技术特征:
1.一种电子设备,包括:
一个或多个传感器;
一个或多个处理器;以及
一个或多个非暂时性计算机可读介质,所述一个或多个非暂时性计算机可读介质存储指令,所述指令在由所述一个或多个处理器执行时,使所述电子设备执行操作,所述操作包括:
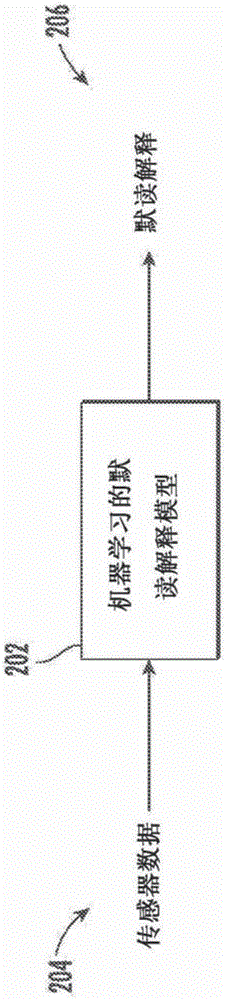
接收由所述一个或多个传感器中的被至少部分定位在用户的耳朵内的至少一个传感器生成的传感器数据,其中,所述传感器数据由所述至少一个传感器与所述用户对默读话语进行默读同时生成;
利用机器学习的默读解释模型来处理所述传感器数据以生成所述默读话语的解释作为所述机器学习的默读解释模型的输出。
2.根据权利要求1所述的电子设备,其中,所述至少一个传感器包括一个或多个麦克风,所述一个或多个麦克风将位于所述用户的所述耳朵的耳道内的声波转换为所述传感器数据。
3.根据权利要求2所述的电子设备,其中,位于所述用户的所述耳朵的耳道内的所述声波由所述用户的鼓膜生成。
4.根据权利要求2或3所述的电子设备,其中,在所述一个或多个麦克风被放置在所述用户的所述耳朵内时,所述一个或多个麦克风被指向所述用户的所述鼓膜。
5.根据前述权利要求中的任一项所述的电子设备,其中,所述至少一个传感器包括以下中的一个或多个:
加速度计;
陀螺仪;
雷达设备;
声纳设备;
激光麦克风;
红外传感器;或
气压计。
6.根据权利要求1所述的电子设备,其中,所述电子设备被调整大小和成形以被至少部分定位在所述用户的所述耳朵内。
7.根据权利要求1-6中的任一项所述的电子设备,其中,所述电子设备耦合到与所述至少一个传感器物理上分开的辅助支持设备。
8.根据前述权利要求中的任一项所述的电子设备,其中,由所述机器学习的默读解释模型输出的所述默读话语的所述解释包括所述默读话语的文本形式的转录。
9.根据前述权利要求中的任一项所述的电子设备,其中,由所述机器学习的默读解释模型输出的所述默读话语的所述解释包括将所述默读话语分类成多个类别中的一个或多个。
10.根据权利要求9所述的电子设备,其中,所述多个类别包括多个定义的命令。
11.根据前述权利要求中的任一项所述的电子设备,其中,所述操作还包括:
由基于人工智能的个人助理系统至少部分基于由所述机器学习的默读解释模型输出的所述默读话语的所述解释来确定要执行的至少一个操作。
12.一种耳塞,包括:
至少一个传感器;
一个或多个处理器;以及
一个或多个非暂时性计算机可读介质,所述一个或多个非暂时性计算机可读介质存储指令,所述指令在由所述一个或多个处理器执行时,使所述耳塞执行操作,所述操作包括:
接收由所述至少一个传感器生成的传感器数据,其中,所述传感器数据由所述至少一个传感器与所述用户对默读话语进行默读同时生成,并且其中所述至少一个传感器被至少部分定位在用户的耳朵内;
利用机器学习的默读解释模型来处理所述传感器数据以生成所述默读话语的解释作为所述机器学习的默读解释模型的输出。
13.根据权利要求12所述的耳塞,其中,所述至少一个传感器包括麦克风,所述麦克风将位于所述用户的所述耳朵的耳道内的声波转换为所述传感器数据。
14.根据权利要求13所述的耳塞,其中,位于所述用户的所述耳朵的耳道内的所述声波由所述用户的鼓膜生成。
15.根据权利要求13或14所述的耳塞,其中,在所述麦克风被放置在所述用户的所述耳朵内时,所述麦克风被指向所述用户的所述鼓膜。
16.根据权利要求12至15中的任一项所述的耳塞,其中,由所述机器学习的默读解释模型输出的所述默读话语的所述解释包括所述默读话语的文本形式的转录。
