用于人工神经网络的光子张量加速器
1.相关申请的交叉引用
2.本技术与2019年5月3日提交的,名称为“用于人工神经网络的光子张量加速器
””
的美国临时专利申请no.62/842,771(美国代理人檔号:ucf34129prov)相关,并要求其优先权,该美国临时专利申请被转让予本案申请人,其中的全部内容通过引用并入本文。
背景技术:
3.本技术总体上涉及光学计算,更具体地涉及用于矢量
‑
矢量、矩阵
‑
矢量、矩阵
‑
矩阵、批(batch)矩阵
‑
矩阵和张量
‑
张量乘法的光子加速。
4.本技术包括在括号中用数字表示的参考文献,例如[x],其中x是数字。参考文献的数字列表可在本技术的末尾找到。此外,这些参考文献在与本案一起提交的信息公开声明(ids)中列出。这些列出的参考文献中的每一个的教导的全部内容通过引用并入本文。
[0005]
到目前为止,电子学和光子学大体上已经在信息化社会中发挥了各自的技术作用。由于电子的费米子性质,电子技术已经主导了信息生成和处理技术。类似地,由于光子的玻色子性质,即使在激光和光纤发明之前电子技术也主导了通信技术,但近几十年来,光子技术仍主导着信息传输技术。如长久以来所预期的,根据摩尔定律,电子集成电路(ic)的处理能力迟早将无法增长。这种预期激发了光学和光子学界在过去的半个世纪中不断地探索光学和光子信息处理的问题。这些努力包括用于通用光学计算的光学晶体管[1]、[2]和逻辑门[3]、[4],以及用于专用信息处理的傅里叶光学[5]。然而,到了1980年代末,光学技术在计算中的职能被过誉的错误已经使该领域倒退了好几次,并在随后的二十年中使该领域几乎处于休眠状态[6]。
[0006]
近年来,ic确实地根据摩尔定律不能维持几何级数的增长,这主要是因为与增加时钟速率所需的小器件相关的高密度功耗的热量难以消散。因此,ic在计算能力方面的扩缩性的限制因素不是总功率而是功率密度。在后摩尔定律时代,行内对扩缩性问题的解决方案是,与单个cpu的冯诺依曼结构相比,构建具有并行计算结构和用于特定计算目的的优化本地存储器的硬件加速器[7]、[8],例如图形处理单元(gpu)和张量处理单元(tpu)。受益于这些硬件加速器,基于使用人工神经网络(ann)实现的人工智能(ai)/机器学习(ml)的新应用在学术界、工业和一般社会上的几乎每个角落都激增,尽管原始ic的处理能力仍然停滞。
技术实现要素:
[0007]
本发明是一种用于矢量
‑
矢量乘法、矩阵
‑
矢量乘法、矩阵
‑
矩阵乘法、批矩阵
‑
矩阵乘法和张量
‑
张量乘法的光子单元。在矢量
‑
矢量相乘的情况下,光子设备包括第一光多路复用器,其接收代表第一矢量的第一光信号,其中,第一矢量中的每个元素在光的第一自由度(dof)/维度上被编码,并且在一个乘法周期中是非时间的,以产生第一多路复用光信号。光子单元包括第二光多路复用器,其接收与第一光信号相干(coherent)的第二光信号,第二光信号表示第二矢量,其中第二矢量中的每个元素,以与映射为第一矢量相同的光映射
的元素
‑
正交自由度(dof)/维度被编码,以产生第二多路复用光信号。光子单元还包括光束组合器,其接收来自第一光多路复用器的第一多路复用光信号和来自第二光多路复用器的第二多路复用光信号,以便将它们组合以在第一光信号和第二光信号之间产生干涉,该干涉包含第一矢量和第二矢量在总干涉强度中的相乘结果。这种累加不需要整个dof,而是需要dof中尚未用于编码的特定点或参数。
[0008]
在具有m
×
1矢量乘法的n
×
m矩阵的情况下,光子单元包括第一光多路复用器,其接收至少第一光信号,该第一光信号表示具有m个元素的至少一个m
×
1矢量,其中m
×
1矢量中的每个元素在光的第一正交自由度(dof)/维度上被编码,并且在一个乘法周期中是非时间的,以产生第一多路复用光信号,并且其中m是大于或等于1的正整数。光子单元包括光学复制器,其用于将表示m
×
1矢量的至少第一光信号复制为在光第二正交自由度(dof)/维度上的n个附加光信号中的n个副本,其中n是大于或等于1的正整数。光子单元还包括n个光多路复用器,在光的第二正交自由度(dof)/维度中,其与光学复制器相同,每个光多路复用器接收m个附加光信号,其中m个附加光信号中的每一个与第一光信号相干(coherent),n个附加光信号中的每一个表示m
×
n矩阵的一独立行,其中,m
×
n矩阵的行中的每个元素,以与映射为表示m
×
1矢量的第一光信号相同的光映射的元素
‑
正交自由度(dof)/维度被编码,以产生n个附加多路复用光信号。光子单元还包括至少一个光束组合器,其接收来自第一光多路复用器的第一多路复用光信号和来自n个光多路复用器的n个附加多路复用光信号的n个副本,以便将它们组合以在第一光信号和n个附加光信号中的每一个之间产生n次干涉,n次干涉包含m
×
n矩阵和m
×
1矢量在n个总干涉强度中的相乘结果。
[0009]
在具有m
×
w矩阵乘法的n
×
m矩阵的情况下,光子单元包括在光的第一正交自由度(dof)/维度中的第一组n个光多路复用器,其接收n个光信号,其中n个光信号中的每一个表示n
