传感器;117:温度湿度传感器;118:周边物体探测传感器;119:显示部;121:发音麦克风;122:头戴式耳机;123:用户状态判别部;124、202、302:振动发生部;125、503:控制部;128、502:存储器;131:第1外周音麦克风;132:第2外周音麦克风;133:第3外周音麦克风;134:防音耳罩检测部;141:虚拟空间信息生成处理部;142、203、303、402:近距离无线通信部;151:传感器设备;200:胸部佩戴型穿戴式终端;201:心跳传感器;300:腕带型穿戴式终端;301:血压传感器;400:输入控制器;401:输入操作部;500:虚拟空间信息生成服务器;501:虚拟空间信息生成处理部;600:外部网络;601:声音输入部;602:声音输出部;610:周围音判别部;611:声音输入处理部;615:阈值生成部;616:阈值表格;617:比较器;620:声音辅助处理部;621:声音输出处理部;622:声音辞典。
具体实施方式
29.以下,根据附图,详细地说明本发明的实施方式。此外,在用于说明实施方式的全部附图中,对同一部件原则上附加同一符号,省略其重复的说明。
30.(实施方式1)
31.《头戴式信息处理装置的概略》
32.图1是示出本发明的实施方式1所涉及的头戴式信息处理装置的外观结构的一个例子的示意图。图1的头戴式信息处理装置具备:佩戴到用户的头部的头戴式信息处理装置主体(头戴式显示器)100、佩戴到用户的胸部的胸部佩戴型穿戴式终端200、佩戴到用户的腕部的腕带型穿戴式终端300、以及输入控制器400。
33.头戴式信息处理装置主体100具备照相机111以及对用户的状态或者用户的周边的状态进行探测的传感器设备。在传感器设备中,包括右眼视线传感器112、左眼视线传感器113、加速度传感器114、陀螺仪传感器115、地磁传感器116、温度湿度传感器117、周边物体探测传感器118、发音麦克风121、第1~第3外周音麦克风131~133等。头戴式信息处理装置主体100使用照相机111对用户的前方影像进行摄像,使用传感器设备来探测用户的视线、用户的头部的活动、用户周边的温度和湿度、用户周边有无物体等。
34.另外,头戴式信息处理装置主体100具备显示部119。显示部119设置于两眼的前方,例如向用户显示虚拟空间信息、用照相机111摄影得到的现实空间信息这样的预定的信息。发音麦克风121对来自用户的发声声音进行集音并变换为声音信号。第1~第3外周音麦克风131~133构成声音输入部。声音输入部佩戴于用户的耳部附近,对在头戴式信息处理装置的外部发生并进入到耳朵的周围音进行集音并变换为输入声音信号。第1外周音麦克风131例如设置于头戴式信息处理装置的中心部,对从其他人等向用户进行了发声的声音进行集音。第2以及第3外周音麦克风132、133以与用户的左右耳接触的方式设置,对从外部进入到用户的耳朵的周围音进行集音。
35.另外,头戴式信息处理装置主体100具备分别佩戴于用户的左右的耳部的头戴式耳机122(122a、122b)。头戴式耳机122a、122b构成声音输出部,将在头戴式信息处理装置内部生成的左右的输出声音信号分别变换为左右的输出用声音后向用户进行放音。此外,在
用户通过声音输出部听取声音时,存在利用进入到耳朵并以空气的振动进行传递的气导音来听取的情况、以及利用不经由耳朵而以骨的振动进行传递的骨导音来听取的情况,作为头戴式耳机122,既可以是气导音型也可以是骨导音(骨传导)型。
36.胸部佩戴型穿戴式终端200具备作为传感器设备的心跳传感器201,探测在一定时间内心脏跳动的次数即心率。腕带型穿戴式终端300具备作为传感器设备的血压传感器301,探测用户的血压。此外,腕带型穿戴式终端300也可以具备脉搏传感器,探测动脉的跳动次数即脉搏数。输入控制器400是用户进行各种输入操作的控制器。胸部佩戴型穿戴式终端200、腕带型穿戴式终端300、输入控制器400通过近距离无线通信而与头戴式信息处理装置主体100之间进行信息的发送接收。此时,不限于无线,也可以通过有线方式进行信息的发送接收。
37.如以上那样,在与用户密接地佩戴的头戴式信息处理装置中,能够探测通过头戴式信息处理装置主体100具备的第2以及第3外周音麦克风132、133等声音输入部而进入到耳朵的周围音。另外,能够通过头戴式信息处理装置主体100、穿戴式终端200、300具备的各种传感器设备,探测用户的状态(例如身心状态、身体的活动)、用户的周边的状态。另外,根据经由输入控制器400的用户输入操作,头戴式信息处理装置主体100中的设置于用户的两眼前方的显示部119能够显示包括现实空间信息或者虚拟空间信息的预定的信息。
38.图2是示出图1的头戴式信息处理装置的概略结构例的框图。在图2中,头戴式信息处理装置主体100具备在图1中叙述的照相机111、各种传感器设备151(112~118、121、131~133)、显示部119以及头戴式耳机122。除此以外,头戴式信息处理装置主体100具备用户状态判别部123、振动发生部124、控制部125、存储器128、防音耳罩检测部134、虚拟空间信息生成处理部141以及近距离无线通信部142。这些各结构部分别经由总线150相互连接。
39.照相机111设置于头戴式信息处理装置主体100的前表面,对用户前方的风景进行摄影。将摄影得到的影像作为现实空间的影像而显示于显示部119。右眼视线传感器112以及左眼视线传感器113分别探测右眼以及左眼的视线。关于探测用户的视线的技术,一般知晓的有眼动追踪(eye tracking)。例如,在利用角膜反射的眼动追踪中,将红外线led(light emitting diode,发光二极管)照射到面部并用红外线照相机进行摄影,以在红外线led的照射中产生的反射光的角膜上的位置(角膜反射)为基准点,根据相对角膜反射的位置的瞳孔的位置来探测视线。
40.加速度传感器114是对每1秒的速度的变化即加速度进行探测的传感器,探测活动、振动、冲击等。陀螺仪传感器115是对旋转方向的角速度进行探测的传感器,探测纵、横、倾斜的姿势的状态。地磁传感器116是对地球的磁力进行检测的传感器,探测头戴式信息处理装置主体100朝向的方向。因此,如果使用陀螺仪传感器115或者地磁传感器116,而且根据情况而一并使用加速度传感器114,则能够探测佩戴头戴式信息处理装置主体100的用户的头部的活动。特别是,如果使用除了前后方向和左右方向以外还探测上下方向的地磁的3轴类型的地磁传感器116,则通过探测针对头部的活动的地磁变化,能够更高精度地探测头部的活动。
41.温度湿度传感器117是对用户的周边的温度以及湿度进行探测的传感器。周边物体探测传感器118是通过发射电波、光波、超声波等并探测来自对象物的反射波,从而探测与对象物之间的距离、对象物的方向、相对速度的传感器。通过将周边物体探测传感器118
佩戴于用户的头部,能够以用户为基准而探测与在用户的周边存在的物体之间的距离、物体的相对速度、物体存在的方向。
