1.本发明涉及语音识别领域,尤其涉及一种利用残差网络的伪装语音检测方法。
背景技术:
2.伪装语音检测技术是指根据语音特性的不同,将伪装语音(包括重放语音、合成语音、转换语音及模仿语音)检测出来,达到区分真实语音和伪装语音的目的,在语音生物特征识别领域具有非常重要的应用。常用的伪装语音检测方法包含特征提取和分类器两部分。目前,特征提取多用梅尔频率倒谱系数(mel
‑
frequency cepstral coefficients,mfccs)、常q倒谱系数(constant q cepstral coefficients,cqccs)等,常用的分类器有高斯混合模型(gaussian mixture model,gmm)、隐马尔科夫模型(hidden markov model,hmm)、支持向量机(support vector machines,svm)等传统机器学习方法。但是这些方法只能检测特定种类的伪装语音,伪装种类未知时,检测效果下降,无法适应多变的伪装语音挑战。
技术实现要素:
3.为解决上述问题,本发明提供一种利用残差网络的伪装语音检测方法,
4.为实现以上技术目的,本发明采用以下技术方案;
5.利用残差网络的伪装语音检测方法,其特征在于,包括以下步骤,
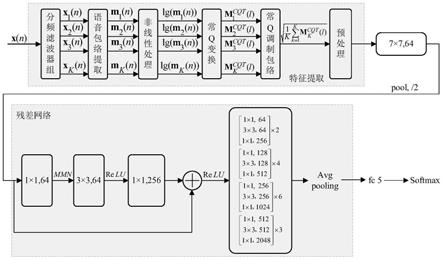
6.s1:利用特征提取模块对语音信号x(n)进行处理后得到基于调制频谱的语音特征
‑
常q调制包络(cqme);
7.s2:将提取出来的常q调制包络特征以q调制包络特征图的形式输出,经预处理后输入到改进后的resnet分类网络中;
8.s3:q调制包络特征以图片的形式输入到分类网络中后,首先通过1个7
×
7卷积层和一个3
×
3池化层,然后通过16个残差单元实现深度特征提取;
9.s4:经过16个残差单元后,通过平均池化层,最终通过全连接层和softmax层输出语音分类。
10.进一步地,步骤s1中,特征提取模块对语音信号x(n)进行处理包括以下步骤,
11.s11:将输入的语音x(n)通过一个分频滤波器组,将语音分成k个不同频段的信号x
k
(n),其中k=1,2,
…
,k;
12.s12:对分频求得的信号x
k
(n)提取包络;
13.s13:对语音包络进行非线性处理;
14.s14:将经过非线性处理的包络lg(m
k
(n))通过常数q变换变换到频域;
15.s15:计算每个频率段的均方值,得到基于调制频谱的语音特征——常q调制包络(constant q transform modulation envelope,cqme)。
16.进一步地,步骤s2中,q调制包络特征图为以频率——幅值为横纵坐标绘制的图像。
17.进一步地,步骤s2中,输入到resnet分类网络的调制包络特征图经过预处理将大小调整为224
×
224
×
3。
18.进一步地,步骤s2中,resnet分类网络为50层的残差网络。
19.进一步地,残差网络包含5个卷积块;第1个卷积块为64个7
×
7的卷积核构成的卷积层,第2个卷积块由1个3
×
3的最大池化层和3个残差单元构成。
20.进一步地,每一残差单元由3层卷积构成,第1层卷积核大小为1
×
1,通过mmn激活函数结合dropout技术与第2层3
×
3卷积相连,第2层卷积通过relu激活函数与第3层1
×
1卷积相连,输出与shortcut连接的输出相加,再次经过relu激活函数非线性处理后传递到下一残差单元。
21.进一步地,结合dropout技术的mmn激活函数,第3层卷积块由4个残差单元构成,第4层卷积块由6个残差单元构成,第5层卷积块由3个残差单元构成,各层卷积块中残差单元的通道数不断递进。
22.进一步地,经过5层卷积块,对输出进行平均池化。
23.与现有技术相比,本发明的有益技术效果为:
24.(1)提取常q调制包络特征时,运用常数q变换,时频分辨率可变,符合语音信号的特性,更加适合语音信号的处理,充分利用了语音信号中蕴含的信息。
