本发明属于语音识别技术领域,具体涉及一种超短语音语种识别方法。
背景技术:
伴随着模式识别、深度学习等技术的发展,人机信息交互也逐渐进化,从传统的指令交互到自然语言交互,语音识别作为人机交互领域的关键技术受到了极大的重视并体现出较大的实用价值。按照形式可将语音划分为与字词信息相关、与语段内容相关的语音识别系统、与语段中所蕴含说话人身份相关的说话人识别系统及与语段所属语言种类相关的语种识别系统。
语种识别系统作为其他语音识别系统的前端处理,需要更快的响应速度和识别精度。目前,语种识别领域中时长大于10s的长语段的识别准确率已经足够好,但是当语音段时长下降,语种识别性能明显下降,提高响应速度对语种识别技术提出了更高的要求。
传统的基于统计模型的全差异空间分析i-vector方法和基于音素语言模型的prlm方法在短语音识别中无法满足识别性能的要求,基于神经网络模型发展起来的端到端方案在当前语音识别领域获得了广泛的关注,有着极好的发展前景,随着深度学习技术的发展,使用深度学习进行语种识别的方案不断涌现包括使用长短时记忆神经网络(longshorttimememorynet,lstm)、时延神经网络(timedelaynet,tdnn)等作为模型主体进行语种识别,或者使用可解释网络进行声纹识别的sincnet网络等。
技术实现要素:
为解决上述问题,本发明提供了一种超短语音语种识别方法,所述方法包括步骤:
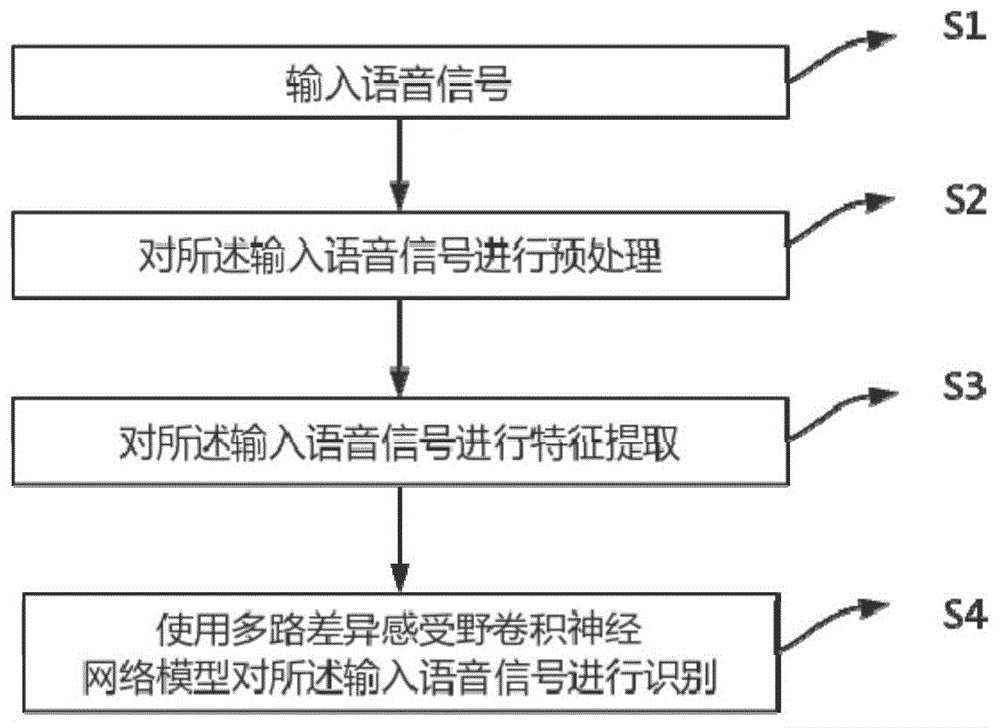
输入语音信号;
对所述输入语音信号进行预处理;
对所述输入语音信号进行特征提取;
使用多路差异感受野卷积神经网络模型对所述输入语音信号进行识别。
优选地,所述所述对所述输入语音信号进行预处理包括步骤:
对所述输入语音信号进行降噪处理;
基于信噪比snr对所述输入语音信号进行静音检测处理;
将所述输入语音信号分割为预设长度的有效语音。
优选地,所述基于信噪比snr对所述输入语音信号进行静音检测处理包括步骤:
获取降噪处理后的所述输入语音信号;
去除所述输入语音信号中的非语音段;
保留所述输入语音信号中的有效语音段。
优选地,所述将所述输入语音信号分割为预设长度的有效语音包括步骤:
获取静音检测处理后的有效语音段;
将所述有效语音段分割为预设长度的多段有效语音;
对每段所述有效语音进行单独语种识别;
将多段所述有效语音语种识别结果进行得分融合;
判断得分是否达到预设置信度阈值;
若是,获取所有所述有效语音;
若否,返回所述对每段所述有效语音进行单独语种识别步骤。
优选地,所述对所述输入语音信号进行特征提取包括步骤:
获取特征模型;
获取特征和输入维度;
获取序列长度;
根据所述输入维度和所述序列长度将所述特征输入所述特征模型中;
获取所述特征模型的输出。
优选地,所述使用多路差异感受野卷积神经网络模型对所述输入语音信号进行识别包括步骤:
获取残差时延神经网络模型和八度一维卷积神经网络层;
将所述残差时延神经网络模型作为主要结构单元;
将所述八度一维卷积神经网络层作为辅助结构单元;
对输入特征维度进行变换;
将d-vector经过2层全连接层进行维度变换;
得到各个语种对应的概率打分。
本发明提出一种超短语音语种识别方法,提供更高的响应速度以及在短语音上的识别精度,本发明使用多路时延神经网络作为主要结构,每路卷积神经网络使用不同的卷积核心,提供不同的感受野抽取特征,在深度特征上进行融合,本发明提升了模型识别精度,减小了模型参数,可应用与1s的超短语音,可快速响应。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明提供的一种超短语音语种识别方法的流程示意图;
