1.本发明涉及语音识别技术领域,具体而言,涉及一种发音识别的方法、装置、电子设备及计算机可读存储介质。
背景技术:
2.语言学习一直是人们所学知识中非常重要的一部分。在今天,随着计算机技术的发展,计算机辅助语言学习系统(computer
‑
assisted language learning system,call)也变得越来越流行。使用call系统,使得学习者可在方便的时间,以轻松的心态及适当的节奏学习第二语言。作为call系统不可或缺的一部分,计算机辅助发音训练系统(computer
‑
assisted pronunciation training system,capt)的主要目的就是给学习者提供纠正性的发音反馈,让学习者清楚发音的具体错误及相应的纠正信息。
3.发音指的是通过唇、舌头、颚、咽等构音器官的摩擦和阻断动作,发出各种语音的过程。一般而言,针对辅音的发音属性(articulatory attributes),使用发音位置和发音方式来描述;针对元音的发音属性,使用三个维度的特征来描述,包括:水平维度(tongue backness)、垂直维度(tongue height)、嘴唇形状(roundedness)。通过识别出语言学习者在发音过程的发音属性,并与标准文本对应的发音属性做比较,可以得出学习者存在的具体发音错误,并给出准确的纠正信息。
4.传统的发音识别方案,主要是通过语言学的知识制定相关规则,以抽取音频中和发音属性相关的特征。该方法识别效果差,且难以解决个体化差异较大的问题。部分方案采用建模的方式进行识别,但由于识别元音、辅音的发音属性时的所用的维度也各不相同,维度较多,模型较为复杂。
技术实现要素:
5.为解决现有存在的技术问题,本发明实施例提供一种发音识别的方法、装置、电子设备及计算机可读存储介质。
6.第一方面,本发明实施例提供了一种发音识别的方法,包括:
7.预设包含至少四个子模型的发音识别模型,四个所述子模型分别用于识别发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式;
8.获取待识别的目标语音数据以及与所述目标语音数据对应的标准文本,根据所述发音识别模型确定所述目标语音数据中的每个音素数据,并确定所述音素数据的发音维度,所述发音维度包括发音位置、发音方式、水平位置、垂直位置和嘴唇形状;
9.根据所述标准文本确定所述音素数据的类别,并根据所述音素数据的类别确定所述音素数据在不同发音维度中的发音属性;其中,在所述音素数据的类别为元音的情况下,确定所述音素数据在水平位置、垂直位置和嘴唇形状中的发音属性;在所述音素数据的类别为辅音的情况下,确定所述音素数据在发音位置和发音方式中的发音属性。
10.第二方面,本发明实施例还提供了一种发音识别的装置,包括:
11.模型模块,用于预设包含至少四个子模型的发音识别模型,四个所述子模型分别用于识别发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式;
12.处理模块,用于获取待识别的目标语音数据以及与所述目标语音数据对应的标准文本,根据所述发音识别模型确定所述目标语音数据中的每个音素数据,并确定所述音素数据的发音维度,所述发音维度包括发音位置、发音方式、水平位置、垂直位置和嘴唇形状;
13.识别模块,用于根据所述标准文本确定所述音素数据的类别,并根据所述音素数据的类别确定所述音素数据在不同发音维度中的发音属性;其中,在所述音素数据的类别为元音的情况下,确定所述音素数据在水平位置、垂直位置和嘴唇形状中的发音属性;在所述音素数据的类别为辅音的情况下,确定所述音素数据在发音位置和发音方式中的发音属性。
14.第三方面,本发明实施例提供了一种电子设备,包括总线、收发器、存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述收发器、所述存储器和所述处理器通过所述总线相连,所述计算机程序被所述处理器执行时实现上述任意一项所述的发音识别的方法中的步骤。
15.第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一项所述的发音识别的方法中的步骤。
16.本发明实施例提供的发音识别的方法、装置、电子设备及计算机可读存储介质,适用于得知目标语音数据对应的标准文本的场景,如在线教育的场景等;该方法设置的子模型分别能够识别发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式,从而可以基于音素数据的类别准确确定该音素数据的多种发音属性。该方法不需要设置过多的发音属性识别模型,可以简化模型,提高训练以及识别效率;且在训练子模型时,元音或辅音的样本均可以标注有意义的标签,从而可以避免增加无意义的标注,能够保证每个子模型识别结果的准确度。
附图说明
17.为了更清楚地说明本发明实施例或背景技术中的技术方案,下面将对本发明实施例或背景技术中所需要使用的附图进行说明。
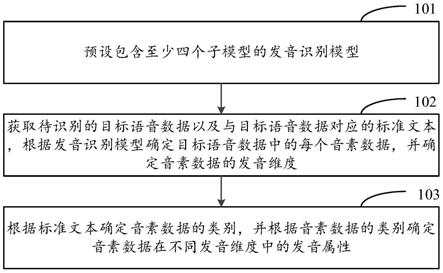
18.图1示出了本发明实施例所提供的一种发音识别的方法的流程图;
19.图2示出了本发明实施例所提供的一种发音识别的装置的结构示意图;
20.图3示出了本发明实施例所提供的一种用于执行发音识别的方法的电子设备的结构示意图。
具体实施方式
21.下面结合本发明实施例中的附图对本发明实施例进行描述。
22.图1示出了本发明实施例所提供的一种发音识别的方法的流程图。如图1所示,该方法包括:
23.步骤101:预设包含至少四个子模型的发音识别模型,四个子模型分别用于识别发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式。
24.本发明实施例中,发音识别模型包含用于识别不同发音维度的子模型。一般情况下,可以使用发音位置和发音方式这两种发音维度来描述辅音,使用水平位置、垂直位置、嘴唇形状这三种发音维度来描述元音;因此,一般需要建立多个模型分别用于识别:是否为元音(或者是否为辅音)、发音位置、发音方式、水平位置、垂直位置、嘴唇形状,共需六个模型。并且,由于元音不具有发音位置、发音方式这两种发音维度,而辅音不具有水平位置、垂直位置、嘴唇形状这三种发音维度,导致在训练过程中需要为样本添加大量无效的标签;例如,为元音的发音位置、发音方式添加无效的标签“n”或者“0”等。复杂的模型以及大量无效的标签均会影响发音识别的效果。
25.本发明实施例中,每种发音维度对应有多种发音属性。具体地,发音位置指的是发音时发音器官所在位置,例如舌尖抵住上颚发音、上下唇接触发音等。发音方式指的是发音时声带和气流的状态,如清爆破音(unvoiced
‑
stop)对应的发音方式为:声带不振动、气流先被阻塞然后突然释放,浊爆破音(voiced
‑
stop)对应的发音方式为:声带振动、气流先被阻塞然后突然释放。水平位置为发音器官(如舌头)在水平方向上的位置,如在口腔靠后的位置、在口腔中间、在口腔靠前的位置;垂直位置为发音器官(如舌头)在垂直方向上的位置,如在口腔较低的位置、在口腔中部、在口腔较高的位置。嘴唇形状一般包括圆形和非圆形两种。部分发音维度对应的发音属性可参见下表1所示:
26.表1
[0027][0028]
本发明实施例提供的方法应用于教育评测的场景,待识别的语音数据对应有相应的文本,例如用户(如学生)按照某文本a发出相应的声音,此时基于该文本a可以直接确定每个音素应该是元音还是辅音,故此时可以不以建模的方式识别是否为元音(或者是否为辅音)。并且,在已知音素为元音或辅音的情况下,本发明实施例能够以同一个模型(即下述的子模型)来识别元音和辅音的发音维度。具体地,本发明实施例提供的发音识别模型至少包含四个子模型,每个子模型分别用于识别:发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式;即,第一个子模型识别发音位置及水平位置,第二个子模型识别发音位置及垂直位置,第三个子模型识别发音位置及嘴唇形状,第四个子模型识别发音方式。四个子模型分别识别语音数据的不同发音维度,基于四个子模型的输出结果可以确定语音数据在不同发音维度中的发音属性。
[0029]
例如,第一个子模型用于识别发音位置及水平位置,即将待识别的语音数据输入到第一个子模型后,该第一个子模型的输出结果可以表示该语音数据的发音位置及水平位
置。具体地,若该语音数据为元音,则该第一个子模型的输出结果具体表示水平位置(此时可以忽略发音位置);若该语音数据为辅音,则该第一个子模型的输出结果具体表示发音位置(此时可以忽略水平位置)。相应地,在训练该第一个子模型时,元音对应的标签为水平位置中的发音属性,辅音对应的标签为发音位置中的发音属性。例如,元音/u:/的水平位置为口腔后部,即其对应的标签可以为表1中的“back”。此外,由于水平位置、垂直位置和嘴唇形状均与发音位置具有一定的相似性,本实施例中的三个子模型均可用于识别发音位置。
[0030]
此外,在训练每个子模型时,无论样本是元音还是辅音,都可以为其设置有意义的标签;例如,在训练地一个子模型时,若样本为元音,则样本的标签为水平位置;若样本为辅音,则样本的标签为发音位置。此外,虽然元音不具有发音方式这一发音维度,但此时也可以为发音方式增加专门用于标注元音的标签,如“vowel”。
[0031]
本发明实施例中,可以使用tdnn
‑
hmm(time delay neural network,时间延迟神经网络;hidden markov model,隐马尔科夫模型)框架对上述四种子模型分别进行统计建模。而为了训练tdnn
‑
hmm,需要先获得帧级别对齐的有标签训练数据。本发明实施例中,可以预先训练一个gmm
‑
hmm(gaussian mixture model,高斯混合模型),再基于gmm
‑
hmm对训练数据做强制对齐,进而得到帧级别对齐的有标签训练数据。其中,从训练数据得到帧级别对齐的有标签训练数据是现有的成熟技术,此处不做详述。基于tdnn
‑
hmm框架训练得到识别发音属性的子模型,可以减少对语言学规则的依赖,方便推广到其他语种。
[0032]
步骤102:获取待识别的目标语音数据以及与目标语音数据对应的标准文本,根据发音识别模型确定目标语音数据中的每个音素数据,并确定音素数据的发音维度,该音素数据的发音维度包括发音位置、发音方式、水平位置、垂直位置和嘴唇形状。
[0033]
本发明实施例中,将待识别的语音数据称为目标语音数据,并且该目标语音数据对应有相应的文本,即标准文本。例如,将标准文本显示给用户,指示用户念出该标准文本,并基于终端采集到用户发出的声音,即可得到目标语音数据。发音识别模型(或者每个子模型)可以对目标语音数据进行强制对齐,提取出目标语音数据中的每个音素对应的语音段,即音素数据,进而确定每个音素数据的发音维度。由于存在多个子模型,且部分子模型可以确定多种发音维度,故本实施例所确定的音素数据的发音维度包括:发音位置、发音方式、水平位置、垂直位置和嘴唇形状。其中,由于三个子模型均可确定发音位置,本实施例可以基于三个子模型的输出结果综合确定音素数据的发音位置,例如将置信度最高的输出结果所对应的发音位置作为该音素数据的发音位置。