×
m矩阵具有m个元素的一独立行,其中,n
×
m矩阵的每个独立行中的每个元素在光的第二正交自由度(dof)/维度上被编码,并且在一个乘法周期中是非时间的,以产生n个多路复用光信号,并且其中,m和n各自是大于或等于1的正整数。光子单元包括第一光学复制器,用于将表示n
×
m矩阵的多个独立行的n个多路复用光信号中的每一个复制为光的第三正交自由度(dof)/维度中的w个副本,其中w是大于或等于1的正整数。光子单元还包括在光的第三正交自由度(dof)/维度中的第二组w个光多路复用器,其与接收w个附加光信号的第一光学复制器相同,其中w个附加光信号中的每一个与n个光信号相干(coherent),w个附加光信号中的每一个表示m
×
w矩阵的具有m个元素的一独立列,其中,m
×
w矩阵的每个独立列中的每个元素,以与映射为n
×
m矩阵的每个独立行中的每个元素相同的光映射的元素
‑
正交自由度(dof)/维度被编码,以产生w个附加的多路复用光信号。光子单元包括第二光学复制器,用于将表示m
×
w矩阵的独立列的w个多路复用信号中的每一个复制为光的第一正交自由度(dof)/维度中的n个副本,其与第一组n个光多路复用器相同。光子单元还包括至少一个光束组合器,光束组合器接收两组n
×
w多路复用光信号,所述两组n
×
w多路复用光信号表示n
×
m矩阵和m
×
w矩阵中的每一个的适当复制的行或列,以便将它们组合以在n
×
m矩阵的每一行与m
×
w矩阵的列之间产生n
×
w次干涉,其中包含n
×
w总干涉强度的相乘结果。
[0010]
在b批矩阵,即多个n
×
m矩阵,
×
(m
×
w矩阵)的情况下,光子单元包括在光的第一正交自由度(dof)/维度中的第一组n个光多路复用器,其用于接收n个光信号,其中n个光信号中的每一个表示第一个m
×
n矩阵中具有m个元素的一独立行,其中第一个m
×
n矩阵的每
个独立行中的每个元素在光的第二正交自由度(dof)/维度上被编码,并且在一个乘法周期中是非时间的,以产生n个多路复用光信号,并且其中m和n各自为大于或等于1的正整数。光子单元包括第一光学复制器,用于将表示第一个n
×
m矩阵的多个独立行的n个多路复用光信号中的每一个复制为多个n
×
m矩阵的光的第三正交自由度(dof)/维度中的w个副本,其中w是大于或等于1的正整数。光子单元包括在光的第四正交自由度(dof)/维度中的第二多路复用器,其接收b个光信号,每个光信号包含n个多路复用光信号的在第三正交自由度(dof)/维度中的w个副本,n个多路复用光信号表示b
×
n
×
m矩阵之一的多个独立行,其中b是大于或等于1的正整数。光子单元包括在光的第三正交自由度(dof)/维度中的第三组w个光多路复用器,其与接收w个附加光信号的第一光学复制器所使用的相同,其中w个附加光信号中的每一个与n个光信号相干(coherent),w个附加光信号中的每一个表示多个m
×
w矩阵中每一个中具有m个元素的一独立列,其中,m
×
w矩阵的每个独立列中的每个元素,以与映射为多个n
×
m矩阵中的每一个矩阵的每个独立行中的每个元素相同的光映射的元素
‑
正交自由度(dof)/维度被编码,以产生w个附加的多路复用光信号。光子单元包括第二光学复制器,用于将w个多路复用信号中表示m
×
w矩阵的独立列的每一个多路复用信号复制为光的第一正交自由度(dof)/维度中的n个副本,其与第一组n个光多路复用器相同。光子单元包括在光的第四正交自由度(dof)/维度中的第三光学复制器,其产生b个相同的光信号,每个光信号包含表示m
×
w矩阵中的每个矩阵的独立列的w个复用信号的在第一正交自由度(dof)/维度中的n个副本。光子单元包括至少一个光束组合器,其从第二多路复用器和第三光学复制器接收两组b
×
n
×
w的多路复用光信号,以将它们组合以产生n
×
w次的干涉,其包含在n
×
w的总干涉强度中b个不同的n
×
m矩阵与相同的m
×
w矩阵的乘积的总和。
[0011]
在两个张量相乘的情况下,其中第一张量具有秩(rank)p并且第二张量具有秩(rank)q,第一张量的形式是[n1,n2,...,n
p
‑1,m],第二张量的形式是[m,w1,...,w
q
‑1]。n1,n2,...,n
p
‑1,m,w1,...,w q
‑1各自是大于或等于1的正整数。光子单元将第一张量的元素从第一秩到第p秩分别编码到第一到第p正交自由度(dof)/维度上。光子单元包括第一组光学复制器,用于将表示张量的多路复用光信号在光的第(p 1)到第(p q)正交自由度/维度上复制为w1×
w2×
...w
q
‑1个副本。光子单元也将第二张量的元素从第一秩到第q秩分别编码到第p到第(p q
‑
1)正交自由度(dof)/维度上,并且具有与映射为第一张量的第(p 1)到第(p q)正交自由度(dof)/维度的副本相同的光映射的元素
‑
正交自由度(dof)/维度。光子单元包括第二组光学复制器,用于将表示第二张量的多路复用信号复制为光的第一至第(p
‑
1)正交自由度(dof)/维度中的n1×
n2×
...