图2是本发明中音频预处理切分方法流程示意图
图3是本发明中residualtdnn模块示意图;
图4是本发明中图像信号的高低频信号分量示意图;
图5是本发明中octaveconv1d模块计算示意图;
图6是本发明中深度网络模型整体结构图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
如图1-6,在本申请实施例中,本发明提供了一种超短语音语种识别方法,所述方法包括步骤:
s1:输入语音信号;
s2:对所述输入语音信号进行预处理;
在本申请实施例中,所述所述对所述输入语音信号进行预处理包括步骤:
对所述输入语音信号进行降噪处理;
基于信噪比snr对所述输入语音信号进行静音检测处理;
将所述输入语音信号分割为预设长度的有效语音。
在本申请实施例中,当对所述输入语音信号进行预处理时,具体地,首先对所述输入语音信号进行降噪处理,并基于信噪比snr对所述输入语音信号进行静音检测处理,然后将所述输入语音信号分割为预设长度的有效语音。
在本申请实施例中,所述基于信噪比snr对所述输入语音信号进行静音检测处理包括步骤:
获取降噪处理后的所述输入语音信号;
去除所述输入语音信号中的非语音段;
保留所述输入语音信号中的有效语音段。
在本申请实施例中,所述将所述输入语音信号分割为预设长度的有效语音包括步骤:
获取静音检测处理后的有效语音段;
将所述有效语音段分割为预设长度的多段有效语音;
对每段所述有效语音进行单独语种识别;
将多段所述有效语音语种识别结果进行得分融合;
判断得分是否达到预设置信度阈值;
若是,获取所有所述有效语音;
若否,返回所述对每段所述有效语音进行单独语种识别步骤。
s3:对所述输入语音信号进行特征提取;
在本申请实施例中,所述对所述输入语音信号进行特征提取包括步骤:
获取特征模型;
获取特征和输入维度;
获取序列长度;
根据所述输入维度和所述序列长度将所述特征输入所述特征模型中;
获取所述特征模型的输出。
在本申请实施例中,当对语音段进行特征提取时,可以使用短时频域特征mfcc(梅尔谱系数特征)、filterbank(滤波器组特征)、fft(频率谱特征)特征,基于深度学习的dbf(深度瓶颈层特征)、pllr(因素对数似然比特征)等特征,可解释的sincnet神经网络特征,长时包络信号特征fdlp(频域线性预测系数)等。得到输入到模型中特征feat,输入维度ffeat和具体特征相关,序列长度为ntime。
s4:使用多路差异感受野卷积神经网络模型对所述输入语音信号进行识别。
在本申请实施例中,所述使用多路差异感受野卷积神经网络模型对所述输入语音信号进行识别包括步骤:
获取残差时延神经网络模型和八度一维卷积神经网络层;
将所述残差时延神经网络模型作为主要结构单元;
将所述八度一维卷积神经网络层作为辅助结构单元;
对输入特征维度进行变换;
将d-vector经过2层全连接层进行维度变换;
得到各个语种对应的概率打分。
在本申请实施例中,使用多路差异感受野卷积神经网络模型对所述输入语音信号进行识别具体包括如下步骤:
选用残差时延神经网络模型(residualtimedelayneuralnetwork,residualtdnn)作为主要结构单元:
具体步骤为:输入为序列特征x,用tdnn prelu tdnn形式的模块对x进行变换,得到新序列特征xresidual;将x和xresidual相加,再经过一次prelu,得到新特征序列xnew;
