1.本公开涉及计算机技术领域,特别涉及一种语音识别方法、语音识别装置和非易失性计算机可读存储介质。
背景技术:
2.5g网络与互联网的兴起,语音识别应用的场景越来越多,持续提升语音识别的准确率与召回率格外重要。
3.在相关技术中,使用统一的语音识别模型对场景中的语音进行识别。
技术实现要素:
4.本公开的发明人发现上述相关技术中存在如下问题:统一的语音识别模型难以兼顾不同特征的语音发出方,导致语音识别的准确率下降。
5.鉴于此,本公开提出了一种语音识别技术方案,能够提高语音识别的准确率。
6.根据本公开的一些实施例,提供了一种语音识别方法,包括:对视频流中各帧图像进行人体识别,确定各帧图像中语音发出方的生理特征;根据不同的语音发出方的生理特征,确定所述不同的语音发出方对应的语音识别模型;利用所述不同的语音发出方对应的语音识别模型,识别所述不同的语音发出方的语音,确定语音识别结果。
7.在一些实施例中,所述确定不同的语音发出方的语音识别模型包括:根据各帧图像对应的生理特征,确定各帧图像对应的唇形识别模型;所述确定语音识别结果包括:根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定所述语音识别结果。
8.在一些实施例中,所述确定所述不同的语音发出方对应的语音识别模型包括:根据所述视频流的时间轴信息,将所述视频流中的各帧图像与所述视频流对应的音频流中的各帧语音进行关联;根据关联结果,确定与各帧语音对应的语音处理模型;所述确定语音识别结果包括:根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定所述语音识别结果。
9.在一些实施例中,所述确定语音识别结果包括:根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定第一语音识别结果;根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定第二语音识别结果;根据所述第一语音识别结果和所述第二语音识别结果的加权平均值,确定综合语音识别结果作为所述语音识别结果。
10.在一些实施例中,语音识别方法还包括:对所述视频流进行图像场景识别,确定所述视频流的场景类型;根据所述场景类型,确定与所述场景类型相匹配的降噪处理模型;利所述降噪处理模型对所述视频流对应的音频流进行降噪处理;所述确定语音识别结果包括:利用不同的语音识别模型对降噪后的音频流进行处理,以确定所述语音识别结果。
11.在一些实施例中,所述场景类型包括户外场景、户内场景、多发声源场景中的多项,所述降噪处理模型包括匹配户外场景的循环神经网络户外降噪模型、匹配户内场景的循环神经网络户内降噪模型、匹配多发声源场景的人声增强与提取算法模型中的多项。
12.在一些实施例中,所述生理特征包括性别特征、年龄特征中的至少一项。
13.在一些实施例中,所述语音识别模型包括用于成人语音识别模型、用于小孩的语音识别模型。
14.根据本公开的另一些实施例,提供一种语音识别装置,包括:特征确定单元,用于对视频流中各帧图像进行人体识别,确定各帧图像中语音发出方的生理特征;模型确定单元,用于根据不同的语音发出方的生理特征,确定所述不同的语音发出方对应的语音识别模型;识别单元,用于利用所述不同的语音发出方对应的语音识别模型,识别所述不同的语音发出方的语音,确定语音识别结果。
15.一些实施例中,所述模型确定单元根据各帧图像对应的生理特征,确定各帧图像对应的唇形识别模型;所述识别单元根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定所述语音识别结果。
16.在一些实施例中,所述模型确定单元根据所述视频流的时间轴信息,将所述视频流中的各帧图像与所述视频流对应的音频流中的各帧语音进行关联,根据关联结果,确定与各帧语音对应的语音处理模型;所述识别单元根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定所述语音识别结果。
17.在一些实施例中,所述识别单元根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定第一语音识别结果,根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定第二语音识别结果,根据所述第一语音识别结果和所述第二语音识别结果的加权平均值,确定综合语音识别结果作为所述语音识别结果。