42.在将在头戴式信息处理装置内部生成的输出声音信号经由头戴式耳机122(声音输出部)作为输出用声音而进行放音时,用户状态判别部123根据各种传感器设备151的探测结果,判别用户的状态或者用户的周边的状态是否是适合听取输出用声音的状态。关于详情在图10以后进行后述,用户状态判别部123例如在视为用户注视着显示部119中的虚拟空间信息或者现实空间信息的情况等预先决定的各种情况下,判别为是不适合听取输出用声音的状态。
43.控制部125例如由cpu(central processing unit,中央处理单元)等构成,通过执行储存于存储器128的os(operating system,操作系统)、动作控制用应用等程序126,控制各结构部,控制头戴式信息处理装置整体的动作。关于详情进行后述,控制部125根据来自声音输入部(第2以及第3外周音麦克风132、133)的输入声音信号的音量等级以及来自声音输出部(头戴式耳机122等)的输出声音信号的音量等级,判别是否是周围音妨碍输出用声音的听取的状态,根据判别的结果来控制声音输出部的放音动作。
44.存储器128是闪存存储器、工作用的ram等。存储器128存储有os、控制部125使用的动作控制用应用等程序126。另外,存储器128存储有由头戴式信息处理装置主体100生成的输出声音信号的数据、由虚拟空间信息生成处理部141生成的虚拟空间信息、来自穿戴式终端200、300的信息这样的各种信息数据127。例如,作为由头戴式信息处理装置主体100生成的输出声音信号的数据,可以列举通过向用户的招呼、引导、信息传达、警告等这样的利用声音进行的与用户的对话而对用户的请求进行应答的声音辅助部的数据等。
45.显示部119由液晶面板等构成,利用影像来显示现实空间信息、虚拟空间信息,并且对面向用户的出示通知信息、动作状态等显示内容进行画面显示。显示部119例如也可以在开始输出声音信号的放音时、中断输出声音信号的放音时、再次开始输出声音信号的放音时,进行用于将其意思通知给用户的显示。由此,用户例如在进行放音的中断、再次开始的情况下,能够辨识出并非是故障而是通过正常的控制动作进行了中断、再次开始。
46.振动发生部124根据来自控制部125的指示而发生振动,例如将由头戴式信息处理装置主体100生成的向用户的通知信息变换为振动。振动发生部124通过在与用户的头部密接地佩戴的状态下发生振动,能够向用户进行辨识度更高的通知。防音耳罩检测部134例如在照相机111的摄像范围包括耳部那样的情况下,根据其图像来检测是否用手等罩住用户的耳部而进入耳朵的周围音被防音。此外,还能够根据进入第2以及第3外周音麦克风132、133的周围音的大小来探测周围音是否被防音。
47.虚拟空间信息生成处理部141生成利用影像、声音来表现与现实空间不同的虚拟空间的虚拟空间信息。近距离无线通信部142是与在能够进行近距离无线通信的范围中存在的胸部佩戴型穿戴式终端200、腕带型穿戴式终端300以及输入控制器400之间分别进行近距离无线通信的通信接口。近距离无线通信部142例如进行来自搭载于各穿戴式终端200、300的传感器的探测信息的接收、用于对搭载于各穿戴式终端200、300的振动发生部进行控制的控制信息的发送、针对输入控制器400的输入操作信息的发送接收等。
48.此外,关于近距离无线通信部142,代表性地是电子标签,但不限于此,只要是在头戴式信息处理装置主体100存在于胸部佩戴型穿戴式终端200、腕带型穿戴式终端300以及
输入控制器400的附近的情况下至少能够进行无线通信的通信部即可。作为这样的通信部,例如可以列举bluetooth(蓝牙,日本注册商标)、irda(infrared data association,红外数据协会)、zigbee(紫蜂,日本注册商标)、homerf(home radio frequency(家用射频),日本注册商标)或者无线lan(ieee802.11a、ieee802.11b、ieee802.11g)等。
49.胸部佩戴型穿戴式终端200具有作为传感器设备的心跳传感器201、振动发生部202以及近距离无线通信部203。心跳传感器201与用户的胸部密接地佩戴,高精度地探测用户的心率。近距离无线通信部203将探测到的心率的信息通过近距离无线通信而发送给头戴式信息处理装置主体100。振动发生部202根据控制输入而发生振动,通过与用户胸部密接地佩戴,能够准确地向用户传达发生振动。
50.腕带型穿戴式终端300具有作为传感器设备的血压传感器301、振动发生部302以及近距离无线通信部303。血压传感器301通过缠绕地佩戴于用户的腕部,高精度地探测用户的血压。近距离无线通信部303将探测到的血压的信息通过近距离无线通信而发送给头戴式信息处理装置主体100。振动发生部302根据输入而发生振动,通过缠绕地佩戴于用户的腕部,能够准确地向用户传达发生振动。
51.在此,头戴式信息处理装置主体100经由近距离无线通信部142,接收来自心跳传感器201的心率的信息、来自血压传感器301的血压的信息。用户状态判别部123能够根据该心率的信息、血压的信息,判别用户的状态(身心状态)是否是适合听取输出用声音的状态。另外,将从头戴式信息处理装置主体100发送的面向用户的通知信息,经由近距离无线通信部142、203、303而传达给各穿戴式终端200、300的振动发生部202、302。振动发生部202、302通过将通知信息变换为振动,能够使用户得知通知信息。
52.此外,头戴式信息处理装置主体100的振动发生部124、各穿戴式终端200、300的振动发生部202、302例如也可以在开始输出声音信号的放音时、中断输出声音信号的放音时、再次开始输出声音信号的放音时,发生用于将其意思通知给用户的振动。由此,用户例如能够较强地辨识进行了放音的中断、再次开始的情形。另外,头戴式信息处理装置主体100也可以通过利用头戴式耳机122发出通知放音的中断、再次开始的声音,从而通知用户使其知晓。
53.输入控制器400具有输入操作部401和近距离无线通信部402。输入操作部401是例如利用键盘、键按钮等的输入单元,能够设定输入用户希望输入的信息。另外,输入操作部401也可以是例如静电电容式等触摸板方式的输入单元。将利用输入操作部401输入的信息经由近距离无线通信部402而发送给头戴式信息处理装置主体100。此外,在此为了提高可用性而使用了无线通信,但当然也可以使用有线通信。
54.《控制部的详情》
55.图3是示出图2的控制部中的详细的处理内容的一个例子的流程图。图4是示出在图2中与声音输入有关的控制部周围的主要部分的结构例的框图。图2的控制部125以预定的控制周期,重复执行图3所示的流程。在图3中,控制部125使用声音输入部(第2以及第3外周音麦克风132、133),探测周围音(步骤s101)。接下来,控制部125判别声音输出部(头戴式耳机122等)是否对输出用声音正在放音(步骤s102)。在步骤s102中对输出用声音正在放音的情况下,控制部125根据在步骤s101中探测到的周围音的音量等级,判别在音量等级的点上是否是周围音妨碍输出用声音的听取的状态(步骤s103)。在说明书中,将在该音量等级
