本申请要求2019年12月17日提交的美国临时专利申请No.62/948,989的提交日的权益,其公开内容由此通过引用并入本文。
技术领域
本公开通常涉及一种电子设备,该电子设备被配置成解释默读话语并按照默读话语行动。更具体地,本公开涉及一种入耳式设备和相关计算支持系统,该相关计算支持系统利用机器学习来解释描述由用户进行默读期间的一个或多个入耳式现象的传感器数据。
背景技术
现今有将诸如请求、命令或文本的信息录入到计算机中的两种主要方式。第一录入模态的集合需要用户与设备之间的物理交互。作为示例,键盘、鼠标、触摸板和/或触摸屏的使用需要用户以物理方式——诸如使用他们的手指或利用触针——与计算机或计算机的外围输入设备交互。用于录入数据的第二模态是通过使用语音,诸如通过话音命令。
这两种录入模态都具有缺点。例如,诸如键盘、鼠标、触摸屏的物理输入模态占用用户的手并且常常需要用户也看着屏幕,这在诸如当操作车辆时的许多情形下可能是不安全的或不希望的。
另一方面,虽然基于语音的接口避免占用用户的手和/或凝视,但是基于语音的接口提供减少的隐私,因为用户通过基于语音的接口与计算机的交互对位于用户周围的任何人而言是可听见的。在许多情况下,不管交互的内容是否包含敏感信息,用户都将宁愿位于附近的人不会无意中听到用户与计算机的交互。作为一个示例,为了礼貌,乘坐公共交通工具的人可能不希望将诸如请求、命令或文本的信息可听见地输入到计算机中。在另一更极端示例中,诸如执法人员的紧急服务响应者可能希望诸如经由计算设备向支持团队或同事提供信息,而不用可听见地讲话,以免泄露他们的位置。
技术实现要素:
本公开的实现方式的各方面和优点将在以下描述中被部分地阐述,或者能够从描述中学习,或者能够通过对实现方式的实践来学习。
本公开的一个示例方面涉及一种电子设备,该电子设备包括一个或多个处理器和一个或多个非暂时性计算机可读介质,该一个或多个非暂时性计算机可读介质存储指令,当由一个或多个处理器执行时,这些指令使电子设备执行操作。操作包括接收由至少部分地定位在用户的耳朵内的至少一个传感器生成的传感器数据,其中,传感器数据由至少一个传感器与用户对默读话语进行默读同时生成。操作包括用机器学习的默读解释模型来处理传感器数据以生成默读话语的解释作为机器学习的默读解释模型的输出。
至少一个传感器能够包括一个或多个麦克风,该一个或多个麦克风将位于用户的耳朵的耳道内的声波转换为传感器数据。位于用户的耳道内的声波能够由用户的鼓膜生成。当一个或多个麦克风被放置在用户的耳朵内时,能够将一个或多个麦克风指向用户的鼓膜。至少一个传感器能够包括以下各项中的一个或多个:加速度计;陀螺仪;雷达设备;声纳设备;激光麦克风;红外传感器;或气压计。
该电子设备能够被调整大小和成形以被至少部分地定位在用户的耳朵内。该电子设备耦合到与至少一个传感器物理上分离的辅助支持设备。
由机器学习的默读解释模型输出的默读话语的解释能够包括默读话语的文本形式的转录。由机器学习的默读解释模型输出的默读话语的解释包括将默读话语分类成多个类别中的一个或多个。多个类别能够包括多个定义的命令。
操作还能够包括由基于人工智能的个人助理系统至少部分地基于由机器学习的默读解释模型输出的默读话语的解释来确定要执行的至少一个操作。
本公开的另一示例方面涉及一种耳塞。该耳塞包括:至少一个传感器;一个或多个处理器;以及一个或多个非暂时性计算机可读介质,该一个或多个非暂时性计算机可读介质存储指令,当由一个或多个处理器执行时,这些指令使耳塞执行操作。操作包括接收由至少一个传感器生成的传感器数据,其中,传感器数据由至少一个传感器与用户对默读话语进行默读同时生成,并且其中至少一个传感器被至少部分地定位在用户的耳朵内。操作包括用机器学习的默读解释模型来处理传感器数据以生成默读话语的解释作为机器学习的默读解释模型的输出。
本公开提供一种入耳式设备和相关联的计算支持系统,该入耳式设备和相关联的计算支持系统利用机器学习来解释描述由用户默读期间的一个或多个入耳式现象的传感器数据。具体地,默读是指一个人用他们的嘴、舌头等形成发出某种声音所必需的形状但未呼出足够的空气通过他们的声带来产生可听语音的实践。在一些情况下,能够将这种实践称为“无声阅读”或“无声语音”。即使因为几乎没有空气通过声带推动所以未产生可听语音,也仍然在用户的耳朵内发生诸如由鼓膜/膜中振动产生的声波的某些现象。本公开的各方面利用机器学习技术来解释描述这种入耳式现象的传感器数据,从而产生能够解释由用户做出的默读话语并智能地对其做出响应的系统。以这种方式,并且与现有基于语音的接口相比,本文提出的系统和方法使得能以更私密的方式实现免提数据录入。
