1.本发明涉及音频转换领域,尤其涉及一种基于和弦的歌曲旋律生成方法、装置、设备及存储介质。
背景技术:
2.在正常情况下歌曲的创作是一个难度很高的任务,需要根据歌曲的综合效果以及创作人的灵感进行调整。随着人工智能技术的普及,直接利用人工智能技术生成歌曲成为了可能。因为歌曲创作是一种综合艺术,除了写词还要谱曲、演唱等多个环节逐步进行。
3.歌曲的生成需要考虑不同的音乐特征,音乐特征的表现形式也多种多样,而旋律是影响歌曲的最重要因素,现有方案生成的歌曲的旋律可听性低,旋律质量低。
技术实现要素:
4.本发明提供了一种基于和弦的歌曲旋律生成方法、装置、设备及存储介质,用于提高歌曲旋律质量,提高歌曲旋律的可听性,提高歌曲旋律的生成效率。
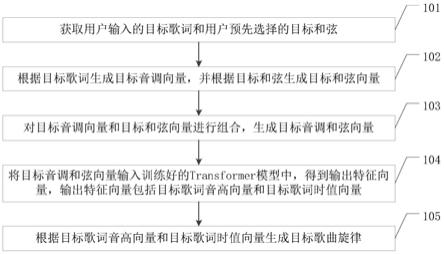
5.本发明实施例的第一方面提供一种基于和弦的歌曲旋律生成方法,包括:获取用户输入的目标歌词和所述用户预先选择的目标和弦;根据所述目标歌词生成目标音调向量,并根据所述目标和弦生成目标和弦向量;对所述目标音调向量和所述目标和弦向量进行组合,生成目标音调和弦向量;将所述目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,所述输出特征向量包括目标歌词音高向量和目标歌词时值向量;根据所述目标歌词音高向量和所述目标歌词时值向量生成目标歌曲旋律。
6.可选的,在本发明实施例第一方面的第一种实现方式中,在所述获取用户输入的目标歌词和所述用户预先选择的目标和弦之前,所述基于和弦的歌曲旋律生成方法还包括:获取预置的训练数据,所述预置的训练数据包括多首歌曲的数字乐谱;利用所述预置的训练数据对预置的初始模型进行训练得到transformer模型。
7.可选的,在本发明实施例第一方面的第二种实现方式中,所述利用所述预置的训练数据对预置的初始模型进行训练得到transformer模型,包括:从预置的训练数据获取多个数字乐谱,其中,每个数字乐谱用于指示一首歌曲的歌词、音调、和弦、音高和时值;从每首歌曲对应的数字乐谱中提取歌曲的音调信息、和弦信息、音高信息和时值信息;根据所述音调信息、和弦信息、音高信息和时值信息依次生成歌曲的音调向量t、和弦向量c、音高向量p和时值向量d,并将多首歌曲的音调向量t、和弦向量c、音高向量p和时值向量d分别进行组合得到音调向量序列t、和弦向量序列c、音高向量序列p和时值向量序列d;利用所述音调向量序列t、和弦向量序列c、音高向量序列p、时值向量序列d对所述预置的初始模型进行训练得到所述transformer模型。
8.可选的,在本发明实施例第一方面的第三种实现方式中,所述利用所述音调向量序列t、和弦向量序列c、音高向量序列p、时值向量序列d对所述预置的初始模型进行训练得到所述transformer模型,包括:将音调向量序列t=[t1,t2,t3,
…
,t
n
]与和弦向量序列c=
[c1,c2,c3,
…
,c
n
]进行组合,得到第一高维向量input,input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]];将音高向量序列p=[p1,p2,p3,
…
,p
n
]与时值向量序列d=[d1,d2,d3,
…
,d
n
]进行组合,得到第二高维向量output,output=[[p1,d1],[p2,d2],[p3,d3],
…
,[p
n
,d
n
];将所述第一高维向量input作为输入向量,将所述第二高维向量output作为输出向量,对所述预置的初始模型进行训练得到transformer模型。
[0009]
可选的,在本发明实施例第一方面的第四种实现方式中,所述从数字乐谱中提取歌曲的音调信息、和弦信息、音高信息和时值信息,包括:将多个数字乐谱转换为xml格式,每个数字乐谱对应一首歌曲;从xml格式的数字乐谱的中读取歌词信息,得到每个数字乐谱中的歌曲汉字;根据每个数字乐谱中的歌词汉字确定每个歌曲中每个字对应的音调信息和音高信息;根据每个数字乐谱确定对应的和弦信息及时值信息;生成多首歌曲对应的音调信息、和弦信息、音高信息和时值信息。
[0010]
