本发明属于音频处理的技术领域,特别涉及一种基于定向降噪与干声提取技术的语音优化方法。
背景技术:
在音频处理过程中,主要有定向降噪和干声提取两种方式。
目前,定向降噪对音频降噪算法的研究主要集中在非压缩域音频的处理,主要的降噪方法有:谱减法、维纳滤波法和门限阈值法。经典的谱减法在假定噪声和信号相互独立的条件下,从含有噪声的信号谱中减去噪声谱,从而实现降噪。谱减法相对简单,但噪声和信号相互独立的假设并不完全相符,这使得采用谱减法降噪处理后的音频中残留有很大的音乐噪声;基于音频时频块的自适应阈值降噪算法在噪声方差已知的条件下,通过最小stein风险估计法自适应地调整时频块的参数,对各种类型的音频都具有良好的降噪效果。
干声提取方法中,也有两种:
(1)基于计算听觉场景分析(casa)的人声分离算法根据每个说话人语音的基音、音色等特征的不同,利用聚类与dnn的方法分离人声。然而,dnn训练得到的人声分离模型常常存在排列问题,即当一段混合语音中包含两个或多个说话人时,dnn输出分离语音的顺序是未知的,导致模型在训练时无法利用目标语音与对应的分离语音间的误差来提升分离效果。
(2)hershey等提出深度聚类(dc)算法,算法将混合语音的时频幅度谱映射到一个嵌入空间中,使同一声源的时频点间的相似度最小、不同声源的时频点间的相似度最大,从而避免了排列问题带来的影响。luo,chen等根据dc算法改进的深度吸引子网络(danet)在嵌入空间中计算得到吸引子,利用各吸引子与其同源的时频点间的相似度变高这一特性来计算分离掩蔽,同时在训练时利用了目标语音与其分离语音的误差来提升网络性能。
然而,定向降噪算法需要从含有噪声的音频信号中估计出噪声方差,噪声方差估计的准确度直接影响了降噪后音频的质量。干声提取所需要的数据量较大,总而言之目前的一些音频降噪算法效果都不是十分理想。
技术实现要素:
为解决上述问题,本发明的首要目的在于提供一种基于定向降噪与干声提取技术的语音优化方法,该方法分别使用ssd和hsd方法处理带噪语音和去噪语音信号在不同噪声类型下的平均pesq(perceptualevaluationofspeechquality客观语音质量评估)和stoi(short-timeobjectiveintelligibility可短时客观可懂)。
本发明的另一目的在于提供一种基于定向降噪与干声提取技术的语音优化方法,该方法使用log-mel图谱系数(mfsc)省略离散余弦变换(dct)压缩;使用能量对书谱作为输入和输出的方法和masking-based方法估计一个语音信号进行去噪,去噪效果好。
为实现上述目的,本发明的技术方案如下。
一种基于音频场景识别的的定向降噪方法,包括以下步骤:
s1、建立声音库;
s2、定义使用的环境;
s3、构建深度语音去噪自监督语音增强全卷积神经网络;
s4、进行声音增强。
其中,s1、建立声音库步骤中,
采用timit语料库,语料库中的音频文件由若干个讲话者(其中,男女各一半)组成的复数个语音音频文件组成,每个音频文件长度约为15s。
上述音频文件为干净语音信号,将干净语音信号通过urbansound8k数据集的噪声信号破坏。
所述数据集由各种噪声文件组成,每个噪声文件持续20s。其中的噪音信号被分为餐厅噪音、风声、发动机声和车流声。带噪的语音文件以48khz采样,归一化到绝对单位最大值。
s2步骤中,将不同的噪声信号分别对应定义到餐厅、室外、马路场景中。
s3步骤中,构建深度语音去噪自监督语音增强全卷积神经网络。
本方法建立在监督训练去噪方法的基础上。基于可用的纯净语音信号的公共领域数据集初始化深度神经网络。在只有噪音语音数据的条件下,对神经网络进行纯净物参考训练。进一步包括有:
(1)模型的输入信号
一个语音 噪声混合或含噪语音信号y(t)表示为y(t)=x(t) n(t)。