[0034]
本领域技术人员可以理解,子模型在识别目标语音数据时不需要关注其中的音素数据对应元音还是辅音,子模型基于输入的目标语音数据即可确定相应的输出结果,该输出结果可以包含多种发音维度。例如,第一个子模型的输出结果包含发音位置和水平位置两种发音维度,而无论地一个子模型的输入是元音还是辅音。
[0035]
步骤103:根据标准文本确定音素数据的类别,并根据音素数据的类别确定音素数据在不同发音维度中的发音属性;其中,在音素数据的类别为元音的情况下,确定音素数据在水平位置、垂直位置和嘴唇形状中的发音属性;在音素数据的类别为辅音的情况下,确定音素数据在发音位置和发音方式中的发音属性。
[0036]
本发明实施例中,音素数据的类别包括两种,即元音和辅音。由于标准文本的存在,可以基于该标准文本确定目标语音数据中每个音素数据具体对应哪个音素,从而可以
确定该音素数据对应的是元音还是辅音,即可以确定音素数据的类别。若该音素数据为元音,则根据子模型的输出结果可以确定该音素数据在水平位置、垂直位置和嘴唇形状三种发音维度中的发音属性。相应地,若该音素数据为辅音,则根据子模型的输出结果可以确定该音素数据在发音位置和发音方式两种发音维度中的发音属性。对目标语音数据中的所有音素数据均可执行上述过程,从而可以确定每个音素数据的发音属性,进而基于该发音属性实现发音识别功能。
[0037]
例如,若音素数据a对应元音/u:/,且该音素数据a输入到第一个子模型后确定了其发音位置为“上下唇接触发音”,水平位置为“口腔后部”;由于该音素数据a为元音,故忽略确定的发音位置即可,该音素数据a的水平位置为“口腔后部”。其中,本领域技术人员可以理解,上述例子只是为了方便理解,在实际情况下第一个子模型的输出结果虽然可以对应发音位置,但此时的发音位置可以只是代码或者置信度,不需要确定其发音位置具体是哪种发音属性,如不需要确定发音位置具体是“上下唇接触发音”。
[0038]
本发明实施例提供的一种发音识别的方法,适用于得知目标语音数据对应的标准文本的场景,如在线教育的场景等;该方法设置的子模型分别能够识别发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式,从而可以基于音素数据的类别准确确定该音素数据的多种发音属性。该方法不需要设置过多的发音属性识别模型,可以简化模型,提高训练以及识别效率;且在训练子模型时,元音或辅音的样本均可以标注有意义的标签,从而可以避免增加无意义的标注,能够保证每个子模型识别结果的准确度。
[0039]
在上述实施例的基础上,上述步骤103“根据标准文本确定音素数据的类别,并根据音素数据的类别确定音素数据在不同发音维度中的发音属性”包括:
[0040]
步骤a1:根据标准文本确定音素数据的类别,在音素数据的类别为元音的情况下,将水平位置、垂直位置和嘴唇形状作为音素数据的决策范围;在音素数据的类别为辅音的情况下,将发音位置和发音方式作为音素数据的决策范围。
[0041]
本发明实施例中,如上所述,将音素数据的类别分为元音和辅音,本实施例基于该音素数据的类别来确定相应的决策范围,方便后续在该决策范围内有针对性地进行处理。该决策范围对应相应的发音维度;具体地,若音素数据的类别为元音,则该决策范围包括水平位置、垂直位置和嘴唇形状;若该音素数据的类别为辅音,则决策范围包括发音位置和发音方式。
[0042]
步骤a2:根据子模型的输出结果确定音素数据对应子模型能够识别的发音维度的概率向量。
[0043]
本发明实施例中,每个子模型能够识别相应的发音维度,例如第一个子模型可以识别发音位置及水平位置这两个发音维度;音素数据输入到子模型后,该子模型的输出结果即对应相应发音维度的概率向量,即该子模型能够识别的发音维度的概率向量。其中,该概率向量包含多个向量元素,一个向量元素对应一个发音属性,且该概率向量中的向量元素表示该音素数据属于相应发音属性的概率。例如,第一个子模型用于识别发音位置及水平位置,一般情况下,发音位置包含7种发音属性,且如上表1所示,水平位置包含3种发音属性;故,可以以10维的概率向量(包含10个向量元素)表示基于该第一个子模型的输出结果所确定的概率向量。
[0044]
可选地,上述步骤a2“根据子模型的输出结果确定音素数据对应子模型能够识别
的发音维度的概率向量”包括:
[0045]
步骤a21:根据发音识别模型对目标语音数据进行强制对齐,确定音素数据的开始帧时间t
s
和结束帧时间t
e
,并确定音素数据中每帧子数据的后验概率。
[0046]
本发明实施例中,每个音素数据对应一个时间段的音频段,例如0.2秒的音频段,该音素数据包含多帧数据,本实施例中将每帧数据称为一个“子数据”。发音识别模型具有强制对其功能,可以确定每帧的子数据属于哪个音素,即可以确定该子数据属于哪个音素数据。例如,可以基于tdnn
‑
hmm框架的子模型对目标语音数据(也需要输入标准文本)进行强制对齐,从而可以确定每个音素数据的开始时间和结束时间,即开始帧时间t
s
和结束帧时间t
e
。并且,每个子模型的输出结果可以用于表示每帧子数据的后验概率。例如,可以基于前向算法在子模型的输出层得到帧级别的后验概率。
[0047]
步骤a22:确定音素数据具有目标发音属性a的对数后验概率lap(a),且:
[0048][0049]
其中,o
t
为音素数据的输入特征,目标发音属性a为在子模型能够识别的发音维度中的发音属性,s表示子模型的输出结果匹配目标发音属性a的子数据,p(s|o
