1.本发明属于情感计算领域,尤其涉及一种基于多特征深度森林的脑电情绪识别方法。
背景技术:
2.近年来,随着人机交互技术的飞速发展,情感计算越来越受到人们的关注。情感在人类交流和个人决策中占有非常重要的地位。虽然情感的存在是众所周知的,但人类对其背后的机制知之甚少。传统上,用于情感识别的人机交互是通过语音信号和面部表情信号来实现的。但这些外部信号有一定程度的伪装。因此,使用语音和面部表情信号作为情感识别的基础是不可信的。脑电生理信号直接由人体中枢神经系统产生,中枢神经系统与人的情绪密切相关。在情绪识别中,脑电图(eeg)信号比其他生理实验更容易被记录,不易被伪装。随着情绪研究基础理论和情绪脑机交互应用的发展,脑电情绪识别成为一个热门的研究课题。例如利用人脑电进行情绪识别用于治疗精神障碍患者。
3.基于脑电的情绪识别研究大都是在valence和arousal的二分类问题上,或者自然、消极、积极三分类情绪识别上,很少有研究通过脑电信号的 valence和arousal的等级来划分相应的情绪进行识别。如何提高对多类别的情绪分类的识别精度,以及如何识别情绪的产生与相应的生理机制之间的关系,是脑机接口领域亟待解决的问题。
技术实现要素:
4.本发明目的在于提供一种基于多特征深度森林的脑电情绪识别方法,以解决基于脑电图对人类情绪进行识别的技术问题。
5.为解决上述技术问题,本发明的一种基于多特征深度森林的脑电情绪识别方法的具体技术方案如下:
6.一种基于多特征深度森林的脑电情绪识别方法,包括如下步骤:
7.步骤一、脑电信号预处理;
8.步骤二、情绪分类标记;
9.步骤三、特征处理;
10.步骤四、情感计算;
11.步骤五、情绪识别分类;
12.步骤六、实验结果判定;
13.步骤五采用多特征深度森林的脑电情绪识别模型,包括如下具体步骤:
14.步骤五.1、建立多特征深度森林的脑电情绪识别模型;
15.步骤五.2、多特征深度森林的脑电情绪识别模型的参数初始化;
16.步骤五.3、多特征深度森林的脑电情绪识别模型分类效果评估。
17.进一步地,步骤五.1的具体步骤包括:
18.步骤五.1.1、选择树节点的分裂特征来设置两种类型的随机森林,树节点分裂特
征采用两种策略,策略一是对特征总数的平方根进行四舍五入,策略二是对特征总数的对数进行四舍五入;
19.步骤五.1.2、选择id3算法作为决策树,且该模型的每一层中取两个相同类的随机森林,每个级联层由四个随机森林组成;
20.步骤五.1.3、将当前层的输出向量作为增强特征,并结合原始数据组成新的数据特征作为下一层的输入,输出向量是每个类的分类概率向量,分类概率由每个决策树的输出进行统计计算。
21.进一步地,步骤五.2的具体步骤包括:
22.步骤五.2.1、将每个随机森林中的决策树设置为120棵,决策树生长的最大深度设置为14,节点中执行分裂的最小采样数设置为5;
23.步骤五.2.2、使用袋外样本来估计泛化精度;
24.步骤五.2.3、在scikit
‑
learn中对类权重参数进行均衡设置;
25.步骤五.2.4、对每个受试者进行单独的实验。
26.进一步地,步骤五.3的指标包括:
27.情绪识别精度(acc
e
)和混淆矩阵(conf),
28.情绪识别精度定义为
[0029][0030]
其中n是所有测试样本的数量,n
e
是正确分类的情感标签。
[0031]
进一步地,步骤一的脑电信号的采样频率为128hz,采用带宽为4.0~ 45.0hz的带通滤波器进行预处理,根据被试者的valence、arousal、 dominance、liking来评分将情绪划分为五类并标记。
[0032]
进一步地,步骤二的标记规则如下:
[0033]
愤怒:valence<4.5,arousal>5.5,
[0034]
快乐:valence>5.5,arousal>5.5,
[0035]
悲伤:valence<4.5,arousal<4.5,
[0036]
愉快:valence>5.5,arousal<4.5,
[0037]
自然:4.5<valence<5.5,4.5<arousal<5.5,
[0038]
valence和arousal的评分为1
‑
