基于语音模型的诊断技术
发明领域
1.本发明总体上涉及医学诊断,特别是关于影响受试者的语音的生理状况的医学诊断。
2.背景
3.sakoe和chiba在声学、语音和信号处理ieee学报26.2(1978):43
‑
49的“dynamic programming algorithm optimization for spoken word recognition”中就一种用于口语词识别的基于最佳动态规划(dp)的时间归一化算法作了报告,该文章通过引用并入本文。首先,使用时间翘曲函数(warping function)给出了时间归一化的一般原理。然后,两个时间归一化的距离定义(称为对称形式和非对称形式)从该原理中被推导出来。通过理论讨论和实验研究,将这两种形式进行了相互比较。对称形式算法的优越性得以确立。引入了一种称为斜率约束的技术,其中翘曲函数的斜率被限制以便提高不同类别的词之间的区分度。
4.rabiner、lawrence r.在ieee 77.2会议录(1989):257
‑
286“a tutorial on hidden markov models and selected applications in speech recognition”中回顾了统计建模类型的理论方面,并展示了它们如何被应用于语音的机器识别中的选定问题,该文章通过引用并入本文。
5.美国专利7,457,753描述了一种用于远程评估用户的系统。该系统包括应用软件,该应用软件驻留在服务器上,并且被布置为通过网络与操作客户端设备的用户交互,以获得用户语音的一个或更多个样本信号。数据存储库(datastore)被布置为存储与用户的细节相关联的用户语音样本。特征提取引擎被布置为从相应的语音样本中提取一个或更多个第一特征。比较器被布置为将从语音样本中提取的第一特征与从一个或更多个参考样本中提取的第二特征进行比较,并提供第一特征和第二特征之间的任何差异的度量,以用于评估用户。
6.美国专利申请公开2009/0099848描述了一种用于痴呆症的被动诊断的系统和方法。通过纵向统计测量自动识别痴呆症的临床和心理测量指标,并使用数学方法来跟踪语言变化和/或患者音频特征的性质。所公开的系统和方法包括多层处理单元,其中记录的音频数据的初始处理在本地单元中进行处理。经处理的和需要的原始数据还被传输到中央单元,该中央单元对音频数据进行深入分析。
7.lotan等人的美国专利申请公开2015/0216448描述了一种用于测量用户的肺活量和耐力以检测慢性心力衰竭、copd或哮喘的方法。该方法包括在用户的移动通信设备上提供客户端应用,所述客户端应用包括用于以下项的可执行的计算机代码:指示用户用空气填充他的肺,并在呼气时发出一定响度(分贝)范围内的语声;由移动通信设备接收并记录所述用户的语声;停止记录语声;测量在所述响度范围内的语声接收时间的长度;以及在移动通信设备屏幕上显示该长度。
8.发明概述
9.根据本发明的一些实施例,提供了一种方法,该方法包括获得从一个或更多个参
考语音样本构建的至少一个语音模型,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。语音模型包括(i)参考语音样本中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。该方法还包括接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。该方法还包括,基于局部距离函数和所允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应局部距离。该方法还包括,响应于将测试语音样本映射到声学状态的最小距离序列,生成指示受试者在第二时间的生理状态的输出。
10.在一些实施例中,该方法还包括接收参考语音样本,并且获得语音模型包括通过从参考语音样本构建语音模型来获得语音模型。
11.在一些实施例中,总距离基于相应的局部距离的总和。
12.在一些实施例中,总距离是相应的局部距离的总和。
13.在一些实施例中,
14.该总和是第一总和,
15.该模型还为允许的转换定义相应的转换距离,并且
16.总距离是(i)第一总和与(ii)包括在声学状态的最小距离序列中的那些允许的转换的转换距离的第二总和。
17.在一些实施例中,生成输出包括:
18.将总距离与预定阈值进行比较;和
19.响应于比较生成输出。
20.在一些实施例中,每个声学状态的局部距离函数返回取决于给定声学特征向量对应于声学状态的估计似然性(estimated likelihood)的负对数的值。
21.在一些实施例中,参考语音样本是在受试者的生理状态相对于特定生理状况稳定时产生的。
22.在一些实施例中,
23.参考语音样本是第一参考语音样本,语音模型是第一语音模型,声学状态是第一声学状态,最小距离序列是第一最小距离序列,并且总距离是第一总距离,
24.该方法还包括:
25.接收在受试者的生理状态相对于特定生理状况不稳定时由受试者产生的一个或更多个第二参考语音样本;
26.基于第二参考语音样本,构建至少一个第二语音模型,该第二语音模型包括在第二参考语音样本中呈现的一个或更多个第二声学状态;
27.通过将测试样本特征向量映射到第二声学状态中的相应的第二声学状态,使得测试样本特征向量和第二声学状态中的相应的第二声学状态之间的第二总距离最小化,来将
测试语音样本映射到第二声学状态的第二最小距离序列;和
28.将第二总距离与第一总距离进行比较,以及
29.生成输出包括响应于将第二总距离与第一总距离进行比较而生成输出。
30.在一些实施例中,参考语音样本是在受试者的生理状态相对于特定生理状况不稳定时产生的。
31.在一些实施例中,参考语音样本和测试语音样本包括相同的预定话语。
32.在一些实施例中,
33.参考语音样本包括受试者的自由语音,
34.构建至少一个语音模型包括:
35.识别自由语音中的多个不同语音单元;
36.为所识别的语音单元构建相应的语音单元模型;和
37.通过连接语音单元模型来构建至少一个语音模型,使得语音模型表示所识别的语音单元的特定连接,以及
38.测试语音样本包括该特定连接。
39.在一些实施例中,
40.总距离是第一总距离,并且
41.生成输出包括:
42.计算测试样本特征向量和声学状态中的相应的声学状态之间的第二总距离,第二总距离不同于第一总距离;和
43.响应于第二总距离生成输出。
44.在一些实施例中,计算第二总距离包括:
45.通过相应的权重来加权相应的局部距离,至少两个权重彼此不同;和
46.通过对加权的局部距离求和来计算第二总距离。
47.在一些实施例中,相应的局部距离是第一相应的局部距离,并且计算第二总距离包括:
48.修改声学状态中的相应的声学状态的局部距离函数;
49.使用修改的局部距离函数,计算测试样本特征向量和声学状态中的相应的声学状态之间的第二相应的局部距离;和
50.通过对第二局部距离求和来计算第二总距离。
51.在一些实施例中,修改局部距离函数包括修改局部距离函数,以便与声学特征中的至少一个其他声学特征相比,给予声学特征中的至少一个声学特征更大的权重。
52.根据本发明的一些实施例,还提供了一种包括网络接口和处理器的装置。处理器被配置为获得从一个或更多个参考语音样本构建的至少一个语音模型,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。语音模型包括(i)参考语音样本中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。处理器还被配置为经由网络接口接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并且计算量化测试
语音样本的不同相应部分的声学特征的多个测试样本特征向量。处理器还被配置为基于局部距离函数和所允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。处理器还被配置为响应于将测试语音样本映射到声学状态的最小距离序列,生成指示受试者在第二时间的生理状态的输出。
53.根据本发明的一些实施例,还提供了一种包括电路和一个或更多个处理器的系统。处理器被配置为协同执行包括如下操作的过程:获得从一个或更多个参考语音样本构建的至少一个语音模型,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。语音模型包括(i)参考语音样本中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。该过程还包括经由电路接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并且计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。该过程还包括,基于局部距离函数和允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。该过程还包括,响应于将测试语音样本映射到声学状态的最小距离序列,生成指示受试者在第二时间的生理状态的输出。
54.在一些实施例中,电路包括模数(a/d)转换器。