t
)表示子数据s的后验概率。
[0050]
本发明实施例中,将子模型能够识别的发音维度中的发音属性称为目标发音属性a;例如,第一个子模型能够识别水平纬度,如表1所示,该水平纬度中的发音属性“back”、“central”等均可作为目标发音属性a。在计算过程中,对于每帧输入的子数据,子模型输出所有tri
‑
attribute(三发音属性)状态s的后验概率,将其中属于目标发音属性a的tri
‑
attribute状态s的后验概率累加,然后取对数,最后,在一个音素段上做算术平均得到当前音素段目标发音属性a的对数后验概率(log attribute posterior),即lap(a)。
[0051]
步骤a23:将每个对数后验概率分别作为一项向量元素,生成音素数据对应子模型能够识别的发音维度的概率向量。
[0052]
本发明实施例中,由于子模型能够识别的发音维度包含多个发音属性,即存在多个目标发音属性a,本实施例将每个目标发音属性a的对数后验概率作为概率向量的一个向量元素,从而可以生成相应的概率向量,该概率向量即为音素数据对应子模型能够识别的发音维度的概率向量。在存在四个子模型的情况下,音素数据也对应有四个概率向量。
[0053]
步骤a3:对概率向量中属于决策范围的向量元素进行归一化处理,并将归一化处理后的最大值所对应的发音属性作为音素数据在子模型能够识别的发音维度中的发音属性。
[0054]
本发明实施例中,基于步骤a1所确定的决策范围进行有针对性地归一化处理,即只对属于该决策范围的向量元素进行归一化处理。例如,第一个子模型对应的概率向量为10维的,其中的7个向量元素属于发音位置,另外3个向量元素属于水平位置;若该音素数据为元音,其决策范围包含水平位置,故此时只对概率向量中相应的3个向量元素进行归一化处理;相反地,若音素数据为辅音,其决策范围包含发音位置,故此时只对概率向量中相应的7个向量元素进行归一化处理。并且,归一化处理后的最大值所对应的发音属性即为该音素数据大概率具有的发音数据,且该发音属性是音素数据在子模型能够识别的发音维度中
的发音属性。对于每个子模型均执行上述过程,即可确定音素数据的所有发音属性。例如,若音素数据为元音,则基于第一个子模型可以确定该音素数据水平位置的发音属性,基于第二个子模型可以确定该音素数据垂直位置的发音属性,基于第三个子模型可以确定该音素数据嘴唇形状的发音属性,第四个子模型与元音无关,此时可以忽略第四个子模型的输出。
[0055]
可选地,上述步骤a3“将归一化处理后的最大值所对应的发音属性作为音素数据在子模型能够识别的发音维度中的发音属性”包括:
[0056]
步骤a31:设置概率阈值。
[0057]
步骤a32:在归一化处理后的最大值大于概率阈值的情况下,将归一化处理后的最大值所对应的发音属性作为音素数据在子模型能够识别的发音维度中的发音属性。
[0058]
本发明实施例中,在归一化以后的lap概率向量中,若一种发音属性相对于其他发音属性的对数后验概率值越大,则可认为把当前音频段识别为该种发音属性的结果越可靠。因此,通过设置归一化后验概率阈值,即步骤a31中的概率阈值,若最大值大于该概率阈值,则认为当前音频段的识别结果可靠。
[0059]
本发明实施例在确定后验概率后,进一步确定每种发音属性的对数后验概率,以对数形式能够准确地表示发音属性对应的概率;且设置决策范围,并只对属于决策范围的向量元素进行归一化处理,能够准确地区分元音和辅音,元音和辅音是绝对隔离的,即辅音的结果中不会出现元音的特征,元音也同样不会出现辅音的特征。通过设置概率阈值,可以筛选出可靠的识别结果,能够保证较高的发音属性的识别准确率;经验证,该准确率可达96%以上。
[0060]
在上述实施例的基础上,该方法还包括:
[0061]
步骤b1:预先建立从第一发音属性改为第二发音属性的纠正文本。
[0062]
本发明实施例中,第一发音属性和第二发音属性为属于同一发音维度的、不同的发音属性,该纠正文本为表示从第一发音属性改为第二发音属性的文本。例如,垂直位置具有三个发音属性,从中依次选取两个发音属性作为第一发音属性和第二发音属性,共有六种选择;以表1中发音属性代码表示:lo
→
mi、lo
→
hi、mi
→
hi、hi
→
mi、hi
→
lo、mi
→
lo。若第一发音属性为lo,第二发音属性为mi,则lo
→
mi对应的纠正文本可以为“抬高舌头的高度”。
[0063]
步骤b2:在确定音素数据在不同发音维度中的发音属性之后,对音素数据的发音属性与标准发音属性进行对比,确定与标准发音属性不同的错误发音属性,并确定相应的有效纠正文本,有效纠正文本为以错误发音属性为第一发音属性、以标准发音属性为第二发音属性时所对应的纠正文本。
[0064]
本发明实施例中,根据上述步骤101
‑
103等可以确定音素数据在多个发音维度中的发音属性,并且,基于标准文本可以确定每个音素数据正确的发音属性,即标准发音属性。若音素数据的发音属性与该标准发音属性相同,则说明用户正确地发音了;否则,说明用户的发音存在问题,此时将音素数据的发音属性中,与标准发音属性不同的发音属性作为错误发音属性,以该错误发音属性作为第一发音属性,以与该错误发音属性对应的标准发音属性作为第二发音属性,可以确定相应的纠正文本,即有效纠正文本。
[0065]
例如,学生的目标语音数据对应的标准文本为school,则该目标语音数据中第三个音素数据应该为元音/u:/,其水平位置的发音属性应该为“back”,即该音素数据的标准
