本发明属于音频处理技术领域,具体涉及一种虚拟低音转换方法。
背景技术:
由于制造工艺的限制,普通扬声器的一般都存在严格的工作带宽限制,尤其是声音信号的低频部分,也因此使其无法对原信号的全部频段进行无损失的还原。在如今多样化的扬声器系统中,低成本扬声器依旧占据主要地位,所以亟需一种通用的解决方案,或者说需要为带宽限制外的频率分量寻找一个合适的替代。在这样的背景下,一种名叫虚拟低音(virtualbass)的技术应运而生。
虚拟低音又名“消失的基频分量”(missingfundamental),这个概念最早由j.c.r.licklider在1951年的论文《aduplextheoryofpitchperception》中提出。这项基于心里声学的研究表明,人类的听觉系统可以从声音信号基频分量(fundamentalcomponent)的高频谐波中感知出低音基频。举个例子来说,如果让一个人听取一段频率分别为200hz,300hz,400hz的谐波序列(harmonicseries),其大脑可以有效的感知到他们之间100hz的共差频率,即想要替换的基频分量。
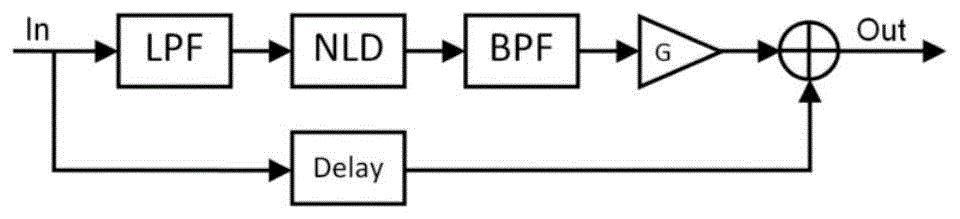
虚拟低音技术最早通过非线性元件系统(nonlineardevicesystem)实现,其中运用最为广泛的一套nld-based系统是由b.t.daniel在1999年的《theeffectofthemaxxbasspsychoacousticbassenhancementsystemonloudspeakerdesign》中提出的maxxbass。参见图1,输入信号首先通过一个低通滤波器(lpf)来获得需要的低频分量,紧接着这个低通信号(低频分量)由非线性元件(nld)处理,产生谐波分量。这些连续的谐波分量通过一个特定带通滤波器(bfp)来获得合适的频段,并添加一个大小为g的增益。此后,这些处理后的信号将与经过延迟处理的原信号叠加,最后输出。
在这之后m.r.bai于2006年在论文《synthesisandimplementationofvirtualbasssystemwithaphase-vocoderapproach》中提出了相位声码器(phasevocoder)来替代非线性元件产生谐波。相位声码器用小时间窗口将输入信号采样,经过快速傅里叶变换(fft)转换之后再进行相关处理,较为有效的保证了信号相位的一致性。相比于非线性元件系统,相位声码器几乎完全作用于信号的频域,也因此可以有效避免系统输出的互调失真。但是相位声码器的缺点在于难以权衡时域和频域的分辨率关系:fres=1/tw,其中fres是频域分辨率(hz),tw是所选窗口长度。因为虚拟低音转换对于频域分辨率有着较高的要求,所以时间窗口的长度选择实际上是一个很难抉择的问题。
最终,来自英国埃塞克斯大学的学者a.j.hill提出了混合虚拟低音(hybridvirtualbass)方法,它混合了此前两种信号处理方法。这个方法结合了非线性元件系统对时域信号变化的高敏感性和相位编码器对于非瞬态信号的良好处理效果的两种优势,设计了一个瞬态成分探测器(transientcontentdetector)。换句话说,所谓的混合系统(hybridsystem)其本质上就是对同一时间窗口中两个系统输出的权重分配。尽管混合虚拟低音系统有效兼顾了非线性元件系统和相位声码器的优势,但它存在时间效率低下,同时需要设置大量的参数等缺点。这直接导致该技术无法被广泛应用。
技术实现要素:
本发明的发明目的在于:针对上述存在的问题,提供一种通过生成网络实现虚拟低音转换方法,简化虚拟低音的设置过程,缩减虚拟低音的处理时间。
本发明的基于生成网络的虚拟低音转换方法,包括下列步骤:
步骤1:设置基于循环生成网络的初始虚拟低音生成网络的网络结构:
所述虚拟低音生成网路包括生成器gx→y和生成器gy→x,以及判别器dx和判别器dy;其中,生成器gx→y分别与生成器gy→x和判别器dy相连,生成器gy→x分别与判别器dx和判别器dy相连,x表示输入数据所在的特征空间,y表示输出数据所在的特征空间;
步骤2:对初始虚拟低音生成网络进行深度学习训练:
步骤201:设置第一训练数据集:
采集原始音频信号集,所述原始音频信号集包括多帧原始音频信号;
对当前帧的原始音频信号进行快速傅里叶变换,得到频域信号,再基于预设的截止频率对所述频域信号进行低通滤波,得到原始低频信号;
根据预设的第一虚拟低音处理方式(基于硬件实现,即传统的虚拟低音处理方式),对当前帧的原始音频信号进行第一虚拟低音处理,得到第一虚拟低音信号;