55.在一些实施例中,电路包括网络接口。
56.根据本发明的一些实施例,还提供了一种计算机软件产品,该计算机软件产品包括其中存储有程序指令的有形的非暂时性计算机可读介质。当被处理器读取时,这些指令使得处理器获得从一个或更多个参考语音样本构建的至少一个语音模型,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。语音模型包括(i)参考语音样本中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。指令还使得处理器接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。指令还使得处理器基于局部距离函数和所允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。这些指令还使得处理器响应于将测试语音样本映射到声学状态的最小距离序列,生成指示受试者在第二时间的生理状态的输出。
57.根据本发明的一些实施例,还提供了一种方法,该方法包括获得从受试者的自由
语音构建的多个语音模型,该自由语音是在受试者的生理状态已知时在第一时间产生的。对于自由语音中多个不同语音单元中不同的相应的语音单元,每个语音模型包括:(i)在语音单元中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。该方法还包括接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并在测试语音样本中识别分别包括所识别的语音单元的一个或更多个测试样本部分。该方法还包括通过以下方式将测试样本部分映射到语音模型中的相应的语音模型:对于每个测试样本部分,计算量化测试样本部分的不同相应部分的声学特征的多个测试样本特征向量,识别针对包括在测试样本部分中的语音单元构建的语音模型,并且基于局部距离函数和包括在所识别的语音模型中的所允许的转换,通过将测试样本特征向量映射到包括在所识别的语音模型中的声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试样本部分映射到所识别的语音模型,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。该方法还包括响应于将测试样本部分映射到语音模型中的相应的语音模型,生成指示受试者在第二时间的生理状态的输出。
58.在一些实施例中,该方法还包括接收自由语音,并且获得语音模型包括通过以下项获得语音模型:
59.识别自由语音中的语音单元,以及
60.基于语音单元,构建语音模型。
61.在一些实施例中,总距离基于相应的局部距离的总和。
62.在一些实施例中,测试语音样本包括预定话语,该预定话语包括至少一个识别的语音单元。
63.在一些实施例中,自由语音是参考自由语音,并且测试语音样本包括测试自由语音。
64.根据本发明的一些实施例,还提供了一种包括网络接口和处理器的装置。该处理器被配置为获得从受试者的自由语音构建的多个语音模型,该自由语音是在受试者的生理状态已知时在第一时间产生的。对于自由语音中多个不同语音单元中不同的相应的语音单元,每个语音模型包括:(i)在语音单元中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。处理器还被配置为经由网络接口接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并且在测试语音样本中识别分别包括所识别的语音单元的一个或更多个测试样本部分。该处理器还被配置为通过以下方式将测试样本部分映射到语音模型中的相应的语音模型:对于每个测试样本部分,计算量化测试样本部分的不同相应部分的声学特征的多个测试样本特征向量,识别针对包括在测试样本部分中的语音单元构建的语音模型,并且基于局部距离函数和包括在所识别的语音模型中的所允许的转换,通过将测试样
本特征向量映射到包括在所识别的语音模型中的声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试样本部分映射到所识别的语音模型,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。处理器还被配置为响应于将测试样本部分映射到语音模型中的相应的语音模型,生成指示受试者在第二时间的生理状态的输出。
65.根据本发明的一些实施例,还提供了一种包括电路和一个或更多个处理器的系统。处理器被配置为协同执行包括以下项的过程:获得从受试者的自由语音构建的多个语音模型,该自由语音是在受试者的生理状态已知时在第一时间产生的。对于自由语音中多个不同语音单元中不同的相应的语音单元,每个语音模型包括:(i)在语音单元中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。该过程还包括经由电路接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并且在测试语音样本中识别分别包括所识别的语音单元的一个或更多个测试样本部分。该过程还包括通过以下方式将测试样本部分映射到语音模型中的相应的语音模型:对于每个测试样本部分,计算量化测试样本部分的不同相应部分的声学特征的多个测试样本特征向量,识别针对包括在测试样本部分中的语音单元构建的语音模型,并且基于局部距离函数和包括在所识别的语音模型中的所允许的转换,通过将测试样本特征向量映射到包括在所识别的语音模型中的声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试样本部分映射到所识别的语音模型,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。该过程还包括,响应于将测试样本部分映射到语音模型中的相应的语音模型,生成指示受试者在第二时间的生理状态的输出。
66.根据本发明的一些实施例,还提供了一种计算机软件产品,该计算机软件产品包括其中存储有程序指令的有形的非暂时性计算机可读介质。当被处理器读取时,指令使得处理器获得从受试者的自由语音构建的多个语音模型,该自由语音是在受试者的生理状态已知时在第一时间产生的。对于自由语音中多个不同语音单元中不同的相应的语音单元,每个语音模型包括:(i)在语音单元中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。指令还使得处理器接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并且在测试语音样本中识别分别包括所识别的语音单元的一个或更多个测试样本部分。指令还使得处理器通过以下方式将测试样本部分映射到语音模型中的相应的语音模型:对于每个测试样本部分,计算量化测试样本部分的不同相应部分的声学特征的多个测试样本特征向量,识别针对包括在测试样本部分中的语音单元构建的语音模型,并且基于局部距离函数和包括在所识别的语音模型中的所允许的转换,通过将测试样本特征向量映射到包括在所识别的语音模型中的声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试样本部分映射到所识别的语音模
型,该总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。指令还使得处理器响应于将测试样本部分映射到语音模型中的相应的语音模型,生成指示受试者在第二时间的生理状态的输出。
67.根据本发明的一些实施例,还提供了一种方法,该方法包括获得至少一个语音模型,该语音模型包括(i)在一个或更多个参考语音样本中呈现的一个或更多个声学状态,该声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。该方法还包括接收由受试者产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。该方法还包括:基于局部距离函数和所允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的第一总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该第一总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。该方法还包括计算测试样本特征向量和声学状态中的相应的声学状态之间的第二总距离,该第二总距离不同于第一总距离,并且响应于第二总距离,生成指示受试者的生理状态的输出。
