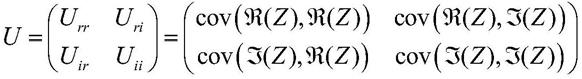
联合波束形成和深度复数u
‑
net网络的语音去混响方法
技术领域
1.本发明涉及语音去混响方法,尤其涉及一种联合波束形成和深度复数u
‑
net网络的语音去混响方法。
背景技术:
2.语音是人类最重要、最常用的交换信息的形式之一。近年来,随着计算机科学和模式识别技术的发展,语音成为人机交互的重要手段。由于房间墙壁和其他物体的反射,麦克风在封闭环境中接收到的信号是直达波和混响的叠加。混响会破坏语音的包络和谐波等结构,导致语音质量和清晰度下降。在存在混响的情况下,自动语音识别系统的性能可能会大大降低。因此,从复杂的声学环境中提取较为纯净的目标说话人语音,发展更为稳定高效的语音交互方式显得更为迫切。
3.由于混响和语音之间的高度相关性,混响是增强语音的一项艰巨任务。目前,混响方法可以分为两类:混响消除和混响抑制。前者与诸如声学脉冲响应的先验数据有关,如波束成形;而后者不需要上述先验数据,如多通道线性预测和深度学习方法。多麦克风波束形成接后置滤波是最传统的去混响方法。多通道线性预测方法在声学脉冲响应等未知的情况下可以实现有效的语音去混响,但是缺陷在于计算速度缓慢,不满足实时应用的需求。波束形成方法和通道线性预测方法共有的缺点在于在低信噪比条件下,去混响的效果会大幅度下降。近年来,得益于深度学习方法的成功,语音去混响方法实现了巨大的进步。基于深度神经网络、卷积神经网络的深度学习方法在语音去混响任务上取得了突破。而如何精简模型使其满足实时应用的需求,如何更加有效的实现去混响成为了最新的问题。
技术实现要素:
4.本发明针对语音去混响问题中现有深度学习方法的不足,提出一种联合波束形成和深度复数u
‑
net网络的语音去混响方法,联合波束形成和深度复数u
‑
net网络实现更高性能的去混响。
5.本发明的目的是通过以下技术方案来实现的:一种联合波束形成和深度复数u
‑
net网络的语音去混响方法,该方法包含以下步骤:
6.(1)使用mvdr波束形成器,对麦克风阵采集的多通道语音进行预处理,得到波束形成输出y
bf
;
7.(2)对随机一个麦克风信号进行短时傅里叶变换,得到输出y
mic
,并与波束形成输出y
bf
进行拼接;
8.(3)将步骤2拼接得到的语音频谱特征进行归一化处理,之后分别输入三个不同空洞率的空洞卷积层进行频带特征提取,实现频带注意力机制,得到输出特征x
in
;
9.(4)基于深度复数u
‑
net网络和输入特征x
in
预测复数值比率掩膜(complex
‑
valued ratio mask,crm),通过复数值比率掩膜与y
mic
相乘得到期望语音信号的频谱
10.(5)利用短时傅里叶逆变换处理网络的输出得到期望语音信号的时域表示
11.进一步地,所述步骤(1)具体实现如下:
12.记mvdr波束形成器的权向量的公式如下:
[0013][0014]
其中表示麦克风接收信号的协方差矩阵,表示麦克风q对应的房间冲激响应,(
·
)
h
表示转置操作,f表示频点;
[0015]
获得波束形成后的输出信号y
bf
,公式如下:
[0016][0017]
其中x(t,f)为麦克风接收信号的频域表示,t表示时间帧。
[0018]
进一步地,所述步骤(2)具体实现如下:
[0019]
步骤21,使用汉宁窗将随机一个麦克风信号分成一批时间帧;
[0020]
步骤22,对每一帧语音信号进行快速傅里叶变换fft,fft的输出为y
mic
(t,f);
[0021]
步骤23,将波束形成输出信号y
bf
与y
mic
进行拼接,输出为y
in
:
[0022]
y
in
=[y
bf
,y
mic
]
[0023]
进一步地,所述步骤(3)具体实现如下:
[0024]
对输入的特征y
in
进行归一化处理,之后分别输入三个不同空洞率的空洞卷积层进行频带特征提取,以高分辨率提取低频带,以中等的分辨率提取中频带,以最低的分辨率提取高频带;
[0025]
对每一个卷积层的输出使用批量归一化进行处理,再使用非线性整流单元(relu)进行非线性激活;
[0026]
最后将三个卷积层的输出在频率维度进行拼接,得到输出特征x
in
。
[0027]
进一步地,所述步骤(4)中,所述深度复数u
‑
net网络由一个编码器、一个解码器和镜像连接构成,输入特征为y
in
;
[0028]
所述编码器由五个复数卷积层构成,解码器由五个复数反卷积层和一个全连接层构成;所述解码器和编码器的镜像卷积层之间采取特征图维度的连接,即解码器每一复数反卷积层的输入特征通道数为上一复数反卷积层输出特征通道数的两倍,这是为了弥补编码器降采样过程带来的信息丢失;