入耳式设备能够被至少部分地定位在用户的耳朵内。入耳式设备能够包括一个或多个传感器,诸如麦克风,这些传感器生成描述在用户对默读话语进行默读的同时在用户的耳朵内发生的现象的传感器数据,例如音频波。机器学习的默读解释模型能够由入耳式设备和/或辅助支持设备来实现。模型能够接收并处理传感器数据以生成默读话语的解释。作为示例,解释能够包括默读话语的文本转录和/或将默读话语分类成多个预定义类别。作为示例,分类能够对应于多个预定义命令或动作,诸如“Play my favorite album(播放我最喜欢的专辑)”。默读话语的解释能够例如由基于人工智能(AI)的个人助理使用,以使基于(AI)的个人助理执行一个或多个操作,诸如录入文本转录或对文本转录做出响应或执行所请求的动作,诸如播放某个音乐专辑、预约等。以这种方式,入耳式设备和/或相关联的系统能够使得用户能够通过默读来输入、请求、命令或以其他方式与计算系统交互。
因此,本文描述的系统的一个特定示例实现方式能够包括两个部分:(a)放置在诸如在外耳内或在耳道内的用户的耳朵中并且指向用户的鼓膜的麦克风系统;以及(b)能够将来自麦克风系统的信号解码成作为示例诸如辅助命令的可动作解释或者直接解码成人类可读的文本或语音的机器学习系统。
所提出的系统和方法基于人类能够快速地训练自己“安静地”讲话的原理,例如通过仍然设法做出正常声音但不推动足够的空气通过他们的声带来生成可听语音。在人类语音器官中通过肌肉移动的此类动作使鼓膜和内耳振动,这在耳道内引起音频信号,该音频信号能够被专门地放置的麦克风系统收集。
然而,由默读引起的入耳式音频信号不可被其他人们听见。此外,即使此类声音可被其他人听见,由放置在耳朵中并指向鼓膜例如朝向耳朵“内部”的麦克风阵列记录的音频也高度地失真并且甚至在放大之后也无法直接被人类识别。因此,音频信号的简单放大不足以渲染可理解内容。
为了解决这些挑战,本公开利用机器学习的默读解释模型,诸如神经网络。例如,机器学习的模型能够被配置成将由麦克风阵列捕获的音频信号处理成可动作和/或可理解解释,诸如由默读引起的音频信号的文本转录。
在一些实现方式中,机器学习的默读解释模型能够将音频信号翻译成能够例如由相同模型或另一模型翻译成特殊命令、文本和/或语音的表示。特殊命令的示例能够包括“what's the time?(现在几点?)”、“when is my next meeting?(我的下一个会议是什么时候?)”和“play music(播放音乐)”。文本的示例能够包括“send email to my partner that I bought ingredients and will cook dinner tonight(向我的伙伴发送我买了食材并将在今晚做晚饭的电子邮件)”。语音的示例能够包括“make a call to the dentist(给牙医打电话)”或“Hello,I'd like to book an appointment next week(你好,我想下周预约)”。
在一些实现方式中,能够在监督学习方法中训练机器学习的默读模型。训练数据集能够包括在一个或多个人们正在对已知字符串进行默读的同时收集的传感器数据的集合,诸如由麦克风捕获的音频信号。因此,能够将模型对每个传感器数据的集合的预测与已知字符串进行比较。
在一些实现方式中,入耳式设备和/或相关系统能够执行或以其他方式接收与用户训练/引导过程相关联的数据,在所述用户训练/引导过程中新用户被要求执行已知内容的默读,诸如通过在不推动空气通过用户的声带的情况下阅读某些文本。能够基于校准数据来训练、重新训练、完善、个性化等模型。这能够使得默读模型能够对于特定用户具有改进的准确性。
附加地或替换地,在一些实现方式中,能够首先在通用可听语音示例上训练默读模型。然后能够经由迁移学习细化在正常音频上训练的模型以在默读数据上训练。在一些实现方式中,不是修改较低层,而是能够简单地向迁移模型的顶部添加较高层。模型能够从自底向上的、以通过在正常音频上训练的较低层然后通过所添加的较高层处理的输入默读开始来处理输入。能够在经由入耳式麦克风阵列从各种用户收集的较小数据集上训练这些添加的较高层。
本公开提供许多技术效果和益处。作为一个示例,所提出的解释默读的技术使得能实现具有改进的隐私和/或安全性的人机接口。作为示例,紧急响应者能够使用实现本公开的各方面的设备来传达信息而不泄露其位置,例如,在不希望泄露其位置的紧急响应者的用例中。作为另一示例,所提出的技术能够使得能实现对非视觉接口的改进且更频繁的使用。对非视觉接口的更频繁使用减少设备需要产生以使得能实现与用户的相同交互的屏幕可视化和光输出的量,从而节约计算资源,诸如电池或能源使用。另一方面涉及一种方法。该方法能够包括:由至少部分地定位在用户的耳朵内的至少一个传感器生成表示由用户做出的默读话语的传感器数据;以及用机器学习的默读解释模型来处理传感器数据以生成默读话语的解释作为机器学习的默读解释模型的输出。