的点上周围音妨碍输出用声音的听取的状态还称为音量妨碍状态。
56.在步骤s103中发生了音量妨碍状态的情况下,控制部125判定能否通过放音方法的变更来进行处置(步骤s104)。关于放音方法的变更,在后面叙述详情,例如是对输出声音信号的频率特性进行变更的处理等。在步骤s104中不能通过放音方法的变更来处置的情况下,控制部125对声音输出部指示放音的中断(步骤s105)。而且,在步骤s105中,控制部125利用基于显示部119的告知显示、或者基于振动发生部124、202、302的触感振动、或者基于声音输出部(头戴式耳机122)的发声声音,向用户通知中断放音的意思,并结束处理。
57.在步骤s103中未发生音量妨碍状态的情况下,控制部125判别声音输出部是否变更放音方法来正在放音(步骤s106)。在步骤s106中变更放音方法来正在放音的情况下,控制部125在步骤s107中解除放音方法的变更之后(即,返回到默认的放音方法之后),在步骤s108中继续利用声音输出部进行放音,并结束处理。另一方面,在步骤s106中并非是变更放音方法来正在放音的情况(即,用默认的放音方法来正在放音的情况)下,控制部125原样地继续利用声音输出部进行放音,并结束处理(步骤s108)。此外,即使在步骤s104中能够通过放音方法的变更来处置的情况下,控制部125仍原样地继续利用声音输出部进行放音(步骤s108)。
58.在步骤s102中并非是对输出用声音正在放音的情况下,控制部125判别对于声音输出部的放音是否为中断中(步骤s109)。在步骤s109中对于放音是中断中的情况下,控制部125在步骤s110中执行放音动作的控制处理并结束处理,详情后述。在放音动作的控制处理中,包括放音方法的变更等。另一方面,在步骤s109中对于放音并非是中断中的情况下,控制部125结束处理。
59.在图4中,示出与图3的步骤s103(即,是否发生音量妨碍状态的判别)关联的控制部125周围的结构例。在图4中,示出控制部125和声音输入部601。声音输入部601具备对进入耳朵的周围音进行集音并变换为输入声音信号(vi)的第2以及第3外周音麦克风132、133。另一方面,控制部125具备周围音判别部610和声音输入处理部611。声音输入处理部611例如接受来自声音输入部601的输入声音信号(vi),检测其音量等级(li)。
60.周围音判别部610具备阈值生成部615、阈值表格616以及比较器617。在阈值表格616中,预先定义有来自声音输出部的输出声音信号(vo)的音量等级(lox)的各范围与表示各范围每一个的相对的周围音的容许值的阈值等级的对应关系。阈值生成部615接受预先由装置内部辨识的输出声音信号(vo)的音量等级(lox),根据阈值表格616来生成与该音量等级(lox)对应的阈值等级(thx)。
61.比较器617通过比较来自声音输入处理部611的输入声音信号(vi)的音量等级(li)和来自阈值生成部615的阈值等级(thx),判别是否对声音输出部指示放音的中断。换言之,比较器617判别是否是与输入声音信号(vi)对应的周围音妨碍与输出声音信号(vo)对应的输出用声音的听取的状态、即是否发生了音量妨碍状态。
62.具体而言,比较器617在输入声音信号(vi)的音量等级(li)是阈值等级(thx)以上的情况下,判别为是周围音妨碍输出用声音的听取的状态(发生了音量妨碍状态的状态),向声音输出部发行放音的中断指示(int)。另外,在声音输出部对于放音是中断中(即,图3的步骤s110中的放音动作的控制处理中)时,在输入声音信号(vi)的音量等级(li)小于阈值等级(thx)的情况下,比较器617判别为是周围音不妨碍输出用声音的听取的状态,向声
音输出部发行放音的再次开始指示(res)。换言之,比较器617判别为音量妨碍状态被消除的状态,向声音输出部发行放音的再次开始指示(res)。
63.在此,在用户听取输出用声音时感觉成为妨碍的周围音的音量等级中,可能存在个体差异。因此,阈值生成部615能够根据用户设定,对阈值等级(thx)加以校正。此外,在此使用阈值表格616来生成阈值等级(thx),但例如还能够使用预先决定的运算式等来生成阈值等级(thx)。
64.另外,在此使用了输入声音信号(vi)的音量等级(li)和输出声音信号(vo)的音量等级(lox)的相对比较,但根据情况,也可以使用输入声音信号(vi)的音量等级(li)的绝对比较,还可以组合使用相对比较和绝对比较。例如,在周围音非常大那样的情况下,通过仅使用了输入声音信号(vi)的音量等级(li)的绝对比较,能够判别为是周围音妨碍输出用声音的听取的状态。
65.而且,周围音判别部610、声音输入处理部611也可以设置于图2的用户状态判别部123,该用户状态判别部123判别用户的状态或者用户的周边的状态是否是适合听取输出用声音的状态。即,在图2中,为方便起见,主要在功能的观点上分成控制部125和用户状态判别部123,但控制部125能够包含用户状态判别部123的功能。另外,在硬件的观点上,例如能够通过利用cpu实施的程序处理来实现用户状态判别部123,在这个观点上,控制部125也能够包含用户状态判别部123。
66.《放音动作的控制处理[1]》
[0067]
图5是示出图3中的放音动作的控制处理的详细的处理内容的一个例子的流程图。图6是示出在图2中与声音输出有关的控制部周围的主要部分的结构例的框图。在图5中,示出在图3中在放音的中断中进行的放音动作的控制处理(步骤s110)的处理内容,示出作为其一个例子的控制处理[1]的处理内容。
[0068]
在图5中,控制部125判别在图3的步骤s103以及图4中叙述那样的音量妨碍状态(周围音妨碍输出用声音的听取的状态)是否被消除(步骤s201)。在步骤s201中音量妨碍状态被消除的情况下,如在图4中叙述那样,控制部125(具体而言是周围音判别部610)通过发行再次开始指示(res),对声音输出部指示放音的再次开始。声音输出部根据该再次开始指示(res),追溯到中断之前的部位而再次开始放音(步骤s202)。
[0069]
另外,在步骤s202中,控制部125在放音的再次开始时,附加与音量妨碍状态即将被消除之前的周围音(输入声音信号(vi))的音量等级(li)对应的延迟时间,详情在图7中后述。具体而言,例如在经过与即将成为周围音不妨碍输出用声音的听取的状态之前的输入声音信号(vi)的音量等级(li)对应的预定的期间之后,控制部125对声音输出部发行再次开始指示(res)。而且,在步骤s202中,控制部125利用基于显示部119的告知显示、或者基于振动发生部124、202、302的触感振动、或者来自声音输出部(头戴式耳机122)的发声声音,向用户通知再次开始放音的意思,并结束处理。在其以后的控制周期中,按照图3的步骤s101