18.在一些实施例中,所述特征确定单元对所述视频流进行图像场景识别,确定所述视频流的场景类型;所述模型确定单元根据所述场景类型,确定与所述场景类型相匹配的降噪处理模型;利用所述降噪处理模型对所述视频流对应的音频流进行降噪处理;所述识别单元利用不同的语音识别模型对降噪后的音频流进行处理,以确定所述语音识别结果。
19.根据本公开的又一些实施例,提供一种语音识别装置,包括:存储器;和耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器装置中的指令,执行上述任一个实施例中的语音识别方法。
20.根据本公开的再一些实施例,提供一种非易失性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述任一个实施例中的语音识别方法。
21.在上述实施例中,根据各帧图像中语音发出方的生理特征,建立语音发出方与语音的关联,并根据语音发出方的生理特征确定匹配的语音识别模型处理关联的语音。这样,能够为不同生理特征的语音发出方匹配相应的语音识别模型,从而提高语音识别的准确率。
附图说明
22.构成说明书的一部分的附图描述了本公开的实施例,并且连同说明书一起用于解释本公开的原理。
23.参照附图,根据下面的详细描述,可以更加清楚地理解本公开,其中:图1示出本公开的语音识别方法的一些实施例的流程图;
图2示出本公开的语音识别方法的另一些实施例的流程图;图3a示出本公开的降噪处理方法的一些实施例的流程图;图3b示出本公开的降噪处理方法的一些实施例的示意图;图3c示出本公开的降噪处理方法的另一些实施例的示意图;图3d示出本公开的唇形识别方法的一些实施例的示意图;图3e示出本公开的唇形识别方法的另一些实施例的示意图;图4a示出本公开的语音识别方法的一些实施例的示意图;图4b示出本公开的语音识别方法的另一些实施例的示意图;图5示出本公开的语音识别装置的一些实施例的框图;图6示出本公开的语音识别装置的另一些实施例的框图;图7示出本公开的语音识别装置的又一些实施例的框图。
具体实施方式
24.现在将参照附图来详细描述本公开的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本公开的范围。
25.同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
26.以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。
27.对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为授权说明书的一部分。
28.在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
29.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
30.如前所述,统一的语音识别模型难以兼顾不同特征的语音发出方,导致语音识别的准确率下降。
31.例如,在低幼年龄段的语言类教学中,发音拼读场景是很常见的场景。但是,幼龄儿童因为年纪较小,发音,拼读能力较差,因此她们的学习过程中经常会有父母领读,儿童跟读的情况。
32.这就给语音识别带来了较大的困难:一方面,难以区分当前朗读的是大人还是孩子;另一方面,单一的语音识别算法也难以兼顾到大人和孩子不同而声学特点,而给出较为合理的分数。
33.另外,嘈杂的背景音也会对语音识别带来较大的影响。
34.针对上述技术问题,本公开结合语音识别和图像识别的效果,将语图像识别作为语音识别的辅助提升手段,从而整体提升识别效果。
35.本公开在语音识别的过程中,引入视频分析;利用分析出的场景特点、人群特点、以及时间轴对齐等方式,判断出当前说话人;建立起人声与视频中说话人的联系;将根据说
话人的唇形特点,利用唇形识别模型的识别结果,与语音处理模型的识别结果进行叠加优化,最终得到更准确的识别效果。
36.例如,可以通过下面的实施例实现本公开的技术方案。
37.图1示出本公开的语音识别方法的一些实施例的流程图。
38.如图1所示,在步骤110中,对视频流中各帧图像进行人体识别,确定各帧图像中语音发出方的生理特征。例如,理特征包括性别特征、年龄特征中的至少一项。
39.在步骤120中,根据不同的语音发出方的生理特征,确定不同的语音发出方对应的语音识别模型。例如,语音识别模型包括用于成人语音识别模型、用于小孩的语音识别模型。
40.在一些实施例中,根据各帧图像对应的生理特征,确定各帧图像对应的唇形识别模型。
41.例如,根据视频流的时间轴信息,将视频流中的各帧图像与视频流对应的音频流中的各帧语音进行关联;根据关联结果,确定与各帧图像关联的各帧语音对应的语音处理模型。
