1.本发明属于语音识别技术领域,具体涉及到一种基于先验概率的声学解码方法。
背景技术:
2.在基于统计的语音识别系统中,一般用隐马尔可夫模型(hmm:hidden markov model)描述每个语音单元(音节)特征向量的分布。在识别阶段,用每个音节的hmm计算当前语音特征向量的概率,并将输出概率最大的hmm对应的音节作为识别结果。
3.在实验室安静环境中,基于统计的语音识别系统可以取得很高的识别率。但是,语音的高频能量较小,容易受到环境噪声的干扰。因此,用实验室环境中得到的纯净语音声学模型对实际环境中提取的含噪语音特征向量进行声学解码时,有可能出现前几个似然值比较接近的情况,这时将最大似然值对应的音节作为识别结果,很有可能导致误判。实际上,语音识别系统的各音节之间不是独立的,它们存在着某种转移关系,从而导致声学解码的精度不高。
技术实现要素:
4.发明目的:针对现有技术中存在的问题,本发明提供一种基于先验概率的声学解码方法,解决了声学解码精度不高的问题。
5.技术方案:本发明提出一种基于先验概率的声学解码方法,包括如下步骤:
6.(1)在训练阶段,将训练语音文本中的所有字都用音节代替,得到音节序列;
7.(2)统计训练语音文本音节序列中每个音节向其他音节转移的概率,得到音节上下文模型;
8.(3)用每个音节的全部训练语音进行模型训练,得到该音节的隐马尔可夫模型,所有音节的隐马尔可夫模型组成语音识别系统的声学模型;
9.(4)在识别阶段,用所述每个声学模型对当前语音特征向量计算输出概率,并将输出概率从大到小排序,存储前若干个概率值;
10.(5)读取上一个语音的声学模型输出概率值,若最大值远大于其他值,则用上一个语音的音节转移到每个音节的先验概率对声学模型的输出概率进行加权,并将加权概率最大的声学模型对应的音节作为当前语音声学解码的结果;否则,
11.若上一个语音的声学模型输出概率的最大值与后面的几个值比较接近,则不用音节转移的先验概率进行加权,直接用输出概率最大的声学模型对应的音节作为当前语音声学解码的结果。
12.进一步的,包括:
13.所述步骤(2)中,具体包括统计训练语音文本音节序列中每个音节向其他音节转移的先验概率,设音节a在训练语音中出现n次,其中,设音节w1在训练语音中出现n次,其中,有m次下一个音节是音节w2,则音节w1向音节w2转移的先验概率为所有音节
转移的先验概率构成所述音节上下文模型。
14.进一步的,包括:
15.所述步骤(3)用每个音节的全部训练语音进行模型训练之前先对训练语音进行预处理,包括加窗、分帧和快速傅里叶变换,然后提取训练语音和测试语音的美尔频率倒谱系数,将所述美尔顿率倒谱系数作为训练语音的特征向量。
16.进一步的,包括:
17.所述隐马尔可夫模型第i个状态的概率密度函数表示为:
[0018][0019]
其中,o
t
表示第t帧mfcc特征向量,c
im
、μ
im
和σ
im
分别表示第i个状态的第m个高斯单元的混合系数、均值向量和协方差矩阵,m表示每个状态的高斯混合数,d表示特征向量的维数。
[0020]
进一步的,包括:
[0021]
所述步骤(5)具体包括:
[0022]
(51)用每个音节的隐马尔可夫模型对当前测试语音的特征向量计算输出概率,并对所述输出概率取对数,得到每个隐马尔可夫模型的似然值l
j
,j=0,1,2
…
n
‑
1,其中,n是音节的数量;
[0023]
(52)将似然值从大到小排序,存储前q个音节的似然值,其中,q≥2,对当前语音进行声学解码时,读取上一个语音的隐马尔可夫模型的输出似然值;
[0024]
(53)如果其最大值远大于其他q
‑
1个值,则用音节转移的先验概率对隐马尔可夫模型的输出概率进行加权:
[0025][0026]
其中,p
ij
是上一个语音的识别结果;是加权后的输出概率似然值;
[0027]
否则,若上一个语音的hmm的输出概率最大值与其他q
‑
1个值中的前几个较大值比较接近,则令即不进行先验概率加权,直接用hmm的输出似然值进行声学解码;
[0028]
(54)比较得到的所有的大小,用最大值对应的音节作为声学解码的识别结果。
[0029]
有益效果:本发明与现有技术相比,其显著优点是:本发明在声学解码时,除了每个hmm的输出概率,还考虑上一个音节对当前语音的影响,将其作为当前语音的先验概率,可以提高声学解码的精度。
附图说明
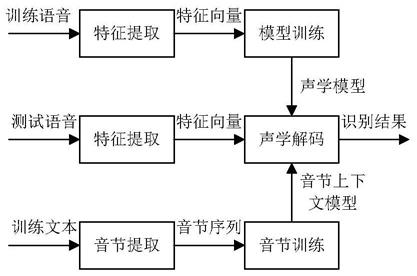
[0030]
图1为本发明所述的方法流程图。
具体实施方式
[0031]
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
[0032]