×
n
p
‑1个副本,其与光映射为第一张量的第一至第(p
‑
1)正交自由度(dof)/维度的光映射的元素
‑
正交自由度(dof)/维度相同。光子单元包括至少一个光束组合器,其从所述第一组和第二组光学复制器接收两组[n1,n2,...,n
p
‑1,m,w1,...,w
q
‑1]多路复用光信号,以将它们组合以产生[n1,n2,...,n
p
‑1,w1,...,w
q
‑1]次干涉,该干涉包含在干涉強度中n1×
n2×
...
×
n
p
‑1×
w1×
...
×
w
q
‑1个不同的m元素矢量
‑
矢量乘法的乘积的总和。
[0012]
上述任何矢量
‑
矢量、矩阵
‑
矢量、矩阵
‑
矩阵、批矩阵
‑
矩阵和张量
‑
张量乘法的干涉信号通常进入非线性光学元件,或者总干涉强度会转换成电信号,该电信号进入非线性电子元件。
[0013]
在一个示例中,编码或复制使用波长、空间模式、偏振、正交和波矢量的分量中的
至少一个。空间模式可以是厄米
‑
高斯(hg)模式、拉盖尔
‑
高斯(laguerre
‑
gaussian)模式或形成空间正交基的离散空间样本中的一种。
[0014]
在另一示例中,编码或复制使用由光的两个或更多个自由度(dof)/维度的组合组成的超维度。
[0015]
在另一示例中,对于编码或复制,至少两个光的正交自由度(dof)/维度是光的维度或超维度的非重叠子集。
附图说明
[0016]
当结合附图阅读时,通过参考说明性实施例的以下详细描述,将最好地理解本发明以及其优选使用模式及其进一步的目的和优点,其中:
[0017]
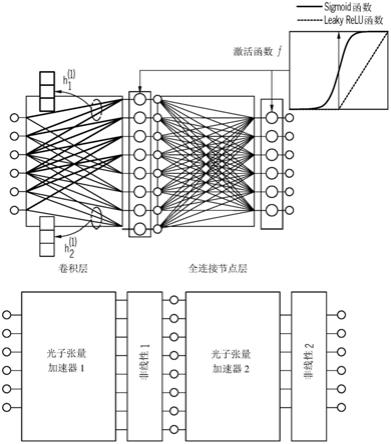
图1是具有卷积隐藏层和全连接输出层的人工神经网络的示意图,以及示出了本发明的光子张量加速器在人工神经网络的实施方式中的功能的示意图;
[0018]
图2a是矩阵乘法被約化为乘法
‑
累加运算并且使用图2b中所示的cpu、图2c中所示的gpu和图2d中所示的tpu实现的示意图,其具有更高的并行度并提高了存储器访问的能量效率;
[0019]
图3是电子加速器和光子加速器的性能比较表;
[0020]
图4a是基于波长编码的光子矩阵加速器的节点层的示意图;
[0021]
图4b是基于模式编码的光子矩阵加速器的节点层的示意图;以及
[0022]
图5是矩阵
‑
矩阵乘法的映射方案的示意图。
具体实施方式
[0023]
非限制性定义
[0024]
术语“光束组合器”是允许相干光束彼此干涉的装置。它可以通过但不限于反射光学器件、折射光学器件、衍射光学元件、光纤器件或这些组件的组合来实现。
[0025]
术语“分束器”是可以将传播的光束分成两个或更多个路径的装置。它可以通过但不限于反射光学器件、折射光学器件、衍射光学元件、光纤器件或这些组件的组合来实现。
[0026]
术语“光映射的元素到正交(element
‑
to
‑
orthogonal)自由度(dof)/维度”是矩阵或矢量元素与光的独立参数(包括波长、空间模式、偏振、正交(quadrature)和波矢量的分量)之间的对应关系。
[0027]
术语“超维度”是指由光的两个或更多个自由度(dofs)/维度的组合组成。
[0028]
术语“维度或超维度的子集”是指光的一个自由度(dof)/维度或光的一个超维度中的独立参数的子集。
[0029]
术语“光”是电磁辐射,其包括光谱的可见部分和不可见部分。
[0030]
术语“乘法周期”是指在在单个计算周期内包括的数学乘法运算。
[0031]
术语“光束复制器”是一种产生入射光的两个或更多个副本的设备,两个或更多个副本具有与入射光相同的一个或多个指定参数,包括波长、空间模式、偏振、正交和波矢量。光束复制器可以通过但不限于反射光学器件、折射光学器件、衍射光学元件、光纤器件或这些组件的组合来实现。
[0032]
背景
[0033]
电子硬件加速器(tpu和gpu)发挥的重要作用清楚地表明,人工神经网络的未来发展取决于软件和硬件的进步。然而,当前,电子硬件加速器在扩缩性方面已经达到了极限。在这种背景下,人们在探索光学在计算中的作用方面进行了新的努力[17],包括将光学互连发展到越来越短的长度尺度,并展示了新的计算范式,例如光学神经形态计算[18]
‑
[23]和光学储层计算[24]
‑
[30]。人工神经网络和深度神经网络(dnn)的三个主要构建基块是:
[0034]
1.互连,
[0035]
2.矩阵
‑
矢量和矩阵
‑
矩阵乘法,以及
[0036]
3.非线性。
[0037]
因为光学和光子学实现前两个功能跟电子学一样好(如果不比电子学好的话);并且在每个神经元级别而非逻辑级别上的光学非线性实际上是相当实用的,因此,现在正是探索光学和光子学在ann和dnn中的作用的合适时机。我们公开了光子张量加速器(pta),其具有比gpu和tpu高几个量级的计算能力,并且能够在一个时钟周期内进行矩阵