可选的,在本发明实施例第一方面的第五种实现方式中,所述将所述第一高维向量input作为输入向量,将所述第二高维向量output作为输出向量,对所述预置的初始模型进行训练得到所述transformer模型,包括:将第一高维向量input输入到预置的初始模型中的编码组件中首端的编码器,所述编码组件包括多个依次连接的编码器,每个编码器包括多头注意力层和前馈网络层;将编码组件中末端的编码器输出的结果输入到解码组件中的每个多头注意力层,所述解码组件包括多个依次连接的解码器,每个解码器包括掩膜多头注意力层、多头注意力层和前馈网络层;将第二高维向量output输入到预置的初始模型中的解码组件中首端的编码器的掩膜多头注意力层;从解码组件中末端的编码器的输出结果输入到线性网络中,得到transformer模型。
[0011]
可选的,在本发明实施例第一方面的第六种实现方式中,所述根据所述目标歌词音高向量和所述目标歌词时值向量生成目标歌曲旋律包括:将目标歌词音高向量和目标歌词时值向量进行对齐;基于所述目标歌词音高向量生成目标歌词的旋律线;根据所述目标歌词时值向量生成目标歌词的节拍;根据所述目标歌词的旋律线和所述目标歌词的节拍,生成目标歌曲旋律。
[0012]
本发明实施例的第二方面提供了一种基于和弦的歌曲旋律生成装置,包括:获取模块,用于获取用户输入的目标歌词和所述用户预先选择的目标和弦;第一生成模块,用于根据所述目标歌词生成目标音调向量,并根据所述目标和弦生成目标和弦向量;组合模块,用于对所述目标音调向量和所述目标和弦向量进行组合,生成目标音调和弦向量;输入模块,用于将所述目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,所述输出特征向量包括目标歌词音高向量和目标歌词时值向量;第二生成模块,用于根据所述目标歌词音高向量和所述目标歌词时值向量生成目标歌曲旋律。
[0013]
可选的,在本发明实施例第二方面的第一种实现方式中,基于和弦的歌曲旋律生成装置还包括:数据获取模块,用于获取预置的训练数据,所述预置的训练数据包括多首歌曲的数字乐谱;训练模块,用于利用所述预置的训练数据对预置的初始模型进行训练得到transformer模型。
[0014]
可选的,在本发明实施例第二方面的第二种实现方式中,训练模块包括:乐谱获取单元,用于从预置的训练数据获取多个数字乐谱,其中,每个数字乐谱用于指示一首歌曲的歌词、音调、和弦、音高和时值;信息获取单元,用于从数字乐谱中提取歌曲的音调信息、和
弦信息、音高信息和时值信息;序列生成单元,用于根据所述音调信息、和弦信息、音高信息和时值信息依次生成歌曲的音调向量t、和弦向量c、音高向量p和时值向量d,并将多首歌曲的音调向量t、和弦向量c、音高向量p和时值向量d分别进行组合得到音调向量序列t、和弦向量序列c、音高向量序列p和时值向量序列d;模型训练单元,用于利用所述音调向量序列t、和弦向量序列c、音高向量序列p、时值向量序列d对所述预置的初始模型进行训练得到所述transformer模型。
[0015]
可选的,在本发明实施例第二方面的第三种实现方式中,模型训练单元具体包括:第一组合子单元,用于将音调向量序列t=[t1,t2,t3,
…
,t
n
]与和弦向量序列c=[c1,c2,c3,
…
,c
n
]进行组合,得到第一高维向量input,input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]];第二组合子单元,用于将音高向量序列p=[p1,p2,p3,
…
,p
n
]与时值向量序列d=[d1,d2,d3,
…
,d
n
]进行组合,得到第二高维向量output,output=[[p1,d1],[p2,d2],[p3,d3],
…
,[p
n
,d
n
];训练子单元,用于将所述第一高维向量input作为输入向量,将所述第二高维向量output作为输出向量,对所述预置的初始模型进行训练得到所述transformer模型。
[0016]
