基于改进synth2aug的配网调度员身份验证方法及系统
技术领域
1.本发明涉及配电网调度领域,尤其涉及一种基于改进synth2aug的配网调度员身份验证方法及系统。
背景技术:
2.随着电网规模的不断扩大,调度机构管辖的电力设备越来越多,调度人员更换交接频繁,为了保证电网调度安全,需要对调度人员的身份进行验证。目前电网调度双方人员通过互相通报姓名方式实现身份认证,很容易造成外部人员冒名顶替的安全隐患。为了保证调度系统安全,现有研究文献提出利用深度学习模型对调度双方进行声纹识别的策略。但在电网调度工作中,省调或市调部门调度人员的数量较少,且每人能提供的采样样本有限,无法满足深度学习模型的需要。
3.针对以上问题,本发明在现有synth2aug技术基础上,提出一种基于改进synth2aug的配网调度员身份验证方法,进行配网调度人员声纹识别,从而提高调度人员身份认证的精准度。
技术实现要素:
4.为解决现有技术中存在的不足,本发明的目的在于,提供一种基于改进synth2aug的配网调度员身份验证方法及系统,根据调度指令关键词自生成调度人员虚拟指令语音,与真实原始语音一起实现对声纹模型的训练,进行配网调度人员声纹识别,从而提高调度人员身份认证的精准度。
5.为实现本发明的目的,本发明所采用的技术方案是:
6.一种基于改进synth2aug的配网调度员身份验证方法,所述方法包括步骤:
7.(1)给定一组调度指令关键词;
8.(2)根据给定的调度指令关键词,利用不同的mttg模型形成不同的调度文本指令;
9.(3)利用文本语音转化模块将步骤(2)得到的调度文本指令转化为虚拟调度指令语音;
10.(4)将调度人员原始录音采样样本按照一定比例分为调度人员训练语音和调度人员测试语音;
11.(5)将虚拟调度指令语音与调度人员训练语音进行混合,形成声纹识别模型的整体训练样本,对调度人员声纹识别模型进行训练;
12.(6)模型训练成功后,利用调度人员测试语音样本对模型进行测试;输出调度人员身份认证结果,确定调度人员身份验证是否成功。
13.进一步地,所述步骤(2)中,mttg_1模型使用双向lstm作为核心模块,生成调度文本指令,使用修饰成分较少;mttg_2模型使用gru作为核心模块,生成调度文本指令,使用相应的修饰成分。
14.进一步地,所述步骤(3)中,文本语音转化模块采用tacotron2模型实现,将调度文
本指令作为模型的输入,输出调度人员虚拟调度指令语音。
15.进一步地,所述步骤(4)中,将调度人员原始录音采样样本按照7:3比例分为调度人员训练语音和调度人员测试语音。
16.进一步地,所述步骤(5)中,将虚拟调度指令语音与调度人员训练语音分别分成n个大小不等的子集,即虚拟调度指令语音子集(vaudioi_k,k=1,2,..n)和原始调度人员训练语音子集(audio_train_k,k=1,2,..n),分别从虚拟调度指令语音子集和原始调度人员训练语音子集取出k相等的子集进行混合,形成n个混合子集,最后将n个混合子集输入到声纹识别训练模型进行模型的训练。
17.进一步地,n可取10。
18.一种基于改进synth2aug的配网调度员身份验证系统,所述系统包括调度文本指令生成模块、文本语音转化模块、调度人员原始录音采样模块、调度人员声纹识别模型训练模块、配网调度员身份验证模块;
19.调度文本指令生成模块,根据给定的调度指令关键词,利用不同的mttg模型形成不同的调度文本指令;
20.文本语音转化模块,利用文本语音转化模块将得到的调度文本指令转化为虚拟调度指令语音;
21.调度人员原始录音采样模块,进行调度人员原始录音采样,并将采样样本按照一定比例分为调度人员训练语音和调度人员测试语音;
22.调度人员声纹识别模型训练模块,将虚拟调度指令语音与调度人员训练语音进行混合,形成声纹识别模型的整体训练样本,对调度人员声纹识别模型进行训练;
23.配网调度员身份验证模块,利用调度人员测试语音样本对模型进行测试,输出调度人员身份认证结果,确定调度人员身份验证是否成功。
24.本发明的有益效果在于,与现有技术相比,本发明能够在调度人员语音样本较少的情况下生成调度人员虚拟指令语音,进而与真实原始指令语音一起实现对声纹模型的训练。虚拟指令语音根据调度指令关键词自动生成,且多个虚拟指令语音样本各自之间满足“主体意思一致、表达方式不同”的原则,与调度现场工况情景相同。
附图说明
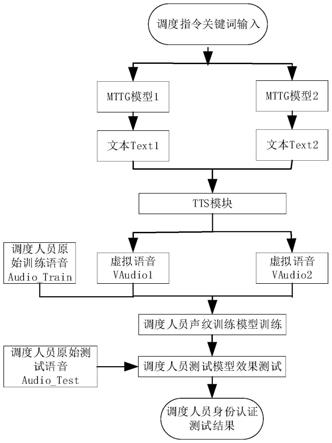
25.图1是基于改进synth2aug的配网调度员身份验证方法流程图;
26.图2是tacotron2模型结构图。
具体实施方式
27.下面结合附图和实施例对本发明的技术方案作进一步的说明。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本技术的保护范围。
28.现有synth2aug利用tts(text
‑
to
‑
speech)进行模型的训练,文本内容text和语音内容speech是完全一致的。在实际调度工作中,由于不同调度人员对同一调度操作的理解和表述习惯不同,造成调度语言的具体内容相差较大。
29.因此,本发明首先给出调度指令关键词作为调度人员的主要意图,然后利用mttg(meaning
‑
to
‑
text generation)生成调度文本,mttg分别采用lstm和gru两种模型生成两
