本申请涉及语音识别技术领域,尤其涉及一种语音识别文本的纠错方法。
背景技术:
语音识别文本大部分依赖于字典中出现的字和词,没有的词会用同音的字拼接而成。这样的语音识别文本中存在一定量的错误同音词汇,这些错误同音词汇与文本序列中的词义不符。这会导致文本语义低,识别效果不好,可读性差的问题。语音识别文本的纠错方法从以上问题出发,解决了语音识别文本纠错中识别效果和可读性差的问题。
技术实现要素:
本申请实施例提供一种语音识别文本的纠错的技术方案,用以解决语音识别文本的纠错问题。
本申请提供的一种语音识别文本的纠错方法,包括:
获取语音解码输出的待处理文本;
调用检错模型处理所述待处理文本,得到出错目标字和出错目标字对应的置信度topk候选字集;
根据所述出错目标字和所述置信度topk候选字集,对所述待处理文本进行纠错,得到第一纠错结果;
根据名词处理模型和所述第一纠错结果,得到出错目标词、目标词类别和名词集合数据;
根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果;
输出所述第二纠错结果,得到纠错后的最终文本;
其中,k为正整数。
进一步的,在本申请提供的一种优选实施方式中,调用检错模型处理所述待处理文本,得到出错目标字和出错目标字对应的置信度topk候选字集,具体包括:
根据bert模型,训练得到检错模型;
调用所述检错模型计算待处理文本中每个字的候选字集及候选字集中每个候选字对应的置信度;
按照所述置信度高低排序,选取置信度排在前k位的候选字组成topk候选字集;
匹配所述字和所述置信度topk候选字集;
当所述字匹配不到所述置信度topk候选字集时,对所述字进行出错标记,得到标记结果;
根据所述标记结果,得到的出错目标字和出错目标字对应的置信度topk候选字集。
进一步的,在本申请提供的一种优选实施方式中,根据bert模型,训练得到检错模型,具体包括:
训练bert模型;
对所述训练的bert模型进行模型蒸馏,得到检错模型;
其中,所述检错模型为3层的bert模型。
进一步的,在本申请提供的一种优选实施方式中,根据所述出错目标字和所述置信度topk候选字集,对所述待处理文本进行纠错,得到第一纠错结果,具体包括:
计算所述出错目标字和所述置信度topk候选字集中候选字的相似度值,得到相似度topn候选字集;
用所述相似度topn候选字集中的候选字分别替换所述出错目标字,得到n个替换后的待纠错语句;
分别计算所述n个待纠错语句的通顺度值,得到n个通顺度ppl值;
选取所述n个通顺度ppl值中最小值,得到最小ppl值;
选取所述最小ppl值对应的候选字,得到替换字;
用所述替换字替换所述出错目标字,得到第一纠错结果;
其中,n为正整数,n小于k。
进一步的,在本申请提供的一种优选实施方式中,计算所述出错目标字和所述置信度topk候选字集中候选字的相似度值,得到相似度topn候选字集,具体包括:
根据相似度计算方法,计算所述出错目标字和所述置信度topk候选字集中候选字的相似度值,得到k个相似度值;
对所述k个候选字集按照相似度值从大到小排序,得到相似度值序列;
选取所述相似度值序列中前n个相似度值对应的候选字,得到相似度topn候选字集;
其中,所述相似度计算方法采用字的拼音的声韵母编辑距离加权计算方法。
进一步的,在本申请提供的一种优选实施方式中,根据名词处理模型和所述第一纠错结果,得到出错目标词、目标词类别和名词集合数据,具体包括:
调用名词处理模型,构建按照名词类别存储名词的名词集合数据;
调用名词处理模型处理所述第一纠错结果,得到出错目标词和目标词类别;
其中,所述名词处理模型为bert-bilstm-crf模型;
所述名词集合数据包括名词类别为所述目标词类别的名词子集合。
进一步的,在本申请提供的一种优选实施方式中,根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果,具体包括:
确定所述出错目标词的名词类别,得到出错目标词类别;
当所述出错目标词类别属于所述目标词类别时,确定所述出错目标词类别在所述名词集合数据中对应的名词子集合;
根据所述出错目标词的第一个字的声母相似度,在所述名词子集合中选择对应名词,得到声母相似集合;
根据所述出错目标词的第一个字的韵母相似度,在所述声母相似集合中得到所述出错目标词的第一个字最相似的候选名词集合;
用所述出错目标词的剩下每个字匹配所述候选名词集合中剩下的字,得到相似度值;
当所述相似度值大于预设的相似度阈值时,在所述候选名词集合中得到最优候选词;
用所述最优候选词替换所述出错目标词,得到第二纠错结果。
进一步的,在本申请提供的一种优选实施方式中,根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果,具体包括:
确定所述出错目标词的名词类别,得到出错目标词类别;
当所述出错目标词类别属于所述目标词类别时,确定所述出错目标词类别在所述名词集合数据中对应的名词子集合;
根据所述出错目标词的第一个字的声母相似度,在所述名词子集合中选择对应名词,得到声母相似集合;
根据所述出错目标词的第一个字的韵母相似度,在所述声母相似集合中得到所述出错目标词的第一个字最相似的候选名词集合;
用所述出错目标词的剩下每个字匹配所述候选名词集合中剩下的字,得到相似度值;
当所述相似度值小于预设的相似度阈值时,根据预置的字典库构建所述出错目标词的候选词集;
用所述候选词集中的候选词分别替换所述出错目标词,得到候选词待纠错语句集合;
分别计算所述候选词待纠错语句集合中语句的通顺度ppl值,得到语句通顺度值集合;
选取所述语句通顺度值集合中通顺度ppl最小的值,得到最小ppl语句通顺度值;
选取所述最小ppl语句通顺度值对应的所述候选词集中的候选词,得到最优候选词;
用所述最优候选词替换所述出错目标词,得到第二纠错结果。
进一步的,在本申请提供的一种优选实施方式中,根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果,具体包括:
确定所述出错目标词的名词类别,得到出错目标词类别;
当所述出错目标词类别不属于所述目标词类别时,根据预置的字典库构建所述出错目标词的候选词集;
用所述候选词集中的候选词分别替换所述出错目标词,得到候选词待纠错语句集合;
分别计算所述候选词待纠错语句集合中语句的通顺度ppl值,得到语句通顺度值集合;
选取所述语句通顺度值集合中通顺度ppl最小的值,得到最小ppl语句通顺度值;
选取所述最小ppl语句通顺度值对应的所述候选词集中的候选词,得到最优候选词;
用所述最优候选词替换所述出错目标词,得到第二纠错结果。
进一步的,在本申请提供的一种优选实施方式中,根据预置的字典库构建所述出错目标词的候选词集,具体包括:
在预置的字典库中分别选择所述出错目标词的每个字对应的m个最相似字;
分别组合所述出错目标词的每个字对应的所述m个最相似字,得到所述出错目标词的每个字对应的相似字候选集合;
按照所述出错目标词中每个字的顺序串联所述相似字候选集合中的候选字,得到所述出错目标词的候选词集;
其中,m为正整数。
本申请提供的实施例,至少具有以下技术效果:
通过调用语言模型处理待处理文本,同时对待处理文本进行二次纠错,能够更好实现对语音识别文本的纠错。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
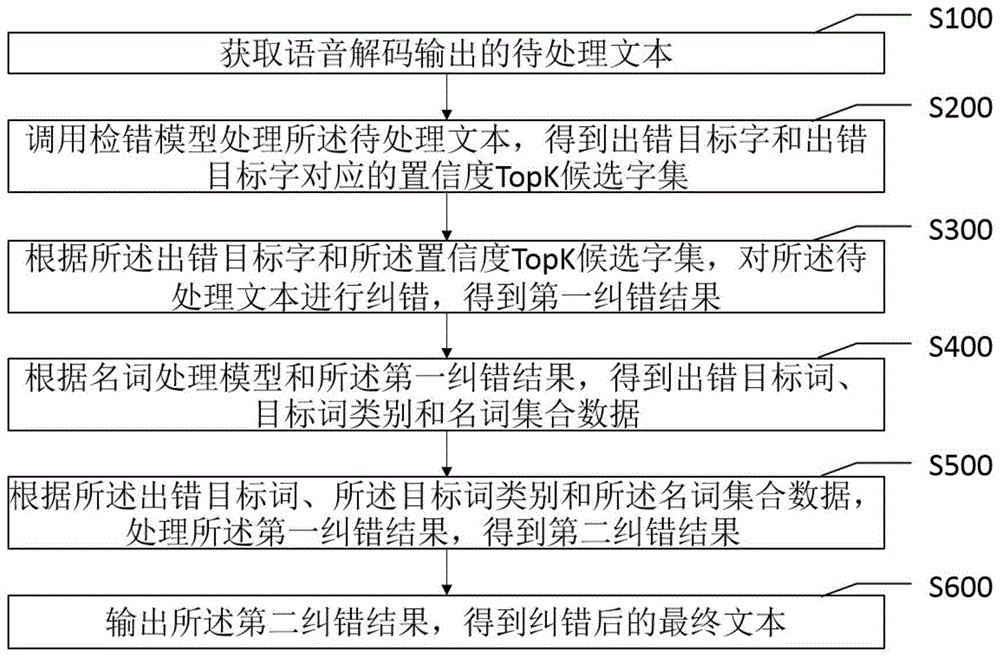
图1为本申请实施例提供的语音识别文本的纠错方法的流程图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
请参照图1,为本申请实施例提供的语音识别文本的纠错方法,具体包括以下步骤:
s100:获取语音解码输出的待处理文本。
可以理解的是,正常的语音识别解码输出文本一般都会存在相同音或相近音错误,我们需要对语音识别文本中相同音或相近音错误进行处理。首先我们需要得到语音识别模型的解码器输出结果,然后把这个输出结果作为纠错的文本输入。这里的待处理文本可以是实时的语音解码输出文本,也可以是其他场景中需要进行纠错的文本。例如我们通过语音解码装置获取到一段输出文本,这段输出文本没有进行纠错处理,这里的文本我们可以理解为待处理文本。
s200:调用检错模型处理所述待处理文本,得到出错目标字和出错目标字对应的置信度topk候选字集。
其中,k为正整数。
可以理解的是,我们把获取到的待处理文本输入到检错模型,检错模型对待处理文本进行处理。我们可以获取到待处理文本的出错目标字和出错目标字对应的置信度topk候选字集。这里的置信度topk候选字集可以理解为出错目标字位置对应的最可能出现的k个候选字组成的字集,这里的k是正整数。在实际的运用场景中,这里的k的具体数值可以根据处理的需要进行相应地设置。显而易见的是,这里的检错模型可以是基于神经网络、向量机、贝叶斯等方法获取的模型。
具体的,在本申请提供的一种优选实施方式中,调用检错模型处理所述待处理文本,得到出错目标字和出错目标字对应的置信度topk候选字集,具体包括:
根据bert模型,训练得到检错模型;
调用所述检错模型计算待处理文本中每个字的候选字集及候选字集中每个候选字对应的置信度;
按照所述置信度高低排序,选取置信度排在前k位的候选字组成topk候选字集;
匹配所述字和所述置信度topk候选字集;
当所述字匹配不到所述置信度topk候选字集时,对所述字进行出错标记,得到标记结果;
根据所述标记结果,得到的出错目标字和出错目标字对应的置信度topk候选字集。
可以理解的是,bert模型是自然语言处理领域一个常用的预训练语言模型。bert的全称是bidirectionalencoderrepresentationfromtransformers,采用了transformerencoderblock进行连接。本申请中的检错模型为基于原bert预训练语言模型训练得到的语言处理模型。在实际的运用场景中,我们可以通过调用检错模型对输入的待处理文本序列中的每个字进行计算。通过计算处理,我们可以获取每个字对应位置上可能出现的相近的候选字,同时获取对应的候选字在对应位置上的置信度。我们通过对每个字对应的候选字的置信度进行高低顺序排列,可以得到每个字对应的按照置信度高低排列的候选字集。优选的,我们可以选取置信度排在前5的5个候选字作为候选字,这5个候选字组成top5候选字集。我们需要对每个字和该字对应的top5候选字集进行匹配,根据匹配结果进行下一步的纠错步骤。当我们根据匹配结果,发现该字没有出现在top5候选字集中时,需要对这个字进行标记。标记的字作为出错字,同时我们在标记时需要记录该出错字的位置。当我们根据匹配结果发现该字出现在top5候选字集中时,则判定该字在当前位置上没有错误。通过对bert模型及候选字集的运用,我们可以有效提高语音识别文本的检错效率。
具体的,在本申请提供的一种优选实施方式中,根据bert模型,训练得到检错模型,具体包括:
训练bert模型;
对所述训练的bert模型进行模型蒸馏,得到检错模型;
其中,所述检错模型为3层的bert模型。