9,对于中间评分范围,标记成中性情绪类型,愤怒、快乐、悲伤、愉快和自然分别用不同数字来标记。
[0039]
进一步地,步骤三采用功率谱密度特征(psd)和微分熵特征(de)提取,功率谱密度特征(psd)提取定义如下:
[0040][0041]
其中,l是信号的长度,p
i
(f)是信号x
i
[n]的快速傅立叶变换。然后,信号x
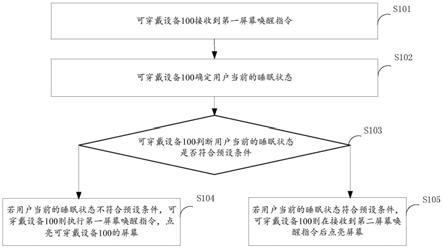
i
[n]的psd特征p(x
i
)可以通过公式得到,
[0042]
其中,k可以从用于计算离散傅立叶变换的频率点的数量中获得。
[0043]
进一步地,步骤四情感计算方法采用降维算法,包括如下步骤:
[0044]
计算最大相关准则,搜索满足单个特征x
i
和类c之间所有互信息值的平均值的特征,计算公式如下,
[0045][0046]
计算最小冗余条件,计算公式如下,
[0047][0048]
最后定义操作符来组合d和r,表示为,
[0049][0050]
进一步地,步骤六包括如下具体步骤:
[0051]
步骤六.1、研究特征降维前后与情绪识别精度之间的关系;
[0052]
步骤六.2、研究特征提取前后,深度森林的脑电情绪识别模型在情绪识别上的精度的变化;
[0053]
步骤六.3、研究输入原始数据、特征和降维后的特征来评估mfdf的可靠性和有效性;
[0054]
步骤六.4、对原始数据进行了实验,以确定所提取特征的有效性;
[0055]
步骤六.5、以未经特征提取的原始数据作为深度森林的输入,并对其精度进行研究。
[0056]
有益效果:本发明探索了通过不同的特征进行组合,挖掘了数据中的数据特征,使得分类精度大大提高。另外在数据预处理过程中,采用了五分类情绪模型进行情绪的划分,研究了脑电信号和情绪之间的联系。本发明采用模式识别方法是“白盒”方法,其内部结构易解释性好透明度高。该多特征深度森林情感识别模型可以有效地提高情绪识别的精度,在大多数情况下能够准确的预测情感类别,鲁棒性强,在脑机交互领域具有较高的应用价值。
附图说明
[0057]
图1为本发明的算法流程图;
[0058]
图2为本发明的多特征深度森林模型图;
[0059]
图3为本发明的五分类模型图;
[0060]
图4为本发明的不同受试者的平均准确度折线图;
[0061]
图5为本发明的输入不同类型的数据的平均准确度折线图;
[0062]
图6为本发明的不同模型识别率柱状图;
[0063]
图7为本发明的mfdf的混淆矩阵列表。
具体实施方式
[0064]
为了更好地了解本发明的目的,下面结合附图,对本发明一种基于多特征深度森
林的脑电情绪识别方法做进一步详细的描述。
[0065]
如图1所示,本基于多特征深度森林的脑电情绪识别方法包括如下步骤:步骤一,对脑电信号进行预处理;步骤二,情绪分类标记;步骤三,特征处理;步骤四,情感计算;步骤五,情绪识别分类,步骤六,实验结果判定。
[0066]
下面通过实施例具体说明:
[0067]
步骤一:脑电信号预处理
[0068]
本发明使用一个公共数据库deap,该数据集包含32个受试者在观看40 段音乐视频时的32个脑电信号和8个外周生理信号。每一段视频都是根据每一个被试者的valence、arousal、dominance、liking来评分的。评分与情绪密切相关。在目前的研究中,只有脑电信号用于情绪识别。脑电信号的采样频率为128hz,采用带宽为4.0~45.0hz的带通滤波器进行预处理。记录的脑电图数据包括观看视频时的60秒试验数据和3秒的基线数据。
[0069]
步骤二:情绪分类标记
[0070]
本发明根据以下规则来标记愤怒、快乐、悲伤、愉快和自然这五类情绪。
[0071]
愤怒:valence<4.5,arousal>5.5,
[0072]
快乐:valence>5.5,arousal>5.5,
[0073]
悲伤:valence<4.5,arousal<4.5,
[0074]
愉快:valence>5.5,arousal<4.5,
[0075]
自然:4.5<valence<5.5,4.5<arousal<5.5,
[0076]
valence和arousal的评分为1
