本发明涉及语音处理及深度学习技术领域,具体而言,涉及一种基于转音音符处理方法的歌唱合成方法及系统。
背景技术:
随着人民日益增长的文化精神需求,各种精神创作呈现出多元化、多样化以及巨量化的趋势,当前音乐创作的数量已经难以满足人民日益增长的精神需求,如何加快或者增多精神创作,成为创作者必然要面临的问题。随着ai技术的不断发展,ai通过提供服务的方式,不断辅助和加速创作者的工作。ai创作作为一个新兴的产业,结合了计算机的强劲计算能力和人类的创造天赋,成为了一个充满生命力的产业。
特别是音乐创作和音乐制作产业的不断发展,更需要快速的、高质量、多样的歌曲。歌曲的创作涉及旋律创作、歌词创作、编曲以及演唱,一首歌曲的乐谱往往由专人演唱,才能明确歌曲创作的质量,歌曲创作需要反复修改,也往往需要专人反复演唱,从而增加成本。ai技术和歌唱融合的歌唱合成技术,使得歌唱可以不依赖于专人,从而降低成本,增快歌曲的创作。
目前市面上有大量的歌唱合成系统文献,鲜有介绍如何处理转音。转音作为歌曲常用的技法,使得歌曲的演唱动听,情绪表达丰富,因而支持转音处理成为歌曲演唱合成的迫切需求。
技术实现要素:
本发明的目的在于提供基于转音音符处理方法的歌唱合成方法及系统,其包括转音音符处理方法以及支持转音的歌唱合成方法以及系统,转音音符处理方法对曲谱内的转音进行处理,使得歌唱合成系统合成的歌曲更生动。
本发明的实施例通过以下技术方案实现:
一种转音音符处理方法,其特征在于,包括如下步骤:
s1.采集曲谱特征离散数据,并将曲谱特征离散数据转化为对应的数值数据,构建音符的音素id值对应表;其中,曲谱特征离散数据包括音符音素、音符音高以及音符持续时间;将音符音素采用自然语言处理常见字符的方法,将音素id值化,并根据音素找出对应音素的音高数值以及持续时间数值,构建音素id值表。
s2.对转音音符进行处理,将转音音符与上一个普通音符的音素进行处理得到新转音音符的音素,再根据音素id值对应表查表得出相应的数值数据;
优选地,所述s2具体为:将转音音符邻近的上一个第一普通音符进行音素拆分,根据转音音符的波形特征,将第一普通音符的音素进行扩展,得到第一普通音符与转音音符融合的新转音音符音素,根据音素id值对应表,查表得出新转音音符音素数值、新转音音符持续时间数值以及新转音音符音高数值。此为转音音符处理方法方案一。
优选地,所述s2具体为:将转印音符邻近的上一个第一普通音符进行音素拆分,将转音音符作为一种额外信息加入至第一普通音符拆分后的音素末尾,得到新转音音符音素,将额外信息的持续时间置为0,根据音素id值对应表,查表得出新转音音符音素数值、新转音音符持续时间数值以及新转音音符音高数值。此为转音音符处理方法方案二。
优选地,所述s2具体为:选取转音音符的上个一个普通音符为第一个普通音符,同时进行任务一以及任务二,其中:
任务一:将第一普通音符进行音素拆分,根据音素id值对应表查表得到第一普通音符音素数值、第一普通音符持续时间数值以及第一普通音符音高数值;
任务二:将转音音符当做独立的第二普通音符,并为第二普通音符附上单音素,将第一普通音符的音素进行拆分,将单音素与第一普通音符音素进行合并得到新转音音符音素,根据音素id值对应表,查表得到新音符音素数值、新音符持续时间数值以及新音符音高数值;此为转音音符处理方法方案一。
一种支持转音的歌唱合成方法,采用如权利要求1-4任意一项转音音符处理方法,其包括如下步骤:
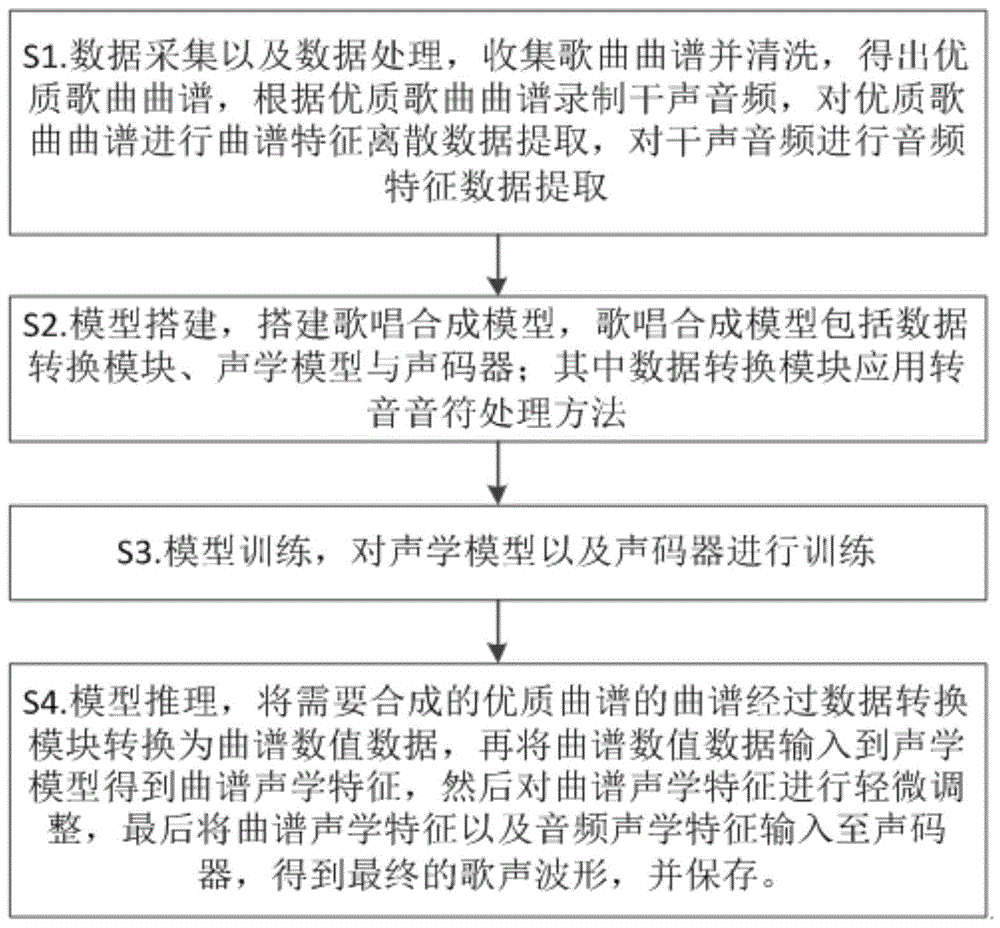