可以理解的是,本申请实施例中用到的bert模型是一个参数非常多的模型。bert模型包含约1.1亿个参数,需要大量的时间来训练。bert模型体积与计算量都很大,难以用于一些性能没那么好的机器上,运用到实时性要求高的应用中也存在一定的难度。因此,训练一个精简的轻量级的bert模型显得极为重要。模型蒸馏是一种比较好的解决方法,因此对bert模型进行模型蒸馏显得非常必要。模型蒸馏可以理解为使用大模型学到的知识训练小模型,从而让小模型具有大模型的泛化能力。模型蒸馏是一种模型压缩的方法,首先需要训练一个大的模型,这个大模型也称为teacher模型。利用teacher模型输出的概率分布训练小模型,小模型称为student模型。训练student模型时,包含softlabel和hardlabel。softlabel对应了teacher模型输出的概率分布,而hardlabel是原来的one-hotlabel。本申请实施例通过模型蒸馏训练方法,利用原始bert模型蒸馏训练了一个3层的轻量级bert模型。检错模型在保持原有bert模型的准确率的情况下,参数比原先要少很多,模型推理时间也大大缩短。本申请实施例通过对bert模型进行精简,有效提高了检错模型的处理速度。
s300:根据所述出错目标字和所述置信度topk候选字集,对所述待处理文本进行纠错,得到第一纠错结果。
具体的,在本申请提供的一种优选实施方式中,根据所述出错目标字和所述置信度topk候选字集,对所述待处理文本进行纠错,得到第一纠错结果,具体包括:
计算所述出错目标字和所述置信度topk候选字集中候选字的相似度值,得到相似度topn候选字集;
用所述相似度topn候选字集中的候选字分别替换所述出错目标字,得到n个替换后的待纠错语句;
分别计算所述n个待纠错语句的通顺度值,得到n个通顺度ppl值;
选取所述n个通顺度ppl值中最小值,得到最小ppl值;
选取所述最小ppl值对应的候选字,得到替换字;
用所述替换字替换所述出错目标字,得到第一纠错结果;
其中,n为正整数,n小于k。
可以理解的是,语音识别文本错误大部分是相同音或相近音错误,不同的同音字放在同一个句子里,有时候表达的意思完全不一样。对于这种情况,我们可以用这个句子的通顺度来衡量这个句子是否通顺。在本申请实施例中,优选的,我们设置n为3,k为5。在实际的运用场景中,我们利用出错目标字与对应的top5候选字集中候选字进行相似度计算,得到当前出错目标字与top5候选字集中候选字的相似度值,并从高到低排序。我们采用top5候选字集中与当前位置的字的相似度最高的3个候选字作为相似度top3候选字集中的候选字。用所述相似度top3候选字集中的候选字分别替换所述出错目标字,得到3个替换后的待纠错语句。分别计算该3个待纠错语句的通顺度值,得到3个通顺度ppl值。选取所述3个通顺度ppl值中最小值,得到最小ppl值。选取所述最小ppl值对应的候选字,得到替换字。我们用所述替换字替换所述出错目标字,得到第一纠错结果。显而易见的是,通顺度ppl可以理解为语言模型混消度,该值越小,语句越通顺,语义越正确。本申请实施例通过对通顺度的运用,能够有效提高语音识别文本的纠错准确性。
具体的,在本申请提供的一种优选实施方式中,计算所述出错目标字和所述置信度topk候选字集中候选字的相似度值,得到相似度topn候选字集,具体包括:
根据相似度计算方法,计算所述出错目标字和所述置信度topk候选字集中候选字的相似度值,得到k个相似度值;
对所述k个候选字集按照相似度值从大到小排序,得到相似度值序列;
选取所述相似度值序列中前n个相似度值对应的候选字,得到相似度topn候选字集;
其中,所述相似度计算方法采用字的拼音的声韵母编辑距离加权计算方法。
可以理解的是,相似度可以用于比较两个事物的相似性。一般通过计算事物的特征之间的距离来判断相似度的大小。常用的相似度计算方法都可以是我们这里的相似度计算方法。在本申请实施例中,优选的,我们设置k为5,n为3。我们利用当前出错目标字与top5候选字集中候选字进行相似度计算,相似度值采用声韵母编辑距离的加权计算得到。其中声母相似度权重优选为0.6,韵母相似度权重优选为0.4,并且分别定义每个声母对应的近似声母候选集合以及每个韵母对应的韵母候选集合。我们可以采用出错目标字的拼音的声韵母编辑距离加权计算得到该出错目标字位置上的字与top5候选字集中候选字的相似度值,并从高到低排序。该top5候选字集中5个候选字按照相似度值从大到小排序后,我们可以得到一个相似度值序列。优选的,我们选取该相似度值序列中最相似的3个候选字,得到相似度top3候选字集。本申请实施例通过相似度计算方法的运用,能够有效提高对出错字进行纠错的准确性。
