本发明涉及语音识别技术领域,尤其是一种基于自适应滤波的语音识别装置、方法、设备及介质。
背景技术:
lms(leastmeansquare)算法的原理为:通过当前时刻滤波器的输出误差,输出信号和滤波器权系数来估算下一时刻可滤波器权系数,最终达到期望输出信号和实际输出信号之间的均方误差最小。rls(recursiveleastsquare)可以进行实时在线估计参数,是一个线性递推估计器,使当前参数的协方差最小化。dentino等1979年首先提出了变换域自适应滤波的概念,其基本思想是把时域信号转变为变换域信号,在变换域中采用自适应算法。
对于强相关的信号,lms算法的收敛性能降低,这是由于lms算法的收敛性能依赖于输入信号自相关矩阵的特征值发散程度,输入信号自相关矩阵的特征值发散程度越小,lms算法的收敛性能越好;rls算法对输入信号的自相关矩阵的逆进行递推估计更新,收敛速度快。lms算法和rls算法对于统计独立的高斯白噪声具有较好的滤波作用,而变换域自适应滤波对于色噪声滤波方面,滤波效果更好。由于环境的复杂多变性,噪声并不是一成不变的,需要基于环境的改变选择更合适的滤波方法。
技术实现要素:
针对现有技术中的缺陷,本发明提供了一种基于自适应滤波的语音识别装置、方法、设备及介质,提高了语音识别的准确度。
第一方面
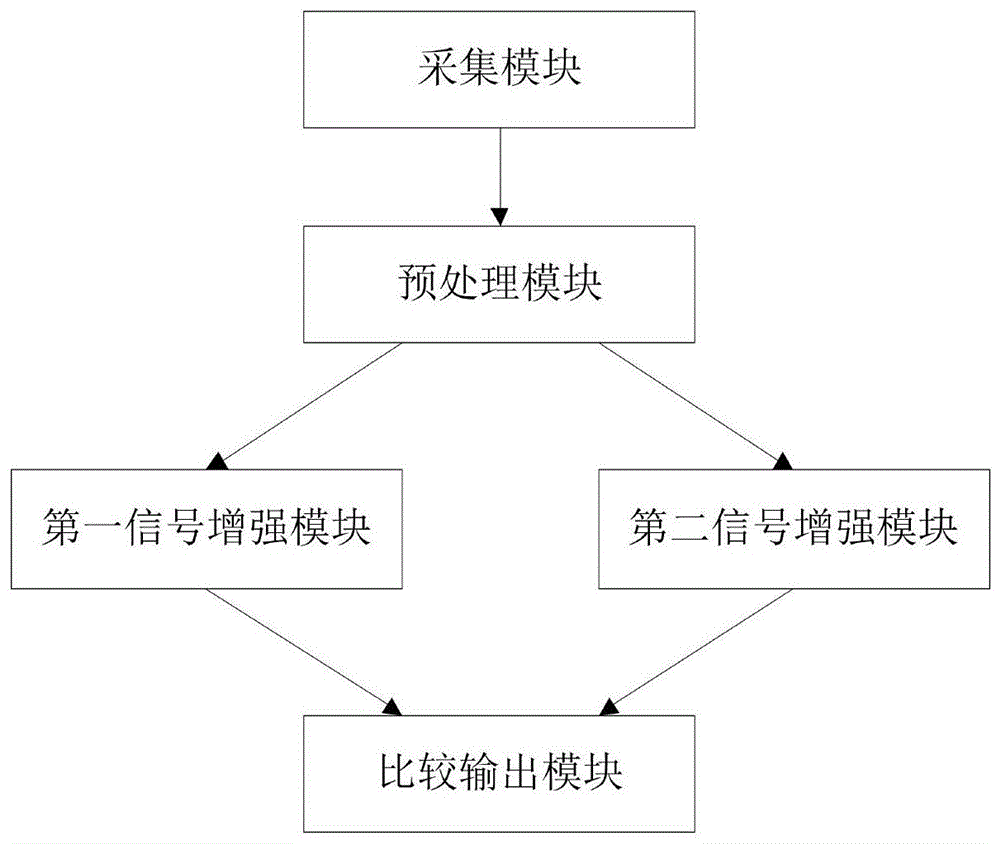
一种基于自适应滤波的语音识别装置,包括:
优选地,采集模块,用于采集说话人的语音信息;
预处理模块,用于对语音信息进行模数转换并产生语音信号;
第一信号增强模块,用于对语音信号按照基于白噪声的自适应滤波算法进行滤波、降噪并输出第一增强信号及第一增强信号对应的第一信噪比;
第二信号增强模块,用于对语音信号按照基于色噪声的自适应滤波算法进行滤波、降噪并输出第二增强信号及第二增强信号对应的第二信噪比;
比较输出模块,用于比较第一信噪比和第二信噪比并输出比较结果;
所述比较第一信噪比和第二信噪比并输出比较结果具体包括:
比较第一信噪比的值是否大于第二信噪比的值,若是,输出第一信噪比及第一增强信号;若否,输出第二信噪比及第二增强信号。
优选地,所述基于白噪声的自适应滤波算法包括以下步骤:
s1、构建目标函数
s2、构造均衡器的权向量系数的递推公式:
w(i)=w(i-1) ηφ(i)[d(i)-φ(i)tw(i-1)]
其中,w(i)为权向量系数,η为步长,
s3、根据rkhs理论,在权向量张成的空间做投影,权向量在特征空间展开可得:
其中,aj(i)为所述投影的系数;
s4、根据mercer核定义进行向量点积,得到均衡器的输出公式:
y(i;k)为滤波器的输出值;
s5、对均衡器进行初始化,按照步骤s2、s3和步骤s4不断进行迭代和更新,直至处理完毕。
优选地,基于色噪声的自适应滤波算法包括变换域自适应滤波算法。
优选地,所述预处理模块包括模数转换芯片,模数转换芯片采用ad9125双通道16位带宽芯片。
优选地,还包括主控模块和通讯模块,主控模块用于接收比较输出模块发送的比较结果,并将比较结果通过通讯模块上传至上位机。
优选地,所述采集模块包括多个等间距排列的麦克风组成的阵列。
第二方面
