本发明属于人工智能领域,具体涉及一种融合词汇及音素发音特征的情感语音合成方法及系统。
背景技术:
语言交互是人类最早的交流方式之一,因此语音成为了人类表达情感的主要方式。随着人机交互的兴起,让对话机器人拥有类似人的情感,说话听起来像真人,成为一种迫切的需求。目前情感主要的分类方式是上世纪ekman提出的7种情感,分别为:中性、开心、悲伤、生气、害怕、厌恶、惊讶。
语音合成技术随着近几年深度学习的兴起,越发成熟起来,让机器的发音像一个播音员一样已经可以实现。但是,让机器像人一样,发出带情感的语音,仍然是一个非常困难的问题,当前主流的情感语音合成可以分为两种方法。一种是基于隐马尔可夫模型这种传统机器学习的分段方法;另外一种是基于深度学习的端到端方法。基于隐马尔可夫方法合成的语音机械感很强,听起来不自然,目前已经非常少用到。基于深度学习的方法合成的语音相对比较自然。但是目前基于深度学习合成的情感语音,也只是简单的将情感标签融入文本特征中,合成的情感语音质量并不能得到有效保证。
在目前的技术中,由于融入情感信息方式比较简单,通常只是将情感的标签简单的融合到文本特征中,而没有考虑人在情感语音发音中的特点,导致模型不能很好的学习到情感信息,所以合成的情感语音比较生硬,不自然。
技术实现要素:
为了解决现有技术中存在的上述技术问题,本发明提出了一种融合词汇及音素发音特征的情感语音合成方法及系统,其具体技术方案如下:
一种融合词汇及音素发音特征的情感语音合成方法,包括如下步骤:
步骤一,通过录音采集设备,采集文本及情感标签;
步骤二,对所述文本进行预处理,获取音素及音素对齐信息,生成分词及分词语义信息;
步骤三,分别计算并得到分词发音时长信息、分词发音语速信息、分词发音能量信息、音素基频信息;
步骤四,分别训练分词语速预测网络net_wordspeed、分词能量预测网络net_wordenergy、音素基频预测网络net_phonemef0;
步骤五,通过tacotron2的encoder,获取音素隐含信息,通过net_wordspeed,获取分词语速隐含信息,通过net_wordenergy,获取分词能量隐含信息,通过net_phonemef0,获取音素基频隐含信息;
步骤六,拼接所述音素隐含信息、分词语速隐含信息、分词能量隐含信息、音素基频隐含信息,合成情感语音。
进一步的,所述步骤一具体包括步骤s1:通过录音采集设备,采集涵盖中性、开心、悲伤、生气、害怕、厌恶、惊讶的7种情感类型的语音音频,表示为
进一步的,所述步骤二具体包括如下步骤:
步骤s2,对采集的文本
步骤s3,对文本
其中,
进一步的,所述步骤三具体包括如下步骤:
步骤s4,利用生成的
步骤s5,通过得到的分词-时长文本
步骤s6,对所述音频
步骤s7,对所述音频
进一步的,所述步骤四具体包括如下步骤:
步骤s8,训练分词语速预测网络net_wordspeed:将情感类型
步骤s9,训练分词能量预测网络net_wordenergy:将情感类型
步骤s10,训练音素基频预测网络net_phonemef0:将情感类型
进一步的,所述步骤s8具体包括如下步骤:
步骤a:情感类型
步骤b:将得到的
步骤c:将分词长度n为的标签,通过one-hot向量转换技术,转换为宽度为5的one-hot向量,最终得到维度为n×5的网络标签矩阵