对当前帧的原始低频信号和第一虚拟低音信号相加,得到当前帧的第一重构虚拟低音信号;
将当前帧的原始音频信号作为一个训练样本数据,并将当前帧的第一重构虚拟低音信号作为该训练样本的目标数据,得到第一训练数据集;
步骤202:基于第一训练数据集对初始虚拟低音生成网络进行第一网络参数训练:
将当前训练样本数据xi分别输入生成器gx→y和判别器dx;
训练样本数据经生成器gx→y得到生成音频gx→y(xi),再将生成音频gx→y(xi)分别输入生成器gy→x和判别器dy;
所述生成音频gx→y(xi)经生成器gy→x得到生成音频gy→x(gx→y(xi));
将当前训练样本数据的目标数据yi分别输入判别器dy和生成器gy→x,目标数据yi经生成器gy→x得到生成音频gy→x(yi);
将所述生成音频gy→x(yi)分别输入生成器gx→y和判别器dx,生成音频g(y)经生成器gx→y得到生成音频gx→y(gy→x(yi));
其中,判别器dx用于判决生成音频gy→x(yi)与训练样本数据xi之间是否存在的差异,判别器dy用于判决gx→y(xi)与目标数据yi之间是否存在的差异;
训练时,所采用的损失函数为lfull:
lfull=ladv(gx→y,dy) ladv(gy→x,dx) λcyclcyc(gx→y,gy→x) λidlid(gx→y,gy→x)
其中,λcyc和λid分别表示损失函数lcyc(gx→y,gy→x)和lid(gx→y,gy→x)的权重;
损失函数
损失函数
损失函数
损失函数
其中,e[]表示数学期望,pdata()表示括号中对象的分布,dy(yi)表示判别器对真实目标样本的打分,dy(gx→y(xi))表示判别器对生成目标样本的打分,dx(xi)表示判别器对真实原始样本的打分,dx(gy→x(yi))表示判别器对生成原始样本的打分,||||1表示l1范数;
当满足预设的第一网络参数训练的收敛条件时,将生成器gx→y作为虚拟低音生成网络;
步骤3:对待转换的原始音频信号进行分帧后对单帧进行快速傅里叶变换,以使得到的单帧数据与步骤2训练得到的虚拟低音生成网络的输入相匹配;
再将各帧数据输入所述虚拟低音生成网络,得到当前帧的网络输出信号;
对各帧的网络输出信号进行高通滤波处理得到各帧的虚拟低音数据,按单帧数据的时序对快速逆傅里叶变换后的单帧虚拟低音数据进行拼接,得到对应待转换的原始音频信号的虚拟低音信号。
进一步的,本发明的步骤2还包括:
步骤201还包括,将原始音频信号集分为两部分,其中一部分的数据量大于另一部分,并将数量较大的部分记为第一原始音频信号子集,数据量较小的部分记为第二原始音频信号子集;
步骤202中,仅对第一原始音频信号子集中的各原始音频信号进行第一虚拟低音处理,得到第一虚拟低音信号;并且当满足预设的第一网络参数训练的收敛条件时,执行步骤203;
所述步骤203包括:
设置第二训练数据集:
根据预设的第二虚拟低音处理方式(基于混合虚拟低音调参实现,如对现有的混合虚拟低音的参数进行人工调整),对第二原始音频信号子集进行第二虚拟低音处理,得到当前帧的第二虚拟低音信号;并对当前帧的原始低频信号和第二虚拟低音信号相加,得到当前帧的第二重构虚拟低音信号;
将当前帧的原始音频信号作为一个训练样本数据,将当前帧的第二重构虚拟低音信号作为该训练样本的目标数据,得到第二训练数据集;
设置第二训练数据集对步骤202训练后的初始虚拟低音生成网络进行第二网络参数训练(即迁移学习),训练时,数据处理过程与步骤202相同,变化的是训练样本数据;
即训练时采用的损失函数为lfull,当满足预设的第二网络参数训练的收敛条件时,将生成器gx→y作为虚拟低音生成网络。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
经本发明生成的虚拟低音的时域波形与传统方法生成虚拟低音的时域波形在低音轮廓上近乎一致。本发明可以极大的缩减信号处理过程中所需时间,克服了虚拟低音技术实时性不足的缺陷,进一步拓展了其适用范围。此外,传统虚拟低音技术需要进行繁琐的参数设置和调整,而本发明则仅仅基于所训练好的虚拟低音生成网络即可,无需每次生成虚拟低音时都进行繁琐的参数设置和调整,即将原始音频信号输入至所训练好的虚拟低音生成网络,基于其输出则可得到对应的虚拟低音信号。
附图说明
图1为传统虚拟低音处理流程;
图2为具体实施方式中,采用cyclegan网络处理音频数据的处理过程示意图;