传感器数据能够基于通过在用户的耳朵内由用户对默读话语进行默读产生的振动所产生的声波。传感器可以是入耳式设备的一部分。入耳式设备能够与至少一个辅助支持设备耦合。
机器学习的默读解释模型能够被实现在入耳式设备中。机器学习的默读解释模型能够被实现在至少一个辅助支持设备中。
另一方面涉及一种系统,该系统包括:至少一个传感器,该至少一个传感器被配置成被至少部分地定位在用户的耳朵内并且与用户对默读话语进行默读同时地生成传感器数据;一个或多个处理器;以及一个或多个计算机可读介质。一个或多个计算机可读介质能够存储指令,当由一个或多个处理器执行时,这些指令能够使一个或多个处理器执行操作,这些操作包括:接收由至少一个传感器生成的传感器数据;用机器学习的默读解释模型来处理传感器数据以生成默读话语的解释作为机器学习的默读解释模型的输出。
至少一个传感器能够被配置成基于通过在用户的耳朵内由用户对默读话语进行默读产生的振动所产生的声波来生成传感器数据。传感器可以是系统的入耳式设备的一部分。入耳式设备能够与系统的至少一个辅助支持设备耦合。机器学习的默读解释模型能够被实现在入耳式设备中。机器学习的默读解释模型能够被实现在至少一个辅助支持设备中。
本公开的其他方面涉及各种系统、装置、非暂时性计算机可读介质、用户接口和电子设备。
参考以下描述和所附权利要求,本公开的各种实现方式的这些及其他特征、方面和优点将变得被更好地理解。被并入在本说明书中并构成本说明书的一部分的附图图示本公开的示例实现方式,并且与描述一起,用来说明相关原理。
附图说明
在参考附图的说明书中阐述针对本领域的普通技术人员的实现方式的详细讨论,在附图中:
图1A描绘根据本公开的示例实现方式的定位在用户的耳朵内的示例入耳式设备的图形图。
图1B-D描绘根据本公开的示例实现方式的包括入耳式设备的示例计算系统的框图。
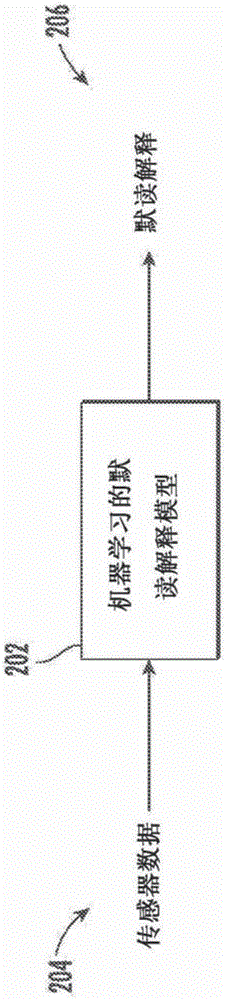
图2描绘根据本公开的示例实现方式的机器学习的默读解释模型的示例推理方案的框图。
图3描绘根据本公开的示例实现方式的机器学习的默读解释模型的示例训练方案的框图。
图4描绘根据本公开的示例实现方式的用于训练机器学习的模型的示例计算系统的框图。
跨越多个附图重复的附图标记旨在标识各种实现方式中的相同特征。
具体实施方式
图1A描绘根据本公开的示例实现方式的定位在用户的耳朵20内的示例入耳式设备10的图形图。设备10能够被至少部分地定位在外耳22中和/或至少部分地定位在诸如耳道24的内耳中。设备10能够包括如本文参考图1B所描述的一个或多个传感器,其能够生成描述在诸如在耳道24内的耳朵20中发生的现象的传感器数据。作为示例,现象能够包括移动、振动、音频信号、视觉变化、组织变形和/或在诸如在耳道24内的耳朵20内的其他现象。
作为一个特定示例,设备10能够包括定位在耳朵20内——例如至少部分地在耳道24内——并且指向耳道24——例如指向耳道内的鼓膜26——的一个或多个麦克风。设备10的麦克风能够记录在耳道内发生的由用户执行默读引起的音频信号。例如,音频信号能够至少部分地通过鼓膜26、骨传导和/或其他振动结构/组织的振动生成。
图1B-D描绘根据本公开的示例实现方式的包括入耳式设备的示例计算系统的框图。具体地参考图1B,示例入耳式设备102能够包括一个或多个处理器112和存储器114。一个或多个处理器112可以是任何合适的处理设备,诸如处理器核心、微处理器、ASIC、FPGA、控制器或微控制器,并且可以是一个处理器或在操作上连接的多个处理器。存储器114能够包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪速存储器设备、磁盘等及其组合。存储器114能够存储由处理器112执行以使用户计算设备102执行操作的数据116和指令118。
入耳式设备102能够包括一个或多个传感器119。传感器119中的至少一些能够生成描述在用户的耳朵中发生的现象的传感器数据。
作为一个示例,传感器119能够包括一个或多个麦克风,该一个或多个麦克风将位于用户的耳朵的耳道内的声波转换为传感器数据。例如,当入耳式设备102被放置在用户的耳朵内时,能够将一个或多个麦克风指向用户的鼓膜。在一些实现方式中,入耳式设备102能够包括不位于耳道内的一个或多个附加麦克风。例如,附加麦克风能够收集在用户的耳朵外部的音频信号,包括来自用户的嘴巴的用户的语音。