种不同的调度文本内容(text1和text2),然后将两个调度文本通过tts技术生成相应的虚拟调度语音样本(vaudio1和vaudio2)。进而,将虚拟调度语言样本与来自于不同调度人员的原始调度语音进行混合,形成调度员声纹识别模型的训练样本。最后根据调度人员的测试样本对模型进行效果测试。
30.如图1所示,基于改进synth2aug的配网调度员身份验证方法如下:
31.(1)给定一组调度指令关键词(key word);
32.(2)根据给定的调度指令关键词,利用不同的mttg模型(mttg_1和mttg_2)形成不同的调度文本指令(text1和text2);
33.(3)利用文本语音转化模块(text
‑
to
‑
speech)将步骤(2)得到的调度文本指令转化为虚拟调度指令语音(vaudio1和vaudio2);
34.(4)将调度人员原始录音采样样本按照一定比例分为调度人员训练语音(audio train)和调度人员测试语音(audio test);
35.(5)将虚拟调度指令语音与调度人员训练语音进行混合,形成声纹识别模型的整体训练样本,对调度人员声纹识别模型进行训练;
36.(6)模型训练成功后,利用调度人员原始测试语音样本对模型进行测试;输出调度人员身份认证结果,确定调度人员身份验证是否成功。
37.以下举例说明,基于改进synth2aug的配网调度员身份验证方法,其具体步骤为:
38.(1)给定一组调度指令关键词(key word);
39.根据配电网运行情况,给出调度指令的关键词。例如,合,***线,**开关。
40.(2)根据给定的调度指令关键词,利用不同的mttg模型(mttg_1和mttg_2)形成不同的调度文本指令(text1和text2);
41.为了利用一组关键词产生不同的文本,使用不同mttg模型(mttg_1和mttg_2)在mttg_1模型中,使用双向长短时记忆网络(双向lstm)作为核心模块,生成文本时使用的“定语、状语、补语”等修饰成分较少。而在mttg_2模型中,使用门控循环单元(gru)作为核心模块,且生成的调度指令文本中使用了相应的“定语、状语、补语”等修饰成分。
42.根据给定的调度指令关键词“合,***线,**开关”,利用mttg_1模型生成调度文本指令text1为“合上***线路**开关”,而mttg_2模型生成的text2则为“请务必立刻合上***线路上的**开关”。
43.(3)利用文本语音转化模块(text
‑
to
‑
speech)将步骤(2)得到的调度文本指令转化为虚拟调度指令语音(vaudio1和vaudio2);
44.文本语音转化模块采用现有的tacotron2模型实现,如图2所示,将步骤(2)中生成的text_1和text_2分别作为模型的输入,输出调度人员虚拟调度指令语音vaudio1和vaudio2。
45.(4)将调度人员原始录音采样样本按照7:3比例分为调度人员训练语音(audio train)和调度人员测试语音(audio test);
46.(5)将虚拟调度指令语音与调度人员训练语音进行混合,形成声纹识别模型的整体训练样本,对调度人员声纹识别模型进行训练;
47.将虚拟调度指令语音与调度人员训练语音分别分成n个大小不等的子集(根据经验值可取n=10),即虚拟调度指令语音子集(vaudioi_k,k=1,2,..10)和原始调度人员训
练语音子集(audio_train_k,k=1,2,..10),分别从虚拟调度指令语音子集和原始调度人员训练语音子集取出k相等的子集进行混合,形成10个混合子集。最后将10个混合子集输入到声纹识别训练模型进行模型的训练。
48.(6)模型训练成功后,利用调度人员原始测试语音样本对模型进行测试;输出调度人员身份认证结果,确定调度人员身份验证是否成功。
49.本发明还提供一种基于改进synth2aug的配网调度员身份验证系统,包括:调度文本指令生成模块、文本语音转化模块、调度人员原始录音采样模块、调度人员声纹识别模型训练模块、配网调度员身份验证模块。
50.调度文本指令生成模块,根据给定的调度指令关键词,利用不同的mttg模型形成不同的调度文本指令。
51.文本语音转化模块,利用文本语音转化模块将得到的调度文本指令转化为虚拟调度指令语音。
52.调度人员原始录音采样模块,进行调度人员原始录音采样,并将采样样本按照一定比例分为调度人员训练语音和调度人员测试语音。
53.调度人员声纹识别模型训练模块,将虚拟调度指令语音与调度人员训练语音进行混合,形成声纹识别模型的整体训练样本,对调度人员声纹识别模型进行训练。
54.配网调度员身份验证模块,利用调度人员测试语音样本对模型进行测试,输出调度人员身份认证结果,确定调度人员身份验证是否成功。
55.本发明的有益效果在于,与现有技术相比,本发明能够在调度人员语音样本较少的情况下生成调度人员虚拟指令语音,进而与真实原始指令语音一起实现对声纹模型的训练。虚拟指令语音根据调度指令关键词自动生成,且多个虚拟指令语音样本各自之间满足“主体意思一致、表达方式不同”的原则,与调度现场工况情景相同。
56.本发明申请人结合说明书附图对本发明的实施示例做了详细的说明与描述,但是本领域技术人员应该理解,以上实施示例仅为本发明的优选实施方案,详尽的说明只是为了帮助读者更好地理解本发明精神,而并非对本发明保护范围的限制,相反,任何基于本发明的发明精神所作的任何改进或修饰都应当落在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