→
s102
→
s103
→
s106
→
s108的流程,继续放音动作。
[0070]
另一方面,在步骤s201中依然发生音量妨碍状态的情况下,控制部125解析周围音的偏差(步骤s203),判别在周围音中是否有偏差(步骤s204)。具体而言,例如图4中的控制部125内的声音输入处理部611判别在来自第2以及第3外周音麦克风132、133的左右的输入声音信号(vi)的音量等级(li)中是否有预先决定的基准值以上的偏差。
[0071]
在步骤s204中在周围音中有偏差的情况下,控制部205使用显示部119来指示用户改变头部的朝向,并结束处理(步骤s205)。之后,如果用户改变头部的朝向,则与其相伴地,周围音的偏差变小。其结果,在接下来的控制周期中经由图3的流程而到达图4的步骤s201时,在音量妨碍状态被消除的情况下,在步骤s202中再次开始放音。
[0072]
另一方面,有时即使用户改变头部的朝向从而使周围音的偏差变得最小,也无法消除音量妨碍状态。在该情况下,控制部125从步骤s204进入到步骤s206,在步骤s206中,使用显示部119而对用户发行堵住耳朵的意思的指示,并结束处理。之后,用户例如在无论如何都想要听取输出用声音那样的情况下,以包括第2以及第3外周音麦克风132、133的方式用手来堵住耳朵。其结果,通常在接下来的控制周期中经由图3的流程而到达图4的步骤s201时,音量妨碍状态被消除,在步骤s202中再次开始放音。
[0073]
此外,在此控制部125根据由图4的周围音判别部610判别的第2以及第3外周音麦克风132、133的探测结果而间接地判别用户是否堵住耳朵,但也可以使用在图2中叙述的防音耳罩检测部134来直接地进行探测。另外,在此控制部125在步骤s204中在周围音中没有偏差的情况下发行堵住耳朵的意思的指示,但也可以与周围音有无偏差无关地(即,在步骤s201中音量妨碍状态未被消除的情况下),发行堵住耳朵的意思的指示。而且,在用户堵住耳朵时,例如也可以将用第1外周音麦克风131等探测到的周围音,调整音量后重叠到输出声音信号(vo)。在该情况下,能够防止完全听不到周围音。
[0074]
而且,在此控制部125在周围音中有偏差的情况下,对用户发行指示以使其改变头部的朝向,但此时也可以包括头部的朝向等而发行指示。具体而言,控制部125例如也可以根据第1~第3外周音麦克风131~133的探测结果来判别周围音的到来方向,通过计算来计算出从该到来方向远离那样的头部的朝向,一边与传感器设备(例如陀螺仪传感器115、地磁传感器116)协作一边引导用户转向该朝向。
[0075]
在图6中,示出与图5的步骤s202(即,放音的再次开始)关联的控制部125周围的结构例。在图6中,示出控制部125、头戴式耳机122以及声音辞典622。控制部125具备声音辅助处理部620和声音输出处理部621。在此,声音辅助处理部620以及声音输出处理部621与头戴式耳机122一起构成声音输出部602,该声音输出部602生成输出声音信号,并将生成的输出声音信号变换为输出用声音后向用户进行放音。
[0076]
声音辅助处理部620承担通过利用声音进行的与用户的对话而对用户的请求进行应答的功能,生成此时成为声音的源的声音文本数据。声音辞典622包括表示各声音的波形数据,例如保持于图2的存储器128。声音输出处理部621通过对来自声音辅助处理部620的声音文本数据合成来自声音辞典622的波形数据,生成输出声音信号(vo)。头戴式耳机122将输出声音信号(vo)变换为输出用声音后向用户进行放音。
[0077]
在此,控制部125在对声音输出部指示放音的中断之后,在图5的步骤s201中成为周围音不妨碍输出用声音的听取的状态的情况下,在步骤s202中对声音输出部602发行再次开始指示(res)。声音输出部602根据再次开始指示(res),追溯到中断之前的部位而再次开始放音。具体而言,声音输出部602例如追溯到在途中中断的句子的开头而再次开始放音,或者追溯到在途中中断的部位的跟前的标点符号或前一个短语而再次开始放音,或者仅追溯预先决定的固定的文字数、单词数而再次开始放音。
[0078]
声音辅助处理部620在生成声音文本数据的过程中,辨识句子的单位、短语的单
位、标点符号的位置等,并且将生成的声音文本数据逐次储存到缓冲器(例如图2的存储器128)。另外,声音输出处理部621也将与声音文本数据对应地生成的输出声音信号(vo)逐次储存到缓冲器。因此,声音输出部602能够根据从控制部125(图4的周围音判别部610)接受中断指示(int)的定时,辨识中断时的句子、短语、被标点符号夹持的区间等这样的中断部位。之后,声音输出部602在从控制部125(图4的周围音判别部610)接受再次开始指示(res)的情况下,能够根据辨识的中断部位,追溯到中断之前的部位而再次开始放音。
[0079]
作为具体例,设想声音输出部602对“今夜的东京地区的天气预报是阴转晴。”这样的句子进行放音的情况。声音输出部602例如在对“阴转晴”的部分正在放音时接受中断指示(int)的情况下,之后当接受再次开始指示(res)时,追溯到句子的开头而从“今夜的”的部分起再次开始放音,或者从“阴转晴”的部分起再次开始放音。
[0080]
此外,这样,放音的中断或者再次开始的控制对象例如是由于用户漏听而可能产生问题的来自声音辅助处理部620的声音等,来自音乐播放器的音乐等这样的即使用户漏听也不会特别产生问题的声音也可以不是控制对象。另外,例如根据由用户经由输入控制器400(参照图2)进行的指示,输出声音信号(vo)的音量等级(lox)会被输入到图6的声音输出部602。声音输出部602以与该音量等级(lox)对应的音量进行放音。在图4所示的周围音判别部610中也使用该音量等级(lox)。
[0081]
图7是示出在图4中在放音的再次开始时附加延迟时间时(步骤s202)的动作例的说明图。在图7中示出周围音噪声等级和输出声音信号的放音动作的关系。在图7中,控制部125在周围音噪声等级701充分低的时刻t1,开始输出声音信号的放音,与此相伴地,放音动作状态702成为开启(动作执行)。之后,周围音噪声等级701变高,在时刻t2成为与图4的阈值等级(thx)对应的第1周围音噪声等级703以上的情况下,控制部125判别为是周围音妨碍输出用声音的听取的状态,中断放音。与此相伴地,放音动作状态702成为关闭(动作停止)。
[0082]
之后,周围音噪声等级701在以第1周围音噪声等级703以上并且不超过比第1周围音噪声等级703高的第2周围音噪声等级704的状态进行了推移之后,在时刻t3小于第1周围音噪声等级703。与此对应地,控制部125并非针对声音输出部立即发行再次开始指示(res),而是在经过与紧接在时刻t3之前(即,即将成为不妨碍的状态之前)的输入声音信号的音量等级对应的预定的期间td1之后的时刻t4,发行再次开始指示(res)。在此,该输入声音信号的音量等级成为第1周围音噪声等级703以上并且第2周围音噪声等级704以下。声音输出部根据时刻t4下的再次开始指示(res)而再次开始放音,与此相伴地,放音动作状态702成为开启(动作执行)。