发音属性为“back”。若经第一个子模型的输出结果确定,该音素数据在水平位置这一发音维度中的发音属性为“central”,即该学生在发/u:/这个因素时,舌头在口腔中间;故此时可以把第一发音属性是“central”、第二发音属性是“back”对应的纠正文本作为有效纠正文本,如该有效纠正文本可以是“发音时将舌位靠后一些”。
[0066]
步骤b3:生成音素数据的反馈方案,该反馈方案包含错误发音属性对应的文本、标准发音属性对应的文本、有效纠正文本和错误发音属性所属的发音维度。
[0067]
本发明实施例中,根据目标语音数据中音素数据的识别结果可以生成相应的反馈方案,该反馈方案包括错误发音属性对应的文本、标准发音属性对应的文本、有效纠正文本和错误发音属性所属的发音维度等多种内容,可以方便用户定位到本身的具体问题,并能够向用户提供准确地纠正意见,方便用户纠正本身的错误。可选地,可以预先设置反馈方案的模板,将相应的内容填充到模板中,从而可以快速地生成反馈方案。
[0068]
仍然以上述步骤b2所示的例子为例,其错误发音属性所属的发音维度为水平位置,错误发音属性对应的文本为“在口腔中间”、标准发音属性对应的文本为“在口腔较靠后的位置”、有效纠正文本为“发音时将舌位靠后一些”。若反馈方案的模板为:错误的音素为:[1];错误原因为:[2]不对;错误纠正:[2]应该是[3],而不是[4],请[5],再试一次。其中,[1]表示该反馈方案对应的音素数据的文本,如元音/u:/,[2]表示错误发音属性所属的发音维度,[3]表示标准发音属性对应的文本,[4]表示错误发音属性对应的文本,[5]表示有效纠正文本。相应地,该反馈方案具体可以是:
[0069]
错误的音素为:元音/u:/;
[0070]
错误原因为:水平位置不对;
[0071]
错误纠正:水平位置应该是在口腔较靠后的位置,而不是在口腔中间,请发音时将舌位靠后一些,再试一次。
[0072]
本发明实施例提供的一种发音识别的方法,适用于得知目标语音数据对应的标准文本的场景,如在线教育的场景等;该方法设置的子模型分别能够识别发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式,从而可以基于音素数据的类别准确确定该音素数据的多种发音属性。该方法不需要设置过多的发音属性识别模型,可以简化模型,提高训练以及识别效率;且在训练子模型时,元音或辅音的样本均可以标注有意义的标签,从而可以避免增加无意义的标注,能够保证每个子模型识别结果的准确度。以对数形式能够准确地表示发音属性对应的概率;且设置决策范围,并只对属于决策范围的向量元素进行归一化处理,能够准确地区分元音和辅音,元音和辅音是绝对隔离的;通过设置概率阈值,可以筛选出可靠的识别结果,能够保证较高的发音属性的识别准确率。在发音识别后可以生成包含纠正文本的反馈方案,方便用户准确纠正自己的问题,能够提高学习效果。
[0073]
上文详细描述了本发明实施例提供的发音识别的方法,该方法也可以通过相应的装置实现,下面详细描述本发明实施例提供的发音识别的装置。
[0074]
图2示出了本发明实施例所提供的一种发音识别的装置的结构示意图。如图2所示,该发音识别的装置包括:
[0075]
模型模块21,用于预设包含至少四个子模型的发音识别模型,四个所述子模型分别用于识别发音位置及水平位置、发音位置及垂直位置、发音位置及嘴唇形状、发音方式;
[0076]
处理模块22,用于获取待识别的目标语音数据以及与所述目标语音数据对应的标准文本,根据所述发音识别模型确定所述目标语音数据中的每个音素数据,并确定所述音素数据的发音维度,所述发音维度包括发音位置、发音方式、水平位置、垂直位置和嘴唇形状;
[0077]
识别模块23,用于根据所述标准文本确定所述音素数据的类别,并根据所述音素数据的类别确定所述音素数据在不同发音维度中的发音属性;其中,在所述音素数据的类别为元音的情况下,确定所述音素数据在水平位置、垂直位置和嘴唇形状中的发音属性;在所述音素数据的类别为辅音的情况下,确定所述音素数据在发音位置和发音方式中的发音属性。
[0078]
在上述实施例的基础上,所述识别模块23根据所述标准文本确定所述音素数据的类别,并根据所述音素数据的类别确定所述音素数据在不同发音维度中的发音属性,包括:
[0079]
根据所述标准文本确定所述音素数据的类别,在所述音素数据的类别为元音的情况下,将水平位置、垂直位置和嘴唇形状作为所述音素数据的决策范围;在所述音素数据的类别为辅音的情况下,将发音位置和发音方式作为所述音素数据的决策范围;
[0080]
根据所述子模型的输出结果确定所述音素数据对应所述子模型能够识别的发音维度的概率向量;
[0081]
对所述概率向量中属于所述决策范围的向量元素进行归一化处理,并将归一化处理后的最大值所对应的发音属性作为所述音素数据在所述子模型能够识别的发音维度中的发音属性。
[0082]
在上述实施例的基础上,所述识别模块23根据所述子模型的输出结果确定所述音素数据对应所述子模型能够识别的发音维度的概率向量,包括:
[0083]
根据所述发音识别模型对所述目标语音数据进行强制对齐,确定所述音素数据的开始帧时间t
s
和结束帧时间t
e
,并确定所述音素数据中每帧子数据的后验概率;
[0084]
确定所述音素数据具有目标发音属性a的对数后验概率lap(a),且:
[0085][0086]
其中,o
t
为所述音素数据的输入特征,目标发音属性a为在所述子模型能够识别的发音维度中的发音属性,s表示所述子模型的输出结果匹配所述目标发音属性a的子数据,p(s|o
t
)表示子数据s的后验概率;
[0087]