‑
矢量乘法、矩阵
‑
矩阵乘法、批矩阵乘法,即,将3d数据立方体(例如,一批图像)乘以权重矩阵,以及张量
‑
张量乘法。在本节的其余部分中,我们首先回顾电子ann的基础知识,然后简要介绍光学ann的相关研究。
[0038]
人工神经网络
[0039]
有三种流行的ann模型[31],即,(a)多层感知器,也称为全连接(fc)网络,其中每个神经元的输出是来自前一层的所有神经元的线性组合的非线性响应;(b)卷积神经网络(cnn),其中每个神经元的输出是来自前一层的神经元子集的指定线性组合的非线性响应(即,内核与来自前一层的神经元子集的卷积);以及(c)循环神经网络(rnn),其中每个神经元的输出是来自前一层的神经元和来自同一层但在先前时间的神经元两者的线性组合的非线性响应。图1示出了具有卷积隐藏层和全连接输出层的ann。
[0040]
卷积和线性组合两者都可以在数学上约化为权重矩阵w∈r
m
×
m
与一批输入矢量{x1,
…
x
n
}∈r
m
×
n
之间的矩阵乘法。为了提高神经网络中的矩阵计算速度,在cpu和gpu中实现了数据变换和线程并行化方案[32]、[33]。尽管可以推动进程并行化和时钟速度,但是微处理器的性能最终受到片上(on
‑
chip)功耗的限制。评估功率效率的关键度量是每次乘积累加运算(mac)(矩阵乘法的必要运算)的能耗。图2a是使用图2b中所示的cpu、图2c中所示的gpu和图2d中所示的tpu将矩阵乘法约化为乘积累加运算的示意图,其具有更高的并行度并提高了存储器访问的能量效率。如图2b所示,每个mac需要三次存储器读取(用于滤波器权重、神经元输入和部分和(partial sum))以及一次存储器写入(更新的部分和)。
[0041]
在现代微处理器中,存储器访问会消耗大部分处理能量。对于每次数据访问,动态随机存取存储器(dram)的能耗比小型片上存储器要高两个量级。因此,通过优化存储在本地存储器上的数据的可重用性,可以大大降低总能量消耗。然而,与dram(数十千兆字节(gb))相比,挑战是本地存储器(数千字节(kb))的有限容量。为了解决存储器访问中的这个挑战,图2c和2d所示的专用集成电路(asic)探索用于计算速度的新空间架构。例如,google的tpu的数据存储空间被放置在靠近逻辑单元的寄存器中,其能量效率约为1pj/mac,与市售gpu相比降低了20倍[31]。然而,存储器访问上的功耗仍比逻辑运算的功耗高3倍。
[0042]
光学人工神经网络
[0043]
光学人工神经网络自20世纪80年代以来一直是研究的主题。我们回顾这个领域的
代表性工作。显而易见的是,经过相对较长的休眠期后,ann领域正在复苏。
[0044]
基于全息术的全光学ann
[0045]
在20世纪80年代,有大量工作旨在实现用于图案识别的全光学人工神经网络。代表性地,使用光折射(pr)体全息图和非线性法布里
‑
珀罗(fp)谐振器[34]、[35]进行面部识别的工作仍然是迄今为止唯一完整的全光学ann,因为所有功能(神经网络训练和图案识别)和所有构建块都是使用光学器件实现的。尽管该现有技术表明光学器件可以基于ann执行图案识别,但它仍具有以下缺点:
[0046]
·
激活非线性fp谐振器所需的高功耗,
[0047]
·
由于光折射全息图的动态范围,扩缩性有限,以及
[0048]
·
慢训练速度,受制于pr载波传输寿命,大约为毫秒;
[0049]
使它无法进行有意义的实际应用。
[0050]
基于衍射光学的机器学习
[0051]
在该现有技术[36]中,使用多平面光学衍射网络,特别是作为数字分类器,来执行图案识别。使用机器学习技术设计网络中的相位屏幕。对来自mnist(改良的美国国家标准与技术研究所)手写数字数据集的10,000个图像进行数值测试[11]。使用3d打印相位屏幕的实验结果显示模拟和实验之间的匹配率为88%。在该分类器中,自由空间光学衍射用于构建互连,而相位掩模用于使互连多样化并建立每个衍射层的权重矩阵。
[0052]
全光学数字分类是使用类似于人工神经网络的结构来完成的。然而,分类系统是完全线性的。结果,只有正交的输入才能被分类。引入非线性将使其具有真正的神经网络的功能。
[0053]
基于相干纳米光子学(coherentnanophotonics)的深度学习全光学神经网络
[0054]
在该研究中,通过将相干输入光信号阵列通过可重构硅光子集成电路(pic)来执行矩阵
‑
矢量乘法。结果,输出光信号变为pic传输矩阵和输入信号的乘积。
[0055]