s400:根据名词处理模型和所述第一纠错结果,得到出错目标词、目标词类别和名词集合数据。
可以理解的是,在进行语音识别文本的过程中,用于生成词汇的词汇表中有时候并不会有一些人名、地名以及机构名等词汇。这个时候,一般需要字典中有的字或词进行拼接得到对应的人名、地名或机构名。这种组合而成的字、词都有多个同音的候选项,这会导致拼接出来的人名、地名和机构名的错误比较多。此时,我们就需要对这些名词错误进行纠错。
具体的,在本申请提供的一种优选实施方式中,根据名词处理模型和所述第一纠错结果,得到出错目标词、目标词类别和名词集合数据,具体包括:
调用名词处理模型,构建按照名词类别存储名词的名词集合数据;
调用名词处理模型处理所述第一纠错结果,得到出错目标词和目标词类别;
其中,所述名词处理模型为bert-bilstm-crf模型;
所述名词集合数据包括名词类别为所述目标词类别的名词子集合。
可以理解的是,bert建立在transformer之上,拥有强大的语言表征能力和特征提取能力。bilstm是bi-directionallongshort-termmemory的缩写,由前向lstm与后向lstm组合而成。两者在自然语言处理任务中都常被用来建模上下文信息。crf也称为条件随机场。crf是给定随机变量x条件下,随机变量y的马尔可夫随机场,是一种无向图模型。近年来条件随机场在分词、词性标注和命名实体识别等序列标注任务中取得了很好的效果。本申请中的名词处理模型采用bert-bilstm-crf模型。在具体的运用场景中,优选的,我们设置目标词类别为人名、地名和机构名。我们可以采用bert-bilstm-crf模型,进行人名、地名和机构名的检测与识别,把检测出的名词分别存入人名表、地名表和机构名表中。这里的存有数据的人名表、地名表和机构名表可以理解为名词集合数据中的名词子集合。接下来,我们通过调用bert-bilstm-crf模型处理第一纠错结果,识别出该第一纠错结果文本序列中可能出现的人名、地名和机构名的起始和结束位置,得到出错目标词与出错目标词位置应该对应的目标词类别。显而易见的是,通过bert模型、bilstm模型和crf模型得到的名词处理模型充分结合了的bert模型、bilstm模型和crf模型的优点,很好地提高了语音识别文本的检错的准确性,同时也有效地降低了实时率。
s500:根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果。
具体的,在本申请提供的一种优选实施方式中,根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果,具体包括:
确定所述出错目标词的名词类别,得到出错目标词类别;
当所述出错目标词类别属于所述目标词类别时,确定所述出错目标词类别在所述名词集合数据中对应的名词子集合;
根据所述出错目标词的第一个字的声母相似度,在所述名词子集合中选择对应名词,得到声母相似集合;
根据所述出错目标词的第一个字的韵母相似度,在所述声母相似集合中得到所述出错目标词的第一个字最相似的候选名词集合;
用所述出错目标词的剩下每个字匹配所述候选名词集合中剩下的字,得到相似度值;
当所述相似度值大于预设的相似度阈值时,在所述候选名词集合中得到最优候选词;
用所述最优候选词替换所述出错目标词,得到第二纠错结果。