17.根据权利要求12至16中的任一项所述的耳塞,其中,由所述机器学习的默读解释模型输出的所述默读话语的所述解释包括将所述默读话语分类成多个类别中的一个或多个。
18.根据权利要求17所述的耳塞,其中,所述多个类别包括多个定义的命令。
19.根据权利要求12至18中的任一项所述的耳塞,其中,所述操作还包括:
由基于人工智能的个人助理系统至少部分基于由所述机器学习的默读解释模型输出的所述默读话语的所述解释来确定要执行的至少一个操作。
20.一种方法,包括:
由至少部分定位在用户的耳朵内的至少一个传感器生成表示由所述用户做出的默读话语的传感器数据;以及
利用机器学习的默读解释模型来处理所述传感器数据以生成所述默读话语的解释作为所述机器学习的默读解释模型的输出。
21.根据权利要求20所述的方法,其中,所述传感器数据基于通过在所述用户的所述耳朵内由所述用户对所述默读话语进行默读产生的振动所产生的声波。
22.根据权利要求20或权利要求21所述的方法,其中,所述传感器是入耳式设备的一部分。
23.根据权利要求22所述的方法,其中,所述入耳式设备与至少一个辅助支持设备耦合。
24.根据权利要求22或23所述的方法,其中,所述机器学习的默读解释模型被实现在所述入耳式设备中。
25.根据权利要求23所述的方法,其中,所述机器学习的默读解释模型被实现在所述至少一个辅助支持设备中。
26.一种系统,包括:
至少一个传感器,所述至少一个传感器被配置成被至少部分定位在用户的耳朵内并且与所述用户对默读话语进行默读同时生成传感器数据,
一个或多个处理器;以及
一个或多个非暂时性计算机可读介质,所述一个或多个非暂时性计算机可读介质存储指令,所述指令在由所述一个或多个处理器执行时,使所述一个或多个处理器执行操作,所述操作包括:
接收由所述至少一个传感器生成的所述传感器数据;
利用机器学习的默读解释模型来处理所述传感器数据以生成所述默读话语的解释作为所述机器学习的默读解释模型的输出。
27.根据权利要求26所述的系统,其中,所述至少一个传感器被配置成基于通过在所述用户的所述耳朵内由所述用户对所述默读话语进行默读产生的振动所产生的声波来生成所述传感器数据。
28.根据权利要求26或27所述的系统,其中,所述传感器是所述系统的入耳式设备的一部分。
29.根据权利要求28所述的系统,其中,所述入耳式设备与所述系统的至少一个辅助支持设备耦合。
30.根据权利要求28或29所述的系统,其中,所述机器学习的默读解释模型被实现在所述入耳式设备中。
31.根据权利要求29所述的系统,其中,所述机器学习的默读解释模型被实现在所述至少一个辅助支持设备中。
技术总结
提供的是一种入耳式设备和相关联的计算支持系统,该相关联的计算支持系统利用机器学习来解释描述由用户默读期间的一个或多个入耳式现象的传感器数据。一种电子设备能够接收由至少部分定位在用户的耳朵内的至少一个传感器生成的传感器数据,其中,该传感器数据由至少一个传感器与用户对默读话语进行默读同时生成。该电子设备然后能够用机器学习的默读解释模型来处理传感器数据以生成默读话语的解释作为机器学习的默读解释模型的输出。
技术研发人员:雅罗斯拉夫·沃洛维奇;安特·厄兹塔斯肯特;布勒斯·阿格拉-阿尔卡斯;
受保护的技术使用者:谷歌有限责任公司;
技术研发日:2020.11.24
技术公布日:2022.05.13
本文用于企业家、创业者技术爱好者查询,结果仅供参考。