25.(2)通过采用改进残差网络,并将mmn激活函数与dropout技术结合使用来替代底层relu激活函数,解决了卷积神经网络训练层数越深准确率下降的问题,提高了伪装语音检测的准确性。
26.(3)通过对不同伪装语音提取常q调制包络特征,并通过残差网络分类的方式,解决了传统伪装检测方式只能检测单一伪装语音的弊端,在未知伪装类型的情况下也可以进行检测,方便使用。
附图说明
27.图1为本发明利用残差网络的伪装语音检测方法示意图;
28.图2为本发明残差单元结构图;
29.图3为本发明maxout单元结构图;
30.图4为本发明mmn单元结构图。
31.图5为本发明结合dropout的mmn结构图
32.图6为本发明利用残差网络的伪装语音检测方法整体流程图。
具体实施方式
33.下面结合具体实施例对本发明进行进一步地描述,但本发明的保护范围并不仅仅限于此。
34.如图1
‑
6所示,本实施例提出了一种利用残差网络的伪装语音检测方法,以下步骤,
35.s1:利用特征提取模块对语音信号x(n)进行处理后得到基于调制频谱的语音特征
‑
常q调制包络(cqme);
36.s2:将提取出来的常q调制包络特征以q调制包络特征图的形式输出,经预处理后
输入改进后resnet分类网络中;
37.s3:q调制包络特征以图片的形式输入到分类网络中后,首先通过1个7
×
7卷积层和一个3
×
3池化层,然后通过16个残差单元实现深度特征提取;
38.s4:经过16个残差单元后,通过平均池化层,最终通过全连接层和softmax层输出语音分类。
39.本实施例所提语音伪装检测系统由两部分构成,第一部分对任意输入语音,计算其常q调制包络,得到输入语音的特征图作为分类网络的输入。不同类型的伪装语音在基频、噪音等方面有所不同,提取得到的特征图与真实语音有所差别。第二部分将特征图输入到训练好的resnet分类网络中后,通过几组卷积块对特征图进行深度特征提取、类别匹配,最后通过全连接层和softmax层输出分类。整个过程可以对真实语音和伪装语音分类,实现了伪装语音的检测。
40.其中,步骤s1中,特征提取模块对语音信号x(n)进行处理包括以下步骤,
41.s11:将输入的语音x(n)通过一个分频滤波器组,将语音分成k个不同频段的信号x
k
(n),其中k=1,2,
…
,k;
42.s12:对分频求得的信号x
k
(n)提取包络来;此过程具体为,对每一段语音求其希尔伯特变换,进一步得到每一段语音的解析信号,提取每段语音解析信号的幅度,即可得到k段语音的包络;
43.s13:对语音包络进行非线性处理;此过程具体为数函数将语音包络进行非线性处理变换尺度。
44.s14:将经过非线性处理的包络lg(m
k
(n))通过常数q变换变换到频域。此过程具体为求得常数q变换参数,通过常数q变换将特征变换到频域。
45.s15:计算每个频率段的均方值,得到基于调制频谱的语音特征——常q调制包络(constant q transform modulation envelope,cqme)。
46.以频率——幅值为横纵坐标绘制图像,得到常q调制包络特征图。将特征图预处理,重新定义特征图尺寸为224
×
224
×
3;
47.因此,本实施例采用常数q调制包络特征与改进后的残差网络(residual network,resnet)结合来处理伪装方式未知的伪装语音检测方案。语音信号x(n)输入后,系统将其分频处理,分成k个不同频段的信号x
k
(n),其中k=1,2,
…
,k。对每个频段的信号提取其包络并进行非线性处理,然后通过常数q变换(constant q transform,cqt)将包络特征变换到频域,计算每个频率段的均方值,得到基于调制频谱的语音特征——常q调制包络(constant q transform modulation envelope,cqme)。将提取出来的特征以图片的形式输出,经预处理后输入到改进的50层resnet分类网络中。本发明中的resnet分类网络采用了由2个1
