本发明涉及电动车技术领域,尤其涉及一种用于电动车智能仪表的声音复刻方法及电动车。
背景技术:
人们对环保节能的呼声越来越大,电动车产业的发展越来越迅速。人们在骑行电动车的同时,也越来越关注使用体验。电动车的语音控制功能是提升用户用车体验的重要一部分,然而,目前传统的语音控制功能中语音的音色均为厂商设定的几种音色,无法实现用户自定义,语音控制过程单调、乏味,无法满足用户个性化需求,影响用户体验。以上问题亟待解决。
技术实现要素:
本发明的目的在于通过一种用于电动车智能仪表的声音复刻方法及电动车,来解决以上背景技术部分提到的问题。
为达此目的,本发明采用以下技术方案:
一种用于电动车智能仪表的声音复刻方法,该方法包括如下步骤:
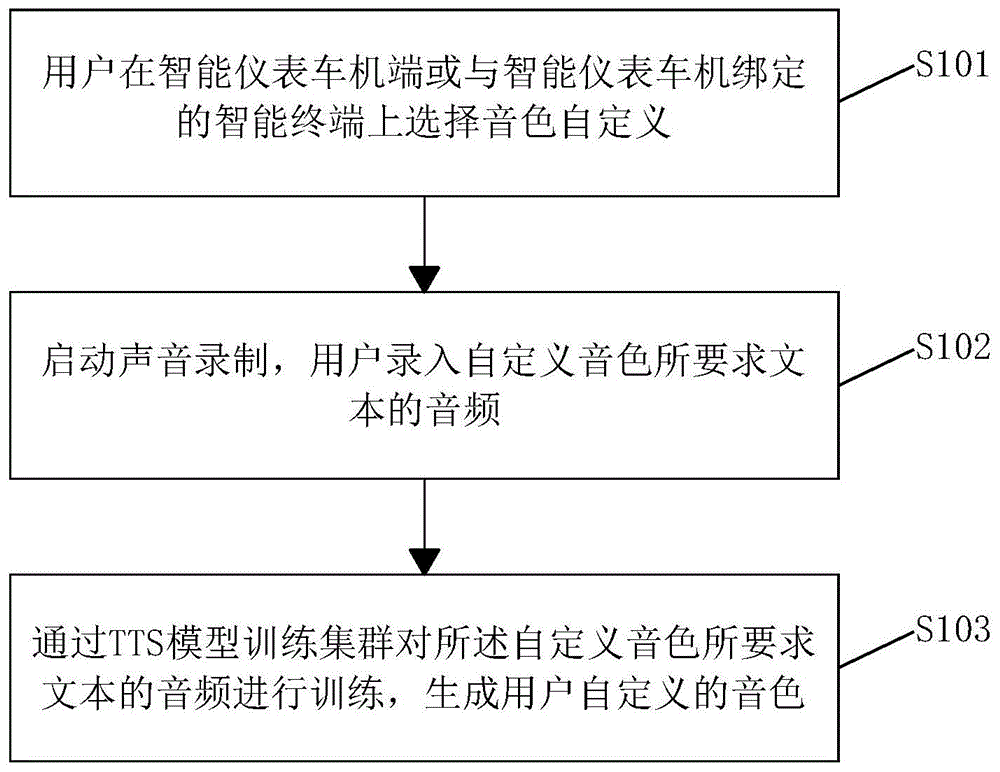
s101.用户在智能仪表车机端或与智能仪表车机绑定的智能终端上选择音色自定义;
s102.启动声音录制,用户录入自定义音色所要求文本的音频;
s103.通过文语转换(texttospeech,tts)模型训练集群对所述自定义音色所要求文本的音频进行训练,生成用户自定义的音色。
可选的,所述步骤s101包括:当用户在智能仪表车机端选择音色自定义时,需要验证是否为绑定用户,若是绑定用户,则执行音色自定义功能,若不是绑定用户,则提示用户进行绑定。
可选的,所述步骤s101还包括:在进行音色自定义时,需要判断当前已有的音色是否超出设定数量,若超出,则提示音色数量已达上限,需删除一个音色后才能自定义新的音色。
可选的,所述步骤s102中用户录入自定义音色所要求文本的音频,包括:用户朗读若干节文本,并在每朗读完一节文本后对录入音频进行校验,若校验不合格,则要求用户重新进行朗读,直至校验合格,若校验合格,则显示下一节文本供用户朗读,直至成功录入自定义音色所要求文本的全部音频。
可选的,所述若校验不合格,则要求用户重新进行朗读,直至校验合格,具体包括:若校验不合格,则在文本上标注存在不合格的地方,要求用户重新进行朗读,直至校验合格。
可选的,所述步骤s102还包括:在声音录制之前,提示用户输入发音人性别和音色昵称。
可选的,所述步骤s102还包括:在声音录制之前,提示用户保持周围环境安静。
可选的,所述步骤s103包括:用户在智能终端上自定义音色生成后,控制是否要下发智能仪表车机,在下发到智能仪表车机后,智能仪表车机上将显示新增音色。
第二方面,本发明实施例还提供一种电动车,该电动车采用上述用于电动车智能仪表的声音复刻方法进行声音复刻。
本发明实施例提出的用于电动车智能仪表的声音复刻方法及电动车实现了电动车在语音控制功能中音色的自定义,能够将用户自己的声音复刻到电动车上,增加了驾驶乐趣,满足了用户的个性化需求,智能化程度高。本发明在智能仪表车机端或智能终端均可以进行音色自定义,方便,灵活,适宜推广应用。
附图说明
图1为本发明实施例提供的用于电动车智能仪表的声音复刻方法流程图;
图2为本发明实施例提供的通过智能终端进行声音复刻的原理示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容,除非另有定义,本文所使用的所有技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中所使用的术语只是为了描述具体的实施例,不是旨在于限制本发明。
实施例一
请参照图1所示,图1为本发明实施例提供的用于电动车智能仪表的声音复刻方法流程图。