[0029]
复数卷积层的操作为:
[0030]
z=w*y=(a
×
c
‑
b
×
d) i(b
×
c a
×
d)
[0031]
其中w=a ib为复数卷积滤波器,y=c id为复数卷积层的输入。
[0032]
复数卷积层的输出使用复数批量归一化进行处理,得到输出公式如下:
[0033]
[0034][0035]
其中ε表示均值计算,cov表示协方差计算,其中ε表示均值计算,cov表示协方差计算,分别表示z的实部和虚部。
[0036]
复数批量归一化的输出使用复数非线性整流单元(crelu)进行非线性激活,得到输出公式如下:
[0037][0038]
使用双曲正切函数(tanh)对网络输出进行非线性激活,得到估计的复数值比率掩膜
[0039]
获得估计的期望语音信号的频谱公式如下:
[0040][0041]
其中
⊙
表示矩阵点乘。
[0042]
进一步地,所述步骤(5)中,利用短时傅里叶逆变换处理网络的输出多帧信号进行拼接得到期望语音信号的时域表示实现语音去混响。
[0043]
本发明的有益效果是:本发明联合波束形成,对多通道语音信号进行预处理,有效提高信噪比;基于复数卷积操作,对期望语音信号的相位谱实现了有效的估计,进一步提升了去混响的性能。
附图说明
[0044]
图1为本发明实施例提供的联合波束形成和深度复数u
‑
net网络的语音去混响方法的结构图;
[0045]
图2为本发明实施例中对语音频谱特征进行频带特征提取的示意图;
[0046]
图3为本发明在仿真数据上的测试结果,其中,(a)混响语音的频谱,(b)本发明处理语音的频谱;
[0047]
图4为本发明在浙江大学玉泉校区某房间a实验数据上的测试结果,其中,(a)混响语音的频谱,(b)本发明处理语音的频谱。
[0048]
图5为本发明在浙江大学玉泉校区某房间b实验数据上的测试结果,其中,(a)混响语音的频谱,(b)本发明处理语音的频谱。
具体实施方式
[0049]
下面结合附图对本发明具体实施方式做进一步说明。
[0050]
如图1所示,本发明实施例提供的一种联合波束形成和深度复数u
‑
net网络的语音去混响方法的,具体实施方式如下:
[0051]
(1)使用mvdr波束形成器,对麦克风阵采集的多通道语音进行预处理,得到波束形成输出y
bf
;具体实现如下:
[0052]
记mvdr波束形成器的权向量的公式如下:
[0053][0054]
其中表示麦克风接收信号的协方差矩阵,表示麦克风q对应的房间冲激响应,(
·
)
h
表示转置操作,f表示频点;
[0055]
获得波束形成后的输出信号y
bf
,公式如下:
[0056][0057]
其中x(t,f)为麦克风接收信号的频域表示,t表示时间帧。
[0058]
(2)对随机一个麦克风信号x
mic
进行短时傅里叶变换,得到输出y
mic
,并与波束形成输出y
bf
进行拼接;具体实现如下:
[0059]
步骤21,使用汉宁窗将随机一个麦克风信号分成一批时间帧,本实施例中使用窗长为480、窗移为160的汉宁窗;
[0060]
步骤22,对每一帧语音信号进行快速傅里叶变换fft,fft的输出为y
mic
(t,f),本实施例中采用512点的fft;
[0061]
步骤23,将波束形成输出信号y
bf
与y
mic
进行拼接,输出为y
in
:
[0062]
y
in
=[y
bf
,y
mic
]
[0063]
(3)将步骤2拼接得到的语音频谱特征进行归一化处理,之后分别输入三个不同空洞率的空洞卷积层进行频带特征提取,实现频带注意力机制,得到输出特征x
in
;具体实现如下:
[0064]
对输入的特征y
in
进行归一化处理,之后分别输入三个不同空洞率的空洞卷积层进行频带特征提取,以高分辨率提取低频带,以中等的分辨率提取中频带,以最低的分辨率提取高频带;
[0065]
对每一个卷积层的输出使用批量归一化进行处理,再使用非线性整流单元(relu)进行非线性激活;
[0066]
最后将三个卷积层的输出在频率维度进行拼接,得到输出特征x
in
;
[0067]
如图2所示,本实施例中采用空洞率为1,2,4,卷积核大小为3*3,输出通道数为16的三个空洞卷积层。
[0068]
(4)基于深度复数u
‑
net网络和输入特征x
in
预测复数值比率掩膜,通过复数值比率掩膜与y
mic
相乘得到期望语音信号的频谱
[0069]
具体的,所述深度复数u
‑
net网络由一个编码器、一个解码器和镜像连接构成,输入特征为y
in