68.根据本发明的一些实施例,还提供了一种包括网络接口和处理器的装置。处理器被配置为获得至少一个语音模型,该语音模型包括(i)在一个或更多个参考语音样本中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。处理器还被配置为经由网络接口接收由受试者产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。处理器还被配置为基于局部距离函数和所允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的第一总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该第一总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。处理器还被配置为计算测试样本特征向量和声学状态中的相应的声学状态之间的第二总距离,第二总距离不同于第一总距离,并且响应于第二总距离,生成指示受试者的生理状态的输出。
69.根据本发明的一些实施例,还提供了一种包括电路和一个或更多个处理器的系统。处理器被配置为协同执行包括以下项的过程:获得至少一个语音模型,该语音模型包括(i)在一个或更多个参考语音样本中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。该过程还包括经由电路接收由受试者产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。该过程还包括,基于局部距离函数和所允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特
征向量和声学状态中的相应的声学状态之间的第一总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该第一总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。该过程还包括计算测试样本特征向量和声学状态中的相应的声学状态之间的第二总距离,第二总距离不同于第一总距离,并且响应于第二总距离,生成指示受试者的生理状态的输出。
70.根据本发明的一些实施例,还提供了一种计算机软件产品,该计算机软件产品包括其中存储有程序指令的有形的非暂时性计算机可读介质。当被处理器读取时,指令使得处理器获得至少一个语音模型,该语音模型包括(i)在一个或更多个参考语音样本中呈现的一个或更多个声学状态,声学状态与相应的局部距离函数相关联,使得给定局部距离函数域内的任何声学特征向量时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度,以及(ii)如果语音模型包括多个声学状态,则允许声学状态之间的转换。这些指令还使得处理器接收由受试者产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。这些指令还使得处理器基于局部距离函数和所允许的转换,通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的第一总距离最小化,来将测试语音样本映射到声学状态的最小距离序列,该第一总距离基于测试样本特征向量和声学状态中的相应的声学状态之间的相应的局部距离。这些指令还使得处理器计算测试样本特征向量和声学状态中的相应的声学状态之间的第二总距离,第二总距离不同于第一总距离,并且响应于第二总距离,生成指示受试者的生理状态的输出。
71.根据本发明的一些实施例,还提供了一种方法,该方法包括获得多个参考样本特征向量,这些参考样本特征向量量化至少一个参考语音样本的不同相应部分的声学特征,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。该方法还包括接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。该方法还包括:通过在预定义的约束条件下,将测试样本特征向量映射到参考样本特征向量中的相应的参考样本特征向量,使得测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的总距离最小化,来将测试语音样本映射到参考语音样本。该方法还包括,响应于将测试语音样本映射到参考语音样本,生成指示受试者在第二时间的生理状态的输出。
72.在一些实施例中,该方法还包括接收参考语音样本,并且获得参考样本特征向量包括通过基于参考语音样本计算参考样本特征向量来获得参考样本特征向量。
73.在一些实施例中,总距离是从测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的相应的局部距离推导出的。
74.在一些实施例中,总距离是局部距离的加权总和。
75.在一些实施例中,将测试语音样本映射到参考语音样本包括使用动态时间规整(dtw)算法将测试语音样本映射到参考语音样本。
76.在一些实施例中,生成输出包括:
77.将总距离与预定阈值进行比较;和
78.响应于比较生成输出。
79.在一些实施例中,参考语音样本是在受试者的生理状态相对于特定生理状况稳定时产生的。
80.在一些实施例中,
81.参考语音样本是第一参考语音样本,参考样本特征向量是第一参考样本特征向量,并且总距离是第一总距离,
82.该方法还包括:
83.接收在受试者的生理状态相对于特定生理状况不稳定时由受试者产生的至少一个第二参考语音样本;
84.计算量化第二参考语音样本的不同相应部分的声学特征的多个第二参考样本特征向量;
85.在预定义的约束条件下,通过将测试样本特征向量映射到第二参考样本特征向量中的相应的第二参考样本特征向量,使得测试样本特征向量和第二参考样本特征向量中的相应的第二参考样本特征向量之间的第二总距离最小化,来将测试语音样本映射到第二参考语音样本;和
86.将第二总距离与第一总距离进行比较,以及
87.生成输出包括响应于将第二总距离与第一总距离进行比较而生成输出。
88.在一些实施例中,参考语音样本是在受试者的生理状态相对于特定生理状况不稳定时产生的。
89.在一些实施例中,参考语音样本和测试语音样本包括相同的预定话语。
90.在一些实施例中,参考语音样本包括受试者的自由语音,而测试语音样本包括包含在自由语音中的多个语音单元。
91.在一些实施例中,
92.总距离是第一总距离,并且
93.生成输出包括:
94.计算测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的第二总距离,第二总距离不同于第一总距离;和
95.响应于第二总距离生成输出。
96.在一些实施例中,
97.第一总距离是测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的相应的局部距离的第一加权总和,其中局部距离的第一加权总和由相应的第一权重加权,以及
98.第二总距离是相应的局部距离的第二加权总和,其中局部距离由相应的第二权重加权,第二权重中的至少一个第二权重不同于第一权重中的对应的第一权重。
99.在一些实施例中,该方法还包括:
100.将参考样本特征向量与相应的声学语音单元(apu)相关联;和
101.响应于apu选择第二权重。
102.在一些实施例中,将参考样本特征向量与apu相关联包括通过将语音识别算法应用于参考语音样本来将参考样本特征向量与apu相关联。
103.在一些实施例中,
104.第一总距离基于测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的相应的第一局部距离,并且
105.第二总距离基于测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的相应的第二局部距离,第二局部距离中的至少一个第二局部距离不同于第一局部距离中的对应的第一局部距离。
106.在一些实施例中,
107.将测试语音样本映射到参考语音样本包括使用第一距离度量来计算第一局部距离,以及
108.计算第二总距离包括使用不同于第一距离度量的第二距离度量来计算第二局部距离。
109.在一些实施例中,计算第二总距离包括基于对第一局部距离没有贡献的至少一个声学特征来计算第二局部距离。
110.根据本发明的一些实施例,还提供了一种包括网络接口和处理器的装置。处理器被配置为获得多个参考样本特征向量,该参考样本特征向量量化至少一个参考语音样本的不同相应部分的声学特征,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。处理器还被配置为经由网络接口接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并且计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。处理器还被配置为:通过在预定义的约束条件下,将测试样本特征向量映射到参考样本特征向量中的相应的参考样本特征向量,使得测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的总距离最小化,来将测试语音样本映射到参考语音样本。处理器还被配置为响应于将测试语音样本映射到参考语音样本,生成指示受试者在第二时间的生理状态的输出。