本实施例中用于电动车智能仪表的声音复刻方法包括如下步骤:
s101.用户在智能仪表车机端或与智能仪表车机绑定的智能终端上选择音色自定义;
s102.启动声音录制,用户录入自定义音色所要求文本的音频;
s103.通过tts模型训练集群对所述自定义音色所要求文本的音频进行训练,生成用户自定义的音色。
实施例二
本实施例中用于电动车智能仪表的声音复刻方法包括如下步骤:
s201.用户在智能仪表车机端或与智能仪表车机绑定的智能终端上选择音色自定义。
s202.启动声音录制,用户录入自定义音色所要求文本的音频。
s203.通过文tts模型训练集群对所述自定义音色所要求文本的音频进行训练,生成用户自定义的音色。
示例性的,在本实施例中当用户在智能仪表车机端选择音色自定义时,需要验证是否为绑定用户,若是绑定用户,则执行音色自定义功能,若不是绑定用户,则提示用户进行绑定。
示例性的,在本实施例中在进行音色自定义时,需要判断当前已有的音色是否超出设定数量(例如五个),若超出,则提示音色数量已达上限,需删除一个音色后才能自定义新的音色。
示例性的,在本实施例中所述步骤s102中用户录入自定义音色所要求文本的音频,包括:用户朗读若干节文本,并在每朗读完一节文本后对录入音频进行校验,若校验不合格,则要求用户重新进行朗读,直至校验合格,若校验合格,则显示下一节文本供用户朗读,直至成功录入自定义音色所要求文本的全部音频。示例性的,在本实施例中所述若校验不合格,则要求用户重新进行朗读,直至校验合格,具体包括:若校验不合格,则在文本上标注存在不合格的地方,这样用户在第二次朗读该节文本可以重点注意这些标注不合格的地方,要求用户重新进行朗读,直至校验合格。
示例性的,在本实施例中所述步骤s102还包括:在声音录制之前,提示用户输入发音人性别和音色昵称。示例性的,在本实施例中所述步骤s102还包括:在声音录制之前,提示用户保持周围环境安静,如果周围环境噪音比较大时,会弹出提示框,提示噪音过大,请保持周围环境安静。
示例性的,在本实施例中所述步骤s103包括:用户在智能终端上自定义音色生成后,控制是否要下发智能仪表车机,在下发到智能仪表车机后,智能仪表车机上将显示新增音色。
为了利于理解本发明,下面以用户在智能终端上自定义音色为例,对声音复刻的原理扼要介绍如下:如图2所示,第一步,声音采集:一、检测环境噪音;二、在环境噪音检测合格后,通过智能终端如手机上的app端采集用户声音;三、体验固定文本合成音效;四、断点续传。第二步,声音训练和模型生成:一、对采集的音频进行音频质量检测;二、数据标注,数据清晰,模型资源训练生成,音色生成;三、合成完成通知。第三步,模型同步:模型资源训练完成后,同步到tts应用服务器。第四步,模型调用:电动车智能仪表车机端调用服务器端的新音色。
实施例三
本实施例提供一种电动车,该电动车采用实施例一或二任一所述的用于电动车智能仪表的声音复刻方法进行声音复刻。
本发明实施例提出技术方案实现了电动车在语音控制功能中音色的自定义,能够将用户自己的声音复刻到电动车上,增加了驾驶乐趣,满足了用户的个性化需求,智能化程度高。本发明在智能仪表车机端或智能终端均可以进行音色自定义,方便,灵活,适宜推广应用。
本领域普通技术人员可以理解实现上述实施例中的全部或部分是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体或随机存储记忆体等。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