结果表明,硅pic的传输矩阵可以设置为任何指定的权重矩阵。这是因为任何实值m
×
n矩阵t可以通过奇异值分解(svd)被分解为其中u和v是m
×
n和n
×
m的单一矩阵,并且∑是m
×
n实值矩形对角矩阵。此外,可以使用光学分束器和移相器实现任何单位变换[37]。
[0056]
在[38]中,分束器和移相器是在硅波导马赫-曾德尔(mz)干涉仪中实现的。为了实现全光学ann,还必须在光域中实现非线性激活函数。在[38]中,提出了可饱和吸收体以提供光学非线性激活函数。在实际的实验中,非线性激活仍在电学领域中执行。
[0057]
pic是一种相干的多输入多输出(mimo)系统,其传输矩阵被设置为权重矩阵。这种方法的优点在于,集成pic既可以进行矩阵
‑
矢量乘法的乘法运算,也可以进行累加运算,而不会主动消耗任何功率。在[38]中,pic具有54个mz,占据约1.2
×
0.5cm2的面积。因此,一个12英寸的晶圆可以支持大约60,500个mz,或大约250
×
250个mz。因此,“定向耦合器和相位调制器的占地面积使得扩缩到较大数量(n>1000个)的神经元非常具有挑战性[39]”,而典型的应用需要100,000个神经元[38]。
[0058]
基于时分多路复用(tdm)和相干混频的深度学习光电人工神经网络
[0059]
这是一种混合方法,其中mac操作在光域中执行,非线性激活在电域中执行[39]。使用数字模拟来演示数字分类。预计每个mac的能耗低于现有的电子器件。
[0060]
通过时分多路复用(tdm)信号与tdm本地振荡器(lo)之间的元素方面的相干光学混合来执行矢量
‑
矢量乘法,并且通过低通滤波对光检测信号执行累加,其等同于积分。然后通过利用自由空间的并行性来完成矩阵
‑
矢量乘法。由于权重矩阵是通过时间调制生成的,所以该配置可实现超快速ann训练。还声称每个mac的能耗可以比电子器件低得多。然而,通常而言,ann权重矩阵更新可以很缓慢,并且最终保持在静态状态。但是在这种配置下,即使对于静态权重,权重矩阵也总是需要耗电的高速调制,因为累加是通过时间积分来实现的。此外,这种构造对其可扩缩性具有直接的影响。让我们假设mac的积分时间是1ns,对应于电子非线性激活的1ghz时钟速率。假设最大调制速度为500ghz,则每栏的权重数量被限制为500,并不比tpu多得多。其次的是,这种结构与全光学ann不兼容。
[0061]
发明概述
[0062]
在图3的表中,总结了光子加速器与现有的电子器件的性能比较。如上所述,可扩缩性是最重要的度量。我们在这里没有列出能量效率,因为它需要严格的、系统的核算,即使所有光学技术都有潜力实现能效,因为乘法是无源的。每种光学技术都提供了我们可以从中学习的重要创新。如下面将示出的,结合这些创新和本文公开的多维方法,应可使得光子张量加速器(pta)能够在可扩缩性方面最终超越电子器件。
[0063]
所公开的发明使用光学和光子方法,这些方法:1)与电子器件相比,提供以量级计更高的可扩缩性速度;2)快速、可编程、理想地与训练以及推理兼容,以及3)降低功耗密度,以便至少在某些类别的ai功能上,可以使ann相较纯电子器件具有优势。值得一提的是:
[0064]
·
ann仅需要特别适合于光子加速器的特殊操作/计算(例如mac),而不是通用计算。
[0065]
·
由于ann对数据动态范围和非线性激活方面的变化具有鲁棒性[40],所以模拟光子加速器可以实现与数字逻辑加速器相当的性能。
[0066]
本发明的实施例
[0067]
波长编码和模式编码矩阵
‑
矢量乘法加速器
[0068]
图4a和图4b中的矩阵
‑
矢量乘法与[39]具有单一相似性,其中乘法是通过相干混合和平方律检测来执行的。我们的方法与[39]之间存在主要差异:[39]中的累加是在时域中执行的,但是我们的方法中的累加是在光的波长、空间和所有其他非时域/自由度/维度中执行的。在图4a和图4b中,输入矢量和权重矢量被元素相关地投影到不同波长或空间模式[例如,厄米
‑
高斯(hg)模式]上。波长编码或模式编码的输入矢量扇出(fan
‑
out)为所需数量的副本,并与对应的波长编码或模式编码的los混合,其中,los包含权重矢量,权重矢量包括权重矩阵。由于波长或空间模式之间的正交性[41],一对信号和lo流之间的相干混合[图4a]或[图4b]产生矢量
‑
矢量乘法,并且2d空间并行化产生作为整体的矩阵
‑
矢量乘法。
[0069]
图4a和图4b示出了基于(a)波长编码和(b)模式编码的光子矩阵加速器的节点层。光子加速器在2d
(x,z)
平面中并行化以执行矩阵
‑