图3为具体实施方式中,正反向网络循环一致性损失的示意图;
图4为具体实施方式中,本发明的虚拟低音生成方法处理流程图;
图5为具体实施方式中,原始信号的时域波形;
图6为具体实施方式中,通过对抗网络生成虚拟低音信号的时域波形;
图7为具体实施方式中,通过传统方法处理生成虚拟低音信号的时域波形。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
在本发明中,所采用的生成网络是为了学习一个从输入x输出y的映射关系。对于每一个输入音频xi∈x,本发明都能找到一个对应的样本yi∈y。其中,i代表一组平行数据的序号,x表示输入数据数据所在的特征空间,y表示输出数据所在的特征空间。
参考图2,本具体实施方式中,训练时,采用cyclegan网络处理音频数据的处理过程为:
将原始音频x输入生成器generatorgx-y得到生成音频g(x),再将生成音频g(x)输入生成器generatorgy-x,从而得到生成音频cyclicx;将传统方法生成音频y输入到生成器generatorgy-x得到生成音频g(y),再将生成音频g(y)输入生成器gx-y,从而得到生成音频cyclicy。同时将原始音频x和生成音频g(y)输入判别器dx,用于判别两者的区别并输出;以及同时将生成音频g(x)和音频y输入输入判别器dy,用于判别两者的区别并输出。
其中,采用的损失函数主要由对抗损失(adversarialloss)和循环一致性损失(cycle-consistencyloss)两部分组成。
对抗损失作为度量转换数据gx→y(xi)与目标数据yi之间的区别的一个重要参数,可以表示为:
其中,gx→y表示从x到y的映射函数,即从x到y的生成器,gx→y()表示生成器gx→y()的输出,即生成器输出的生成音频,dy表示关于y的判别器,判别器dy的输出表示为dy(),e[]表示数学期望,pdata()表示括号中对象的分布。即gx→y(xi))表示生成器gx→y将试图生成一段新的音频信号g(xi),使其听起来像它对应的经过虚拟低音技术预处理过后的音频yi,于此同时,判别器dy将试图去区分生成的音频信号g(xi)和实际信号yi之间的差异,此关系可以用数学表达式表示为:
其中,gy→x表示从y到x的生成器,其生成输出表示为gy→x();dx表示关于x的判别器,其输出表示为dx()。
由于对抗性损失的局限性,即无法保证神经网络能将单个输入的xi映射到期望的输出yi上。所以,为了进一步缩小可能的映射的空间,cyclegan网络通过引入循环一致性损失来保证映射函数(mappingfunction)gx→y和gy→x应当是循环一致(cycle-consistent)的,如图3所示。
本发明将这个关系表达如下:
其中,||||1表示l1范数。
此外,为了保证语言信息的完整性,现有的cycleganvc中通过引入lid来表示映射损失(identity-mappingloss):
综上所述,本发明结合(1)-(4)式,设置网络的总损失函数lfull为:
lfull=ladv(gx→y,dy) ladv(gy→x,dx) λcyclcyc(gx→y,gy→x) λidlid(gx→y,gy→x)(5)
其中,λcyc和λid为两个权重参数,用于调控循环一致性损失lcyc和映射损失lid对网络总损失lfull的相对重要性。
当网络收敛时(训练次数达到预设的最大训练次数,或者网络的总损失达到指定值),可将待处理的音频数据输入生成器generatorgx-y,进而基于其输出得到转换后的虚拟低音数据。
参见图4,本发明基于上述对网络的设置处理,基于所设置的生成对抗网络生成虚拟低音的具体处理为:
训练集数据预处理:
为了提升生成音频的质量,并且尽可能缩短训练所需要的时间。
本发明首先从原数据(原始音频信号x[n])中随机抽取了100条样本作为测试数据,它们将不参与训练。
接着,在剩下的数据按照7:1的比例分成一大一小两个数据集,然后将大数据集,也就是大部分数据,用默认参数设置生成虚拟低音(如图1所示的方式),得到输出xdi[n]。将其余的小部分数据,使用调整过后的参数生成虚拟低音,得到输出xai[n]。
其中,调整过后的参数生成虚拟低音可以是:谐波生成器采用的非线性方程从指数修改为反正切平方根;以及提高相位声码器(pv)最高谐波分量(startharm)来确保能够产生满足要求的高频谐波。