将每个所述对数后验概率分别作为一项向量元素,生成所述音素数据对应所述子模型能够识别的发音维度的概率向量。
[0088]
在上述实施例的基础上,所述识别模块23将归一化处理后的最大值所对应的发音属性作为所述音素数据在所述子模型能够识别的发音维度中的发音属性,包括:
[0089]
设置概率阈值;
[0090]
在归一化处理后的最大值大于所述概率阈值的情况下,将所述归一化处理后的最大值所对应的发音属性作为所述音素数据在所述子模型能够识别的发音维度中的发音属性。
[0091]
在上述实施例的基础上,该装置还包括反馈模块;所述反馈模块用于:
[0092]
预先建立从第一发音属性改为第二发音属性的纠正文本;
[0093]
在所述确定所述音素数据在不同发音维度中的发音属性之后,对所述音素数据的发音属性与标准发音属性进行对比,确定与所述标准发音属性不同的错误发音属性,并确定相应的有效纠正文本,所述有效纠正文本为以所述错误发音属性为第一发音属性、以所述标准发音属性为第二发音属性时所对应的纠正文本;
[0094]
生成所述音素数据的反馈方案,所述反馈方案包含所述错误发音属性对应的文本、所述标准发音属性对应的文本、所述有效纠正文本和所述错误发音属性所属的发音维度。
[0095]
此外,本发明实施例还提供了一种电子设备,包括总线、收发器、存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该收发器、该存储器和处理器分别通过总线相连,计算机程序被处理器执行时实现上述发音识别的方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
[0096]
具体的,参见图3所示,本发明实施例还提供了一种电子设备,该电子设备包括总线1110、处理器1120、收发器1130、总线接口1140、存储器1150和用户接口1160。
[0097]
在本发明实施例中,该电子设备还包括:存储在存储器1150上并可在处理器1120上运行的计算机程序,计算机程序被处理器1120执行时实现上述发音识别的方法实施例的各个过程。
[0098]
收发器1130,用于在处理器1120的控制下接收和发送数据。
[0099]
本发明实施例中,总线架构(用总线1110来代表),总线1110可以包括任意数量互联的总线和桥,总线1110将包括由处理器1120代表的一个或多个处理器与存储器1150代表的存储器的各种电路连接在一起。
[0100]
总线1110表示若干类型的总线结构中的任何一种总线结构中的一个或多个,包括存储器总线以及存储器控制器、外围总线、加速图形端口(accelerate graphical port,agp)、处理器或使用各种总线体系结构中的任意总线结构的局域总线。作为示例而非限制,这样的体系结构包括:工业标准体系结构(industry standard architecture,isa)总线、微通道体系结构(micro channel architecture,mca)总线、扩展isa(enhanced isa,eisa)总线、视频电子标准协会(video electronics standards association,vesa)、外围部件互连(peripheral component interconnect,pci)总线。
[0101]
处理器1120可以是一种集成电路芯片,具有信号处理能力。在实现过程中,上述方法实施例的各步骤可以通过处理器中硬件的集成逻辑电路或软件形式的指令完成。上述的处理器包括:通用处理器、中央处理器(central processing unit,cpu)、网络处理器(network processor,np)、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field programmable gate array,fpga)、复杂可编程逻辑器件(complex programmable logic device,cpld)、可编程逻辑阵列(programmable logic array,pla)、微控制单元(microcontroller unit,mcu)或其他可编程逻辑器件、分立门、晶体管逻辑器件、分立硬件组件。可以实现或执行本发明实施例中公开的各方法、步骤及逻辑框图。例如,处理器可以是单核处理器或多核处理器,处理器可以集成于单颗芯片或位于多颗不同的芯片。
[0102]
处理器1120可以是微处理器或任何常规的处理器。结合本发明实施例所公开的方
法步骤可以直接由硬件译码处理器执行完成,或者由译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存取存储器(random access memory,ram)、闪存(flash memory)、只读存储器(read
‑
only memory,rom)、可编程只读存储器(programmable rom,prom)、可擦除可编程只读存储器(erasable prom,eprom)、寄存器等本领域公知的可读存储介质中。所述可读存储介质位于存储器中,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。
[0103]
总线1110还可以将,例如外围设备、稳压器或功率管理电路等各种其他电路连接在一起,总线接口1140在总线1110和收发器1130之间提供接口,这些都是本领域所公知的。因此,本发明实施例不再对其进行进一步描述。
[0104]