111.根据本发明的一些实施例,还提供了一种包括电路和一个或更多个处理器的系统。处理器被配置为协同执行包括以下项的过程:获得多个参考样本特征向量,这些参考样本特征向量量化至少一个参考语音样本的不同相应部分的声学特征,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。该过程还包括经由电路接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并且计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。该过程还包括:通过在预定义的约束条件下,将测试样本特征向量映射到参考样本特征向量中的相应的参考样本特征向量,使得测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的总距离最小化,来将测试语音样本映射到参考语音样本。该过程还包括,响应于将测试语音样本映射到参考语音样本,生成指示受试者在第二时间的生理状态的输出。
112.根据本发明的一些实施例,还提供了一种计算机软件产品,该计算机软件产品包括其中存储有程序指令的有形的非暂时性计算机可读介质。当被处理器读取时,这些指令使得处理器获得多个参考样本特征向量,这些参考样本特征向量量化至少一个参考语音样本的不同相应部分的声学特征,该参考语音样本是在受试者的生理状态已知时由受试者在第一时间产生的。这些指令还使得处理器接收在受试者的生理状态未知时由受试者在第二时间产生的至少一个测试语音样本,并计算量化测试语音样本的不同相应部分的声学特征的多个测试样本特征向量。这些指令还使得处理器通过在预定义的约束条件下,通过将测
试样本特征向量映射到参考样本特征向量中的相应的参考样本特征向量,使得测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的总距离最小化,来将测试语音样本映射到参考语音样本。这些指令还使得处理器响应于将测试语音样本映射到参考语音样本,生成指示受试者在第二时间的生理状态的输出。
113.根据结合附图进行的本发明的实施例的以下详细描述,本发明将得到更完全地理解,其中:
114.附图简述
115.图1是根据本发明的一些实施例的用于评估受试者的生理状态的系统的示意图;
116.图2是根据本发明的一些实施例的语音模型的构造的示意图;
117.图3是根据本发明的一些实施例的测试语音样本到语音模型的映射的示意图;
118.图4是根据本发明的一些实施例的用于从多个语音单元模型构建语音模型的技术的示意图;
119.图5是根据本发明的一些实施例的测试语音样本到参考语音样本的映射的示意图;和
120.图6是根据本发明的一些实施例的用于评估受试者的测试语音样本的示例算法的流程图。
具体实施方式
121.综述
122.本发明的实施例包括一种用于通过分析受试者的语音来评估受试者的生理状态的系统。例如,通过分析受试者的语音,系统可以识别生理状况(例如充血性心力衰竭(chf)、冠心病、心房颤动或任何其他类型的心律失常、慢性阻塞性肺病(copd)、哮喘、间质性肺病、肺水肿、胸腔积液、帕金森病或抑郁症)的发作或恶化。响应于评估,系统可以生成输出,例如对受试者、受试者的医生和/或监测服务的警报。
123.为了评估受试者的生理状态,当受试者的生理状态被认为稳定时,系统首先从受试者获取一个或更多个参考(或“基线”)语音样本。例如,可以在受试者的医生指示受试者的生理状态稳定后获取参考样本。作为另一个示例,对于患有肺水肿的受试者,系统可以在受试者进行治疗以稳定受试者的呼吸之后获取参考语音样本。在获得每个参考语音样本之后,系统从样本中提取声学特征向量序列。通过量化样本在样本中不同的相应时间点的时间附近的声学特性,每个特征向量对应于样本中不同的相应时间点。
124.在获取参考样本之后(例如,几天之后),当受试者的状态未知时,系统从受试者获取至少一个其他语音样本(在下文中称为“测试语音样本”),并从该样本中提取相应的特征向量。随后,基于测试样本和参考样本的特征向量,系统计算量化测试样本与参考样本的偏差的至少一个距离值,如下文详细描述的。响应于该距离满足一个或更多个预定义的标准(例如,响应于该距离超过预定义的阈值),系统可以生成警报和/或另一输出。
125.更具体地,在一些实施例中,基于从参考样本中提取的特征向量,系统构建特定于受试者的参数统计模型,该参数统计模型表示在受试者的生理状态被认为是稳定时的受试者的语音。特别地,受试者的语音由多个声学状态表示,这些声学状态隐含地对应于受试者的语音产生系统的相应的身体(physical)状态。该模型还定义了状态之间允许的转换,并
且还可以包括转换的相应的转换距离(或“成本”)。
126.声学状态与相应的参数局部距离函数相关联,这些函数是为特定的向量域定义的。给定域内的任何特定特征向量,每个局部距离函数在应用于特征向量时返回一值,该值指示特征向量和与该函数相关联的声学状态之间的对应程度。在本说明书中,该值被称为特征向量和声学状态之间的“局部距离”。
127.在一些实施例中,每个声学状态与相应的概率密度函数(pdf)相关联,并且声学状态和特征向量之间的局部距离是应用于特征向量的pdf的对数的负值。类似地,每个转换可以与相应的转换概率相关联,并且转换的成本可以是转换概率的对数的负值。具有这些特性的至少一些模型被称为隐马尔可夫模型(hmm)。
128.在构建模型之后,为了分析测试语音样本,通过将每个测试样本特征向量(即,从测试样本中提取的特征向量)分配给属于模型的声学状态中的相应的声学状态,系统将测试样本映射到模型。特别地,给定允许的状态转换,系统从所有可能的映射中选择提供具有最小总距离的状态序列的映射。这个总距离可以被计算为测试样本特征向量和它们被分配给的声学状态之间的相应的局部距离的总和;可选地,包括在序列中的转换距离的总和可以加到这个总和上。响应于样本和模型之间的总距离,系统可以生成警报和/或另一输出。
129.在一些实施例中,每个参考样本包括相同的特定话语(即相同的语音单元序列)。例如,受试者的移动电话可以提示受试者通过重复一个或更多个指定的句子、词语或音节来产生参考样本,这些句子、词语或音节可以包含任意数量的指定音素、双音素、三音素和/或其他声学语音单元(apu)。当受试者产生参考样本时,属于移动电话的麦克风可以记录样本。随后,属于移动电话或远程服务器的处理器可以从样本构建表示特定话语的模型。随后,为了获取测试样本,系统提示受试者重复话语。
130.在其他实施例中,参考样本是从受试者的自由语音中获取的。例如,受试者的移动电话可以提示受试者回答一个或更多个问题,然后可以记录受试者对这些问题的回答。可替代地,可以记录受试者在正常对话期间的语音。在获取参考样本之后,系统使用合适的语音识别算法来识别参考样本中的各种语音单元。例如,系统可以识别各种词语、apu(例如音素、音节、三音素或双音素)或合成声学单元,例如单个hmm状态。然后,系统为这些语音单元构建相应的模型(本文称为“语音单元模型”)。(在包括单个hmm状态的合成声学单元的情况下,语音单元模型包括单状态hmm。)
131.在构建语音单元模型之后,系统可以基于语音单元在话语中出现的顺序,将语音单元模型连接成表示特定话语的组合模型。(为了连接任意两个语音单元模型,系统添加从一个模型的最终状态到另一个模型的初始状态的转换,并且如果使用转换距离,则为该转换分配转换距离。)系统然后可以获取包括该特定话语的测试样本,并且将该测试样本映射到组合模型。
132.可替代地,代替连接语音单元模型,系统可以提示受试者为测试样本产生包括为其构建语音单元模型的语音单元的任何特定话语。系统然后可以识别测试样本中的这些语音单元,并计算每个语音单元和相应的语音单元模型之间的相应的“语音单元距离”。基于语音单元距离,系统可以计算测试样本和参考样本之间的总距离。例如,系统可以通过对语音单元距离求和来计算总距离。
133.作为又一种替代方案,测试样本可以从受试者的自由语音中获取。当系统识别测
试样本的言语内容时,系统可以为测试样本中具有相应的语音单元模型的每个语音单元计算相应的语音单元距离。如上所述,系统然后可以根据语音单元距离计算总距离。
134.在其他实施例中,系统不从参考样本构建模型,而是直接将测试语音样本与先前获取的每个单独的参考样本进行比较。例如,为了获取参考样本,系统可以提示受试者发出特定的话语。随后,为了获取测试样本,系统可以提示受试者发出相同的话语,然后可以将两个样本相互比较。可替代地,系统可以记录受试者的自由语音,并使用自动语音识别(asr)算法从自由语音中提取参考样本,以识别参考样本的言语内容。随后,为了获取测试样本,系统可以提示受试者产生相同的言语内容。
135.为了执行测试样本和参考样本之间的比较,系统使用对准算法(例如上文在背景中提到的动态时间规整(dtw)算法)来将测试样本与参考样本对准,即,找到每个测试样本特征向量和相应的参考样本特征向量之间的对应关系。(根据对准,多个连续的测试样本特征向量可以对应于单个参考样本特征向量;同样,多个连续的参考样本特征向量可以对应于单个测试样本特征向量。)在执行对准时,系统计算两个样本之间的距离d。随后,系统可以响应于d生成警报和/或任何其他合适的输出。(上述对准在下文中还被称为“映射”,因为测试样本被映射到参考样本。)