42.例如,确定各帧图像中语音发出方的生理特征(如年龄、性别等);根据各帧图像中语音发出方的生理特征,确定与各帧图像关联的各帧语音的语音识别模型。
43.在一些实施例中,根据视频流的场景类型,对音频流匹配相应的降噪方案;对视频流进行人体识别和唇形识别,结合音频流时间轴,建立起声音与人像的关联;提取出说话人的生理特点(如性别、年龄等),匹配相应的语音识别算法。
44.在步骤130中,利用不同的语音发出方对应的语音识别模型,识别不同的语音发出方的语音,确定语音识别结果。
45.在一些实施例中,根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定语音识别结果。还可以根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定语音识别结果。
46.在一些实施例中,将唇形识别的结果和语音处理的结果进行加权修正,给出校正后的语音识别结果。
47.例如,唇语识别模型可采取拼音序列识别方案:先经过vgg
‑
m(visual geometry group,视觉几何组)卷积神经网络模型对帧图像进行卷积运算;然后进行批规范化、rnn(recurrent neural network,循环神经网络)网络处理等多个环节,最终得到帧图像中唇形与识别的文字的对应结果。
48.在一些实施例中,可以根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定第一语音识别结果;根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定第二语音识别结果;根据第一语音识别结果和第二语音识别结果的加权平均值,确定综合语音识别结果作为语音识别结果。
49.例如,唇形识别模型确定的第一语音识别结果包括语料库中各候选词的第一候选概率;语音处理模型确定的第二语音识别结果包括语料库中各候选词的第二候选概率;对分别对各候选词的第一候选概率和第二候选概率计算加权平均值,得到各候选词的综合候选概率,以确定综合语音识别结果。
50.在一些实施例中,第一语音识别结果的权重大于第二语音识别结果的权重。
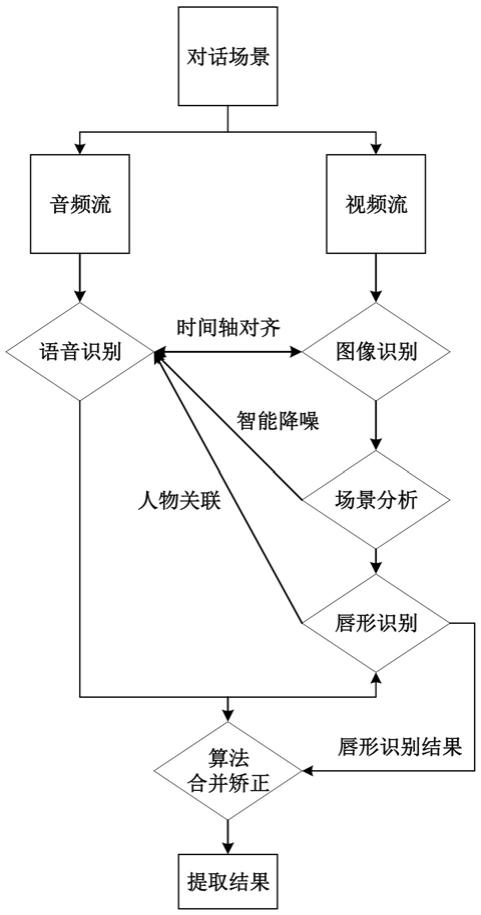
51.在一些实施例中,根据场景类型,确定匹配的降噪处理模型;利用降噪处理模型对视频流对应的音频流进行降噪处理;利用不同的语音识别模型对降噪处理后的音频流进行处理,确定语音识别结果。
52.例如,场景类型可以包括户外场景、户内场景、多发声源场景中的多项;降噪处理模型可以包括匹配户外场景的循环神经网络户外降噪模型、匹配户内场景的循环神经网络户内降噪模型、匹配多发声源场景的人声增强与提取算法模型中的多项。
53.在一些实施例中,可以对视频流进行图像场景识别,获取场景类型,以匹配相应的降噪方案。例如,可以通过机器学习方法进行图像场景识别,降噪方案可以包括l1、l2、l3。
54.例如,降噪方案l1可以包括基于户外背景音(如街道、汽车、大自然等)场景训练的算法模型,如rnnoise
‑
outdoors(循环神经网络户外降噪)模型。
55.降噪方案l2可以包括基于户内背景音(人教室、商场等)场景训练的算法模型,如rnnoise
‑
indoors(循环神经网络户内降噪)模型。
56.降噪方案l3可以包括人声增强与提取算法模型,如谱减法模型、维纳滤波模型等。
57.在一些实施例中,对音频流进行降噪处理(如降噪方案l3)后,再利用匹配的语音处理模型(如成人模型或小孩模型)进行语音识别,得到第二语音识别结果。
58.图2示出本公开的语音识别方法的另一些实施例的流程图。
59.如图2所示,采集对话场景中的视频流及其相应的音频流。对视频流进行图像识别,获取场景类型,以匹配相应的降噪方案。例如,可以通过机器学习方法进行图像场景识别,降噪方案可以包括l1、l2、l3。例如,可以通过图3a中的实施例确定降噪方案。
60.图3a示出本公开的降噪处理方法的一些实施例的流程图。
61.如图3a所示,对视频流进行图像(背景)识别后,确定降噪方案。降噪方案l1可以包括基于户外背景音(如街道、汽车、大自然等)场景训练的算法模型,如rnnoise
‑
outdoors(循环神经网络户外降噪)模型。
62.降噪方案l2可以包括基于户内背景音(人教室、商场等)场景训练的算法模型,如rnnoise
‑
indoors(循环神经网络户内降噪)模型。
63.降噪方案l3可以包括人声增强与提取算法模型,如谱减法模型、维纳滤波模型等。
64.例如,可以通过图3b的方式进行降噪处理。
65.图3b示出本公开的降噪处理方法的一些实施例的示意图。