收发器1130可以是一个元件,也可以是多个元件,例如多个接收器和发送器,提供用于在传输介质上与各种其他装置通信的单元。例如:收发器1130从其他设备接收外部数据,收发器1130用于将处理器1120处理后的数据发送给其他设备。取决于计算机系统的性质,还可以提供用户接口1160,例如:触摸屏、物理键盘、显示器、鼠标、扬声器、麦克风、轨迹球、操纵杆、触控笔。
[0105]
应理解,在本发明实施例中,存储器1150可进一步包括相对于处理器1120远程设置的存储器,这些远程设置的存储器可以通过网络连接至服务器。上述网络的一个或多个部分可以是自组织网络(ad hoc network)、内联网(intranet)、外联网(extranet)、虚拟专用网(vpn)、局域网(lan)、无线局域网(wlan)、广域网(wan)、无线广域网(wwan)、城域网(man)、互联网(internet)、公共交换电话网(pstn)、普通老式电话业务网(pots)、蜂窝电话网、无线网络、无线保真(wi
‑
fi)网络以及两个或更多个上述网络的组合。例如,蜂窝电话网和无线网络可以是全球移动通信(gsm)系统、码分多址(cdma)系统、全球微波互联接入(wimax)系统、通用分组无线业务(gprs)系统、宽带码分多址(wcdma)系统、长期演进(lte)系统、lte频分双工(fdd)系统、lte时分双工(tdd)系统、先进长期演进(lte
‑
a)系统、通用移动通信(umts)系统、增强移动宽带(enhance mobile broadband,embb)系统、海量机器类通信(massive machine type of communication,mmtc)系统、超可靠低时延通信(ultra reliable low latency communications,urllc)系统等。
[0106]
应理解,本发明实施例中的存储器1150可以是易失性存储器或非易失性存储器,或可包括易失性存储器和非易失性存储器两者。其中,非易失性存储器包括:只读存储器(read
‑
only memory,rom)、可编程只读存储器(programmable rom,prom)、可擦除可编程只读存储器(erasable prom,eprom)、电可擦除可编程只读存储器(electrically eprom,eeprom)或闪存(flash memory)。
[0107]
易失性存储器包括:随机存取存储器(random access memory,ram),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的ram可用,例如:静态随机存取存储器(static ram,sram)、动态随机存取存储器(dynamic ram,dram)、同步动态随机存取存储器(synchronous dram,sdram)、双倍数据速率同步动态随机存取存储器(double data rate sdram,ddrsdram)、增强型同步动态随机存取存储器(enhanced sdram,esdram)、同步连接动态随机存取存储器(synchlink dram,sldram)和直接内存总线随机存取存储器(direct rambus ram,drram)。本发明实施例描述的电子设备的存储器1150包括但不限于上述和任意其他适合类型的存储器。
[0108]
在本发明实施例中,存储器1150存储了操作系统1151和应用程序1152的如下元素:可执行模块、数据结构,或者其子集,或者其扩展集。
[0109]
具体而言,操作系统1151包含各种系统程序,例如:框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务。应用程序1152包含各种应用程序,例如:媒体播放器(media player)、浏览器(browser),用于实现各种应用业务。实现本发明实施例方法的程序可以包含在应用程序1152中。应用程序1152包括:小程序、对象、组件、逻辑、数据结构以及其他执行特定任务或实现特定抽象数据类型的计算机系统可执行指令。
[0110]
此外,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述发音识别的方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
[0111]
计算机可读存储介质包括:永久性和非永久性、可移动和非可移动媒体,是可以保留和存储供指令执行设备所使用指令的有形设备。计算机可读存储介质包括:电子存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备以及上述任意合适的组合。计算机可读存储介质包括:相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、非易失性随机存取存储器(nvram)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、光盘只读存储器(cd
‑
rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带存储、磁带磁盘存储或其他磁性存储设备、记忆棒、机械编码装置(例如在其上记录有指令的凹槽中的穿孔卡或凸起结构)或任何其他非传输介质、可用于存储可以被计算设备访问的信息。按照本发明实施例中的界定,计算机可读存储介质不包括暂时信号本身,例如无线电波或其他自由传播的电磁波、通过波导或其他传输介质传播的电磁波(例如穿过光纤电缆的光脉冲)或通过导线传输的电信号。