136.在一些实施例中,当受试者的生理状态被认为不稳定时,例如由于特定疾病的发作或恶化,获得一个或更多个参考语音样本。(在包括权利要求在内的本技术的上下文中,如果受试者的健康以任何方式恶化,即使受试者没有注意到任何恶化的症状,受试者的生理状态也被称为“不稳定”。)基于这些样本,系统可以构建表示处于不稳定状态的受试者的语音的参数统计模型。系统然后可以将测试样本与“稳定模型”和“不稳定模型”进行比较,并且例如如果测试样本更接近不稳定模型而不是稳定模型,则生成警报。可替代地,即使不构建稳定模型,系统也可以将测试样本与不稳定模型进行比较,并且响应于该比较,例如响应于测试样本和模型之间的距离小于预定义的阈值,生成警报。
137.类似地,该系统可以使用如上所述的对准技术,将测试样本直接与“不稳定的”参考样本进行比较,可替代地或附加地将测试样本与“稳定的”参考样本进行比较。响应于该比较,系统可以生成警报。
138.在一些实施例中,通常在这些受试者相对于受试者遭受的特定状况处于不稳定状态时,从其他受试者获得多个参考语音样本。基于这些样本(和/或从受试者获取的样本),构建通用(即,非特定于受试者的)语音模型。随后,受试者的测试样本可以被映射到通用模型。有利的是,该技术可以避免对从受试者获取大量参考样本(当受试者的状态不稳定时,这可能特别难以做到)的需要。
139.在一些实施例中,参考样本特征向量序列被标记为对应于相应的语音单元,例如相应的词语或音素。例如,每个参考样本可以被映射到独立于说话者的hmm,其中一个或更多个状态的组对应于相应的已知语音单元。(如上所述,如果参考样本是从受试者的自由语音中获得的,则在任何情况下执行这种映射。)可替代地,例如,参考样本可以由专家标记。如果从参考样本构建模型,则系统还基于参考样本的标记来标记模型中的状态序列。
140.在这样的实施例中,在将测试样本映射到模型或一个参考样本之后,系统可以重新计算测试样本和模型或参考样本之间的距离,给予一个或更多个语音单元更大的权重,该语音单元已知关于正被评估的特定生理状况比其他语音单元更具指示性。系统然后可以
响应于重新计算的距离来决定(而不是响应于在映射期间计算的原始距离来决定)是否生成警报。在重新计算距离时,系统不改变原始映射,即每个测试样本特征向量保持映射到相同的模型状态或参考样本特征向量。
141.可替代地或附加地,在将测试样本映射到模型或一个参考样本之后,系统可以使用与用于映射的那些局部距离函数不同的局部距离函数来重新计算测试样本和模型或参考样本之间的距离。在这种情况下,系统也不会改变原始映射,而是仅重新计算距离。
142.例如,系统可以修改局部距离函数,以将在执行映射时没有使用的一个或更多个特征计算在内,或者给予某些特征更大的权重。典型地,关于正在评估的特定生理状况,系统强调的特征是已知比其他特征更具指示性的那些特征。(更具指示性的特征的一个示例是音调的变化,该音调倾向于随着某些疾病的发作或恶化而降低。)可选地,系统还可以修改局部距离函数,使得一个或更多个特征具有较小的权重,或者对局部距离根本没有贡献。
143.系统描述
144.首先参考图1,图1是根据本发明的一些实施例的用于评估受试者22的生理状态的系统20的示意图。
145.系统20包括受试者22使用的音频接收设备32,例如移动电话、平板计算机、膝上型计算机、台式计算机、声控的个人助理(例如amazon echo
tm
或google home
tm
设备)或智能扬声器设备。设备32包括音频传感器38(例如,麦克风),其将声波转换成模拟电信号。设备32还包括处理器36和其他电路,该其它电路包括例如模数(a/d)转换器42和/或网络接口,例如网络接口控制器(nic)34。通常,设备32还包括数字存储器(或“存储设备”)、屏幕(例如触摸屏)和/或其他用户接口部件,例如键盘。在一些实施例中,音频传感器38(以及可选地,a/d转换器42)属于设备32外部的单元。例如,音频传感器38可以属于头戴式耳机,该头戴式耳机通过有线或无线连接(例如蓝牙连接)连接到设备32。
146.系统20还包括服务器40,该服务器40包括处理器28、数字存储器(或“存储设备”)30(例如硬盘驱动器或闪存驱动器)、和/或其他电路(包括例如a/d转换器和/或网络接口(例如网络接口控制器(nic)26))。服务器40还可以包括屏幕、键盘和/或任何其他合适的用户接口部件。典型地,服务器40远离设备32定位,例如在控制中心,并且服务器40和设备32经由它们相应的网络接口、通过网络24彼此通信,该网络24可以包括蜂窝网络和/或互联网。
147.系统20被配置为通过处理从受试者接收的一个或更多个语音信号(本文还称为“语音样本”)来评估受试者的生理状态,如下文详细描述的。典型地,设备32的处理器36和服务器40的处理器28协同执行至少一些语音样本的接收和处理。例如,当受试者对着设备32说话时,受试者语音的声波可以被音频传感器38转换成模拟信号,该模拟信号转而可以被a/d转换器42采样和数字化。(通常,受试者的语音可以以任何合适的速率(例如8khz到45khz之间的速率)进行采样。)所得数字语音信号可以由处理器36接收。处理器36然后可以经由nic 34将语音信号传送到服务器40,使得处理器28经由nic 26接收语音信号。随后,处理器28可以处理语音信号。
148.典型地,在处理受试者的语音时,处理器28将在受试者的生理状态未知时由受试者产生的测试样本与在受试者的生理状态已知时(例如,被医生认为是稳定的)产生的参考样本或者与从多个这样的参考样本构建的模型进行比较。例如,处理器28可以计算测试样
本和参考样本或模型之间的距离。
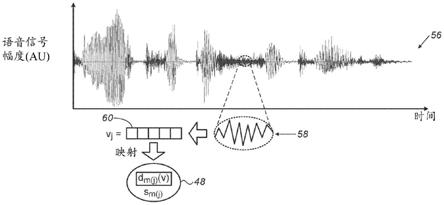
149.基于对受试者的语音样本的处理,处理器28可以生成指示受试者的生理状态的输出。例如,处理器28可以将前述距离与阈值进行比较,并且响应于该比较,生成指示受试者生理状况恶化的警报(例如音频或视觉警报)。可选地,这种警报可以包括对受试者的状态的描述;例如,警报可以指示受试者的肺是“湿的”(即部分填充有流体)。可替代地,如果受试者的语音样本指示受试者的状态稳定,则处理器28可以生成指示受试者的状态稳定的输出。
150.为了生成输出,处理器28可以向受试者、受试者的医生和/或监测中心发出呼叫或发送消息(例如,文本消息)。可替代地或附加地,处理器28可以将输出传送给处理器36,处理器36然后可以例如通过在设备32的屏幕上显示消息来将输出传送给受试者。
151.在其他实施例中,处理器36和处理器28协同执行上述语音信号处理。例如,处理器36可以从语音样本中提取声学特征向量(如下文进一步描述的),并将这些向量传送给处理器28。处理器28然后可以如本文所述处理向量。可替代地,处理器28可以(从处理器36、从一个或更多个其他处理器、和/或直接)接收由受试者22和/或由一个或更多个其他受试者产生的一个或更多个参考语音样本。基于这些样本,处理器28可以计算至少一个语音模型,或者多个参考样本特征向量。处理器28然后可以将模型或参考样本特征向量传送给处理器36。基于从处理器28获得的这些数据,处理器36可以如本文所述处理来自受试者22的测试样本。(可选地,处理器36可以将前述距离传送给处理器28。处理器28然后可以将该距离与前述阈值进行比较,并且如果适当,则生成警报。)作为又一替代方案,本文描述的整个诊断技术可以由处理器36执行,使得系统20不一定包括服务器40。
152.尽管有上述内容,为了简单起见,本说明书的其余部分通常假设处理器28——在下文中还简称为“处理器”——执行所有的处理。
153.在一些实施例中,设备32包括模拟电话,该模拟电话不包括a/d转换器或处理器。在这样的实施例中,设备32通过电话网络将模拟音频信号从音频传感器38发送到服务器40。典型地,在电话网络中,音频信号被数字化、以数字方式进行传送,然后在到达服务器40之前被转换回模拟信号。因此,服务器40可以包括a/d转换器,该a/d转换器将经由合适的电话网络接口接收的输入模拟音频信号转换为数字语音信号。处理器28从a/d转换器接收数字语音信号,然后如本文所述处理该信号。可替代地,服务器40可以在信号被转换回模拟信号之前从电话网络接收信号,使得服务器不一定包括a/d转换器。
154.典型地,服务器40被配置为与属于多个不同受试者的多个设备通信,并处理这些多个受试者的语音信号。典型地,存储器30存储数据库,其中存储了受试者的与本文所述的语音样本处理相关的数据(例如,一个或更多个参考语音样本或从中提取的特征向量、一个或更多个语音模型和/或一个或更多个阈值距离)。如图1所示,存储器30可以在服务器40内部,或者在服务器40外部。对于处理器36处理受试者的语音的实施例,属于设备32的存储器可以存储受试者的相关数据。
155.处理器28可以体现为单个处理器,或者体现为协同联网或集群化的一组处理器。例如,控制中心可以包括多个互连的服务器,这些服务器包括相应的处理器,这些处理器协同执行本文描述的技术。在一些实施例中,处理器28属于虚拟机。
156.在一些实施例中,如本文所述,处理器28和/或处理器36的功能仅在硬件中实现
(例如使用一个或更多个专用集成电路(asic)或现场可编程门阵列(fpga))。在其他实施例中,处理器28和处理器36的功能至少部分地以软件实现。例如,在一些实施例中,处理器28和/或处理器36体现为包括至少中央处理单元(cpu)和随机存取存储器(ram)的编程数字计算设备。包括软件程序的程序代码和/或数据被加载到ram中,以用于由cpu执行和处理。例如,程序代码和/或数据可以通过网络以电子形式下载到处理器。可替代地或附加地,程序代码和/或数据可以被提供和/或存储在非暂时性有形介质(例如磁、光或电子存储器)上。这种程序代码和/或数据在被提供给处理器时产生机器或专用计算机,其被配置为执行本文所述的任务。