其中x(t)和n(t)分别表示纯净语音信号和附加噪声信号。假设纯净语音信号和噪声信号不相关。
网络参数和连接权值表示为θ。
将y(t)和θ作为模型的两个输入。
(2)模型的训练
语音去噪网络的训练基于帧的方式进行,通过将噪声语音信号分割成20ms帧,相邻帧之间有50%的重叠,利用深度神经网络提取去噪后的语音信号
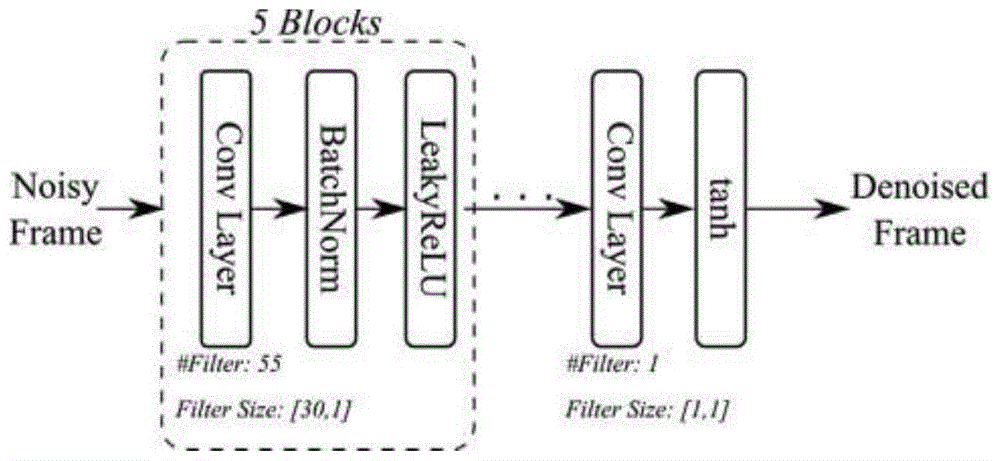
所使用的神经网络体系结构是一个完全卷积神经网络(fcnn),忽略完全连接的图层。使用一维卷积对时间序列数据的时间属性进行建模。体系使用6个卷积层,55个大小为(30,1)的滤波器分布在第一到第五卷积层,使用1个大小为(1,1)的滤波器在最后一个卷积层,使用双曲正切激活函数。
s4步骤中,声音增强,是指利用深度吸引子与其同源的时频点间的相似度变高这一特性来计算分离掩蔽,在失真度最小的条件下,增强提取得到的纯净语音信号。
本发明的有益效果在于:
1、本发明基于四种常用的性能指标(pesq、stoi、lsd、ssnr四种性能指标)和主观测试结果,去噪效果明显优于传统的有监督深度语音去噪方法。
2、能够针对餐厅、室外、马路等不同的场景进行降噪,大大提升了降噪的效果。
3、能够根据语音分辨不同的说话人,避免同时有多个说话人时将人声作为噪声进行降噪,可以将噪音与语音进行准确区分,识别效果好。
附图说明
图1是本发明所实现的fcnn的架构图。
图2是本发明所实现深度吸引子网络结构的示意图。
图3是本发明所实现深度吸引子网络核心流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明所实现基于音频场景识别的的定向降噪方法,包括以下步骤:
s1、建立声音库;
s2、定义使用的环境;
s3、构建深度语音去噪自监督语音增强全卷积神经网络;
s4、进行声音增强。
其中s1、建立声音库步骤中,
采用timit语料库,由20个讲话者(男女各10个)组成的3600个语音音频文件组成,每个音频文件长度约为15s。演讲者来自中国不同省份,阅读中学课文,以满足不同口音的需要。
上述干净语音信号由urbansound8k数据集的噪声信号破坏,该数据集由各种噪声文件组成,每个噪声文件持续20s。
其中的噪音信号被分为餐厅噪音、风声、发动机声和车流声。带噪的语音文件以48khz采样,归一化到绝对单位最大值。
所述噪声文件通过离散余弦变换(dct)进行压缩。dct是一种空间变换,dct变换的最大特点是对于一般的图像都能够将像块的能量集中于少数低频dct系数上,这样就可能只编码和传输少数系数而不严重影响图像质量。dct不能直接对图像产生压缩作用,但对图像的能量具有很好的集中效果,为压缩打下了基础。例如:一帧图像内容以不同的亮度和色度像素分布体现出来,而这些像素的分布依图像内容而变,毫无规律可言。但是通过离散余弦变换(dct),像素分布就有了规律。代表低频成份的量分布于左上角,而越高频率成份越向右下角分布。然后根据人眼视觉特性,去掉一些不影响图像基本内容的细节(高频分量),从而达到压缩码率的目的。
离散余弦变换(dct)是对实信号定义的一种变换,变换后在频域中得到的也是一个实信号,相比dft而言,dct可以减少一半以上的计算。dct还有一个很重要的性质(能量集中特性):大多书自然信号(声音、图像)的能量都集中在离散余弦变换后的低频部分,因而dct在(声音、图像)数据压缩中得到了广泛的使用。由于dct是从dft推导出来的另一种变换,因此许多dft的属性在dct中仍然是保留下来的。
推导n点长实序列的dct,首先来定义一个新的长度为2n的序列:
这个序列可看作是将周期为n的序列x[m]做一个周期延拓成一个周期为2n的序列。