在一些实现方式中,附加麦克风能够用于从由指向用户的一个或多个麦克风记录的音频信号中滤除来自用户外部的源的音频信号。取决于来自用户外部的源的信号的音量和频率,这些信号可能泄漏到由指向用户的一个或多个麦克风记录的信号中。为了补偿这些附加信号,附加麦克风能够记录能够稍后从由指向用户的一个或多个麦克风记录的信号中标识和移除的外部音频。
在一些情况下,能够通过入耳式设备102在由用户穿戴时的形状、大小或预期位置来改进一个或多个麦克风在转换声波时的准确性。在一些实现方式中,入耳式设备102被成形为使得当按预期穿戴时,入耳式设备102齐平地坐落于用户的耳道中。在这些实现方式中,入耳式设备102的形状能够帮助将麦克风集中于拾取用户的耳道内的声波而不是来自用户外部的源的声波。
作为另外的示例,作为麦克风的补充或替代,传感器119能够包括下列中的一些或全部:加速度计;陀螺仪;雷达设备;声纳设备;激光麦克风;红外传感器;和/或气压计。例如,这些传感器能够诸如由加速度计、陀螺仪检测和记录运动/加速度;诸如由雷达设备、声纳设备、激光麦克风或红外传感器检测和记录耳朵中的物理变形,诸如鼓膜的变形/振动;并且/或者例如由气压计检测和记录耳朵中的压力变化。作为使用由如本文所描述的一个或多个麦克风捕获的音频数据的补充或替代,还能够使用由任何或所有这些传感器119收集的传感器数据。
作为又另外的示例,一个或多个传感器119能够包括温度计和/或接近传感器,诸如以导电涂层为特征的传感器。入耳式设备102能够分析由这些传感器生成的数据以确定入耳式设备102当前是否被放置在用户的耳朵内。如果设备不在用户的耳朵内,则能够暂停诸如传感器数据的收集的某些特征,直到当入耳式设备102被放置到耳朵中时的这种时间为止。
在一些实现方式中,入耳式设备102能够存储和实现一个或多个机器学习的模型120。例如,机器学习的模型120可以是或者能够以其他方式包括各种机器学习的模型,诸如神经网络或其他类型的机器学习的模型,包括非线性模型和/或线性模型。神经网络能够包括前馈神经网络、诸如长短期记忆循环神经网络的循环神经网络、卷积神经网络或其他形式的神经网络。参考图2-3讨论示例机器学习的模型120。
在一些实现方式中,入耳式设备102能够存储和实现基于AI的个人助理140。基于AI的个人助理140能够例如基于从用户接收到的输入代表用户执行某些操作或采取某些动作。基于AI的个人助理140的一个示例是谷歌助理。
在一些实现方式中,入耳式设备102能够存储和实现一个或多个应用142。应用142可以是任何应用,作为示例包括文本消息传送应用、电话呼叫应用、电子邮件应用、音乐应用、web搜索应用、web浏览应用、绘图应用、日历应用等。在一些实现方式中,基于AI的个人助理140能够使应用142执行各种操作,例如通过一个或多个应用编程接口。
在一些实现方式中,入耳式设备102能够包括一个或多个扬声器144。例如,当设备102在用户的耳朵中时,扬声器144也能够被指向用户的鼓膜。扬声器144能够用于播放音乐,向用户提供电话音频,从基于AI的个人助理140返回对话等。
现在参考图1C和图1D,在一些实现方式中,参考图1B描述的一些或所有组件能够位于辅助计算设备130而不是入耳式设备102中。例如,能够做这个以使入耳式设备102变得更轻、更便宜、更小等。
作为一个示例,参考图1C,模型120仍然被存储在入耳式设备102处并由入耳式设备102实现,但是基于AI的个人助理设备140和应用142被存储在辅助计算设备130处并由辅助计算设备130实现。在此场景中,入耳式设备102能够将由入耳式设备102接收到的音频信号的由模型120提供的解释传送到辅助计算设备130。
作为另一示例,参考图1D,所有模型120、基于AI的个人助理设备140和应用142都被存储在辅助计算设备130处并由辅助计算设备130实现。入耳式设备102能够将由传感器119生成的传感器数据传送到辅助计算设备130。
尽管被示出为入耳式设备102的一部分,但是模型120能够被实现在入耳式设备102之外。例如,模型120能够被实现在诸如服务器或辅助计算设备130的另一设备上。如果模型120未被直接实现在入耳式设备102上,则入耳式设备102能够被配置成传送和接收与模型120的输入和输出相对应的数据,如在下面更详细地描述的那样。发送到远离入耳式设备102的设备上的模型120的输入可以是由传感器119接收到的原始输入,或来自由传感器119接收到的原始输入的至少部分地处理的数据。