157.构建参数统计模型
158.现在参考图2,其是根据本发明的一些实施例的语音模型46的构建的示意图。
159.在一些实施例中,处理器28(图1)根据从受试者22获取的一个或更多个参考语音样本44构建至少一个参数统计模型46。处理器然后使用模型46来评估受试者的后续语音。
160.特别地,处理器首先例如经由设备32接收样本44,如上面参考图1所述。通常,参考语音样本是在受试者的生理状态已知时由受试者产生的。例如,当医生认为受试者的生理状态相对于特定的生理状况稳定时,可以产生参考语音样本。作为特定的示例,对于患有诸如肺水肿或胸腔积液的生理状况的受试者,可以在受试者的肺被认为没有流体时产生参考样本。可替代地,可以在受试者的生理状态相对于特定生理状况不稳定时(例如,在受试者的肺是湿的时)产生参考语音样本。
161.接下来,基于接收的样本,处理器构建模型46。特别地,处理器通常从参考样本中提取声学特征的向量(如下面参考图3针对测试样本所述),然后根据向量构建模型46。该模型可以例如存储在存储器30(图1)中。
162.模型46包括在参考语音样本中呈现的一个或更多个声学状态48(例如,apu和/或合成声学单元)。声学状态48与相应的局部距离函数50相关联。给定函数50域内的任何声学特征向量“v”时,每个声学状态的局部距离函数返回局部距离,该局部距离指示给定声学特征向量和声学状态之间的对应程度。模型46还包括参考语音样本中呈现的声学状态之间的转换52;这些转换在本文被称为“允许的转换”。在一些实施例中,模型46还为转换定义相应的转换距离54。
163.例如,图2示出了语音模型的示例片段,该示例片段包括(i)具有第一局部距离函数d1(v)的第一声学状态s1,(ii)具有第二局部距离函数d2(v)的第二声学状态s2,以及(iii)具有第三局部距离函数d3(v)的第三声学状态s3。s1以转换距离t
12
转换到s2,并且以转换距离t
13
转换到s3。s3以转换距离t
31
转换到s1。
164.作为具体的简化示例,如果图2中所示的片段表示如受试者在参考语音样本中说出的单词“bobby”,则s1可以对应于音素“\b\”,s3可以对应于音素“\aw\”,以及s2可以对应于音素“\ee\”。(注意,通常在实践中,至少一些音素由多个状态的序列表示。)
165.在一些实施例中,每个声学状态与相应的多维概率密度函数(pdf)相关联,从该多维概率密度函数(pdf)隐含地推导出给定特征向量“v”和声学状态之间的局部距离。特别地,pdf提供给定声学特征向量对应于声学状态的估计似然性(即,给定特征向量是从在受试者的语音产生系统处于对应于声学状态的身体状态时产生的语音中推导出的),并且局部距离是从该估计似然性中推导出的。例如,每个声学状态的局部距离函数可以返回取决
于估计似然性的负对数的值。例如,该值可以是负对数本身或负对数的倍数。
166.作为具体示例,每个声学状态可以与高斯pdf相关联,使得当计算为负对数似然性时,局部距离是特征向量的分量和分布平均值的相应分量之间的差的平方和,该分布平均值由分布的相应方差的倒数加权。
167.在其他实施例中,局部距离是根据信息论考虑推导的;基于这种考虑的距离度量的一个示例是itakura
‑
saito距离度量,其在下面参考图5进行描述。可替代地,对于构建稳定模型和不稳定模型的实施例,局部距离可以根据类别区分考虑推导,因为局部距离可以被选择以便最佳区分稳定参考样本和不稳定参考样本。可替代地,局部距离可以根据启发式考虑推导。
168.典型地,转换距离54基于如从参考语音样本估计的相应的转换概率;例如,每个转换距离可以是相应的转换概率的负对数。
169.一般来说,模型的参数(例如,前述pdf的参数)和转换概率可以使用任何合适的技术(例如baum
‑
welch算法)从参考语音样本中来估计,该baum
‑
welch算法例如在l.rabiner和b
‑
h.juang的《fundamentals of speech recognition》(1993年的prentice hall)的第6.4.3节中描述,该文献通过引用并入本文。
170.将测试样本映射到模型
171.现在参考图3,其是根据本发明的一些实施例的测试语音样本56到语音模型的映射的示意图。
172.在获取参考样本之后,在稍后的时间,当受试者的生理状态未知时,处理器使用模型46来评估受试者的生理状态。
173.具体地,处理器首先接收至少一个测试语音样本56,该测试语音样本56是在受试者的生理状态未知时由受试者产生的。接下来,处理器计算量化样本56的不同相应部分58的声学特征的多个测试样本特征向量60。声学特征可以包括例如部分58的频谱包络(包括例如线性预测系数和/或倒谱系数)的表示。向量60可以包括任何合适数量的特征;举例来说,图3示出了五维向量v
j
。
174.一般来说,每个部分58可以具有任何合适的持续时间,诸如例如在10ms到100ms之间。(通常,这些部分具有相等的持续时间,尽管一些实施例可以使用具有不同持续时间的部分的音调同步分析。)在一些实施例中,部分58彼此重叠。例如,向量60可以对应于相应的时间点“t”,由此每个向量描述了占据时间段[t
‑
t,t t]的信号的部分的声学特征,其中t例如在5ms到50ms之间。例如,连续的时间点可以彼此相隔在10ms到30ms之间。
[0175]
在计算特征向量之后,基于局部距离函数和由模型46定义的允许的转换,处理器通过将测试样本特征向量映射到声学状态中的相应的声学状态,使得测试样本特征向量和声学状态中的相应的声学状态之间的总距离最小化,来将测试语音样本映射到属于该模型的声学状态的最小距离序列。总距离基于测试样本特征向量和特征向量映射到的声学状态之间的相应的局部距离;例如,总距离可以基于相应的局部距离的总和。
[0176]
为了进一步解释,如图3所示,测试语音样本到模型的每个映射将特征向量的每个索引“j”映射到声学状态的索引m(j),使得第j特征向量v
j
映射到声学状态s
m(j)
。(s
m(j)
可以是允许从s
m(j
‑
1)
转换到的任何声学状态。)v
j
到s
m(j)
的映射产生了v
j
和s
m(j)
之间的局部距离d
j
=d
m(j)
(v
j
)。因此,假设n个测试样本特征向量,测试样本被映射到n个状态的序列,并且该映
射的局部距离的总和是映射的总距离基于例如,总距离可以定义为或者,如果模型中包括转换距离,则总距离可以定义为其中,t
j(j 1)
是从第j状态到第j 1状态的转换距离。处理器找到使该总距离最小化的状态序列。
[0177]
举例来说,再次参考图2,并且假设处理器从测试样本中提取六个特征向量的序列{v1,v2,v3,v4,v5,v6},处理器可以将测试样本映射到最小距离状态序列{s1,s3,s1,s2,s2,s3}。该映射的总距离可以计算为d1(v1) t
13
d3(v2) t
31
d1(v3) t
12
d2(v4) t
22
d2(v5) t
23
d3(v6)。
[0178]
在一些实施例中,为了找到测试样本到模型的最佳映射,系统使用viterbi算法,该viterbi算法在前面提到的rabiner和juang的参考文献的第6.4.2节中描述,该文献通过引用并入本文。
[0179]
随后,响应于将测试语音样本映射到声学状态的最小距离序列,处理器生成指示测试样本产生时受试者的生理状态的输出。
[0180]
例如,处理器可以将最佳映射的总距离与预定阈值进行比较,然后响应于该比较生成输出。特别地,如果参考语音样本是在受试者的状态稳定时获取的,则可以响应于总距离超过阈值而生成警报;相反,如果参考语音样本是在受试者的状态不稳定时获取的,则可以响应于总距离小于阈值而生成警报。
[0181]
在一些实施例中,处理器基于总距离在适当数量的映射上的统计分布来确定阈值,这可以针对单个受试者(在这种情况下,阈值可以是特定于受试者的)或者针对多个相应的受试者来执行。特别地,如果当已知受试者的状态稳定时执行映射,则可以设置阈值,使得总距离在足够大的百分比(例如,大于98%)的映射中小于阈值。相反,如果当已知受试者的状态不稳定时执行映射,则可以设置阈值,使得总距离在足够大的百分比的映射中超过阈值。
[0182]
可替代地,处理器可以构建两个语音模型:一个使用在受试者的状态稳定时获取的参考语音样本,而另一个使用在受试者的状态不稳定时获取的样本。然后可以将测试样本映射到每个模型中相应的状态的最小距离序列。然后可以将测试样本和两个模型之间的相应的总距离相互比较,并且可以响应于该比较生成输出。例如,如果测试样本和稳定状态模型之间的距离超过测试样本和不稳定状态模型之间的距离,则可能生成警报。
[0183]
在一些实施例中,系统参考相同的模型或不同的相应模型,为多个测试样本计算相应的总距离。系统然后可以响应于距离(例如响应于一个或更多个距离超过阈值),生成警报。
[0184]