[0083]
之后,周围音噪声等级701在时刻t5成为第1周围音噪声等级703以上,与此相伴地,放音动作状态702成为关闭。然后,周围音噪声等级701在时刻t5~时刻t6的期间,以第2周围音噪声等级704以上并且不超过比第2周围音噪声等级704高的第3周围音噪声等级705的状态进行推移,在时刻t6小于第1周围音噪声等级703。与此对应地,控制部125针对声音输出部,在经过与紧接在时刻t6之前的输入声音信号的音量等级(即,第2周围音噪声等级704以上并且第3周围音噪声等级705以下)对应的预定的期间td2之后发行再次开始指示(res)。在此,期间td2由于对应的音量等级大于与期间td1对应的音量等级,所以比期间td1长。
[0084]
此外,在图7的例子中,周围音噪声等级701在经过预定的期间td2的时刻t8之前的
时刻t7再次变高,超过第1周围音噪声等级703。因此,不发行再次开始指示(res),声音输出部维持放音的中断状态。在时刻t7之后,周围音噪声等级701在以第3周围音噪声等级705以上的状态进行推移之后,在时刻t9小于第1周围音噪声等级703。与此对应地,控制部125针对声音输出部,在经过与紧接在时刻t9之前的输入声音信号的音量等级(即,第3周围音噪声等级705以上)对应的预定的期间td3(>td2)之后的时刻t10,发行再次开始指示(res)。声音输出部根据时刻t10下的再次开始指示(res),再次开始放音。
[0085]
一般对于用户而言,有时在大的周围音之后产生听力下降期间。周围音的音量等级越高,则该听力下降期间越长。因此,通过进行如图7所示的控制,即使根据周围音的音量等级而产生听力下降期间的变化,控制部125也能够准确地避开听力下降期间而进行放音,用户能够与周围音的音量等级无关地,在听力良好的状态下听见输出用声音。此外,在图7的例子中,示出将周围音的音量等级分成3个阶段的例子,但还能够使用分成更细致的阶段或者使预定的期间根据音量等级而连续地变化那样的方式。而且,也可以在再次开始放音动作时,进行将输出声音信号的音量等级稍微提高那样的控制。
[0086]
《放音动作的控制处理[2]》
[0087]
图8是示出图3中的放音动作的控制处理的与图5不同的详细的处理内容的一个例子的流程图。在图8中,示出在图3中在放音的中断中进行的放音动作的控制处理(步骤s110)的与图5不同的处理内容,示出作为其一个例子的控制处理[2]的处理内容。在图5中,控制部125使用户进行各种应对,从而实施针对周围音的对策,但在图8中,控制部125变更放音方法(具体而言是变更频率特性),从而不经由用户的应对而实施针对周围音的对策。
[0088]
在图8中,控制部125与图5的步骤s201的情况同样地判别音量妨碍状态是否被消除,在被消除的情况下,与图5的步骤s202的情况同样地进行放音的再次开始、延迟时间的附加以及向用户的通知。另一方面,在步骤s201中依然发生音量妨碍状态的情况下,控制部125例如使用图4的声音输入处理部611来解析与周围音对应的输入声音信号(vi)的频率特性(步骤s301)。
[0089]
接下来,控制部125根据步骤s301中的频率特性的解析结果,判别是否能够通过变更所放音的输出声音信号的频率特性来处置(步骤s302)。即,虽然在通过图9的步骤s201、图3的步骤s103来判别的音量等级这点上无法消除音量妨碍状态,但控制部125判别是否能够通过变更放音方法来消除周围音妨碍输出用声音的听取的状态。
[0090]
在步骤s302中判别为能够通过频率特性的变更来处置的情况下,控制部125在变更所放音的输出声音信号的频率特性之后(步骤s303)进入到步骤s202,进行放音的再次开始、延迟时间的附加以及向用户的通知,并结束处理。在其以后的控制周期中,按照图3的步骤s101
→
s102
→
s103
→
s104
→
s108的流程,继续进行变更了频率特性的状态下的放音动作。
[0091]
另外,在变更了该频率特性的状态下的放音动作继续的过程中,周围音的音量等级下降,在音量妨碍状态被消除的情况下,按照图3的步骤s103
→
s106
→
s107的流程来解除频率特性的变更,返回到默认的频率特性。然后,按照图3的步骤s101
→
s102
→
s103
→
s106
→
s108的流程,继续放音动作。另一方面,控制部125在步骤s302中判别为无法通过频率特性的变更(即,放音方法的变更)来处置的情况下,结束处理。其结果,中断了放音的状态持续至音量妨碍状态被消除为止。
[0092]
在此,说明步骤s301~s303中的与频率特性的变更有关的具体的方式的一个例子。首先,控制部125(例如图6的声音输出处理部621)预先具备能够应用于输出声音信号(vo)的多个频率特性(例如基频)。控制部125通过在步骤s301中解析输入声音信号的频率特性,辨识输入声音信号的频率特性(例如基频)。
[0093]
然后,控制部125对声音输出部621发行指示使其从能够应用于输出声音信号(vo)的多个频率特性中选择与输入声音信号的频率特性的类似度比预先决定的基准值低的频率特性(步骤s303)。具体而言,控制部125例如使声音输出部621选择从输入声音信号的基频偏离基准值以上的输出声音信号(vo)的基频。
[0094]
这样,通过变更输出声音信号的频率特性,即使在存在大到某种程度的周围音的情况下,用户也能够充分地听到所放音的输出声音信号。但是,在能够应用于输出声音信号的多个频率特性之中不存在与输入声音信号的频率特性的类似度比基准值低的频率特性的情况下,在步骤s302中判别为无法通过频率特性的变更来处置,不进行放音的再次开始等。
[0095]
此外,控制部125例如能够根据设定来选择性地执行图8所示的控制处理[2]和图5所示的控制处理[1]中的任一方、或者在图8所示的控制处理[2]之后执行图5所示的控制处理[1]。具体而言,控制部125例如在图8的步骤s302中判别为无法通过频率特性的变更来处置的情况下,执行图5的控制处理[1]而向用户请求预定的应对即可。
[0096]
《放音动作的控制处理[3]》
[0097]
图9是示出图3中的放音动作的控制处理的与图8不同的详细的处理内容的一个例子的流程图。在图9中,示出使图8的控制处理[2]变形得到的控制处理[3]的处理内容。在图9中,与图8的情况同样地,控制部125变更放音方法,从而不经由用户的应对而实施针对周围音的对策,但与图8的情况不同,通过变更所放音的输出用声音的声像来实施对策。
[0098]