一种基于自适应滤波的语音识别方法,包括以下步骤:
采集说话人的语音信息;
对语音信息进行模数转换并产生语音信号;
对语音信号按照基于白噪声的自适应滤波算法进行滤波、降噪并输出第一增强信号及第一增强信号对应的第一信噪比;
对语音信号按照基于色噪声的自适应滤波算法进行滤波、降噪并输出第二增强信号及第二增强信号对应的第二信噪比;
比较第一信噪比的值是否大于第二信噪比的值,若是,输出第一信噪比及第一增强信号;若否,输出第二信噪比及第二增强信号。
优选地,所述基于白噪声的自适应滤波算法包括以下步骤:
s1、构建目标函数
s2、构造均衡器的权向量系数的递推公式:
w(i)=w(i-1) ηφ(i)[d(i)-φ(i)tw(i-1)]
其中,w(i)为权向量系数,η为步长,
s3、根据rkhs理论,在权向量张成的空间做投影,权向量在特征空间展开可得:
其中,aj(i)为所述投影的系数;
s4、根据mercer核定义进行向量点积,得到均衡器的输出公式:
y(i;k)为滤波器的输出值;
s5、对均衡器进行初始化,按照步骤s2、s3和步骤s4不断进行迭代和更新,直至处理完毕。
第三方面
一种基于自适应滤波的语音识别设备,包括存储器和处理器;所述存储器用于存储可执行程序代码;
所述处理器用于读取所述存储器中存储的可执行程序代码,以执行第二方面所述的一种基于自适应滤波的语音识别方法。
第四方面
一种介质,所述存储介质存储有权利要求7中所述的可执行程序代码。
本发明提供的了一种基于自适应滤波的语音识别装置、方法、设备及介质,考虑了白噪声和色噪声两种噪声的影响,针对性地采用基于白噪声的自适应滤波算法和基于色噪声的自适应滤波算法,输出较高信噪比对应的增强信号,提高了语音识别的准确度。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
图1为本发明实施例的一种基于自适应滤波的语音识别装置的结构示意图;
图2为本发明实施例的一种基于自适应滤波的语音识别方法的流程示意图;
图3为本发明实施例的一种基于自适应滤波的语音识别设备的硬件架构图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。
需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
如图1所示,本发明实施例提供了一种基于自适应滤波的语音识别装置,采集模块,用于采集说话人的语音信息;预处理模块,用于对语音信息进行模数转换并产生语音信号;第一信号增强模块,用于对语音信号按照基于白噪声的自适应滤波算法进行滤波、降噪并输出第一增强信号及第一增强信号对应的第一信噪比;第二信号增强模块,用于对语音信号按照基于色噪声的自适应滤波算法进行滤波、降噪并输出第二增强信号及第二增强信号对应的第二信噪比;比较输出模块,用于比较第一信噪比和第二信噪比并输出比较结果。其中,比较第一信噪比和第二信噪比并输出比较结果具体包括:比较第一信噪比的值是否大于第二信噪比的值,若是,输出第一信噪比及第一信噪比对应的第一增强信号;若否,输出第二信噪比及第二信噪比对应的第二增强信号。
本发明实施例中基于白噪声的自适应滤波算法包括以下步骤:
s1、构建目标函数