可以理解的是,我们在判断得到出错目标词之后,就要对该出错目标词进行纠错。在具体的应用场景中,例如我们得到了出错目标词“张小小”以及目标词类别范围为“人名”、“地名”、“机构名”中任意一种。我们可以确定出错目标词“张小小”的名词类别是“人名”,由于目标词类别范围中包括“人名”,所以我们可以判断出所述出错目标词类别属于所述目标词类别。接下来,我们找到对应的人名表。这里的人名表可以理解为所述名词集合数据中对应的名词子集合。我们先根据该词“张小小”的第一个字“张”的声母相似度查询人名表得到一个声母相似度集合,再在该集合中利用第一个字“张”的韵母相似度快速定位词表中最相似的字,在所述声母相似集合中得到所述出错目标词的第一个字最相似的候选名词集合。然后用该词的第二个字“小”的相似度去匹配该候选名词集合中的剩下的字,接着用该词的第三个字“小”的相似度去匹配该集合中的剩下的字。最终我们可以得到一个相似度值。优选的,我们这里设定相似度阈值为0.8,当我们得到的相似度值大于0.8时,我们在所述候选名词集合中得到最优候选词。用所述最优候选词替换所述出错目标词,我们就可以得到对名词进行纠错的纠错结果。这里的纠错结果我们可以理解为第二纠错结果。
具体的,在本申请提供的一种优选实施方式中,根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果,具体包括:
确定所述出错目标词的名词类别,得到出错目标词类别;
当所述出错目标词类别属于所述目标词类别时,确定所述出错目标词类别在所述名词集合数据中对应的名词子集合;
根据所述出错目标词的第一个字的声母相似度,在所述名词子集合中选择对应名词,得到声母相似集合;
根据所述出错目标词的第一个字的韵母相似度,在所述声母相似集合中得到所述出错目标词的第一个字最相似的候选名词集合;
用所述出错目标词的剩下每个字匹配所述候选名词集合中剩下的字,得到相似度值;
当所述相似度值小于预设的相似度阈值时,根据预置的字典库构建所述出错目标词的候选词集;
用所述候选词集中的候选词分别替换所述出错目标词,得到候选词待纠错语句集合;
分别计算所述候选词待纠错语句集合中语句的通顺度ppl值,得到语句通顺度值集合;
选取所述语句通顺度值集合中通顺度ppl最小的值,得到最小ppl语句通顺度值;
选取所述最小ppl语句通顺度值对应的所述候选词集中的候选词,得到最优候选词;
用所述最优候选词替换所述出错目标词,得到第二纠错结果。
可以理解的是,我们在判断得到出错目标词之后,就要对该出错目标词进行纠错。在具体的应用场景中,例如我们得到了出错目标词“张小小”以及目标词类别范围为“人名”、“地名”、“机构名”中任意一种。我们可以确定出错目标词“张小小”的名词类别是“人名”,由于目标词类别范围中包括“人名”,所以我们可以判断出所述出错目标词类别属于所述目标词类别。接下来,我们找到对应的人名表。这里的人名表可以理解为所述名词集合数据中对应的名词子集合。我们先根据该词“张小小”的第一个字“张”的声母相似度查询人名表得到一个声母相似度集合,再在该集合中利用第一个字“张”的韵母相似度快速定位词表中最相似的字,在该声母相似集合中得到所述出错目标词的第一个字最相似的候选名词集合。然后用该词的第二个字“小”的相似度去匹配该候选名词集合中的剩下的字,接着用该词的第三个字“小”的相似度去匹配该集合中的剩下的字。最终我们可以得到一个相似度值。优选的,我们这里设定相似度阈值为0.8,当我们得到的相似度值小于0.8时,我们需要根据预置的字典库构建该出错目标词“张小小”的候选词集。此时,我们可以用该候选词集中的候选词分别替换出错目标词“张小小”,得到由候选词替换出错目标词组成的待纠错语句集合。这里的待纠错语句集合由候选词替换出错目标词所在语句后的语句组成。为了进行候选词的筛选,我们需要分别计算该候选词待纠错语句集合中语句的通顺度ppl值。我们通过计算可以得到候选词对应语句的通顺度值集合。此时,我们选取该语句通顺度值集合中通顺度ppl最小的值,得到最小ppl语句通顺度值。显而易见的是,通顺度ppl最小表示这个语句最通顺。我们选取最小ppl语句通顺度值对应的候选词集中的候选词,得到最优候选词,用该最优候选词替换该出错目标词,我们就可以得到对名词进行纠错的纠错结果。这里的纠错结果我们可以理解为第二纠错结果。