在图9中,图8中的步骤s301~s303的处理被置换为步骤s401~s403的处理。在图9中,在步骤s201中音量妨碍状态未被消除的情况下,控制部125解析周围音的音源位置(步骤s401)。具体而言,控制部125例如使用图4的声音输入处理部611,根据来自第2以及第3外周音麦克风132、133的左右的输入声音信号(vi)的音量等级、延迟差等来判别周围音的音源位置。
[0099]
接下来,控制部125根据步骤s401中的周围音的音源位置的解析结果,判别是否能够通过变更所放音的输出用声音的声像来处置(步骤s402)。即,控制部125判别是否能够通过变更放音方法来消除周围音妨碍输出用声音的听取的状态。在步骤s402中判别为能够通过输出用声音的声像的变更来处置的情况下,控制部125在变更输出用声音的声像之后(步骤s403)进入到步骤s202,进行放音的再次开始、延迟时间的附加以及向用户的通知,并结束处理。另一方面,控制部125在步骤s402中判别为无法通过输出用声音的声像的变更来处置的情况下,结束处理。
[0100]
在步骤s403中,具体而言,控制部125指示声音输出部以使输出用声音的声像的位置从周围音的音源的位置偏离预先决定的基准值以上的方式生成左右的输出声音信号。与此对应地,例如图6的声音输出处理电路621通过控制左右的输出声音信号的音量等级、延迟差等来控制从左右的头戴式耳机122a、122b放音的输出用声音的声像。此时,例如在周围音的音源位置是左斜前方的情况下,输出用声音的声像位置被决定为右斜后方等。
[0101]
这样,通过变更输出用声音的声像,即使在存在大到某种程度的周围音的情况下,用户也能够充分地听取所放音的输出用声音。另外,控制部125在步骤s402中判别为无法通过输出用声音的声像的变更来处置的情况下,具体而言在无法作出从周围音的音源的位置偏离基准值以上的声像的位置的情况下,结束处理。其结果,中断了放音的状态持续至音量妨碍状态被消除为止。
[0102]
此外,控制部125例如能够根据设定来选择性地执行图9所示的控制处理[3]和图8所示的控制处理[2]中的任一方、或者在图8所示的控制处理[2]之前或之后且在图5所示的控制处理[1]之前执行图9所示的控制处理[3]。具体而言,控制部125例如在图9的步骤s402和图8的步骤s302这两方中判别为无法通过放音方法的变更来处置的情况下,执行图5的控制处理[1]而向用户请求预定的应对即可。
[0103]
《控制部的其它动作》
[0104]
作为其它动作例,控制部125也可以在周围音妨碍输出用声音的听取的状态的情况下,指示声音输出部在所生成的输出声音信号的开头插入表示引导用户的意识的语言的固定的输出声音信号并放音。具体而言,控制部125例如在图3的步骤s105中通过声音向用户进行通知的情况、在图8或图9中变更放音方法之后再次开始放音的情况下等,发行这样的指示。这样,通过将引导用户的意识的语言放入到输出声音信号的开头,从而周围音增加,能够使用户明确地意识到难以听到所放音的输出用声音并提醒注意,另外通过鸡尾酒会效应(cocktail party effect)的选择性注意,还有容易听见所放音的声音的效果。作为引导用户的意识的语言,例如可以列举预先登记到装置的用户的名字等。
[0105]
而且,作为其它动作例,控制部125也可以在周围音妨碍输出用声音的听取的状态的情况下,以在显示部119中对来自头戴式信息处理装置内部的输出声音信号进行文字显示来代替对输出用声音进行放音的方式,进行切换处理。此时,控制部125与放音的再次开始时同样地,追溯到中断之前的部位而进行文字显示。由此,头戴式信息处理装置虽然无法经由听觉向用户传达预定的信息,但能够经由视觉向用户传达预定的信息。
[0106]
《实施方式1的主要的效果》
[0107]
以上,通过使用实施方式1的头戴式信息处理装置,代表性地即使存在对于用户不必要的周围音,也能够使用户准确地听取期望的声音。另外,即使存在对于用户而言不必要的周围音,也能够使用户顺利地听取期望的声音。
[0108]
在详细说明时,在产生大的周围音并进入耳朵而听不到来自头戴式信息处理装置内部的输出声音信号的放音的状态下,通过中断放音,能够防止用户漏听输出用声音。另外,在周围音变小而成为不妨碍输出用声音的听取的状态时,通过追溯到中断之前的部位而再次开始放音,用户不会漏听输出用声音并且能够顺利地听取输出用声音。特别是,能够使用户准确地完全听取如来自声音辅助部的输出用声音那样漏听可能成为问题的声音。
[0109]
另外,即使在由于大的周围音进入到耳朵而耳朵的听力短暂下降的情况下,通过等待听力恢复所需的时间后再次开始放音,从而用户能够准确地顺利听取期望的声音。而且,根据需要,针对输出用声音进行频率特性的变更、声像的变更这样的放音方法的变更、或者向用户请求进行堵住耳朵等的应对,从而在依然存在周围音的状况下用户能够准确地顺利听取期望的声音。另外,在放音的中断时、再次开始时,利用显示、声音、振动向用户进行通知,从而用户的可用性得到提高。
[0110]
此外,在此根据周围音进行放音动作的控制,但根据头戴式信息处理装置的目录内容,有时用户不希望进行这样的放音动作的控制。因此,例如用户也可以针对头戴式信息处理装置主体100,按照每个目录来设定是否进行放音动作的控制。头戴式信息处理装置主体100也可以根据该用户设定,按照每个目录来选择是否进行放音动作的控制。
[0111]
(实施方式2)
[0112]
《控制部的详情》
[0113]
在实施方式2中,与在实施方式1中叙述的周围音的状态不同,控制部125反映用户的状态(例如身心状态等)或者用户的周边的状态(例如危险的状况的发生等)来控制放音动作。概要而言,在图2中,头戴式信息处理装置主体100内的传感器设备151、各穿戴式终端200、300内的传感器设备探测用户的状态或者用户的周边的状态。
[0114]
用户状态判别部123根据该传感器设备的探测结果,判别用户的状态或者用户的周边的状态是否是适合听取输出用声音的状态。控制部125根据用户状态判别部123的判别结果,在适合听取输出用声音的状态的情况下使声音输出部(头戴式耳机122等)进行放音,在不适合听取输出用声音的状态的情况下对声音输出部指示放音的中断。以下,对其详情进行说明。
[0115]
图10是示出在本发明的实施方式2所涉及的头戴式信息处理装置中图2的控制部的详细的处理内容的一个例子的流程图。控制部125以预定的控制周期,重复执行图10所示的流程。在图10中,控制部125使用用户状态判别部123,通过各种传感器设备来探测用户的状态或者用户的周边的状态(步骤s501)。
[0116]
接下来,控制部125判别声音输出部(头戴式耳机122等)是否对输出用声音正在放音(步骤s502)。在步骤s502中对输出用声音正在放音的情况下,控制部125根据步骤s501的探测结果,使用用户状态判别部123来判别用户的状态或者用户的周边的状态是否是适合听取输出用声音的状态(步骤s503)。在说明书中,将用户的状态或者用户的周边的状态不适合听取输出用声音的状态还称为用户不适状态。