s2、构造均衡器的权向量系数的递推公式:
w(i)=w(i-1) ηφ(i)[d(i)-φ(i)tw(i-1)]
其中,w(i)为权向量系数,η为步长,
s3、根据rkhs理论,在权向量张成的空间做投影,权向量在特征空间展开可得:
其中,aj(i)为投影的系数;
s4、根据mercer核定义进行向量点积,得到均衡器的输出公式:
y(i;k)为滤波器的输出值;
s5、对均衡器进行初始化,按照步骤s2、s3和步骤s4不断进行迭代和更新,直至处理完毕。
根据实际需要,本发明实施例基于白噪声的自适应滤波算法还可采用lms滤波算法或rls滤波算法。lms滤波算法实现的步骤如下:
1)初始化,设定滤波器w(k)的初始值:
2)估计滤波器输出值:
y(n)=wt(n)x(n)
3)计算估计误差:
e(n)=d(n)-y(n)
4)权值更新:
固步长lms:w(n 1)=w(n) 2μe(n)x(n)
归一化lms:
rls算法的流程为:
1)初始化估计器:
x0=e[x]
p0=e[(x-x0)(x-x0)t]
2)建立观测模型,定义雅克比和测量协方差矩阵:
yk=hkx vk
3)更新对xk的估计和协方差pk:
xk=xk-1 kk(yk-hkxk-1)
pk=(1-kkhk)pk-1
变换域自适应滤波算法的原理为:变换矩阵n*n的t矩阵,常用的正交变换有离散余弦变换(dct)、离散傅立叶变换(dtft)、离散hartly变换及沃尔什-哈达玛(walsh—hadamard)变换等。变换后的信号为:
x'=t*x
变换域的递推公式为:
w(n 1)=w(n) 2μe(n)p-1(n)x(n)
p(n)=diag[p(n,0),p(n,1),…,p(n,n-1)]
p(n,l)=βp(n-1,l) (1-β)xt(n,l)·x(n,l),l=0,1…n-1
若令λ2=p(n),则权系数向量的迭代方程为:
w(n 1)=w(n) 2μe(n)λ-2x(n)
本发明实施例中,基于色噪声的自适应滤波算法包括变换域自适应滤波算法。
预处理模块包括模数转换芯片,模数转换芯片采用ad9125双通道16位带宽芯片。ad9125是一款双通道、16位、高动态范围txdac数模转换器(dac),提供1000msps采样速率,可以产生最高达奈奎斯特频率的多载波。它具有针对直接变频传输应用进行优化的特性,包括复合数字调制以及增益与失调补偿。dac输出经过优化,可以与模拟正交调制器无缝接口,例如adi公司的adl537xf-mod系列调制器。4线式串行端口接口允许对许多内部参数进行编程和回读。满量程输出电流可以在8.7ma至31.7ma范围内进行编程。
本实施例实现的一种基于自适应滤波的语音识别装置还包括主控模块、通讯模块和定位模块,主控模块用于接收比较输出模块发送的比较结果,并将比较结果通过通讯模块上传至上位机;定位模块用于定位位置信息并发送至主控模块,主控模块将位置信息通过通讯模块上传至上位机。
本实施例中,采集模块包括多个麦克风,麦克风等间距排列成线阵或者方阵。
本发明实施例还提供了一种基于自适应滤波的语音识别方法,如图2所示,包括以下步骤:
s1、采集说话人的语音信息;
s2、对语音信息进行模数转换并产生语音信号;