矢量乘法,并与(a)光检测之后的电子非线性激活和b)使用可饱和吸收体的光学非线性激活一起形成节点层。电子和光学非线性激活都与波长编码或模式编码或波长编码/模式编码组合的光子加速器兼容。这里,输入数据以波长或模式维度表示,权重矩阵以2d(波长或模式,z)维度表示,并且输出端口以x维度表示。累加分别在波长(a)或模式(b)维度上。
[0070]
波长编码和模式编码的光子矩阵加速器的输出可以通过平衡检测转换为电信号,以用作电子非线性激活的输入,如图4a所示。可替代的,输出可以直接输入到光学非线性激活单元中并用作光学非线性激活单元的泵浦,例如图4b所示的可饱和吸收体(sa)[较长波长或正交偏振的探测波]。因此,波长编码和/或模式编码矩阵加速器与全光学ann或混合光电ann兼容。
[0071]
存在多种实现模式多路复用器(和信号分离器)的方法,包括级联定向耦合器[42]、[43]、光子灯[44]
‑
[46]和多平面光转换器(mplc)[47]
‑
[49]。
[0072]
波长编码和/或模式编码矩阵加速器和光子张量加速器(pta)的主要优点是它们的可扩缩性。单独使用模式编码时,我们的矩阵加速器可以被缩放到至少300
×
300。mplc模式多路复用器具有宽的工作波长范围,因此是波长编码的。结合波长编码和模式编码,我们可以通过将波长和模式组合成一个超维度来潜在地将矩阵
‑
矢量乘法缩放到前所未有的大小,使得矢量的长度成为波长数量和模式数量的乘积。借助当今的技术,我们已经可以采用c波段中10ghz信道间隔的300个波长和300个模式,从而获得90,000的矢量长度。这是因为波长编码和模式编码的信号和lo流的干涉(相乘)可以在单个检测器上累加。矩阵的大小为90,000
×
[2d
(x,z)
空间并行化的程度],后者可以容易地超过100,使得该波长编码和模式编码的加速器的总mac至少为9,000,000,并具有2d空间并行化。
[0073]
偏振和正交编码可以各自使矩阵
‑
矢量乘法的规模加倍。从这里开始,我们将偏振和模式维度组合在一起成为单一维度,称为矢量模式。
[0074]
矩阵
‑
矩阵乘法加速器
[0075]
本发明通过进一步进入y方向的3d空间并行化来实现前所未有的大小的矩阵
‑
矩阵乘法。在这种情况下,如图5所示,输入矩阵以(波长和/或模式,y)维度表示,权重矩阵以(波长和/或模式,z)维度表示,并且在y方向上复制,输出矩阵包含在(x,y)中。
[0076]
广义张量乘法加速器
[0077]
总之,我们的发明可以配置许多维度(波长、矢量模式、正交和空间的三(3)个维度)的光来构建光子加速器。在自由空间实现中,使用空间的三个维度是自然的,并且对于ics或pic,使用空间的两个维度是自然的。可以使用任何两个(三个)维度来构建用于矩阵
‑
矢量(矩阵
‑
矩阵)乘法的光子加速器。可以将多个维度(例如,上述波长
‑
模式)组合成超维度以增加可扩缩性。矢量模式是空间模式和偏振模式的组合。类似地,每个维度可以独立地用于构建用于批矩阵乘法运算的光子张量加速器(pta)。例如,波长模式维度可以用于表示一批图像(3d数据立方体),然后可以将其与权重矩阵相乘,即一起在一个时钟周期中一次加速。可替代地,具有大量参数的每个维度可以被划分为相互正交的子集,以有效地增加独立/正交自由度的数量。例如,波长具有比仅具有2个参数的偏振更多的参数。空间是另一自由度,其具有大量的参数可划分成相互正交的子集。这在执行张量
‑
张量乘法中特别有用。
[0078]
非限制性实施例
[0079]
尽管已经讨论了本发明的具体实施例,但是本领域普通技术人员将理解,在不脱离本发明的范围的情况下,可以对具体实施例进行改变。因此,本发明的范围不限于具体实施例,并且所附权利要求旨在覆盖本发明范围内的任何和所有这些应用、修改和实施例。
[0080]
应当注意,本发明的一些特征可以在其一个实施例中使用,而不使用本发明的其他特征。因此,前面的描述应该被认为仅仅是对本发明的原理、教导、示例和示例性实施例
的说明,而不是对其的限制。
[0081]
此外,这些实施例仅是本文中的创新教导的许多有利用途的示例。通常,在本技术的说明书中做出的陈述不一定限制任何各种要求保护的发明。此外,一些陈述可能适用于一些发明特征,但不适用于其他发明特征。
[0082]
已经出于说明和描述的目的呈现了本发明的描述,并且本发明的描述并不旨在穷举或将本发明限于所公开的形式。在不脱离所描述的实施例的范围和精神的情况下,许多修改和变化对于本领域普通技术人员将是显而易见的。选择和描述实施例是为了最好地解释本发明的原理、实际应用,并且使本领域普通技术人员能够理解本发明的具有适合于预期的特定用途的各种修改的各种实施例。选择本文使用的术语是为了最好地解释实施例的原理、实际应用或对市场中发现的技术的技术改进,或者使本领域普通技术人员能够理解本文公开的实施例。
[0083]
并入的参考文献