辅助计算设备130可以是任何不同类型的计算设备,包括智能电话、平板、膝上型电脑、服务器计算设备、能够被穿戴的计算设备、嵌入式计算设备、车辆计算设备、导航计算设备、游戏控制台等。
在一些实现方式中,入耳式设备102和/或辅助计算设备130能够包括要例如通过数据连接和/或Wi-Fi连接来连接到局域网或广域网或总体上更大的因特网的网络接口。
示例模型布置
图2描绘根据本公开的示例实现方式的机器学习的默读解释模型202的示例推理方案的框图。机器学习的默读解释模型202能够接收并处理由入耳式设备并在用户对话语进行默读的同时从用户的耳朵内收集的传感器数据204。机器学习的默读解释模型202能够处理传感器数据204以生成默读话语的解释206。
在一些情况下,与被训练来处理可听或非默读话语的模型相比,传感器数据204能够提供可以由模型202以更细微方式处理以便生成解释206的输入。这是至少因为传感器数据204可能对由用户执行的不涉及语音的不同身体动作例如打喷嚏、咀嚼或饮酒更敏感。传感器数据204能够通过相对于对应于由用户安静地讲出的命令或词的默读话语具有不同的物理性质——例如,音高、频率或音调——的话语来表示这些动作。
例如,当用户正在吃饭时对比当用户正在对命令进行默读时,由指向用户的鼓膜的麦克风收集的传感器数据204能够具有明显不同的特征。能够训练模型202来解释这些不同的特征以区分由用户默读的话语和由咀嚼或饮酒引起的噪声。
传感器数据204中的差异能够对应于用户的身体响应于像安静地讲话或饮酒一样的正常功能的生理变化。例如,当由话语引起的振动穿过经历与讲话、打喷嚏或饮酒有关的不同身体功能的身体时,由麦克风拾取的记录话语可能被翘曲、放大或静音。作为另一示例,耳朵的咽鼓管或其他部分能够取决于用户是否患感冒、流感或过敏而改变形状。例如,这些或其他疾病可能使耳朵的一部分发炎或积液,这可能使传感器数据204相对于在用户未生病时记录的传感器数据变化。例如,由于当用户生病/未生病时用户的耳朵中的声学差异,可能发生变化。因此,能够训练模型202来学习这些差异,当检测到仅可听语音时,这些差异可能不那么显著。
能够训练模型202来处理传入传感器数据204并且从传感器数据204生成一个或多个特征。特征是指数据的可量化或分类特性。作为示例,传入传感器数据204的音高、频率和音量可以是由模型202用于生成解释206的特征。模型202能够生成一些特征作为其他特征的函数,诸如随着时间推移而测量的特征。作为示例,一个这种特征可以是传入传感器数据204在时间段内的音量。模型202能够生成表示传感器数据204在时间段内的平均音量的特征,或者模型202能够标识随着时间推移的音量变化的模式。例如,后者能够指示由用户进行的重复动作,诸如咀嚼然后在咀嚼之间暂停。作为训练的一部分并如本文所描述的,能够训练模型202来标识不同的特征和/或标识哪些特征对于生成解释206比其他特征更相关。
作为生成特征的一部分,模型202能够将传入传感器数据204转换成不同的格式。例如,模型202能够接收默读话语并将话语转换成频谱图。频谱图是音频信号在某个域之上的视觉表示。例如,频谱图能够在视觉上表示音频信号在一时间段内的频率变化。模型202能够处理频谱图以从传入传感器数据204生成附加特征。例如,模型202能够从如频谱图中指示的那样表示传入传感器数据204中的频率中由变化所引起的振幅变化的频谱图生成特征。
用于将传感器数据204转换成不同的格式的一个原因是能够利用特定于给定格式的特征提取技术。例如,通过将传入传感器数据204转换为频谱图,模型202能够对于图像数据利用各种不同的机器学习特征生成技术中的任一种,这些技术可能尚不适用于作为默读话语的传入传感器数据204。
作为示例,解释206能够包括默读话语的文本转录和/或将默读话语分类成多个预定义类,这多个预定义类可以对应于多个预定义命令或动作,诸如“Play my favorite album”。因此,在一些实现方式中,机器学习的默读解释模型202能够将传感器数据204翻译成能够诸如由相同模型202或另一模型翻译成以下各项的表示:(a)特殊命令,诸如“what's the time?”、“when is my next meeting?”、“play music”;(b)文本,诸如“send email to my partner that I bought ingredients and will cook dinner tonight”;和/或(c)语音,诸如“make a call to the dentist”或“Hello,I'd like to book an appointment next week”。例如,默读话语的解释206能够例如由基于人工智能(AI)的个人助理使用,以引起一个或多个操作,例如录入文本转录或对文本转录做出响应或执行所请求的动作,诸如播放某个音乐专辑或预约。因此,机器学习的模型202能够被配置成将传感器数据204解码成可动作和/或可理解解释206,诸如默读话语的文本转录。