66.如图3b所示,可以采用vad (voice activity detection,语音活动检测)作为降噪处理模型。
67.可以将包含噪声的语音信号输入vad模型;经过谱减法(spectral subtraction)处理、语音活动检测处理、噪声谱估计(noise spectral estimation)处理,输出降噪后的语音信号。
68.例如,可以通过图3c的方式进行降噪处理。
69.图3c示出本公开的降噪处理方法的另一些实施例的示意图。
70.如图3c所示,降噪处理模型可以包括谱减法模块、语音活动检测模块、噪声谱估计模块。
71.语音活动检测模块可以包括以tanh为激活函数的密集(dense)层、以relu(rectified linear unit,线性整流函数)为激活函数的gru(gated recurrent unit,门控
循环单元)层、以sigmoid函数为激活函数的密集层。语音活动检测模型输出语音活动检测处理结果。
72.噪声谱估计模块包括以relu为激活函数的gru层;谱减法模块包括以relu为激活函数的gru层、以sigmoid函数为激活函数的密集层。谱减法模型输出增益结果。
73.进行降噪处理后,可以继续通过图2中的其余步骤进行语音识别。
74.根据视频流的场景类型,对音频流匹配相应的降噪方案;对视频流进行人体识别和唇形识别,结合音频流时间轴,建立起声音与人像的关联;提取出说话人的生理特点(如性别、年龄等),匹配相应的语音识别算法。
75.对音频流进行降噪处理(如降噪方案l3)后,再利用匹配的语音处理模型(如成人模型或小孩模型)进行语音识别,得到第二语音识别结果。
76.将唇形识别的结果和语音处理的结果进行加权修正,给出校正后的语音识别结果。
77.图3d示出本公开的唇形识别方法的一些实施例的示意图。如图3d所示,通过p2p(picture 2 pinyin,图片到拼音)处理过程和p2cc(picture 2 chinese character,拼音到汉字)处理过程,可以确定汉字序列。
78.如图3e所示,唇形识别模型可采取拼音序列识别方案。对嘴唇图片序列进行处理得到拼音序列,进而得到汉字序列。
79.] 例如,先经过vgg
‑
m卷积神经网络模型对帧图像进行卷积运算;然后进行批度规范化、rnn网络处理等多个环节,最终得到帧图像中唇形与识别的文字的对应结果。
80.] 图3e示出本公开的唇形识别方法的另一些实施例的示意图。
81.如图3e所示,可以采用机器学习模型进行唇形识别。例如,将帧图像中的唇形图片输入卷积网络(convnet)、lstm(long short
‑
term memory,长短期记忆网络)网络和ctc(connectionist temporal classification,联结机制时间分类)模块后,输出识别结果。
82.卷及网络可以包括多个卷积模块(conv1~5),lstm网络可以包括多个lstm模块。
83.图4a示出本公开的语音识别方法的一些实施例的示意图。
84.如图4a所示,对视频流进行图像识别,确定用户a’的生理特征为成人、女,用户b’的生理特征为幼儿、男;确定语音发出方用户a’和用户b’的唇动时段(各帧图像);根据生理特征为用户a’、用户b’匹配相应的唇形识别模型;进行唇形识别后,输出第一语音识别结果。
85.对降噪后的音频流进行声音识别,确定语音发出方用户a和用户b的发生时段(各帧语音);根据时间轴建立发生时段与唇动时段的关联关系,从而确定各发生时段相应的语音模型;进行语音处理后,输出第二语音识别结果。
86.对第一语音识别结果和第二语音识别结果进行加权修正,得到不同用户的综合识别结果。
87.图4b示出本公开的语音识别方法的另一些实施例的示意图。
88.如图4b所示,考虑到算法模型的体积较大,多种降噪方案算法和多种语音识别算法,都可以存储在云端。在需要进行降噪处理、唇形识别处理、语音识别处理的时候,从相应的服务器将相应的处理模型下载到本地的移动端。
89.在上述实施例中,在语音识别中引入新的识别维度,可以建立人声与说话人的联
系;使用图像识别等方式进行二次矫正,最终进一步提升识别准确率。
90.图5示出本公开的语音识别装置的一些实施例的框图。
91.如图5所示,语音识别装置5包括:特征确定单元51,用于对视频流中各帧图像进行人体识别,确定各帧图像中语音发出方的生理特征;模型确定单元52,用于根据不同的语音发出方的生理特征,确定不同的语音发出方对应的语音识别模型;识别单元53,用于利用不同的语音发出方对应的语音识别模型,识别不同的语音发出方的语音,确定语音识别结果。