[0117]
在步骤s503中发生用户不适状态的情况下,控制部125对声音输出部指示放音的中断(步骤s504)。而且,在步骤s504中,控制部125利用基于显示部119的告知显示、或者基于振动发生部124、202、302的触感振动、或者基于声音输出部(头戴式耳机122)的发声声音,向用户通知中断放音的意思,并结束处理。另一方面,在步骤s503中未发生用户不适状态的情况下,控制部125继续利用声音输出部进行放音,结束处理(步骤s505)。
[0118]
在步骤s502中并非是对输出用声音正在放音的情况下,控制部125判别对于声音输出部的放音是否为中断中(步骤s506)。在步骤s506中对于放音并非是中断中的情况下,控制部125结束处理。另一方面,在步骤s506中对于放音是中断中的情况下,控制部125判别用户不适状态是否被消除(步骤s507)。
[0119]
在步骤s507中用户不适状态被消除的情况(即,成为适合听取输出用声音的状态的情况)下,与在图4中叙述的实施方式1的情况同样地,控制部125通过发行再次开始指示(res),对声音输出部指示放音的再次开始。声音输出部根据该再次开始指示(res),追溯到中断之前的部位而再次开始放音(步骤s508)。另外,在步骤s508中,控制部125利用基于显示部119的告知显示、或者基于振动发生部124、202、302的触感振动、或者来自声音输出部(头戴式耳机122)的发声声音,向用户通知再次开始放音的意思,并结束处理。在其以后的
控制周期中,按照图10的步骤s501
→
s502
→
s503
→
s505的流程,继续放音动作。
[0120]
《用户不适状态的详情》
[0121]
图11是说明在图10中用户不适状态的一个例子的图。在图11中,示出在图10的步骤s503、s507中判别为发生用户不适状态的状况的具体例,在此示出7种状况(1)~(7)。状况(1)是视为用户注视着显示部119中的虚拟现实(vr)空间信息或者增强现实(ar)空间信息的状况。
[0122]
具体而言,用户状态判别部123例如在步骤s501中根据右眼视线传感器112以及左眼视线传感器113来探测用户的视线的位置,进而从图2的虚拟空间信息生成处理部141、照相机11得到虚拟空间信息、现实空间信息的显示位置。然后,用户状态判别部123判别用户的视线的位置与虚拟空间信息、现实空间信息的显示位置一致的时间比率是否为预定的基准值以上。在一致的时间比率是预定的基准值以上的情况下,用户状态判别部123视为用户注视着虚拟空间信息或者现实空间信息,在步骤s503、s507中判别为是不适合听取输出用声音的状态(换言之发生用户不适状态)。
[0123]
状况(2)是视为用户进行快速的眼球运动的状况。具体而言,用户状态判别部123根据步骤s501中的各视线传感器112、113的探测结果,例如判别预定时间内的用户的视线的变动次数是否为预定的基准值以上。一般而言,人在使视线从某个视点移动到分离的其它视点时,引起被称为扫视的眼球的快速的转动,在此,判别有没有发生该扫视。用户状态判别部123在用户的视线的变动次数是预定的基准值以上的情况下视为发生扫视,在步骤s503、s507中判别为是不适合听取输出用声音的状态。
[0124]
状况(3)是视为用户漫不经心的状况。具体而言,用户状态判别部123根据步骤s501中的各视线传感器112、113的探测结果,例如判别预定时间内的用户的视线的变动次数是否为预定的基准值以下。在用户的视线的变动次数是预定的基准值以下的情况下,用户感觉困倦而不具有清楚的意识,视为漫不经心。在用户漫不经心的情况下,用户状态判别部123在步骤s503、s507中判别为是不适合听取输出用声音的状态。
[0125]
状况(4)是用户的头部大幅地活动的状况。具体而言,用户状态判别部123根据步骤s501中的加速度传感器114、陀螺仪传感器(角速度传感器)115或者地磁传感器116的探测结果,例如判别用户的头部是否按照预定的基准速度以上而进行了预定的基准量以上的活动。在用户的头部大幅地活动的情况下,例如有可能危险逼近用户等在用户的周边的外部环境中发生某种异常情况,用户的视觉或者听觉上的注意转向那里。在用户的头部大幅地活动的情况下,为了不妨碍用户的注意力集中,用户状态判别部123在步骤s503、s507中判别为是不适合听取输出用声音的状态。
[0126]
状况(5)是发生了用户的急剧的身体状况变化的状况。具体而言,用户状态判别部123根据步骤s501中的心跳传感器201、血压传感器301的探测结果,例如判别用户的心率或者血压的时间变化率(例如增加率)是否为预先决定的基准值以上。在心率、血压急剧上升的情况下,有可能用户的身心状态发生急剧的异常情况,用户无法注意到听觉。在发生了用户的身体状况变化的情况下,用户状态判别部123在步骤s503、s507中判别为是不适合听取输出用声音的状态。
[0127]
此外,在图1、图2中,利用能够最准确地探测的与胸部密接的胸部佩戴型穿戴式终端200的心跳传感器201来探测心率,利用能够容易地探测的与腕部密接的腕带型穿戴式终
端300的血压传感器301来探测血压。但是,心跳、血压并不特别限定于此,例如也可以通过通信从ai(artificial intelligence,人工智能)手表等取得。另外,取得的信息不限于心率、血压,只要是能够对用户的身心状态进行检测的生物体信息即可。
[0128]
状况(6)是用户与其他人正在对话的状况。具体而言,用户状态判别部123在步骤s501中,通过第1外周音麦克风131、发音麦克风121来探测声音,通过各视线传感器112、113来探测眼球的活动。用户状态判别部123根据探测到的声音以及眼球运动,判别用户的意识在哪,判别是否与其他人面对面正在对话或者用电话正在对话。此时,用户状态判别部123既可以根据照相机11的摄像结果来辨别其他人的存在,另外如果在头戴式信息处理装置主体100中搭载有电话功能,则也可以据此来辨识利用电话进行的对话。在用户与其他人正在对话的情况下,用户状态判别部123在步骤s503、s507中判别为是不适合听取输出用声音的状态。
[0129]
状况(7)是在用户的周围存在接近物体的状况。具体而言,用户状态判别部123在步骤s501中,根据周边物体探测传感器118的探测结果来探测与在用户的周围存在的车、人、动物等这样的物体的距离、相对速度,从而探测接近的物体是否存在于用户的周围的一定范围内。
[0130]
用户状态判别部123在接近的物体存在于用户的周围的一定范围内的情况下,视为用户的视觉或者听觉上的注意转向物体,在步骤s503、s507中判别为是不适合听取输出用声音的状态。另外,在该步骤s503、s507时,在用户状态判别部123根据周边物体探测传感器118判别为是不适合听取输出用声音的状态的情况下,控制部125指示声音输出部向用户发出表示危险的警告音。
[0131]