另外,因为解释206能够包括文本转录,所以能够用机器学习的默读解释模型202和被配置成接收文本转录作为输入的另一模型来端到端地处理接收到的默读话语。第二模型可以是基于(AI)的助理或被配置成接收文本转录作为输入并且使入耳式设备102、辅助计算设备130或另一设备中的一个或多个响应于文本转录而执行操作的另一模型。
例如,能够训练被配置成接收解释206的文本转录的模型来阅读转录,标识一个或多个特殊命令或文本,并且使设备102、130响应于经标识的命令或文本而执行动作。能够根据用于使用机器学习来处理文本的各种不同的技术中的任一种来配置被配置成接收文本转录的模型。因此,模型202能够生成能够由被配置成接收文本转录作为输入的任何模型灵活地使用的解释206。在一些实现方式中,模型202被训练来使设备120、130在不使用附加模型的情况下响应于解释206中表示的命令或文本而执行动作。
入耳式设备102能够被配置成连续地处理转录或者处理传入信号以搜索特殊命令的存在,与用于“热词检测”的技术一致。换句话说,入耳式设备102能够被配置成仅在检测或一个或多个特殊命令或热词时才开始传入数据的后续处理。
解释206还能够包括输出可听音频信号,诸如不是默读的音频,在一些实现方式中默读解释模型202被配置成从传感器数据204生成所述不是默读的音频。输出可听音频信号能够对应于记录的默读话语中讲出的命令或词。输出音频信号能够由被配置成接收并处理音频信号以标识特殊命令或语音的另一模型来处理。此附加模型可以是基于(AI)的助理或另一模型。此附加模型能够被进一步配置成将表示来自音频信号的经标识的特殊命令或语音的数据传递到被配置成使设备102、130响应于经标识的命令或文本而执行动作的另一模型。在一些实现方式中,模型202被训练来使设备120、130在不使用附加模型的情况下响应于解释206中表示的命令或语音而执行动作。
现在参考图3,在一些实现方式中,能够在监督学习方法中训练机器学习的默读模型202。训练数据集302能够包括在一个人正在对具有地面实况解释的已知字符串进行默读的同时收集的训练传感器数据304的集合,诸如由麦克风捕获的音频信号。因此,由模型202在每个训练传感器数据304的集合上提供的解释306能够使用损失函数356来与地面实况解释354进行比较。能够使用损失函数356来训练模型202以计算损失函数356相对于诸如神经网络的权重的模型参数值的梯度。例如,能够随着损失函数356反向传播通过模型202而更新模型202的参数的值。
在一些实现方式中,训练数据集302能够包括作为用户训练/引导过程的一部分而收集的数据,在所述用户训练/引导过程中新用户被要求执行已知内容的默读,诸如通过在不推动空气通过用户的声带的情况下阅读某些文本。能够基于校准数据来训练、重新训练、完善或个性化模型202,诸如通过使用本文参考图3描述的监督方案。这能够使得默读解释模型202能够对于特定用户具有改进的准确性。模型202能够执行此训练过程一次,例如当用户第一次或者多次——例如周期性地或响应于用户请求——操作入耳式设备102时。
附加地或替换地,在一些实现方式中,能够首先在通用可听语音示例上训练默读模型。然后能够经由迁移学习完善在正常音频上训练的模型以在默读数据上训练。在一些实现方式中,不是修改较低层,而是能够简单地向迁移模型的顶部添加较高层。模型能够从自底向上的、以通过在正常音频上训练的较低层然后通过所添加的较高层处理的输入默读开始来处理输入。能够在经由入耳式麦克风阵列从各种用户收集的较小数据集上训练这些添加的较高层。
能够训练所添加的较高层以学习由较低层处理的哪个特征或哪些特征与生成解释206相关。例如,模型的较低层能够在通用可听语音示例上被训练,并且能够被配置成生成表示输入默读的特征的已处理数据作为中间输出。在来自各种用户的默读话语的数据集上训练的模型的较高层能够接收中间输出作为输入。能够训练模型的较高层来学习用于处理输入默读的一些或全部特征的权重,例如使用本文参考图4描述的各种学习技术中的任一种。在处理期间,较高层可以从中间输出中表示的特征生成一个或多个附加特征。
