本发明涉及语音识别、深度学习、信息安全技术领域,具体涉及一种基于对抗样本的语音隐写方法。
背景技术:
随着机器学习和深度学习技术的快速发展,自然语言处理技术的应用场景越来越广泛,例如机器翻译、智能客服、情感分析、语音识别等,日常生活中的各个地方都存在着自然语言处理技术的应用。
目前自然语言处理技术的许多发明理论被广泛应用于语音识别领域,最广泛使用的技术包括基于长短时记忆网络(longshort-termmemory,lstm)和连接时序分类(connectionisttemporalclassification,ctc)的语音识别发明、基于自注意力机制(transformer)的语音识别发明,可以较为准确地识别出说话者想表达的内容,例如电信运营商智能客服等。目前基于神经网络的语音识别技术已经广泛应用于智能音箱、智能语音助手、车载语音等诸多场景中,语音识别技术的出现客观上解放了人们的双手与眼睛,仅需通过开口说话就可以与机器进行交互,方便了人们的生活。
但是,近年来的一些研究表明,神经网络等人工智能技术存在一定的安全隐患,引起了人们的担忧。例如在图像领域中,卷积神经网络具有脆弱性,攻击者通过添加人眼难以察觉的微小扰动构造对抗样本,对抗样本和原始图像相似性高,人眼难以察觉异常,但使用卷积神经网络识别该对抗样本时,神经网络将以很大的概率将对抗样本识别错,从而产生错误的预测。
此外,许多研究也表明语音识别技术也存在类似的情况。carlini&wagner等人通过向音频中添加微小的噪声,生成的对抗音频不仅让人耳无法察觉到噪声,还能使语音识别系统错误的识别出指定的文本序列。最近学术界提出的一种commandersong能够将控制命令隐藏在音乐中,并对google的语音识别系统进行攻击。另一方面,shreyakhare等人指出在完全不知道系统内部结构的场景下,一种多目标进化优化的对抗样本生成技术也能够对智能语音识别系统构成威胁。这些针对语音识别系统不同的攻击场景均揭示出现代智能语音识别系统的脆弱性。
研究针对语音识别系统等神经网络的攻击具有积极的意义。一方面通过生成对抗样本,可以去评测现有的语音识别系统的稳定性和鲁棒性;另一方面,通过巧妙地利用音频对抗样本自身的特殊性质可以实现隐蔽通信、通信安全等目的。因此,通过研究对语音识别系统生成音频对抗样本的发明,并论证音频对抗样本用于语音隐写领域的安全性和隐秘性,为语音隐写提供一种新的思路和发明。目前主流的语音隐写发明包括:将信息加密压缩到音频比特流中的发明(例如使用mp3stego等工具)、将信息隐藏在频谱图中等。主要技术都是基于传统密码学与信息学的发明,未考虑到利用现代智能语音识别系统的脆弱性实现语音隐写。
技术实现要素:
本发明的目的是为了克服以上现有技术存在的不足,提供了一种具有隐蔽性、保密性和实用性的基于对抗样本的语音隐写方法。
本发明的目的通过以下的技术方案实现:
一种基于对抗样本的语音隐写方法,其特征在于:利用生成对抗样本的方法将噪声δ经编解码器aa添加到音频x上,生成满足最小化目标函数的音频样本x′,其中,音频x包含内容文本为t,音频样本x′包含需要加密传输的信息s。优选地,我们设置目标函数为dbx(δ) c·l(x δ,s) d·g(x δ,t),然后对其进行最小化。
其中,δ是噪声,x是原始音频,x′是加入扰动后的对抗音频,t为原始音频包含的语义文本,s是需要加密传输的信息。计算音频x的声学属性分贝值db(x)=maxi20·log10(xi),为避免将噪声δ添加到音频x上后所添加噪声被人耳察觉到明显异常,从而破坏隐写的隐蔽性,需要根据音频x的声学属性分贝值计算信噪比损失函数dbx(δ)=db(δ)-db(x),当dbx(δ)越小时所添加的噪声越不容易被人耳察觉。