[0084]
以下出版物各自通过引用整体并入:
[0085]
[1]r.f.rutz,“transistor
‑
like device using optical coupling between diffused p
‑
n junctions in gaas,”proc.ieee,1963.
[0086]
[2]k.jain and g.w.pratt,“optical transistor,”appl.phys.lett.,vol.28,no.12,pp.719—721,jun.1976.
[0087]
[3]h.f.taylor,“guided wave electrooptic devices for logic and computation,”appl.opt.,vol.17,no.10,p.1493,may 1978.
[0088]
[4]m.n.islam,“ultrafast all
‑
optical logic gates based on soliton trapping in fibers,”opt.lett.,vol.14,no.22,p.1257,nov.1989.
[0089]
[5]j.w.goodman,“operations achievable with coherent optical information processing systems,”proc.ieee,1977.
[0090]
[6]d.a.b.miller,“are optical transistors the logical next step?,”nat.photonics,vol.4,no.1,pp.3
‑
5,jan.2010.
[0091]
[7]s.a.manavski,“cuda compatible gpu as an efficient hardware accelerator for aes cryptography,”in icspc 2007 proceedings
‑
2007 ieee international conference on signal processing and communications,2007.
[0092]
[8]g.quintana
‑
orti,f.d.igual,e.s.quintana
‑
orti,and r.a.van de geijn,“solving dense linear systems on platforms with multiple hardware accelerators,”acm sigplan not.,2009.
[0093]
[9]m.abadi et ah,“tensorflow:a system for large
‑
scale machine learning this paper is included in the proceedings of the tensorflow:a system for large
‑
scale machine learning,”proc 12th usenix conf.oper.syst.des.implement.,2016.
[0094]
[10]y.jia et al.,“caffe:convolutional architecture for fast feature embedding,”2014.
[0095]
[11]“the mnist database.”[online].available:http://yann.lecun.com/exdb/mnist/.
saturation of absorption,”opt.express,2014.
[0113]
[29]l.larger,a.baylon
‑
fuentes,r.martinenghi,v.s.udaltsov,y.k.chembo,and m.jacquot,“high
‑
speed photonic reservoir computing using a time
‑
delay
‑
based architecture:million words per second classification,”phys.rev.x,2017.
[0114]
[30]a.katumba,j.heyvaert,b.schneider,s.uvin,j.dambre,and p.bienstman,“low
‑
loss photonic reservoir computing with multimode photonic integrated circuits,”sci.rep.,2018.