×
1卷积层、1个3
×
3卷积层和1个shortcut连接而构成的残差单元,并将多层maxout(mmn)激活函数与dropout技术结合使用。常数q调制包络特征图输入到分类网络中后,首先通过1个7
×
7卷积层和3
×
3池化层,然后通过16个残差单元实现深度特征提取,再用平均池化减少数据量,最后由全连接层和softmax层得到该语音的分类。在训练阶段,将不同伪装语音的常q调制包络特征图训练数据集输入到该分类网络中,以交叉熵函数为损失函数进行训练。
48.特征提取模块对输入语音提取常数q调制包络特征。重放语音与真实语音相比,增
加了录音的步骤,会引入设备噪声、环境噪声以及编解码失真等。录音过程中,语音信号会通过不止一个路径传播,与真实语音相比存在延迟与衰减,在高频部分有明显的区别。合成语音与转换语音在形成的过程中,只模仿了谱包络的大致轮廓,帧间的细微变化没有被捕捉到,与自然语音相比,更加平滑且存在杂音。模仿语音与自然语音相似度最低,只可以在人耳级别混淆视听,声谱结构与真实语音差别明显。采用常数q调制包络特征可以将不同种类的伪装语音区别开。
49.特征提取模块对语音信号x(n)进行处理的具体内容为:
50.首先,输入的语音x(n)通过一个分频滤波器组,将语音分为k个不同频段的信号x
k
(n)。该功能通过mel滤波器组实现,根据语音信号的频率范围,这组滤波器的最低频率为300hz,最高频率为3400hz。本发明中k取128,即实现128分频。mel滤波器组是一组三角带通滤波器,每个带通滤波器的传递函数为h
k
(q),0≤k<k:
[0051][0052][0053][0054][0055]
其中,k为滤波器个数128,f(k)为第k个三角滤波器的中心mel频率,f(k
‑
1)为第k个三角滤波器的上限截止mel频率,f(k 1)第k个三角滤波器的下限截止mel频率,q为f(k
‑
1)和f(k 1)为之间的整数值。n为dft的点数,取256,f
s
为采样频率,取为8khz,f
l
为滤波器组的最低频率,f
h
为滤波器组的最高频率,分别为300hz和3400hz,f
mel
(f)可以将频率变换为mel频率,其中f为常规的频率值,即通过公式(3),常规频率值f可以变换为mel频率值f
mel
(f),是它的逆变换,b为mel频率值,即通过公式(4),mel频率值b可以变换为常规频率值
[0056]
然后对分频求得的信号x
k
(n)提取包络:
[0057][0058][0059]
其中,j为虚数单位,为x
k
(n)的希尔伯特变换,s
k
(n)为x
k
(n)的解析信号,为s
k
(n)的共轭信号,m
k
(n)为x
k
(n)的谱包络。进一步对语音包络进行非线性处理,本发明中的非线性通过对数函数来实现。
[0060]
下一步将经过非线性处理的包络lg(m
k
(n))通过常数q变换变换到频域,表示为:
[0061][0062][0063][0064][0065][0066]
其中,n表示时域信号的第n个时间分量,l表示常数q变换谱的总的频率分量数,f
min
为处理的lg(m
k
(n))的最低频率,f
max
为处理的lg(m
k
(n))的最高频率,f
l
为第l分量的频率,δf
l
为第l分量的滤波器带宽,q为一个恒定的常数,等于中心频率与滤波器带宽的比值,f
s
为采样频率,取8khz,l为常数q变换谱的频率序号,为第k个频段的第l个频率分量的常数q变换值,n
l
为随频率而变化的窗口长度,j为虚数单位,用来表示信号相位之间的关系,是长度为n
l
的汉明窗,汉明窗表达式为:
[0067][0068]