选用八度1维卷积神经网络层octaveconv1d作为辅助结构单元;
具体步骤为:输入序列特征x_h(高频特征分量)维度为f_h,x_l(低频特征分量,若不存在为空)维度为f_l,(f_h==2*f_l);使用avgpool(在序列维度上下采样1/2),降低序列特征x_h的数据频率,然后使用一层tdnn(high2low),将x_h变换为x_h2l(高频到低频变换特征),特征维度不变,序列维度变为1/2f_l;使用一层tdnn(high2high),对x_h进行变换得到x_h2h(高频到高频变换特征),特征维度不变,序列维度不变f_h;使用一层tdnn(low2high),对x_l进行变换,然后经过插值上采样变换提升频率得到x_l2h(低频到低频高换特征),特征维度不变,序列维度变为2倍f_h;使用一层tdnn(low2low),对x_l进行变换得到x_l2l(低频到低频变换特征),特征维度不变,序列维度不变f_l;如果输入不存在低频分量特征:
x_h_new=x_h2h,x_l_new=x_h2l。
否则:
x_h_new=x_h2h x_l2h,x_l_new=x_l2l x_h2l。
得到新的高低频特征分量x_h_new,x_l_new。
输入特征维度变换,输入特征feat根据所选用特征不同,得到的特征维度也不相同,使用一层tdnn网络将维度ffeat变换为固定维度finput,得到浅层特征feat0。
将d-vector经过2层全连接层进行维度变换,变换为目标语种个数classcnt,经过softmax层,得到属于各个语种的概率打分p。
在本申请实施例中,多路差异感受野卷积神经网络包括:第一路小感受野卷积路径,使用residualtdnn作为基本单元,堆叠nsmall(10-60)次,选用序列维度上卷积宽度为3,将输入浅层特征feat0变换为深度特征featsmall,维度保持不变finput;第二路大感受野卷积路径,使用residualtdnn作为基本单元,堆叠nbig(nsmall的一般)次,选用序列维度上卷积宽度为9,将输入浅层特征feat0变换为深度特征featbig,维度保持不变finput;第三路八度融合感受野卷积路径,使用octaveconv1d作为基本单元,堆叠nbig次,选用序列维度上卷积宽度为5,将输入浅层特征feat0变换为深度特征featoctave,维度保持不变finput。
在本申请实施例中,多路深度特征融合具体步骤为:将三路不同感受野得到的深度特征进行特征维度上的拼接,得到序列长度不变ntime,特征维度为finput*3;经过一层tdnn,将特征维度变换为ffusion(512-2048);经过multiheadattention,head=8,hidden_size=64,得到便函后特征featatt输出维度为fatt;提取向向量表示,对featatt在序列维度上进行均值和方差向量提取,然后拼接,得到d-vector,维度为fd(2xfatt)。
本发明提出一种超短语音语种识别方法,提供更高的响应速度以及在短语音上的识别精度,本发明使用多路时延神经网络作为主要结构,每路卷积神经网络使用不同的卷积核心,提供不同的感受野抽取特征,在深度特征上进行融合,本发明提升了模型识别精度,减小了模型参数,可应用与1s的超短语音,可快速响应。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