此外,用户状态判别部123例如也可以将对接近物体进行探测的范围决定为位于用户周围的危险范围以及位于比危险范围靠外侧的范围的注意范围这2个阶段。在接近物体存在于注意范围的情况下,控制部125例如以从与接近物体存在的方向相反的方向对输出用声音进行放音的方式进行控制,通过显示、声音、振动来通知放音动作。在该情况下,在接近物体存在于注意范围的情况下,用户能够在由来自接近物体的声音引起的妨碍噪声被降低的状态下收听输出用声音。相反地,控制部125也可以以从存在接近物体的方向对输出用声音进行放音的方式进行控制。在该情况下,用户容易辨识接近物体的方向。
[0132]
如以上那样,用户状态判别部123判别用户的状态或者用户的周边的状态是否为适合听取输出用声音的状态(换言之是否未发生用户不适状态)。根据其判别结果,控制部125在适合听取输出用声音的状态的情况(未发生用户不适状态的情况)下使声音输出部进行放音,在不适合听取输出用声音的状态的情况(发生用户不适状态的情况)下对声音输出部指示放音的中断。
[0133]
另外,作为用户不适状态的其它例子,用户状态判别部123也可以使用对用户的周边的温度、湿度进行探测的温度湿度传感器117,判别是否发生用户不适状态。具体而言,用户状态判别部123也可以在温度、湿度的时间变化率是基准值以上的情况下判别为发生了用户不适状态。另外,作为对用户的周边的状态进行探测的传感器设备,不限于温度湿度传感器117,还能够使用探测气压的气压传感器等。
[0134]
《实施方式2的主要的效果》
[0135]
以上,通过使用实施方式2的头戴式信息处理装置,代表性地是能够反映用户的状
态、用户的周边的状态,使用户准确地听取期望的声音。另外,能够反映用户的状态、用户的周边的状态,使用户顺利地听取期望的声音。
[0136]
在详细说明时,即使从用户有放音动作的请求,如图11的状况(1)~(7)所示,在用户的状态、用户的周边的状态是不适合听取输出用声音的状态的情况下,以中断放音动作的方式进行控制。由此,用户能够不遗漏而准确地听取输出用声音。另外,之后在用户的状态、用户的周边的状态成为适合听取输出用声音的状态的情况下,与实施方式1的情况同样地,追溯到中断之前的部位而再次开始放音。由此,用户能够准确地听取输出用声音,并且能够顺利地听取输出用声音。
[0137]
另外,与实施方式1的情况同样地,在中断放音动作时或再次开始放音动作时,将其意思通知给用户,从而用户的可用性得到提高。而且,关于状况(7),根据接近物体的程度来控制放音动作,从而用户更容易听取输出用声音。此时,在由于接近物体而用户发生危险的情况下,以对于注意提醒、警告以外的辅助声音不放音的方式进行控制,从而能够在确保用户的安全性的同时,使用户准确地听取期望的声音。
[0138]
此外,例如在状况(3)中叙述那样,在视为用户漫不经心的状况下,头戴式信息处理装置主体100也可以进行向用户的眼睛提供光或者在用户的视场内显示闪烁的2个以上的光等处理。由此,用户成为大脑被唤醒而意识清楚的清醒状态,控制部125经由用户状态判别部123来探测该清醒状态,从而能够再次开始放音动作。
[0139]
(实施方式3)
[0140]
《头戴式信息处理装置的概略》
[0141]
图12是示出本发明的实施方式3所涉及的头戴式信息处理装置的概略结构例的框图。图12所示的头戴式信息处理装置相比于图2所示的结构例,是将图2的头戴式信息处理装置主体100内的虚拟空间信息生成处理部141分离到头戴式信息处理装置主体100的外部而设为独立装置的结构例。
[0142]
在图12中,虚拟空间信息生成服务器500生成虚拟空间信息等,经由外部网络600而与头戴式信息处理装置主体100之间发送接收所生成的虚拟空间信息等。头戴式信息处理装置主体100具备发送接收天线1201以及通信部1202,发送接收来自虚拟空间信息生成服务器500的虚拟空间信息等。
[0143]
虚拟空间信息生成服务器500具备虚拟空间信息生成处理部501、存储器502、控制部503、通信部504以及发送接收天线505,它们经由总线506而相互连接。虚拟空间信息生成处理部501生成利用影像、声音来表现与现实空间不同的虚拟空间的虚拟空间信息。存储器502是闪存存储器等,存储有由虚拟空间信息生成处理部501生成的虚拟空间信息、控制部503使用的各种程序等。通信部504是经由发送接收天线505并通过外部网络600而与头戴式信息处理装置主体100进行通信的通信接口。
[0144]
如以上那样,使用与头戴式信息处理装置主体100分离的另外的服务器装置来生成虚拟空间信息,头戴式信息处理装置主体100通过通信来取得该虚拟空间信息,从而能够使虚拟空间的信息量大规模化。另外,能够减少头戴式信息处理装置主体100的硬件资源以及软件资源。
[0145]
此外,也可以针对图2、图12所示的结构例,将胸部佩戴型穿戴式终端200内的心跳传感器201、腕带型穿戴式终端300内的血压传感器301、输入控制器400内的输入操作部401
嵌入到头戴式信息处理装置主体100内。心跳传感器201能够在与头部密接地佩戴的状态下探测心率,血压传感器301也能够在与头部密接地佩戴的状态下利用头皮正下方的头部动脉来探测血压值。
[0146]
另外,输入操作部401设置于在头戴式信息处理装置主体100内用户易于进行输入操作的位置即可。或者,也可以由用户发出表示输入操作的声音,并利用发音麦克风121来集音而取入输入操作信息。另外,既可以使显示部119显示输入操作画面,根据由各视线传感器112、113探测的视线朝向的输入操作画面上的位置而取入输入操作信息,也可以使指针显示于输入操作画面上并通过手的动作等进行指定而取入输入操作信息。通过在输入操作中利用发声、显示,能够进一步提高可用性。
[0147]
此外,本发明不限于上述实施方式,包括各种变形例。例如,上述实施方式是为了易于理解地说明本发明而详细说明的例子,未必限定于具备所说明的所有结构。另外,能够将某个实施方式的结构的一部分置换为其它实施方式的结构,另外还能够对某个实施方式的结构添加其它实施方式的结构。另外,能够针对各实施方式的结构的一部分,进行其它结构的追加、删除、置换。
[0148]
另外,关于上述的各结构、功能、处理部、处理单元等,也可以通过例如用集成电路进行设计等而用硬件来实现它们的一部分或者全部。另外,关于上述的各结构、功能等,也可以通过处理器解释并执行实现各个功能的程序而用软件来实现。实现各功能的程序、表格、文件等信息能够设置到存储器、硬盘、ssd(solid state drive,固态驱动器)等记录装置、或者ic卡、sd卡、dvd等记录介质。
[0149]
另外,关于控制线、信息线,示出认为在说明上必要的部分,在产品方面未必示出所有的控制线、信息线。也可以认为实际上几乎所有的结构相互连接。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。