;所述编码器由五个复数卷积层构成,解码器由五个复数反卷积层和一个全连接层构成;
[0070]
本实施例中各结构的超参数如表1所示,空洞卷积层以“输入通道数*卷积核尺寸*输出通道数,空洞率”的格式给出,复数卷积层和复数反卷积的超参数以“输入通道数*卷积核尺寸*输出通道数,步长”的格式给出,全连接层的超参数以“输入节点数*输出节点数”的格式给出。
[0071]
表1:深度复数u
‑
net网络超参数表
[0072][0073]
所述解码器和编码器的镜像卷积层之间采取特征图维度的连接,即解码器每一复数反卷积层的输入特征通道数为上一复数反卷积层输出特征通道数的两倍,这是为了弥补编码器降采样过程带来的信息丢失;
[0074]
复数卷积层的操作为:
[0075]
z=w*y=(a
×
c
‑
b
×
d) i(b
×
c a
×
d)
[0076]
其中w=a ib为复数卷积滤波器,y=c id为复数卷积层的输入。
[0077]
复数卷积层的输出使用复数批量归一化进行处理,得到输出公式如下:
[0078][0079][0080]
其中ε表示均值计算,cov表示协方差计算,分别表示z的实部和虚部。
[0081]
复数批量归一化的输出使用复数非线性整流单元(crelu)进行非线性激活,得到输出公式如下:
[0082][0083]
使用双曲正切函数(tanh)对网络输出进行非线性激活,得到估计的复数值比率掩膜
[0084]
获得估计的期望语音信号的频谱公式如下:
[0085][0086]
其中
⊙
表示矩阵点乘。
[0087]
(5)利用短时傅里叶逆变换处理网络的输出多帧信号进行拼接得到期望语音信号的时域表示实现语音去混响。
[0088]
上述网络模型构建完成后,需要基于大量的训练数据进行模型的迭代优化。混响语音训练集使用了thchs
‑
30开源语料的训练子集,时长共109小时,混响时间为150
‑
600ms,信噪比为0
‑
30db,采样率为16khz。本发明提出的方法基于pytorch 1.3.1实现,初始学习率
设置为0.001,adam优化器用于调整学习率,批大小为4。在每一批中,所有的训练样本都通过补零来保持同样的长度。最后,网络训练的步数为500,000步。
[0089]
网络训练时使用尺度不变的信号失真比(scale invariant signal
‑
to
‑
distortion ratio,si
‑
sdr)作为损失函数,si
‑
sdr由下式表示:
[0090][0091]
申请人通过实验验证了本发明提出方法的去混响效果,为了评价去混响后语音的质量、可懂度以及失真情况,使用语音混响调制能量比(speech
‑
to
‑
reverberation modulation energy ratio,srmr)、语音感知质量评估(perceptual evaluation of speech quality,pesq)和短时客观可懂度(short
‑
time objective intelligibility,stoi)来评估去混响语音。所用测试集分为两部分,一是thchs
‑
30数据集中的测试子集,二是在浙江大学玉泉校区信电楼a室、b室采集的混响语音数据,测试集具体参数如表2所示。
[0092]
图3展示了thchs
‑
30测试样例的测试结果,图4展示了浙江大学玉泉校区信电楼a室的实验结果,图5展示了浙江大学玉泉校区信电楼b室的实验结果。表3
‑
表6展示了本发明提出的方法在上述测试集上的测试结果,测试结果表明,本发明提出的方法不仅可以在仿真测试集上取得很好的语音去混响效果,在真实环境中,不同混响时间和信噪比的情况下,本发明提出的方法也可以实现较好的语音去混响,具备较好的去混响鲁棒性。另外,申请人进行主观听音时发现,该方法处理过的语音具有很好的可懂度和质量,听起来比较舒适。
[0093]
表2:语音去混响测试集
[0094][0095]
表3:语音去混响仿真结果
[0096]
指标srmr(db)pesqstoi混响语音5.782.410.74去混响语音13.623.130.89
[0097]
表4:不同声源距离的语音去混响仿真结果
[0098][0099]
表5:不同混响时间的语音去混响仿真结果
[0100][0101]
表6:语音去混响实验结果
[0102][0103]
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的优选实施例子,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