本发明设计了一种基于先验概率的声学解码方法,在该算法中,统计训练语音文本中每个音节向其他音节转移的概率,得到音节上下文模型;在声学解码时,用上一个语音的音节转移到每个音节的概率对每个hmm的输出概率进行加权,并将加权概率最大的hmm对应的音节作为当前语音声学解码的结果。
[0033]
如图1所示为基于先验概率的声学解码方法的总体框架,主要包括音节合并、音节训练、特征提取、模型训练和声学解码模块,
[0034]
该方法包括训练阶段和测试阶段,训练阶段首先采集训练语音文本,测试阶段采集测试语音文本,
[0035]
具体的,(1)在训练阶段,将训练语音文本中的所有字都用音节代替,得到音节序列;
[0036]
首先将汉语的所有音节编号,例如,音节wa编号为w1,然后将训练语音文本中的所有字都用其音节编号代替,得到若干个音节序列,每个音节序列对应训练语音文本的一句话。
[0037]
(2)统计训练语音文本音节序列中每个音节向其他音节转移的概率,得到音节上下文模型;
[0038]
设音节w1在训练语音中出现n次,其中,有m次下一个音节是音节w2,则音节w1向音节w2转移的先验概率为
[0039][0040]
所有音节转移的先验概率构成音节上下文模型,如下表所示:
[0041] 音节1音节2音节3 音节j 音节n音节1p
11
p
12
p
13
…
p
1j
…
p
1n
音节2p
21
p
22
p
23
…
p
2j
…
p
2n
音节3p
31
p
32
p
33
…
p
3j
…
p
3n
……………………
音节ip
i1
p
i1
p
i3
…
p
ij
…
p
in
……………………
音节np
n1
p
n2
p
n3
…
p
nj
…
p
nn
[0042]
其中,p
ij
表中音节i向音节j转移的概率,1≤i≤n,1≤j≤n。
[0043]
(3)对训练语音文本和测试语音文本进行预处理,包括加窗、分帧和快速傅里叶变换,提取训练语音和测试语音的美尔频率倒谱系数(mfcc:mel frequency cepstral coefficient),作为语音的特征向量。
[0044]
(4)用每个音节的全部训练语音进行模型训练,得到该音节的隐马尔可夫模型,所有音节的隐马尔可夫模型组成语音识别系统的声学模型;
[0045]
本发明用连续密度隐马尔可夫模型(hmm:hidden markov model)作为语音识别系统每个语音单元的声学模型,hmm的第i个状态的概率密度函数可以表示为:
[0046][0047]
其中,o
t
表示第t帧mfcc特征向量,c
im
、μ
im
和σ
im
分别表示第i个状态的第m个高斯
单元的混合系数、均值向量和协方差矩阵,m表示每个状态的高斯混合数,d表示特征向量的维数。
[0048]
(5)在识别阶段,用所述每个声学模型对当前语音特征向量计算输出概率,并将输出概率从大到小排序,存储前若干个概率值;
[0049]
(6)读取上一个语音的声学模型输出概率值,若最大值远大于其他值,则用上一个语音的音节转移到每个音节的先验概率对声学模型的输出概率进行加权,并将加权概率最大的声学模型对应的音节作为当前语音声学解码的结果;否则,
[0050]
若上一个语音的声学模型输出概率的最大值与后面的几个值比较接近,则不用音节转移的先验概率进行加权,直接用输出概率最大的声学模型对应的音节作为当前语音声学解码的结果。
[0051]
在声学解码中,首先用每个音节的hmm对当前测试语音的特征向量计算输出概率,并对输出概率取对数,得到每个hmm的似然值l
j
,j=0,1,2
…
n
‑
1,其中,n是hmm的数量,即音节的数量。
[0052]
然后,将似然值从大到小排序,存储前q个似然值,本实施例中存储前10个似然值,存储的似然值用于判断下一个语音是否需要概率加权。
[0053]
然后,对当前语音进行声学解码时,读取上一个语音的hmm输出似然值,如果其最大值远大于其他9个值,则用音节转移的先验概率对hmm的输出概率进行加权,远大于是指最大值对应的概率值超过0.9,似然值是概率值的对数。
[0054][0055]
其中,i是上一个语音的识别结果(音节序号);是加权后的输出概率似然值。如果上一个语音的hmm的输出概率最大值与其他9个值中的前几个较大值比较接近,则令:
[0056][0057]
即不进行先验概率加权,直接用hmm的输出似然值进行声学解码。这是因为此时上一个语音的解码结果不太可靠,如果用它进行概率加权,会带来较大的误差。
[0058]
最后,比较的大小,用最大值对应的音节作为声学解码的识别结果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