在一些实施例中,参考语音样本和测试语音样本包括相同的预定话语。例如,为了获取参考样本,设备32(图1)可以(例如,响应于来自服务器40的指令)提示受试者重复发出特定话语。随后,为了获取测试样本,可以类似地提示受试者发出相同的话语。为了提示受试者,设备可以播放话语,并请求(经由书面或音频消息)受试者重复所播放的话语。可替代地,例如,话语的言语内容可以显示在设备的屏幕上,并且可以请求受试者大声朗读言语内容。
[0185]
在其他实施例中,参考语音样本包括受试者的自由语音,即其言语内容不是由系
统20预定的语音。例如,参考语音样本可以包括受试者的正常对话语音。在这方面,现在参考图4,图4是根据本发明的一些实施例的用于根据多个语音单元模型64构建语音模型的技术的示意图。
[0186]
图4描绘了参考样本61,该参考样本61包括受试者的自由语音。在一些实施例中,给定这样的样本时,处理器通过以下方式构建模型46:识别自由语音中的多个不同的语音单元62,针对所识别的语音单元构建相应的语音单元模型64(如上文参考图2针对模型46所述),然后通过连接语音单元模型64来构建模型46,使得语音模型表示所识别的语音单元的特定连接。每个语音单元可以包括一个或更多个词语、apu和/或合成声学单元。
[0187]
例如,假设参考样本包括句子“i’ve been trying all day to reach him,but his line is busy”,处理器可以识别语音单元“trying”、“reach”和“line”,并针对这些语音单元构建相应的语音单元模型。随后,处理器可以通过连接语音单元模型来构建模型46,使得例如该模型表示话语“trying reach line”。
[0188]
为了识别语音单元62,处理器可以使用前面提到的rabiner和juang的参考文献中的第7
‑
8章中描述的用于独立于说话者的大量词汇连接的语音识别的任何算法,该文献通过引用并入本文。这种算法的一个示例是一级动态规划算法,该算法在rabiner和juang的第7.5节中进行了描述,并在ney、hermann的“the use of a one
‑
stage dynamic programming algorithm for connected word recognition”(声学、语音和信号处理ieee学报32.2(1984):第263
‑
271页)中进一步描述,该文献通过引用并入本文。为了识别音素或其他子词,这些算法可以与用于子词识别的技术(例如rabiner和juang的第8.2
‑
8.4节中描述的那些技术)结合使用。rabiner和juang的第8.5
‑
8.7节中描述的语言模型可用于促进这种子词识别。
[0189]
随后,为了获取测试样本,可以提示受试者发出由模型46表示的特定话语。例如,继续上面的示例,可以提示受试者发出“trying reach line”。
[0190]
在其他实施例中,语音单元模型保持彼此分离,即,不执行连接。在一些这样的实施例中,提示受试者发出任何预定的话语,该话语包括针对其构建了语音单元模型的至少一个语音单元。处理器识别话语中的这些语音单元中的每个语音单元,然后分别处理每个语音单元。(通常,处理器使用语音单元模型结合通用语音hmm来识别每个语音单元,该通用语音hmm表示除了针对其构建了语音模型的语音单元之外的所有语音。)
[0191]
在其他这样的实施例中,处理器接收受试者的自由语音用于测试样本。处理器还在测试样本中识别分别包括语音单元62的一个或更多个部分。例如,如果测试样本包括句子“line up,and stop trying to reach the front”,则处理器可以识别测试样本中包括“trying”、“reach”和“line”的部分。(为了识别测试样本自由语音的言语内容,处理器可以使用上述独立于说话者的任何算法。)
[0192]
随后,通过对于每个部分识别针对包括在该部分中的语音单元构建的语音单元模型,然后执行该部分到相应语音单元模型的最小距离映射,处理器将测试样本部分映射到语音单元模型中的相应的语音单元模型。例如,处理器可以将测试样本部分“trying”映射到针对语音单元“trying”构建的模型,将测试样本部分“reach”映射到针对“reach”构建的模型,并且将测试样本部分“line”映射到针对“line”构建的模型。
[0193]
随后,响应于将测试样本部分映射到语音单元模型,处理器生成指示受试者的生
理状态的输出。例如,处理器可以计算映射的相应距离的总和,然后响应于该距离生成输出。例如,如果处理器分别针对“trying”、“reach”和“line”计算距离q1、q2和q3,则处理器可以响应于q1 q2 q3生成输出。
[0194]
使用不同的总距离进行诊断
[0195]
在一些实施例中,处理器不是响应于映射中最小化的总距离,而是响应于测试样本特征向量和向量所映射到的相应的声学状态之间的不同总距离来生成输出。换句话说,处理器可以通过最小化第一总距离来将测试样本映射到模型,但是然后响应于不同于第一总距离的第二总距离来生成输出。
[0196]
在一些实施例中,处理器通过按相应的权重对相应的局部距离进行加权(至少两个权重彼此不同),然后对加权的局部距离求和,来计算第二总距离。例如,返回到上面参考图2描述的示例,其中{v1,v2,v3,v4,v5,v6}被映射到{s1,s3,s1,s2,s2,s3},处理器可以将第二总距离计算为w1*d1(v1) t
13
w3*d3(v2) t
31
w1*d1(v3) t
12
w2*d2(v4) t
22
w2*d2(v5) t
23
w3*d3(v6),其中权重{w1,w2,w3}中的至少两个彼此不同。作为具体的示例,如果声学状态s1比其他两个状态与受试者的生理状况更相关,则w1可能大于w2和w3中的每一个。
[0197]
可替代地或附加地,处理器可以修改特征向量映射到的相应的声学状态的局部距离函数。使用修改的局部距离函数,处理器可以计算测试样本特征向量和向量映射到的相应的声学状态之间的不同局部距离。处理器然后可以通过对这些新的局部距离求和来计算第二总距离。例如,对于上述示例映射,处理器可以将第二总距离计算为d
’1(v1) t
13
d
’3(v2)
…
d
’2(v5) t
23
d
’3(v6),其中符号“d
’”
表示修改的局部距离函数。
[0198]
典型地,局部距离函数被修改,以便给予向量中量化的至少一个声学特征更大的权重。典型地,被选择用于更大加权的声学特征是已知与其他特征相比跟受试者的生理状况更相关的那些特征。
[0199]
例如,对于任何给定向量[z
1 z2ꢀ…ꢀ
z
k
],原始局部距离函数可以返回值其中b
i
=s
i
(z
i
‑
r
i
)2,其中每个r
i
是合适的参考量,并且每个s
i
是权重,对于某些索引,s
i
可以是0。在这样的实施例中,修改的局部距离函数可以返回其中c
i
=s’i
*(z
i
‑
r
i
)2,其中针对至少一些索引,{s’i
}是不同于s
i
的合适权重。通过使用不同于{s
i
}的{s’i
},处理器可以调整特征的相对权重。在一些情况下,对于s
i
(因此,b
i
)为零的至少一个索引,修改的函数可以包括非零的s’i
(因此,非零的c
i
),使得处理器在计算第二总距离时,考虑根本没有用于执行映射的至少一个特征。(注意,为了效率,对和的实际计算可以跳过任何零值项。)
[0200]
在一些实施例中,受试者的测试样本被映射到非特定于受试者的模型,通常根据由相对于受试者的生理状况不稳定的其他受试者产生的多个参考样本来构建该模型。(可选地,来自受试者的一个或更多个不稳定状态样本还可以用于构建模型。)随后,如上所述,计算测试样本和模型之间的第二总距离。接下来,处理器可以响应于第二总距离生成输出。例如,如果根据如上所述的不稳定状态参考样本来构建该模型,则处理器可以响应于第二总距离小于阈值而生成警报。
[0201]
直接比较
[0202]
如上文综述中所述,在一些实施例中,处理器直接将测试语音样本与参考样本进
行比较。
[0203]
特别地,处理器首先接收参考样本,如上所述,该参考样本是在受试者的生理状态已知时由受试者产生的。随后,处理器计算量化参考语音样本的不同相应部分的声学特征的多个参考样本特征向量,如上面参考图3针对测试样本所述。这些特征可以存储在存储器30(图1)中。
[0204]
接下来,在稍后的时间,处理器接收测试样本,如上所述,该测试样本是在受试者的生理状态未知时由受试者产生的。处理器然后从测试样本中提取测试样本特征向量,如上面参考图3所述。随后,处理器通过将测试样本特征向量映射到参考样本特征向量中的相应的参考样本特征向量,使得测试样本特征向量和参考样本特征向量中的相应的参考样本特征向量之间的总距离在预定义的约束条件下最小化,来将测试语音样本映射到参考语音样本。
[0205]
关于该映射的进一步细节,现在参考图5,图5是根据本发明的一些实施例的测试语音样本到参考语音样本的映射的示意图。
[0206]
作为介绍,注意到:测试样本到参考样本的任何映射(还称为测试样本与参考样本的“对准”)可以由n对索引的序列{(t1,r1),
…
,(t
n
,r
n
)}来表示,其中每个索引t
i
是测试样本中的特征向量的索引,每个索引r
i
是参考样本中的特征向量的索引,因此,每对索引(t
i
,r
i