其中,
步骤d:将网络输入
进一步的,所述步骤五具体包括如下步骤:
步骤s11,通过tacotron2的encoder,获取音素隐含信息:将对应的音素文本
步骤s12,通过net_wordspeed,获取分词语速隐含信息:将分词特征
步骤s13,通过net_wordenergy,获取分词能量隐含信息:将分词特征
步骤s14,通过net_phonemef0,获取音素基频隐含信息:将音素文本
进一步的,所述步骤六具体包括如下步骤:
步骤s15将
步骤s16,将所述
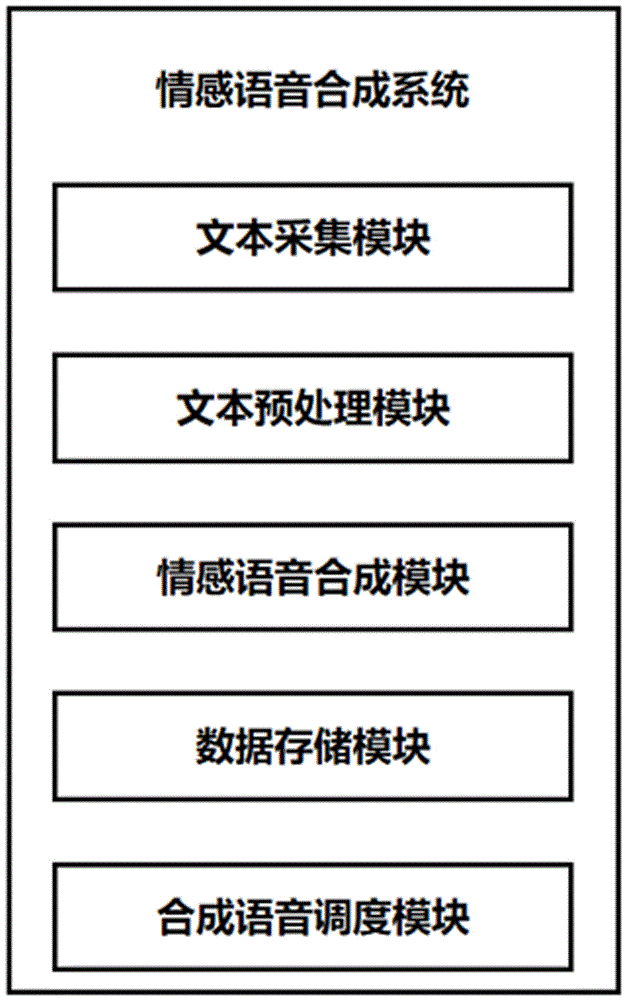
一种融合词汇及音素发音特征的情感语音合成系统,包括:
文本采集模块,用于采用http传输,采集需要合成的文本内容及情感标签;
文本预处理模块,用于将采集到的文本进行预处理,对所述文本进行分词、音素转换操作,包括:对文本依次进行文本符号统一转换为英文符号、数字格式统一转换为中文文本、对中文本分词、将分词文本通过预训练bert转换成语义向量表示形式、文本通过pypinyin工具包转换得到音素文本,所述情感标签通过one-hot转换得到情感标签的向量表示,生成可用于神经网络处理的数据;
情感语音合成模块,用于通过设计的网络模型处理文本及情感信息,合成情感语音;
数据存储模块,用于利用mysql数据库,存储已经合成的情感语音;
合成语音调度模块,用于决策,采用模型合成语音,还是从数据库调用已合成语音,作为输出,并开放http端口用于输出合成好的情感语音。
进一步的,所述输出优先采用已合成情感语音,其次采用模型合成以提升系统响应速度。
本发明的优点:
1.本发明的情感语音合成方法,通过控制词语的发音控制间接控制合成语音的情感,由于词语是发音韵律的基本单位,人通过控制不同词语发音的音量、语速、基频来信息表达不同的情感,所以通过模拟人类发音表达情感的方式进行情感语音合成,能够更好的合成蕴含语音的情感,使得合成的语音更加自然;
2.本发明的情感语音合成方法,利用独立的语速预测网络、能量预测网络和基频预测网络预测关于情感发音的三个要素,所以可以通过对独立网络的输出通过一个简单的系数进行相乘调整的方式,便捷的控制最终输出语音的效果;
3.本发明的情感语音合成方法,利用tacotron2作为骨架网络,能够有效提升最终语音合成的质量;
4、本发明的情感语音合成系统配置有情感语音调用接口,能够通过简单的http调用就能合成带情感的高质量情感语音,对于需要进行人机语音交互的场景,能够极大提高用户使用体验感。例如用于智能电话客服对话场景,地图智能导航对话场景,儿童教育中的对话机器人交互场景,银行、机场等人形机器人对话交互场景等。
附图说明
图1为本发明的情感语音合成系统的结构示意图;
图2为本发明的情感语音合成方法的流程示意图;
图3为本发明的情感语音合成方法的网络结构示意图;
图4语音合成系统tacotron2网络结构示意图。
具体实施方式
为了使本发明的目的、技术方案和技术效果更加清楚明白,以下结合说明书附图,对本发明作进一步详细说明。
如图1所示,一种融合词汇及音素发音特征的情感语音合成系统,包括:
文本采集模块,用于采用http传输,采集需要合成的文本内容及情感标签;