[0112]
在本技术所提供的几个实施例中,应该理解到,所披露的装置、电子设备和方法,可以通过其他的方式实现。例如,以上描述的装置实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口、装置或单元的间接耦合或通信连接,也可以是电的、机械的或其他的形式连接。
[0113]
所述作为分离部件说明的单元可以是或也可以不是物理上分开的,作为单元显示的部件可以是或也可以不是物理单元,既可以位于一个位置,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或全部单元来解决本发明实施例方案要解决的问题。
[0114]
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以是两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0115]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术作出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计
算机设备(包括:个人计算机、服务器、数据中心或其他网络设备)执行本发明各个实施例所述方法的全部或部分步骤。而上述存储介质包括如前述所列举的各种可以存储程序代码的介质。
[0116]
在本发明实施例的描述中,所属技术领域的技术人员应当知道,本发明实施例可以实现为方法、装置、电子设备及计算机可读存储介质。因此,本发明实施例可以具体实现为以下形式:完全的硬件、完全的软件(包括固件、驻留软件、微代码等)、硬件和软件结合的形式。此外,在一些实施例中,本发明实施例还可以实现为在一个或多个计算机可读存储介质中的计算机程序产品的形式,该计算机可读存储介质中包含计算机程序代码。
[0117]
上述计算机可读存储介质可以采用一个或多个计算机可读存储介质的任意组合。计算机可读存储介质包括:电、磁、光、电磁、红外或半导体的系统、装置或器件,或者以上任意的组合。计算机可读存储介质更具体的例子包括:便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom)、闪存(flash memory)、光纤、光盘只读存储器(cd
‑
rom)、光存储器件、磁存储器件或以上任意组合。在本发明实施例中,计算机可读存储介质可以是任意包含或存储程序的有形介质,该程序可以被指令执行系统、装置、器件使用或与其结合使用。
[0118]
上述计算机可读存储介质包含的计算机程序代码可以用任意适当的介质传输,包括:无线、电线、光缆、射频(radio frequency,rf)或者以上任意合适的组合。
[0119]
可以以汇编指令、指令集架构(isa)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、集成电路配置数据或以一种或多种程序设计语言或其组合来编写用于执行本发明实施例操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言,例如:java、smalltalk、c ,还包括常规的过程式程序设计语言,例如:c语言或类似的程序设计语言。计算机程序代码可以完全的在用户计算机上执行、部分的在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行以及完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络,包括:局域网(lan)或广域网(wan),可以连接到用户计算机,也可以连接到外部计算机。
[0120]
本发明实施例通过流程图和/或方框图描述所提供的方法、装置、电子设备。
[0121]
应当理解,流程图和/或方框图的每个方框以及流程图和/或方框图中各方框的组合,都可以由计算机可读程序指令实现。这些计算机可读程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,从而生产出一种机器,这些计算机可读程序指令通过计算机或其他可编程数据处理装置执行,产生了实现流程图和/或方框图中的方框规定的功能/操作的装置。
[0122]
也可以将这些计算机可读程序指令存储在能使得计算机或其他可编程数据处理装置以特定方式工作的计算机可读存储介质中。这样,存储在计算机可读存储介质中的指令就产生出一个包括实现流程图和/或方框图中的方框规定的功能/操作的指令装置产品。
[0123]
也可以将计算机可读程序指令加载到计算机、其他可编程数据处理装置或其他设备上,使得在计算机、其他可编程数据处理装置或其他设备上执行一系列操作步骤,以产生计算机实现的过程,从而使得在计算机或其他可编程数据处理装置上执行的指令能够提供实现流程图和/或方框图中的方框规定的功能/操作的过程。
[0124]
以上所述,仅为本发明实施例的具体实施方式,但本发明实施例的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明实施例披露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明实施例的保护范围之内。因此,本发明实施例的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