s3、对语音信号按照基于白噪声的自适应滤波算法进行滤波、降噪并输出第一增强信号及第一增强信号对应的第一信噪比;对语音信号按照基于色噪声的自适应滤波算法进行滤波、降噪并输出第二增强信号及第二增强信号对应的第二信噪比;
s4、比较第一信噪比的值是否大于第二信噪比的值,若是,输出第一信噪比及第一信噪比对应的第一增强信号;若否,输出第二信噪比及第二信噪比对应的第二增强信号。
基于白噪声的自适应滤波算法包括以下步骤:
s1、构建目标函数
s2、构造均衡器的权向量系数的递推公式:
w(i)=w(i-1) ηφ(i)[d(i)-φ(i)tw(i-1)]
其中,w(i)为权向量系数,η为步长,
s3、根据rkhs理论,在权向量张成的空间做投影,权向量在特征空间展开可得:
其中,aj(i)为投影的系数;
s4、根据mercer核定义进行向量点积,得到均衡器的输出公式:
y(i;k)为滤波器的输出值;
s5、对均衡器进行初始化,按照步骤s2、s3和步骤s4不断进行迭代和更新,直至处理完毕。
本发明实施例中,基于色噪声的自适应滤波算法包括变换域自适应滤波算法。
图3为硬件架构的结构图,如图3所示,一种自适应滤波的语音识别设备包括输入设备、输入接口、中央处理器、存储器、输出接口和输出设备。其中,输入接口、中央处理器、存储器及输出接口通过总线相互连接,输入设备和输出设备分别通过输入接口和输出接口与总线连接,进而与设备的其他组件连接。具体地,输入设备接收来自外部的输入信息,并通过输入接口将输入信息传送到中央处理器。中央处理器基于存储器存储的计算机可执行程序代码对输入信息进行处理以生成输出信息,将输出信息临时或者永久地存储在存储器中,然后通过输出接口将输出信息传送到输出设备,输出设备将输出信息输出到设备的外部供用户使用。
本发明实施例还提供了一种计算机存储介质,该计算机存储介质上存储有可执行程序代码,该可执行程序代码被处理器执行时实现上述一种基于自适应滤波的语音识别方法。本实施例中,存储介质可以是计算机能够读取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。其中,可用介质可以是磁性介质(如软盘、硬盘、磁带)、光介质(如dvd)、或者半导体介质(如固态硬盘ssd)等。本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以是两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
本发明实施例提供的一种基于自适应滤波的语音识别装置、方法、设备及介质,说话人语音信息经采集和预处理后,分别采用基于白噪声的自适应滤波算法和基于色噪声的自适应滤波算法进行滤波、去噪,比较并选择较大信噪比对应的增强信号作为最终的输出信号。本实施例考虑了白噪声和色噪声两种噪声的影响,针对性地采用基于白噪声的自适应滤波算法和基于色噪声的自适应滤波算法,输出较高信噪比对应的增强信号,提高了语音识别的准确度。本实施例中,还可通过通讯模块将比较结果及位置信息发送至上位机,方便远程监控。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