[0115]
[31]n.p.jouppi et al.,“in
‑
datacenter performance analysis of a tensor processing unit,”in proceedings of the 44th annual international symposium on computer architecture
‑
isca17,2017,pp.1
‑
12.
[0116]
[32]m.mathieu,m.henaff,and y.lecun,“fast training of convolutional networks through ffts,”pp.1
‑
9,2013.
[0117]
[33]a.krizhevsky,i.sutskever,and g.e.hinton,“imagenet classification with deep convolutional neural networks,”adv.neural inf.process.syst.,pp.1
‑
9,2012.
[0118]
[34]k.wagner and d.psaltis,“multilayer optical learning networks,”appl.opt.,vol.26,no.23,p.5061,dec.1987.
[0119]
[35]d.psaltis,d.brady,x.g.gu,and s.lin,“holography in artificial neural networks.,nature,vol.343,no.6256,pp.325
‑
30,1990.
[0120]
[36]x.lin et ah,“all
‑
optical machine learning using diffractive deep neural networks,science(80
‑
.).,2018.
[0121]
[37]m.reck,a.zeilinger,h.j.bernstein,and p.bertani,“experimental realization of any discrete unitary operator,”phys.rev.lett.,1994.
[0122]
[38]y.shen et al.,“deep learning with coherent nanophotonic circuits,”nat.photonics,vol.11,no.7,pp.441
‑
446,jul.2017.
[0123]
[39]r.hamerly,a.sludds,l.bernstein,m.soljacic,and d.englund,“large
‑
scale optical neural networks based on photoelectric multiplication,”arxiv prepr.arxiv 1812.07614,pp.1
‑
18,nov.2018.
[0124]
[40]p.merolla,r.appuswamy,j.arthur,s.k.esser,and d.modha,“deep neural networks are robust to weight binarization and other non
‑
linear distortions,”arxiv prepr.arxivl606.01981,jun.2016.
[0125]
[41]y.wang,n.zhao,z.yang,z.zhang,b.huang,and g.li,“few
‑
mode sdm receivers exploiting parallelism of free space,”ieee photonics journal,2019.
[0126]
[42]b.huang,c.xia,g.matz,n.bai,and g.li,“structured directional coupler pair for multiplexing of degenerate modes,”2013.
[0127]
[43]y.gao et al.,“non
‑
circularly
‑
symmetric mode
‑
group demultiplexer based on fused
‑
type fmf coupler for mgm transmission,”2018.
[0128]
[44]t.a.birks,i.gris
‑
sanchez,s.yerolatsitis,s.g.leon
‑
saval,and r.r.thomson,“the photonic lantern,”adv.opt.photonics,2015.
[0129]
[45]b.huang et al.,“all
‑
fiber mode
‑
group
‑
selective photonic lantern using graded
‑
index multimode fibers,”opt.express,2015.
[0130]
[46]b.huang et al.,“triple
‑
clad photonic lanterns for mode scaling,”opt.express,2018.
[0131]
[47]g.labroille,b.denolle,p.jian,j.f.morizur,p.genevaux,and n.treps,“efficient and mode selective spatial mode multiplexer based on multi
‑
plane light conversion,”in 2014 ieee photonics conference,ipc 2014,2014.
[0132]
[48]n.k.fontaine,r.ryf,h.chen,d.t.neilson,k.kim,and j.carpenter,“scalable mode sorter supporting 210 hermite
‑
gaussian modes,”2018.
[0133]
[49]s.bade et al.,“fabrication and characterization of a mode
‑
selective 45
‑
mode spatial multiplexer based on multi
‑
plane light conversion,”in optical fiber communication conference postdeadline papers,2018,p.th4b.3.
[0134]
[50]z.i.borevich and s.l.krupetskii,“subgroups of the unitary group that contain the group of diagonal matrices,”j.sov.math.,1981.
[0135]
[51]j.
‑
f.morizur et ah,“programmable unitary spatial mode manipulation,”j.opt.soc.am.a,vol.27,no.11,p.2524,nov.2010.
[0136]
[52]h.takahashi,t.saida,y.sakamaki,and t.hashimoto,“wavefront matching method:a new approach for need
‑
oriented waveguide design,”in conference proceedings
‑
lasers and electro
‑
optics society annual meeting
‑
leos,2005.
[0137]
[53]t.umezawa et ah,“10
‑
ghz 32
‑
pixel 2
‑
d photodetector array for advanced optical fiber communications,”2017.
[0138]
[54]d.j.brady et ah,“multiscale gigapixel photography,”nature,vol.486,no.7403,pp.386
‑
389,2012.
[0139]
[55]l.gao,j.liang,c.li,and l.v wang,“single
‑
shot compressed ultrafast photography at one hundred billion frames per second,”nature,vol.516,no.7529,pp.74
‑
77,2014.
[0140]
[56]k.simonyan and a.zisserman,“very deep convolutional networks for large
‑
scale image recognition,”pp.1
‑
14,2014.
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