)表示测试样本特征向量和参考样本特征向量之间的对应关系。例如,第十测试样本特征向量和第十一参考样本特征向量之间的对应关系由一对索引(10,11)来表示。
[0207]
通常,索引对的序列必须满足一些预定义的约束条件,对准才有效。这种约束条件的示例包括:
[0208]
·
单调性和连续性:t
i
≤t
i 1
,r
i
≤r
i 1
,和0<(r
i 1
t
i 1
)
‑
(r
i
t
i
)≤2,对于i=1,
…
,n
‑1[0209]
·
约束斜率:1≤t
i 2
‑
t
i
≤2和1≤r
i 2
‑
r
i
≤2,对于i=1,
…
,n
‑2[0210]
·
边界条件:t1=1,r1=1,t
n
=m,和r
n
=l,其中测试样本包括m个特征向量,并且参考样本包括l个特征向量。
[0211]
给定任何特定的对准,测试样本和参考样本之间的总距离d可以定义为其中是测试样本的第t
i
特征向量,是参考样本的第r
i
特征向量,d是可以利用任何合适的距离度量(例如l1或l2距离度量)的两个特征向量之间的局部距离,并且每个w
i
是应用于d的权重。在一些实施例中,对于i=2,
…
,n,w1=2并且w
i
=(r
i
t
i
)
‑
(r
i
‑1 t
i
‑1),使得对于每个对准,权重的总和是m l,从而消除不同对准之间的任何先验偏差。可选地,总距离d可以以任何其他合适的方式从局部距离推导出。
[0212]
注意,在包括权利要求的本技术的上下文中,两个向量之间的“距离”可以被定义为包括一个向量相对于另一个向量的任何种类的偏差或失真。因此,局部距离函数不一定返回几何意义上的距离。例如,例如,返回几何意义上的距离。例如,例如,可能不一定正确,和/或对于任何三个特征向量v1、v2和v3,d(v1,v3)≤d(v1,v2) d(v2,v3)可能不一定正确。可以在本发明的实施例中使用的非几何距离度量的示例是线性预测(lpc)系数的向量之间的itakura
‑
saito距离度量,其在前面提到的rabiner和juang的参考文献的第4.5.4节中描述,该文献通过引用并入本文。
[0213]
除了上述介绍之外,图5示出了测试样本与参考样本的对准,其可以由处理器例如使用动态时间规整(dtw)算法来执行,该算法在前面提到的sakoe和chiba的参考文献中描述,该文献通过引用并入本文。特别地,图5示出了一些测试样本特征向量和参考样本特征向量中的对应的参考样本特征向量之间的对应关系,这是由对准产生的。每对对应的特征向量具有相关联的局部距离d
i
,其中从所有可能的对准中,处理器选择最小化距离d的对准,例如,使用在前面提到的rabiner和juang的参考文献的第4.7节中描述的动态规划算法,该文献通过引用并入本文。(注意,dtw算法包括用于寻找最佳对准的动态规划算法。)
[0214]
(为了避免任何混淆,注意图5所示的四个参考样本特征向量不一定是属于参考样本的前四个特征向量。例如,r2可以是2,并且r3可以是4,使得第三参考样本特征向量不被映射到。类似地,图5所示的四个测试样本特征向量不一定是属于测试样本的前四个特征向量。)
[0215]
响应于将测试语音样本映射到参考语音样本,处理器可以生成指示在获取测试语音样本时受试者的生理状态的输出。例如,处理器可以将总距离d与合适的预定义的阈值进行比较,并响应于该比较生成输出。
[0216]
在一些实施例中,如上文参考图2所述,参考语音样本在受试者的生理状态被认为相对于特定生理状况稳定时产生。在其他实施例中,参考语音样本在受试者的生理状态被认为不稳定时产生。在另外的其他实施例中,处理器接收两个参考语音样本:稳定状态语音样本和不稳定状态语音样本。处理器然后将测试样本映射到每个参考语音样本,从而产生到稳定状态语音样本的第一距离和到不稳定状态语音样本的第二距离。处理器然后将这两个距离相互比较,并响应于此生成输出。例如,如果第二距离小于第一距离(指示测试样本更类似于不稳定状态参考样本),则处理器可以生成警报。
[0217]
在一些实施例中,参考语音样本和测试语音样本包括相同的预定话语,如上文参考图3所述。在其他实施例中,参考语音样本包括受试者的自由语音,而测试语音样本包括包含在自由语音中的多个语音单元。例如,使用上面参考图4描述的技术,处理器可以识别受试者的自由语音中的多个不同语音单元。处理器然后可以根据这些语音单元构建话语,然后提示受试者通过发出该话语来产生测试样本。
[0218]
在一些实施例中,系统针对相应的测试样本计算相对于不同的相应的参考样本的多个距离;系统然后可以响应于多个距离(例如响应于一个或更多个距离超过阈值)来生成警报。
[0219]
使用不同的总距离进行诊断
[0220]
在一些实施例中,在执行测试样本到参考样本的映射之后,处理器计算测试样本特征向量和它们所映射到的参考样本特征向量之间的另一个不同的总距离。处理器随后响应于该另一个总距离生成输出。
[0221]
例如,如上所述,处理器可以首先选择最小化的映射。随后,处理器可以(在不改变映射的情况下)计算其中至少一个新权重u
i
不同于相应的原始权重w
i
。换句话说,处理器可以计算局部距离的另一加权总和,其中局部距离
由不同于原始权重集{w
i
}的新权重集{u
i
}加权,不同之处在于对于至少一个索引i,u
i
不同于w
i
。
[0222]
典型地,通过将参考样本特征向量与相应的apu相关联,然后响应于apu选择新的权重,来选择新的权重。(在这种情况下,如果处理器认为向量已经从包含在apu中的语音中被提取,则处理器称该向量与apu相关联。)例如,响应于和与特定的apu相关联,已知该apu比其他apu与受试者的生理状况更相关,处理器可以相对于其他新的权重为u2和u3分配更高的值。
[0223]
为了将参考样本特征向量与相应的apu相关联,处理器可以将任何合适的语音识别算法应用于参考语音样本。例如,处理器可以使用在前面提到的rabiner和juang的参考文献的第7
‑
8章中描述的用于独立于说话者的大量词汇连接语音识别的任何算法,例如一级动态规划算法。
[0224]
可替代地或附加地,在计算新的总距离时,处理器可以(在不改变映射的情况下)使用不同的局部距离。换句话说,处理器可以将新的总距离计算为(或者),其中d’是不同于原始函数的局部距离函数,使得至少一个新的局部距离不同于对应的原始局部距离,即:对于至少一个索引i,不同于
[0225]
例如,对于新的局部距离,处理器可以使用不同于原始距离度量的新的距离度量。(例如,处理器可以使用l1距离度量来代替l2距离度量。)可替代地或附加地,处理器可以基于对第一局部距离没有贡献的至少一个声学特征来计算新的局部距离。例如,如果原始局部距离不依赖于向量的相应的第三元素(其可以量化任何特定的声学特征),则处理器可以修改局部距离函数,使得函数的输出依赖于这些元素。
[0226]
示例算法
[0227]
现在参考图6,图6是根据本发明的一些实施例的用于评估受试者的测试语音样本的示例算法66的流程图。
[0228]
算法66开始于接收步骤68,在该步骤68中,处理器从受试者接收测试语音样本。在接收样本之后,在提取步骤70,处理器从样本中提取测试样本特征向量。接下来,在检查步骤72,处理器检查合适的参考模型是否可用。(如上文参考图4所述,可以根据从受试者接收的参考样本和/或根据从多个其他受试者接收的参考样本来构建这种模型。)例如,处理器可以通过查询存储在存储器30(图1)中的数据库来寻找合适的模型。
[0229]
随后,如果处理器能够找到合适的参考模型,则处理器在第一映射步骤78将测试样本特征向量映射到参考模型中的状态序列,使得向量和状态之间的第一总距离最小化,如上面参考图3所述。可替代地,如果处理器不能找到合适的参考模型,则在检索步骤74,处理器检索参考样本特征向量序列,该参考样本特征向量是先前从受试者的参考样本中提取的。随后,在第二映射步骤76,处理器将测试样本特征向量映射到参考样本特征向量,使得向量序列之间的第一总距离最小化,如上面参考图5所述。
[0230]
在第一映射步骤78或第二映射步骤76之后,处理器在距离计算步骤80计算(i)测试样本特征向量和(ii)参考模型或参考样本特征向量之间的第二总距离。例如,如上面参
考图4
‑
5所述,在计算第二总距离时,处理器可以改变局部距离的相对权重,和/或改变局部距离本身。
[0231]
随后,在比较步骤82,处理器将第二总距离与阈值进行比较。如果第二总距离大于(或者,在一些情况下,例如在参考样本对应于不稳定状态的情况下,小于)阈值,则在警报生成步骤84,处理器生成警报。否则,算法66可以在没有任何进一步活动的情况下终止;可替代地,处理器可以生成指示受试者的状态稳定的输出。
[0232]
本领域中的技术人员将认识到,本发明不被限制于上文所具体示出和描述的内容。相反,本发明的实施例的范围包括上文所描述的各种特征的组合和子组合以及本领域技术人员在阅读以上描述之后将想到的且未在现有技术中的其变型和修改。通过引用并入本专利申请中的文件被视为本技术的组成部分,除了任何术语在这些并入的文件中在某种程度上以与本说明书中明确地或隐含地做出的定义冲突的方式被定义之外,应该仅考虑本说明书中的定义。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