‑
9,如图3所示,我们根据评分的范围制作了一个五分类模型。对于一些中间评分范围,我们将其标记成中性情绪类型。本发明通过五分类情绪模型给受试者标记不同的情绪标签,愤怒、快乐、悲伤、愉快和自然分别用0、1、2、3、4来标记以便分类。
[0077]
步骤三:特征提取
[0078]
本发明从原始脑电信号中提取了α、β、γ、θ四种脑电信号,然后对这四类信号和原始信号进行了特征提取。
[0079]
(1)功率谱密度特征(psd)提取
[0080]
welch方法的功率谱密度估计可以提供非常强的特征,而且它也是脑电信号的一个很好的表示。本发明采用功率谱密度的平均值作为数据特征。功率谱密度的定义如下:
[0081][0082]
其中,l是信号的长度,pi(f)是信号xi[n]的快速傅立叶变换。然后,信号xi[n]的psd特征p(xi)可以通过公式2得到。
[0083][0084]
其中,k可以从用于计算离散傅立叶变换的频率点的数量中获得。本发明使用短时傅里叶变换求得脑电信号的功率谱密度,我们使用1s的汉宁窗和无重叠滑动来提取的功率谱密度。我们对每个窗口内的功率谱密度求平均值,作为该时间段脑电信号的功率谱密度特征。
[0085]
(2)微分熵特征(de)提取
[0086]
微分熵是反映警觉变化的最准确、最稳定的脑电特征。功率谱密度的定义如下:
[0087][0088]
这里x
i
[n]的高斯分布为n(μ,σ2)。本发明使用1s的窗口和1s的步长来提取脑电信号的微分熵特征。对每个窗口内的脑电信号计算出方差,然后通过公式(3)求得该窗口内的微分熵特征。
[0089]
步骤四:情感计算
[0090]
(1)降维算法
[0091]
最小冗余最大相关(mrmr)算法利用互信息作为关联度量,并分别采用最大依赖准则和最小冗余准则。最大相关准则搜索满足单个特征x
i
和类c之间所有互信息值的平均值的特征,如下所示,
[0092][0093]
当两个特征高度依赖于同一个类时,如果去掉其中一个特征,那么整体的类区分能力不会有太大的变化。因此,可以添加以下最小冗余条件来选择互斥特性,
[0094][0095]
上述两个约束被称为“最小冗余最大相关”。我们定义操作符来组合d和r,最简单的定义可以表示为,
[0096][0097]
步骤五:情绪识别分类
[0098]
本发明旨在通过脑电信号的多通道提取功率谱密度和微分熵这两个特征作为输入,同一时间内的提取多个特征组成多特征数据,通过深度森林来进行脑电的情绪分类识别。情绪识别分类步骤如下:
[0099]
一、建立多特征深度森林的脑电情绪识别模型
[0100]
作为随机森林的一种延伸,深度森林不同于一般的随机森林。随机森林是以决策树为基础,利用集成学习的思想对数据进行分类。而深度森林采用级联结构,结合神经网络的特点,进一步提高了随机森林的分类识别能力,并且级联层可以自动调整最佳分类层数。深度森林通过比较相邻层的分类性能,自动优化深度森林的结构。
[0101]
本发明通过选择树节点的分裂特征来设置两种类型的随机森林。树节点分裂特征的一种策略是对特征总数的平方根进行四舍五入,另一种策略是对特征总数的对数进行四舍五入。本发明选择id3算法作为决策树,且该模型的每一层中取两个相同类的随机森林,所以每个级联层由四个随机森林组成。
[0102]
如图2所示,是本发明多特征深度森林模型图,本发明将当前层的输出向量作为增强特征,并结合原始数据组成新的数据特征作为下一层的输入。输出向量实际上是每个类的分类概率向量。分类概率由每个决策树的输出进行统计计算。在本发明中,我们进行了五类情绪的分类。因此,每个级联层生成20个增强特征。在本发明中,深度森林的层数不是固定的,而是通过评估相邻层是否能提高分类性能来确定。
[0103]
二、多特征深度森林的脑电情绪识别模型的参数初始化
[0104]
本发明采用一种可解释性的参数初始化,多特征深度森林模型的基本单元是决策树,所以本模型的参数初始化规则如下:
[0105]
多特征深度森林模型的参数主要有决策树的数量、节点中执行分裂的最小采样数、级联层生长的精度范围。本发明将每个随机森林中的决策树设置为120棵。决策树生长的最大深度设置为14。节点中执行分裂的最小采样数设置为5。本发明还使用袋外样本来估计泛化精度。为了解决数据不平衡的问题,在scikit