s1.数据采集以及数据处理:收集歌曲曲谱并根据收集的曲谱特征录制干声音频,分别提取歌曲曲谱的曲谱特征离散数据以及干声音频的音频特征数据;其中,收集歌曲曲谱后需对收集的歌曲曲谱根据清洗需求进行清洗,得到优质歌曲曲谱,对优质歌曲曲谱录制干声音频,具体清洗需求如下:
1.包含常见字的所有读音;
2.包含所需要的所有高音;
3.歌词与曲谱一一对应,且包括转音符号;
4.包含音符的持续时间。
然后对优质歌曲曲谱进行曲谱特征离散数据提取;对干声音频进行音频特征数据提取得出音频声学特征;对录制的干声音频进行数据分割,根据分割后的干声音频分割对应的曲谱特征离散数据以及音频特征数据;曲谱特征离散数据包括:音符音素、音符音高以及音符持续时间;
音符音素的提取:将曲谱数据各个音符对应的转为无声调的拼音,将拼音转为对应的音素,一个拼音由1-3个音素组成,转音用“-”符号表示;
音符音高的提取:确定中央c为c4或c3,并以数字60为中央c,将其他的音高转为对应的数值,数值以半音为单位;
音符持续时间的提取:将曲谱数据的音符持续时间提取成数组,根据帧长,将数据从以秒为单位转换为以帧为单位。
s2.模型搭建:构建歌唱合成模型,该模型包括用于转换曲谱特征离散数据以及对转音音符处理的数据转换模块、接收数据转换模块转换数据的声学模型以及接收声学模型输出的声学特征的声码器;其中,数据转换模块应用所述转音音符处理方法;
s3.模型训练:分别训练声学模型以及声码器,得到训练好的声学模型以及声码器;
s4.模型推理:将需要合成歌曲曲谱经过数据转换模块转换为曲谱数值数据,再将曲谱数值数据输入到声学模型得到曲谱声学特征,最后将曲谱声学特征以及音频声学特征输入至声码器,得到最终的歌声波形,并保存。
具体的,如上述所知,转音音符处理方法有三种方案:
其中,当使用的声码器为world声码器时,方可采用方案三,采用方案三后将任务一得出的第一普通音符音素数值、第一普通音符持续时间数值以及第一普通音符音高数值与任务二得出的新音符音素数值、新音符持续时间数值以及新音符音高数值分别输入至声学模型,分别得出声学特征。
采用方案一与方案二后,将方案一与方案二得出的新转音音符音素数值、新转音音符持续时间数值以及新转音音符音高数值输入至声学模型,得出曲谱声学特征,再将曲谱声学特征以及音频声学特征输入至声码器中,声码器运算得出波形。
优选地,所述音频特征数据提取包括如下步骤:
第一步,音量归一化处理,使得干声音频的音量一致;
第二步,提取干声音频的音频声学特征;基于模型搭建内使用的声码器不同,提取不同声码器所需的对应的音频声学特征;
第三步:对音频声学特征进行归一化处理,归一化处理后的音频声学特征以及曲谱声学特征一起输入至声码器中。
优选地,所述声码器的训练方法为:将曲谱数值数据作为输入,以曲谱声学特征作为输出,分割训练数据集和测试数据集来训练声学模型,训练直到声学模型loss收敛,中间每隔一定时间保存模型文件,选取测试数据集上与预设结果最接近的文件作为声学模型的训练结果。
优选地,所述声码器的训练方法为:调整声码器的参数,以曲谱声学特征以及音频声学特征为输入,以单声道干声波形为输出,进行训练直到声码器收敛,选取测试数据上与预设结果最接近的文件作为声码器的训练结果。
一种支持转音的歌唱合成系统,包括:
数据提取模块:用于采集歌曲曲谱以及干声音频,分别提取歌曲曲谱的曲谱特征离散数据以及干声音频的音频特征数据;
数据处理模块:将普通音符与转音音符的曲谱特征离散数据转换为对应的数值数据,输入声学模型中得出对应的曲谱声学特征;
歌曲合成模块:通过向声码器输入曲谱声学特征以及音频声学特征以合成歌唱波形。