其中,n表示时域信号的第n个时间分量,用傅里叶变换处理信号时,频率点是等间隔分布的,相当于一组中心频率等间隔分布且具有相同带宽的滤波器组。而常数q变换最初是针对音乐信号的处理提出的,音乐的音阶频率间隔不是固定的,是以log2为底的,常数q变换可以看作一组中心频率按指数分布,且中心频率与带宽之比为常数的滤波器组,用常数q变换来处理更加符合语音信号的特性,时频分辨率可变,在低频处频率分辨率较高,高频处时间分辨率高。最后将每一个频率成分的均方值求出即可得到语音特征:
[0069][0070]
为第k个频段的第l个频率分量的常数q变换值,最终将得到的特征向量绘制成以频率为自变量的特征图,即为后续分类网络的输入。
[0071]
本实施例改进残差网络模块为改进后的resnet分类网络,输入到resnet分类网络的特征图首先需要经过预处理将大小调整为224
×
224
×
3。本发明采用了50层的残差网络作为分类网络,该残差网络包含5个卷积块。第1个卷积块为64个7
×
7的卷积核构成的卷积层,第2个卷积块由1个3
×
3的最大池化层和3个残差单元构成,其中每个残差单元由3层卷积层构成。
[0072]
本实施例中残差单元的结构如图2。其中,x为输入,shortcut连接将输入x直接传输到加法器,与经卷积层得到的输出f(x)相加,最终输出h(x)=f(x) x,残差网络需要训练
学习的将不再是输出h(x),而是残差f(x)=h(x)
‑
x,在极端情况h(x)=f(x)=x时,只需训练f(x)逼近于0即可。残差单元的原理可以表示为:
[0073]
y=f(x,{ω
i
}) ω
s
x
ꢀꢀ
(14)
[0074]
在这里,y表示残差单元的输出,ω
i
表示3层卷积的处理,ω
s
表示对shortcut连接做处理,使shortcut连接与残差映射的维度保持一致,从而可以直接相加,可以通过1
×
1卷积层来实现。1
×
1卷积层的作用是降维或升维,通过卷积核的个数决定处理后的维数。首先将输入特征矩阵降维至64,在第3层再升维至256,在最底层采用mmn作为激活函数,同时结合dropout技术,第2层和第3层采用relu作为激活函数。
[0075]
在残差单元中,第一层采用了mmn激活函数,mmn激活函数是在maxout激活函数的基础上发展的,maxout单元结构如图3所示。其中x
i
为输入向量,为第i个输入向量对应的第j个隐藏节点的权重系数,为第i个输入向量对应的第j个隐藏节点的偏移量,z
j
为输入向量x
i
加权后与偏置项之和,表示为:
[0076][0077]
和通过训练达到最优。若每个maxout单元包含g个隐藏节点,则每个maxout单元的输出为:
[0078][0079]
多个maxout单元联合使用即为mmn单元,本实施例使用的mmn单元结构如图4。其中,和两个参数分别表示,在第1次加权操作中,第i个输入向量对应的第j个输出节点的权重系数和偏移量,代表第1次加权的第j个节点的输出,表示第1次max操作的第j个节点的输出,的计算方式与maxout激活函数相同,与的计算方式相同。多个mmn单元构成mmn激活函数,maxout激活函数可以拟合任意凸函数,而mmn激活函数可以拟合任意形式的分布,可以更好的表示特征,收敛速度更快。
[0080]
在训练阶段,特征矩阵经过mmn激活函数处理后,结合dropout技术与下一层卷积层连接,即在每次训练过程中,随机忽略特定数量的隐藏节点,本发明中dropout隐藏50%,隐藏层mmn单元的数量为100个,相当于用不同的网络来训练,最后对训练结果取平均,在预测阶段不使用该技术,结合dropout技术的mmn激活函数结构如图5:
[0081]
第3层卷积块由4个残差单元构成,第4层卷积块由6个残差单元构成,第5层卷积块由3个残差单元构成,各层卷积块中残差单元的通道数不断递进,这5层卷积块如表1所示。
[0082][0083]
表1
[0084]
经过5层卷积块,对输出进行平均池化,降低数据的复杂度,然后通过全连接层将其输出,得到语音信号属于真伪语音的概率,最后通过softmax层得到其分类。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