‑
learn中对类权重参数进行了均衡设置。最后,每个受试者进行了单独的实验。
[0106]
三、多特征深度森林的脑电情绪识别模型的分类效果评估指标
[0107]
本发明提出了一种用于多特征深度森林模型的两个指标,在本发明的应用中,两个指标分别为:情绪识别精度(acc
e
)和混淆矩阵(conf)。情绪识别精度定义为
[0108][0109]
其中n是所有测试样本的数量,n
e
是正确分类的情感标签。
[0110]
混淆矩阵(conf)的定义规则
[0111]
conf真实值=1真实值=2真实值=3真实值=4真实值=5预测值=1tpfnfnfnfn预测值=2fntpfnfnfn预测值=3fnfntpfnfn预测值=4fnfnfntpfn预测值=5fnfnfnfntp
[0112]
其中tp表示预测值与真实值分类相同的情况,是指正确分类,fn表示预测值与真实分类值不相同的情况下,是指错误分类,该发明涉及五分类的情况。
[0113]
本发明设计采用深度森林对数据进行分析,从而得到不同实验参数与条件下的情绪识别精度。此外本发明与传统的分类器(支持向量机(svm)、k 最邻近法(knn)、随机森林(rf))进行了分类精度比较。对于svm,采用线性核函数,惩罚系数为0.8。对于knn分类器,k系数设置为5。在rf中,决策树的数量设置成120,并使用id3算法进行训练。
[0114]
步骤六:实验结果分析
[0115]
本发明设计了两个实验来评估多特征深度森林模型的准确性和鲁棒性。第一个实验研究特征降维前后与情绪识别精度之间的关系。第二个实验研究特征提取前后,该模型在情绪识别上精度的变化。
[0116]
如图4所示,显示了不同受试者的平均准确度。结果表明,mfdf、rf、 svm和knn的平均精度分别为71%、68%、52%和63%。该模型的平均识别精度比svm高19.53%,比rf高3.4%,比knn高8.54%。此外,对于受试者s7和 s16,所提出的mfdf模型达到了最高的86%的精确度。
[0117]
如图5所示,本发明还通过研究输入的不同类型的数据(原始数据、特征和降维后的特征)来评估mfdf的可靠性和有效性。结果表明,进行降维处理之后的平均识别率为51.30%。虽然它比没有降维之前的平均识别精度要低得多,但它的平均识别率仍然高于所比较的分类器。如图6所示,该模型的平均识别率比svm高5.76%,比rf高1.19%,比knn高11.21%。
[0118]
本发明还对原始数据进行了实验,以确定所提取特征的有效性。由于原始数据没有以任何方式进行处理,可能会出现严重的维度灾难。考虑到计算机资源和识别精度之间的平衡,我们将每个rf的决策树数设置为30个。由于原始数据的实验占用了大量的计算机计算资源,本文仅对s1、s2、s4、s5、 s6、s7、s8、s9、s10、s11等10个被试进行了实验。实验结果如图6所示,平均识别率为25.37%。
[0119]
此外,本发明以未经特征提取的原始数据作为深度森林的输入,并对其精度进行了研究,。结果如图6所示,未进行降维处理的平均精度为72.94%,降维处理的平均精度为51.13%。原始数据的平均准确率为25.37%。结果表明,以原始特征作为输入,分类精度最高,说明在目前的案例研究中,深度森林能够更有效地处理特征而不是原始数据。
[0120]
混淆矩阵是通过mfdf的混淆矩阵来体现该发明的模型具有一定可解释性。如图7所示,0、1、2和3组中的样本被错误分类为4组的样本数最多,对错误的贡献最大。0、1、2、3和4组的准确率分别为72.33%、70.85%、70.70%、 74.53%和69.47%中,我们可以看出该模型对3组的分类效果较好,对4组的分类准确度较差,这有助于优化的mfdf模型的鲁棒性。
[0121]
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本技术的权利要求范围内的实施例都属于本发明所保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。