通过以至少部分地在可听语音示例上训练的模型开始,依照本公开的各方面,能够更快地训练模型来生成默读话语的解释。如本文所描述的那样训练模型可以是有利的,至少因为标记语音示例可听语音可能对比默读语音的标记语音示例更容易大量获得。即使两种形式的语音示例都可容易地获得,在一些实现方式中也能够如本文所描述的那样训练模型来更准确地生成默读话语的解释,至少因为对比在单独在默读话语的较小集合上训练,能够从由两种类型的示例进行的训练的更大组合来训练模型。
示例训练环境
图4描绘根据本公开的示例实现方式的用于训练机器学习的模型的示例计算系统400的框图。系统400包括通过网络480通信地耦合的用户计算设备402、服务器计算系统430和训练计算系统450。
用户计算设备402可以是任何类型的计算设备,诸如例如个人计算设备(诸如膝上型计算机或台式计算机)、移动计算设备(诸如智能电话或平板)、游戏控制台或控制器、可穿戴计算设备、嵌入式计算设备、或任何其他类型的计算设备。
在一些实现方式中,用户计算设备402能够存储或包括一个或多个机器学习的模型420。例如,机器学习的模型420可以是或能够以其他方式包括各种机器学习的模型,诸如神经网络,例如深度神经网络,或其他类型的机器学习的模型,包括非线性模型和/或线性模型。神经网络能够包括前馈神经网络、循环神经网络(诸如长短期记忆循环神经网络)、卷积神经网络或其他形式的神经网络。
在一些实现方式中,一个或多个机器学习的模型420能够通过网络480从服务器计算系统430接收,然后存储和实现在用户计算设备402处。在一些实现方式中,用户计算设备402能够实现单个机器学习的模型420的多个并行实例,诸如以跨越传感器数据的多个实例执行并行默读解释。
附加地或替换地,一个或多个机器学习的模型440能够被包括在服务器计算系统430中或者由服务器计算系统430以其他方式存储和实现,所述服务器计算系统430根据客户端-服务器关系与用户计算设备402进行通信。例如,机器学习的模型440能够由服务器计算系统440实现为web服务的一部分,诸如默读解释服务。因此,一个或多个模型420能够被存储和实现在用户计算设备402处并且/或者一个或多个模型440能够被存储和实现在服务器计算系统430处。
用户计算设备402还能够包括接收用户输入的一个或多个用户输入组件422。例如,用户输入组件422可以是触敏组件,诸如对诸如手指或触针的用户输入对象的触摸敏感的触敏显示屏或触摸板。触敏组件能够用来实现虚拟键盘。其他示例用户输入组件包括麦克风、传统键盘、或用户能够通过其提供用户输入的其他手段。
服务器计算系统430包括一个或多个处理器432和存储器434。一个或多个处理器432可以是任何合适的处理设备,诸如处理器核心、微处理器、ASIC、FPGA、控制器或微控制器,可以是一个处理器或在操作上连接的多个处理器。存储器434能够包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪速存储器设备或磁盘及其组合。存储器434能够存储由处理器432执行以使服务器计算系统430执行操作的数据436和指令438。
在一些实现方式中,服务器计算系统430包括一个或多个服务器计算设备或者由一个或多个服务器计算设备以其他方式实现。在服务器计算系统430包括多个服务器计算设备的情况下,此类服务器计算设备能够根据顺序计算架构、并行计算架构或其某种组合来操作。
如上所述,服务器计算系统430能够存储或以其他方式包括一个或多个机器学习的模型440。例如,模型440可以是或者能够以其他方式包括各种机器学习的模型。示例机器学习的模型包括神经网络或其他多层非线性模型。示例神经网络包括前馈神经网络、深度神经网络、递归神经网络和卷积神经网络。
用户计算设备402和/或服务器计算系统430能够经由与通过网络480通信地耦合的训练计算系统450的交互来训练模型420和/或440。训练计算系统450能够与服务器计算系统430分开或者可以是服务器计算系统430的一部分。
训练计算系统450包括一个或多个处理器452和存储器454。一个或多个处理器452可以是任何合适的处理设备,诸如处理器核心、微处理器、ASIC、FPGA、控制器或微控制器,并且可以是一个处理器或在操作上连接的多个处理器。存储器454能够包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪速存储器设备或磁盘及其组合。存储器454能够存储由处理器452执行以使训练计算系统450执行操作的数据456和指令458。在一些实现方式中,训练计算系统450包括一个或多个服务器计算设备或者由一个或多个服务器计算设备以其他方式实现。