一种支持转音的歌唱合成电子设备,包括处理器、存储器以及储存在所述存储器上并可被所述处理器执行的歌唱合成程序,所述歌唱合成程序被所述处理器执行时实现如权利要求5-8中任一项所述的歌唱合成方法的步骤。
本发明实施例的技术方案至少具有如下优点和有益效果:
本发明提供三种转音音符处理方法,通过处理转音音符以及上一个普通音符的音素,将转音音符同样输入至声学模型中,使得歌唱合成系统能够对转音音符处理,使得合成的歌曲更加生动。
附图说明
图1为本发明实施例1提供的支持转音的歌唱合成系统的流程图;
图2为本发明实施例1提供的曲谱特征数值化的示意图;
图3为本发明实施例1提供的转音音符处理方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
实施例1
如图1-3所示,一种转音音符处理方法,其特征在于,包括如下步骤:
s1.采集曲谱特征离散数据,并将曲谱特征离散数据转化为对应的数值数据,构建音符的音素id值对应表;其中,曲谱特征离散数据包括音符音素、音符音高以及音符持续时间;将音符音素采用自然语言处理常见字符的方法,将音素id值化,并根据音素找出对应音素的音高数值以及持续时间数值,构建音素id值表。
如图2所示:将音符“我”、“和”与“你”的进行音素拆分,再进行数字化处理得到音素id值,对应的音符音高的数值,在图2中:采用120bpm为时间单位,表示每秒120拍,即一个拍子为0.5秒,以15ms为一个单位,就换算得出每个音素对应的持续时间的数值。为方便计算,在本实施例中,采用5ms为一个单位。音素id值、音高数值以及持续时间数值构成音素id值对应表。
s2.对转音音符进行处理,将转音音符与上一个普通音符的音素进行处理得到新转音音符的音素,再根据音素id值对应表查表得出相应的数值数据;
所述s2具体为:将转音音符邻近的上一个第一普通音符进行音素拆分,根据转音音符的波形特征,将第一普通音符的音素进行扩展,得到第一普通音符与转音音符融合的新转音音符音素,根据音素id值对应表,查表得出新转音音符音素数值、新转音音符持续时间数值以及新转音音符音高数值。此为转音音符处理方法方案一。
所述s2具体为:将转印音符邻近的上一个第一普通音符进行音素拆分,将转音音符作为一种额外信息加入至第一普通音符拆分后的音素末尾,得到新转音音符音素,将额外信息的持续时间置为0,根据音素id值对应表,查表得出新转音音符音素数值、新转音音符持续时间数值以及新转音音符音高数值。此为转音音符处理方法方案二。
所述s2具体为:选取转音音符的上个一个普通音符为第一个普通音符,同时进行任务一以及任务二,其中:
任务一:将第一普通音符进行音素拆分,根据音素id值对应表查表得到第一普通音符音素数值、第一普通音符持续时间数值以及第一普通音符音高数值;
任务二:将转音音符当做独立的第二普通音符,并为第二普通音符附上单音素,将第一普通音符的音素进行拆分,将单音素与第一普通音符音素进行合并得到新转音音符音素,根据音素id值对应表,查表得到新音符音素数值、新音符持续时间数值以及新音符音高数值;此为转音音符处理方法方案一。
一种支持转音的歌唱合成方法,采用如权利要求1-4任意一项转音音符处理方法,其包括如下步骤:
s1.数据采集以及数据处理:收集歌曲曲谱并根据收集的曲谱特征录制干声音频,分别提取歌曲曲谱的曲谱特征离散数据以及干声音频的音频特征数据;其中,收集歌曲曲谱后需对收集的歌曲曲谱根据清洗需求进行清洗,得到优质歌曲曲谱,对优质歌曲曲谱录制干声音频,具体清洗需求如下:
1.包含常见字的所有读音;
2.包含所需要的所有高音;
3.歌词与曲谱一一对应,且包括转音符号;
4.包含音符的持续时间。
然后对优质歌曲曲谱进行曲谱特征离散数据提取;对干声音频进行音频特征数据提取得出音频声学特征;对录制的干声音频进行数据分割,根据分割后的干声音频分割对应的曲谱特征离散数据以及音频特征数据;曲谱特征离散数据包括:音符音素、音符音高以及音符持续时间;录制干声音频时,应当注意需要找专业的歌唱人员进行演唱,并在专业录音棚内录制,并不对声音进行美化和修音。录制时应当进行检查,对跑调的数据予以重录。
音符音素的提取:将曲谱数据各个音符对应的转为无声调的拼音,将拼音转为对应的音素,一个拼音由1-3个音素组成,转音用“-”符号表示;
音符音高的提取:确定中央c为c4或c3,并以数字60为中央c,将其他的音高转为对应的数值,数值以半音为单位;
音符持续时间的提取:将曲谱数据的音符持续时间提取成数组,根据帧长,将数据从以秒为单位转换为以帧为单位。
s2.模型搭建:构建歌唱合成模型,该模型包括用于转换曲谱特征离散数据以及对转音音符处理的数据转换模块、接收数据转换模块转换数据的声学模型以及接收声学模型输出的声学特征的声码器;其中,数据转换模块应用所述转音音符处理方法,采用转音音符处理方法对转音音符进行处理,得到新转音音符的曲谱特征数值,并输入至声学模型中;
s3.模型训练:分别训练声学模型以及声码器,得到训练好的声学模型以及声码器;
s4.模型推理:将需要合成的优质歌曲曲谱经过数据转换模块转换为曲谱数值数据,再将曲谱数值数据输入到声学模型得到曲谱声学特征,然后对曲谱声学特征进行轻微调整,最后将曲谱声学特征以及音频声学特征输入至声码器,得到最终的歌声波形,并保存。其中,曲谱声学特征包括f0、sp以及ap。
在本发明中,声学模型为将曲谱数据转为声学特征的深度学习模型,输出的声学特征为以帧为单位的浮点数特征。声学模型的核心特点为将较短的曲谱数据序列,转为较长的声学特征序列,从而实现歌唱合成的最基本步骤。声学模型往往由编码器、复制模块以及解码器三部分组成。编码器负责将曲谱数据编码成隐层向量;复制模块通过根据音符的持续时间,将曲谱信息的shape对齐到声学特征;解码器将对齐后的向量转换成声学特征。声学模型为现有技术。
声码器可以为基于gan的声码器,也可以为waveglow等基于wavenet的声码器,需保证声码器的采样率和hop_size等参数同声学模型。
声学模型往往由编码器、复制模块以及解码器三部分组成。编码器负责将曲谱数据编码成隐层向量;复制模块通过根据音符的持续时间,将曲谱信息的shape对齐到声学特征;解码器将对齐后的向量转换成声学特征
具体的,如上述所知,转音音符处理方法有三种方案:
其中,当使用的声码器为world声码器时,方可采用方案三,采用方案三后将任务一得出的第一普通音符音素数值、第一普通音符持续时间数值以及第一普通音符音高数值与任务二得出的新音符音素数值、新音符持续时间数值以及新音符音高数值分别输入至声学模型,分别得出声学特征。
采用方案一与方案二后,将方案一与方案二得出的新转音音符音素数值、新转音音符持续时间数值以及新转音音符音高数值输入至声学模型,得出曲谱声学特征,再将曲谱声学特征以及音频声学特征输入至声码器中,声码器运算得出波形。
在本实施例中,以第一普通音符“中”、转音音符“-”,得到“zhong-”音符,“c4e4”音高,“6633”持续时间曲谱序列为例,详细解释上述三个方案;
“中”拼音为“zhong”,音素为“zhuu_hng_h”。