它是关于x=-1/2对称的,要让他关于x=0对称需要将其向右平移1/2个单位,得到x’[m]=x’[m-1/2]就是关于x=0对称的周期序列了。
然后求这个2n序列的dft:
令m’∨=m 1/2代入上式做变量代换:
就是dct-2型离散余弦变换。从上面的过程也可以直接看出,离散余弦变换相当于一个长度大概是它两倍的离散傅里叶变换。
变换后的x[n]是以2n为周期,偶对称的序列:x[n n]=x[n n-2n]=x[n-n]=x[n-n]
定义变换矩阵c[n,m]:
定义变换矩阵c[n,m]:
为了使其正交化,引入系数a[n]
得到正交dct:
对于正交余弦变换矩阵就有
c-1=ct或ctc=i
s2步骤中,将不同的噪声信号分别对应定义到餐厅、室外、马路场景中,场景可以由使用者自行定义,而不必局限于上述场景。
s3步骤中,构建深度语音去噪自监督语音增强全卷积神经网络。
本方法建立在监督训练去噪方法的基础上,基于可用的纯净语音信号的公共领域数据集初始化深度神经网络。全卷积神经网络可以在只有噪音语音数据的条件下,对神经网络进行纯净物参考训练。,具体包括有:
(1)模型的输入信号
全卷积神经网络首先需要建立语音模型,语音模型通常包括一个语音 噪声混合或含噪语音信号,y(t)表示为y(t)=x(t) n(t)。
其中,y(t)表示一个语音 噪声混合语音信号或含噪语音信号,x(t)和n(t)分别表示纯净语音信号和附加噪声信号。假设纯净语音信号和噪声信号不相关。
网络参数和连接权值表示为θ。
将y(t)和θ作为模型的两个输入。
(2)模型的训练
语音去噪网络的训练基于帧的方式进行,通过将噪声语音信号分割成20ms帧,相邻帧之间有50%的重叠,利用深度神经网络提取去噪后的语音信号
如图1所示,所使用的神经网络体系结构是一个完全卷积神经网络(fcnn),忽略完全连接的图层。使用一维卷积对时间序列数据的时间属性进行建模。体系使用6个卷积层,55个大小为(30,1)的滤波器分布在第一到第五卷积层,使用1个大小为(1,1)的滤波器在最后一个卷积层,使用双曲正切激活函数。
s4.声音增强。
利用深度吸引子与其同源的时频点间的相似度变高这一特性来计算分离掩蔽,在失真度最小的条件下,增强提取得到的纯净语音信号。
其中深度吸引子的算法,如图2、图3所示。
应用一:基于单麦克风语音分离的深度吸引子网络。
核心工作:提出了在高维空间中嵌入吸引子(attractor)将时频信息整合来训练的网络,模型实现了端到端的训练,分离不需要知道混合源的数量。
应用二:用于独立声源语音分离。
核心工作:在原danet基础上提出第三种寻找声源嵌入空间中的吸引子方法,并进行训练、测试阶段的实现。
声源分离方法。步骤:
1.在每个t-f块生成一个高维嵌入空间(与dpcl相似);
2.在嵌入空间中形成吸引子,将属于该声源的tf块拉向自身,造成空间中的声源分离开来;
3.利用每个嵌入空间和吸引子的相似性来估计混合语音中每个声源的mask(dpcl使用亲和矩阵来衡量和嵌入空间的相似性);
4.由于掩模的顺序与吸引子直接相关,因此在吸引子确定之后掩模顺序也可以确定下来;
5.设定一组锚点(所述锚点是用于定位的标记点),便可以不通过后聚类直接估计声源掩码。
总之,本发明本发明基于四种常用的性能指标(pesq、stoi、lsd、ssnr四种性能指标)和主观测试结果,去噪效果明显优于传统的有监督深度语音去噪方法。
本发明能够针结合具体应用,对餐厅、室外、马路等不同的场景进行降噪,大大提升了降噪的效果。
本发明能够根据语音分辨不同的说话人,避免同时有多个说话人时将人声作为噪声进行降噪,可以将噪音与语音进行准确区分,识别效果好。
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