训练计算系统450能够包括模型训练器460,其使用各种训练或学习技术(诸如例如误差的反向传播)来训练存储在用户计算设备402和/或服务器计算系统430处的机器学习的模型420和/或440。例如,损失函数能够通过模型反向传播以例如基于损失函数的梯度更新模型的一个或多个参数。能够使用各种损失函数,诸如均方误差、似然损失、交叉熵损失、合页损失和/或各种其他损失函数。梯度下降技术能够用于在许多训练迭代上迭代地更新参数。
在一些实现方式中,执行反向传播能够包括执行通过时间的截断反向传播。模型训练器460能够执行许多泛化技术,诸如衰减权重或执行暂退(dropout),以改进正在训练的模型的泛化能力。
特别地,模型训练器460能够基于训练数据462的集合来训练机器学习的模型420和/或440。训练数据462能够包括例如监督训练数据,包括例如在校准例程期间生成的用户特定监督训练数据。
因此,在一些实现方式中,如果用户已提供同意,则训练示例能够由用户计算设备402提供。因此,在此类实现方式中,提供给用户计算设备402的模型420能够由训练计算系统450在从用户计算设备402接收到的用户特定数据上训练。在一些情况下,能够将此过程称为使模型个性化。
模型训练器460包括用于提供期望功能性的计算机逻辑。能够在硬件、固件和/或控制通用处理器的软件中实现模型训练器460。例如,在一些实现方式中,模型训练器460包括存储在存储设备上、加载到存储器中并由一个或多个处理器执行的程序文件。在其他实现方式中,模型训练器460包括被存储在诸如RAM硬盘或光学或磁介质的有形计算机可读存储介质中的计算机可执行指令的一个或多个集合。
模型训练器460能够根据与模型训练相关联的不同超参数(诸如不同的学习速率、批大小和与所实现的特定类型的模型相关联的其他超参数)或用于训练模型420的特定技术来训练默读解释模型420。模型训练器460还能够实现用于超参数搜索或优化的任何种类的技术,例如随机搜索,或者在模型的集合体上基于群体或进化的技术。
网络480可以是任何类型的通信网络,诸如局域网(诸如内联网)、广域网(诸如因特网)或其某种组合,并且能够包括任何数目的有线或无线链路。一般而言,网络480上的通信能够使用各式各样通信协议(诸如TCP/IP、HTTP、SMTP、FTP)、编码或格式(诸如HTML、XML)和/或保护方案(诸如VPN、安全HTTP或SSL)来经由任何类型的有线和/或无线连接承载。
图4图示能够用于实现本公开的一个示例计算系统。也能够使用其他计算系统。例如,在一些实现方式中,用户计算设备402能够包括模型训练器460和训练数据集462。在此类实现方式中,能够在用户计算设备402处既训练又在本地使用模型420。在一些此类实现方式中,用户计算设备402能够实现模型训练器460以基于用户特定数据使模型420个性化。换句话说,模型训练器460能够离线、在线或根据混合方法训练模型420。
本文讨论的技术参考服务器、数据库、软件应用和其他基于计算机的系统,以及所采取的动作和往返于此类系统发送的信息。基于计算机的系统的固有灵活性允许在组件之间和当中实现任务和功能性的各式各样可能的配置、组合和划分。例如,本文讨论的过程能够使用单个设备或组件或相结合地工作的多个设备或组件来实现。数据库和应用能够被实现在单个系统上或者跨越多个系统分布。分布式组件能够顺序地或并行地操作。
虽然已经相对于本主题的各种特定示例实现方式详细地描述了本主题,但是每个示例是作为说明而不是对本公开的限制来提供的。本领域的技术人员在获得对前文的理解后,能够容易地产生此类实现方式的变更、变化和等同物。因此,本主题公开不排除包括如对于本领域的普通技术人员而言将容易地显而易见的对本主题的此类修改、变化和/或添加。例如,作为一个实现方式的一部分图示或描述的特征能够与另一实现方式一起使用以产生再一个实现方式。因此,本公开旨在涵盖此类变更、变化和等同物。
尽管本公开的各方面集中于被配置成被定位在用户的耳朵内的入耳式设备,但是本文描述的原理也能够适于从相对于用户的身体定位在其他位置上的传感器收集的传感器数据的解释。例如,在由用户默读期间由一副眼镜中的传感器——诸如由定位在眼镜的桥接器上以便接触用户的节点的桥接器的传感器——收集的数据能够使用机器学习来分析以生成默读的解释。作为另一示例,在由用户默读期间由领带中的传感器——诸如由定位在领带上以便接触诸如用户会厌的用户颈部的传感器——收集的数据能够使用机器学习来分析以生成默读的解释。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。