92.在一些实施例中,模型确定单元52根据各帧图像对应的生理特征,确定各帧图像对应的唇形识别模型;识别单元53根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定语音识别结果。
93.在一些实施例中,模型确定单元52根据视频流的时间轴信息,将视频流中的各帧图像与视频流对应的音频流中的各帧语音进行关联,根据关联结果,确定与各帧图像关联的各帧语音对应的语音处理模型;识别单元53根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定语音识别结果。
94.在一些实施例中,识别单元53根据各帧图像对应的唇形识别模型对各帧图像的处理结果,确定第一语音识别结果,根据各帧语音对应的语音处理模型对各帧语音的处理结果,确定第二语音识别结果,根据所述第一语音识别结果和所述第二语音识别结果的加权平均值,确定综合语音识别结果作为语音识别结果。
95.在一些实施例中,特征确定单元51对视频流进行图像场景识别,确定视频流的场景类型;模型确定单元52根据场景类型,确定与场景类型相匹配的降噪处理模型,利用降噪处理模型对视频流对应的音频流进行降噪处理;识别单元53利用不同的语音识别模型对降噪处理后的音频流进行处理,确定语音识别结果。
96.在一些实施例中,场景类型包括户外场景、户内场景、多发声源场景中的多项,降噪处理模型包括匹配户外场景的循环神经网络户外降噪模型、匹配户内场景的循环神经网络户内降噪模型、匹配多发声源场景的人声增强与提取算法模型中的多项。
97.在一些实施例中,生理特征包括性别特征、年龄特征中的至少一项。
98.在一些实施例中,语音识别模型包括用于成人语音识别模型、用于小孩的语音识别模型。
99.图6示出本公开的语音识别装置的另一些实施例的框图。
100.如图6所示,该实施例的语音识别装置6包括:存储器61以及耦接至该存储器61的处理器62,处理器62被配置为基于存储在存储器61中的指令,执行本公开中任意一个实施例中的语音识别方法。
101.其中,存储器61例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序(boot loader)、数据库以及其他程序等。
102.图7示出本公开的语音识别装置的又一些实施例的框图。
103.如图7所示,该实施例的语音识别装置7包括:存储器710以及耦接至该存储器710的处理器720,处理器720被配置为基于存储在存储器710中的指令,执行前述任意一个实施例中的语音识别方法。
104.存储器710例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序(boot loader)以及其他程序等。
105.语音识别装置7还可以包括输入输出接口730、网络接口740、存储接口750等。这些接口730、640、750以及存储器710和处理器720之间例如可以通过总线760连接。其中,输入输出接口730为显示器、鼠标、键盘、触摸屏、麦克、音箱等输入输出设备提供连接接口。网络接口640为各种联网设备提供连接接口。存储接口750为sd卡、u盘等外置存储设备提供连接接口。
106.本领域内的技术人员应当明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用非瞬时性存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
107.至此,已经详细描述了根据本公开的语音识别方法、语音识别装置和非易失性计算机可读存储介质。为了避免遮蔽本公开的构思,没有描述本领域所公知的一些细节。本领域技术人员根据上面的描述,完全可以明白如何实施这里公开的技术方案。
108.可能以许多方式来实现本公开的方法和系统。例如,可通过软件、硬件、固件或者软件、硬件、固件的任何组合来实现本公开的方法和系统。用于所述方法的步骤的上述顺序仅是为了进行说明,本公开的方法的步骤不限于以上具体描述的顺序,除非以其它方式特别说明。此外,在一些实施例中,还可将本公开实施为记录在记录介质中的程序,这些程序包括用于实现根据本公开的方法的机器可读指令。因而,本公开还覆盖存储用于执行根据本公开的方法的程序的记录介质。
109.虽然已经通过示例对本公开的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本公开的范围。本领域的技术人员应该理解,可在不脱离本公开的范围和精神的情况下,对以上实施例进行修改。本公开的范围由所附权利要求来限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