方案一:“zhong”的音素表示为“zhuu_hng_h”,根据转音的波形特征,可以将中间的u_h拆分为两个不同音高的u_h,其音素应当表示为“zhuu_hu_hng_h”,再通过音素id值对应表,查表得到“zhong-”音符的音素id值、音高数值以及持续时间数值。
方案二:“zhong”的音素表示为“zhuu_hng_h”,将转音音符带入“zhong”的音素中表示为“zhuu_hng_h-”,再通过音素id值对应表,查表得到“zhong-”音符的音素id值、音高数值以及持续时间数值。
方案三:
任务一:“zhong”音素表示为“zhuu_hng_h”,查找音素id值对应表,获取数值化数据,音高表示为“606060,持续表示为“999999”。
任务二:将转音符号“-”当做独立音符“yi”,“yi”的音素表示为“yii_hi_h”,合并“zhong”音符以及“yi”音符的音素为“zhuu_hng_hyii_hi_h”,查找音素id值对应表得到音高表示为“606060626262,持续时间表示为“666666333333”。
将方案一中得出的“zhong-”音符的音素id值、音高数值以及持续时间数值输入至声学模型中,得到对应的曲谱声学特征:f0、sp以及ap。将f0、sp以及ap作为输入输入至声码器中,得出波形。
将方案二中得出的“zhong-”音符的音素id值、音高数值以及持续时间数值输入至声学模型中,得到对应的曲谱声学特征:f0、sp以及ap,将f0、sp以及ap作为输入输入至声码器中,得出波形。
将方案三中任务一得出的“zhong”音符的音素id值、音高数值以及持续时间数值输入至声学模型中,得到对应的曲谱声学特征:第一f0、第一sp以及第一ap;将方案三中任务二得出的“zhong-”音符的音素id值、音高数值以及持续时间数值输入至声学模型中,得到对应的第二f0、第二sp以及第二ap;选取第一sp、第一ap以及第二f0作为输入输入声码器中,得出波形。
所述音频特征数据提取包括如下步骤:
第一步,音量归一化处理,使得干声音频的音量一致;
第二步,提取干声音频的音频声学特征;基于模型搭建内使用的声码器不同,提取不同声码器所需的对应的音频声学特征;
第三步:对音频声学特征进行归一化处理,归一化处理后的音频声学特征以及曲谱声学特征一起输入至声码器中。
所述声码器的训练方法为:将曲谱数值数据作为输入,以曲谱声学特征作为输出,分割训练数据集和测试数据集来训练声学模型,训练直到声学模型loss收敛,中间每隔一定时间保存模型文件,选取测试数据集上与预设结果最接近的文件作为声学模型的训练结果。
所述声码器的训练方法为:调整声码器的参数,以曲谱声学特征以及音频声学特征为输入,以单声道干声波形为输出,进行训练直到声码器收敛,选取测试数据上与预设结果最接近的文件作为声码器的训练结果。
一种支持转音的歌唱合成系统,包括:
数据提取模块:用于采集歌曲曲谱以及干声音频,分别提取歌曲曲谱的曲谱特征离散数据以及干声音频的音频特征数据;
数据处理模块:将普通音符与转音音符的曲谱特征离散数据转换为对应的数值数据,输入声学模型中得出对应的曲谱声学特征;
歌曲合成模块:通过向声码器输入曲谱声学特征以及音频声学特征以合成歌唱波形。
一种支持转音的歌唱合成电子设备,包括处理器、存储器以及储存在所述存储器上并可被所述处理器执行的歌唱合成程序,所述歌唱合成程序被所述处理器执行时实现如权利要求5-8中任一项所述的歌唱合成方法的步骤。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