即本发明实施例中,为了提升网络的准确性,分别采用基于非线性元件和调参后的混合虚拟低音方式来得到两组训练数据集,该两组训练数据集对应生成网络的第一和第二网络参数训练,其中第一网络参数训练即为常规训练,第二网络参数训练即为迁移学习训练。且在两种获取虚拟低音的方式中,混合虚拟低音的准确性高于基于非线性元件系统的方式,将准确度较高方式获取的虚拟低音作为迁移学习时的生成音频y,准确度较低的方式获取的虚拟低音作为第一网络参数训练时的生成音频y。
接着,对xdi[n]和xai[n]进行快速傅里叶变换(fastfouriertransform,fft)可以得到xdi[k]和xai[k]。本实施例中的截至频率(cutofffrequency)fcutoff=120hz,所有音频的采样率(samplingrate)都调整为8000hz,单个音频帧长为32ms。需要说明的是,本实例中,将音频样本中低于截至频率120hz的频率分量为低频分量xl。
然后,对单个音频样本的一帧x[n]进行快速傅里叶变换,得到频域信号x[k],并将频域信号x[k]中的对应低频分量xli[k]提取出来(小于截止频率的频段),并与xai[k]以及xdi[k]相加后获得两个最终数据集的目标生成信号,这一步是为了补充xai[k]以及xdi[k]缺失的低频部分方便网络的收敛。由于低频部分在截止频率以上的位置的值都为0,相加(对位相加)的目的就是为了将虚拟低音处理后的音频缺失的低频补上,从而能保证训练的时候网络不容易出数值问题。即本发明实施例中,将x[k]作为第一原始输入信号x,用于输入生成器generatorgx-y以获得生成音频g(x),以及将第一原始信号输入判别器dx,而将低频分量xli[k]与xdi[k]的相加结果作为其对应的目标虚拟低音信号,即传统方法得到的生成音频y,实现对生成网络的第一网络参数训练。以及将x[k]作为第二原始输入信号x,用于输入生成器generatorgy-x以获得生成音频g(y),而将xli[k]与xai[n]的相加结果作为其对应的真实音频,即调参后的混合虚拟低音方法得到的生成音频y,实现对生成网络的第二网络参数训练。
训练过程:首先,将大的数据集作为训练集,训练3轮,每轮300个epochs,本实例中,没有直接的使用整段音频信号,而是从成对的数据中分别抽取帧固定长度的数据段(afixed-lengthsegment)(256点)来进行训练。
此外,本实施例中,将λcyc和λid分别设置为10和5,λid仅存在于前104次迭代中用于引导网络训练,除此之外它将被置零,以进一步降低计算量。训练过程中,将优化器选择为adamoptimize,并将batchsize设置为1,生成器的学习率为0.0005,学习速率衰减等于2.5×10-9;判别器的学习率为0.0001,学习速率衰减为5×10-10。在每一轮最初的2×105次迭代中,使学习率保持初始值恒定不变,之后使学习率在迭代中呈现线性衰减,直到为0,以此来获得较好的收敛效果。在先前得到的模型的基础上,用小数据集(利用传统的人工调参的方法生成)进行迁移学习,进而获得最终的网络模型,将训练好的生成器gx-y作为最终的虚拟低音生成网路。
最后,将测试数据输入至训练好的虚拟低音生成网路,得到对应的网络输出信号,对网络输出信号进行高通滤波(滤掉低频部分),再进行频域到时域的还原,从而得到测试数据的虚拟低音信号。因为虚拟低音本质就是虽然没有低频但是听起来像是有低频,所以需要对网络输出信号进行高通滤波。
为了验证本发明的生成性能,使用预先分离的验证数据,将其分别用传统方法(混合虚拟低音)和本发明的生成网络进行虚拟低音处理,并将得到的虚拟低音数据中的低频分量移除后,从而得到用于验证虚拟低音转换性能的音频信号。生成的音频数据的时域波形分别如图7和6所示,与图5所示的原始信号以及传统方式进行对比,可以发现,经本发明生成的虚拟低音的时域波形与传统方法生成虚拟低音的时域波形在低音轮廓上近乎一致。尽管在音质方面有待提升,但是用传统方法处理一条10秒长度的音频需要消耗大约40秒,本发明处理一条相同长度音频信号仅需要大约3秒,因此本发明可以极大的缩减信号处理过程中所需时间,克服了虚拟低音技术实时性不足的缺陷,进一步拓展了其适用范围。此外,传统虚拟低音技术需要进行繁琐的参数设置和调整,对使用者的专业知识能力有一定要求,本发明巧妙跳过了这一过程,极大程度提升了虚拟低音技术的易用性和泛化能力,为这项技术大规模应用提供了一个可能的实现途径。综上可以看出,本发明所提出的音频信号处理方法具有可观的实际利用价值。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