文本预处理模块,用于将采集到的文本进行预处理,对所述文本进行分词、音素转换操作,包括:对文本依次进行文本符号统一转换为英文符号、数字格式统一转换为中文文本、对中文本分词、将分词文本通过预训练bert转换成语义向量表示形式、文本通过pypinyin工具包转换得到音素文本,所述情感标签通过one-hot转换得到情感标签的向量表示,生成可用于神经网络处理的数据;
情感语音合成模块,用于通过设计的网络模型处理文本及情感信息,合成情感语音;
数据存储模块,用于利用mysql数据库,存储已经合成的情感语音;
合成语音调度模块,用于决策,采用模型合成语音,还是从数据库调用已合成语音,作为输出,并开放http端口用于输出合成好的情感语音,其中输出的情感语音优先采用已合成情感语音,其次采用模型合成以提升系统响应速度。
如图2-图4所示,一种融合词汇及音素发音特征的情感语音合成方法,包括如下步骤:
步骤s1,采集文本及情感标签:通过录音采集设备,采集涵盖中性、开心、悲伤、生气、害怕、厌恶、惊讶的7种情感类型的语音音频,表示为
步骤s2,预处理文本,获取音素及音素对齐信息:对步骤s1采集的文本
步骤s3,预处理文本,生成分词及分词语义信息:对文本
其中,
步骤s4,计算分词发音时长信息:利用步骤s2生成的
步骤s5,计算分词发音语速信息:通过步骤s4得到的分词-时长文本
步骤s6,计算分词发音能量信息:对步骤s1得到的音频和步骤s4得到的分词-时长文本
步骤s7,计算音素基频信息:对步骤s1得到的音频
步骤s8,训练分词语速预测网络net_wordspeed:将步骤s1得到的情感类型
步骤a:情感类型
步骤b:将步骤s3和步骤a得到的
步骤c:将分词长度n为的标签
其中,
步骤d:将步骤b得到的网络输入
步骤s9,训练分词能量预测网络net_wordenergy:将步骤s1得到的情感类型
步骤s10,训练音素基频预测网络net_phonemef0:将步骤s1得到的情感类型
步骤s11,通过tacotron2的encoder,获取音素隐含信息:将步骤s2得到的
步骤s12,通过net_wordspeed,获取分词语速隐含信息:将步骤s3得到的分词特征
步骤s13,通过net_wordenergy,获取分词能量隐含信息:将步骤s3得到的分词特征
步骤s14,通过net_phonemef0,获取音素基频隐含信息:将步骤s2得到的音素文本
步骤s15,拼接音素隐含信息、分词语速隐含信息、分词能量隐含信息、音素基频隐含信息:将步骤s11得到
步骤s16,合成情感语音:将步骤s15得到的,输入到tacotron2的decoder解码器网络中,然后通过tacotrn2网络的后续结构,解码并合成得到最终的情感语音。
综上所述,本实施提供的方法,通过控制文本词汇的发音,提高了情感语音特征生成的合理性,能够提高最终合成的情感语音的质量。
以上所述,仅为本发明的优选实施案例,并非对本发明做任何形式上的限制。虽然前文对本发明的实施过程进行了详细说明,对于熟悉本领域的人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行同等替换。凡在本发明精神和原则之内所做修改、同等替换等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