l(x δ,s)为编解码器模型aa的损失函数,用于评估音频样本x’经编解码器aa识别后结果与加密信息s的一致性;当该损失函数l(x δ,s)为0时代表编解码器模型aa识别音频样本x’的结果与加密信息s完全一致,反之,该损失函数越大时,识别音频样本x’的结果与加密信息s的差别越大。
g(x δ,t)为第三方的语音识别模型bb的损失函数,用于评估音频样本x’在被第三方窃听后,被第三方的语音识别模型bb识别的结果与内容文本t的一致性。当该损失函数g(x δ,t)为0时代表语音识别模型bba识别音频样本x’的结果与内容文本t完全一致,反之,该损失函数越大时,识别音频样本x’的结果与内容文本t的差别越大。c、d为可人为调整的参数,用以动态权衡隐写音频样本的隐蔽性等级,默认情况下设置c=1,d=0。
优选地,目标函数使用adam优化器执行求解,最大迭代次数设置为6000,学习率初始设置为10。
本发明相对于现有技术具有如下优点:
一些传统的语音隐写发明例如将信息存储在频谱图上所生成的音频为一段杂乱无章的噪音,容易引起相关人员的注意并进一步分析得到加密信息;本发明进一步在语音隐写的隐蔽性上进行了进一步加强,巧妙地利用了音频对抗样本难以被人类听觉所感知,并且能够成功的绕过语音识别系统的特性,提出了一种新颖的基于对抗样本的语音隐写方法。
本发明将所生成的音频对抗样本用于语音隐写领域,具有较高的保密性、隐蔽性、安全性。在通常情况下,第三方无法轻易察觉到加密音频样本存在异常或隐写信息。即便第三方认为该音频样本存在隐写信息,在保障编解码器模型aa不被窃取的前提下,第三方无法获得其中所隐藏的信息。
本发明不仅可以用于机要部门的秘密通信,也可以被用于个人隐私保护、数字作品版权保护等民用目的,具有较高的应用价值。同时对该基于对抗样本的语音隐写方法的研究可以为现有的语音识别模型抵御对抗攻击、提高鲁棒性提供思路,也可以为如何检测这类新颖的语音隐写数据提供方向。
附图说明
构成本申请的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
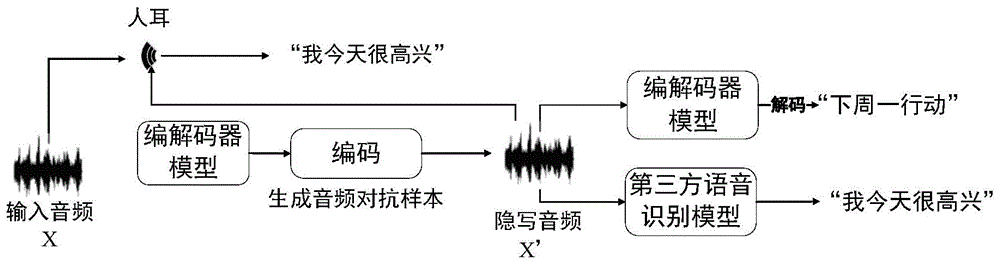
图1为本实施例的基于对抗样本的语音隐写方法的流程示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
参见图1,内容文本t为“我今天很高兴”的音频样本x,经过人耳、编解码器模型aa、第三方语音识别模型bb的识别结果均为“我今天很高兴”,即aa(x)=“我今天很高兴”,bb(x)=“我今天很高兴”,需加密传输的信息s为“下周一行动”。
步骤1:通过最小化损失函数dbx(δ) c·l(x δ,″下周一行动″) d·g(x δ,″我今天很高兴″),优化过程可选取adam优化器,最大迭代次数设置为6000,学习率初始设置为10。
步骤2:在步骤1中计算得到最优的噪声δ后,将噪声δ添加原始音频样本x中,并保存输出为音频y。原始音频样本x为不含任何重要信息的音频。
步骤3:测试音频y在人耳听来无明显异常且识别结果仍为“我今天很高兴”,第三方模型bb识别结果也不发生改变,bb(y)=“我今天很高兴”,但音频y经编解码器aa解码结果为“下周一行动”,实现语音隐写。
本发明新颖地采用基于对抗样本的发明实现语音隐写,可以应用于真实场景当中,且具备高度隐蔽性、保密性和安全性,具有较好的实际应用价值。
本发明核心思想简单,对损失函数进行简单修改即可将不同的语音识别模型改造为编解码器模型,对其进行研究一方面可以提高现有的语音识别模型抵御对抗攻击的能力,另一方面可以对此类基于神经网络脆弱性的语音隐写样本检测提供方向。
上述具体实施方式为本发明的优选实施例,并不能对本发明进行限定,其他的任何未背离本发明的技术方案而所做的改变或其它等效的置换方式,都包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