具体的,在本申请提供的一种优选实施方式中,根据所述出错目标词、所述目标词类别和所述名词集合数据,处理所述第一纠错结果,得到第二纠错结果,具体包括:
确定所述出错目标词的名词类别,得到出错目标词类别;
当所述出错目标词类别不属于所述目标词类别时,根据预置的字典库构建所述出错目标词的候选词集;
用所述候选词集中的候选词分别替换所述出错目标词,得到候选词待纠错语句集合;
分别计算所述候选词待纠错语句集合中语句的通顺度ppl值,得到语句通顺度值集合;
选取所述语句通顺度值集合中通顺度ppl最小的值,得到最小ppl语句通顺度值;
选取所述最小ppl语句通顺度值对应的所述候选词集中的候选词,得到最优候选词;
用所述最优候选词替换所述出错目标词,得到第二纠错结果。
可以理解的是,我们在判断得到出错目标词之后,就要对该出错目标词进行纠错。在具体的应用场景中,例如我们得到了出错目标词“帐消消”以及目标词类别范围为“人名”、“地名”、“机构名”中的任意一种。我们可以确定出错目标词“帐消消”的名词类别不属于“人名”、“地名”、“机构名”中的任意一种。这时,我们需要根据预置的字典库构建该出错目标词“帐消消”的候选词集。此时,我们可以用该候选词集中的候选词分别替换出错目标词“帐消消”,得到由候选词替换出错目标词组成的待纠错语句集合。这里的待纠错语句集合由候选词替换出错目标词所在语句后的语句组成。为了进行候选词的筛选,我们需要分别计算该候选词待纠错语句集合中语句的通顺度ppl值。我们通过计算可以得到候选词对应语句的通顺度值集合。此时,我们选取该语句通顺度值集合中通顺度ppl最小的值,得到最小ppl语句通顺度值。显而易见的是,通顺度ppl最小表示这个语句最通顺。我们选取最小ppl语句通顺度值对应的候选词集中的候选词,得到最优候选词,用该最优候选词替换该出错目标词,我们就可以得到对名词进行纠错的纠错结果。这里的纠错结果我们可以理解为第二纠错结果。本申请实施例通过结合拼字纠错方法和语句通顺度对语音识别文本进行纠错,能够有效提高纠错准确性。
具体的,在本申请提供的一种优选实施方式中,根据预置的字典库构建所述出错目标词的候选词集,具体包括:
在预置的字典库中分别选择所述出错目标词的每个字对应的m个最相似字;
分别组合所述出错目标词的每个字对应的所述m个最相似字,得到所述出错目标词的每个字对应的相似字候选集合;
按照所述出错目标词中每个字的顺序串联所述相似字候选集合中的候选字,得到所述出错目标词的候选词集;
其中,m为正整数。
可以理解的是,我们这里的字典库需要提前预置。在预置的字典库中,我们选择出错目标词的每个字对应的m个最相似字。优选的,我们这里的m可以设置为3。我们从字典库中找到该出错目标词的每一个字最相似的3个字,然后组成候选集合,利用每个字的候选集合中的字进行串联得到心动的序列。组合所有串联得到的序列就构成了我们出错目标词的候选词集。例如,我们获取到出错目标词“张小小”,出错目标词的第一个字“张”、第二个字“小”和第三个字“小”可以从字典库中分别找到最相似的3个字。由此我们可以组合出一个含有27个元素的候选词集。显而易见的是,我们在组合最相似字时,第一个字“张”对应的最相似的3个字只能放在“张”的位置,第二个字“小”对应的最相似的3个字只能放在第二个“小”的位置,第三个字“小”对应的最相似的3个字只能放在第三个“小”的位置。
s600:输出所述第二纠错结果,得到纠错后的最终文本。
可以理解的是,我们在得到第二纠错结果之后,就完成了主要的纠错工作。此时,我们可以把纠错后的文本按照需要的格式输出,从而完成最终的纠错工作。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