可选的,在本发明实施例第二方面的第四种实现方式中,信息获取单元具体用于:将多个数字乐谱转换为xml格式,每个数字乐谱对应一首歌曲;从xml格式的数字乐谱的中读取歌词信息,得到每个数字乐谱中的歌曲汉字;根据每个数字乐谱中的歌词汉字确定每个歌曲中每个字对应的音调信息和音高信息;根据每个数字乐谱确定对应的和弦信息及时值信息;生成多首歌曲对应的音调信息、和弦信息、音高信息和时值信息。
[0017]
可选的,在本发明实施例第二方面的第五种实现方式中,训练子单元具体用于:将第一高维向量input输入到预置的初始模型中的编码组件中首端的编码器,所述编码组件包括多个依次连接的编码器,每个编码器包括多头注意力层和前馈网络层;将编码组件中末端的编码器输出的结果输入到解码组件中的每个多头注意力层,所述解码组件包括多个依次连接的解码器,每个解码器包括掩膜多头注意力层、多头注意力层和前馈网络层;将第二高维向量output输入到预置的初始模型中的解码组件中首端的编码器的掩膜多头注意力层;从解码组件中末端的编码器的输出结果输入到线性网络中,得到transformer模型。
[0018]
可选的,在本发明实施例第二方面的第六种实现方式中,第二生成模块具体用于:将目标歌词音高向量和目标歌词时值向量进行对齐;基于所述目标歌词音高向量生成目标歌词的旋律线;根据所述目标歌词时值向量生成目标歌词的节拍;根据所述目标歌词的旋律线和所述目标歌词的节拍,生成目标歌曲旋律。
[0019]
本发明实施例的第三方面提供了一种基于和弦的歌曲旋律生成设备,存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;所述至少一个处理器调用所述存储器中的所述指令,以使得所述基于和弦的歌曲旋律生成设备执行上述的基于和弦的歌曲旋律生成方法。
[0020]
本发明实施例的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质存储有指令,当所述指令被处理器执行时实现上述任一实施方式所述的基于和弦的歌曲旋律生成方法的步骤。
[0021]
本发明实施例提供的技术方案中,获取用户输入的目标歌词和用户预先选择的目标和弦;根据目标歌词生成目标音调向量,并根据目标和弦生成目标和弦向量;对目标音调向量和目标和弦向量进行组合,生成目标音调和弦向量;将目标音调和弦向量输入训练好
的transformer模型中,得到输出特征向量,输出特征向量包括目标歌词音高向量和目标歌词时值向量;根据目标歌词音高向量和目标歌词时值向量生成目标歌曲旋律。本发明实施例,通过和弦、音高、音调和时值对初始的transformer模型进行训练,再通过训练好的transformer模型生成目标歌曲旋律,提高了歌曲旋律质量,提高了歌曲旋律的可听性,进而提高了歌曲旋律的生成效率。
附图说明
[0022]
图1为本发明实施例中基于和弦的歌曲旋律生成方法的一个实施例示意图;
[0023]
图2为本发明实施例中基于和弦的歌曲旋律生成方法的另一个实施例示意图;
[0024]
图3为本发明实施例中基于和弦的歌曲旋律生成装置的一个实施例示意图;
[0025]
图4为本发明实施例中基于和弦的歌曲旋律生成装置的另一个实施例示意图;
[0026]
图5为本发明实施例中基于和弦的歌曲旋律生成设备的一个实施例示意图。
具体实施方式
[0027]
本发明提供了一种基于和弦的歌曲旋律生成方法、装置、设备及存储介质,用于提高歌曲旋律质量,提高歌曲旋律的可听性,进而提高歌曲旋律的生成效率。
[0028]
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例进行描述。
[0029]
本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”或“具有”及其任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
[0030]
请参阅图1,本发明实施例提供的基于和弦的歌曲旋律生成方法的流程图,具体包括:
[0031]
101、获取用户输入的目标歌词和用户预先选择的目标和弦。
[0032]
服务器获取用户输入的目标歌词和用户预先选择的目标和弦,其中,目标歌词为用户输入的文字组合,目标和弦为用户在预置和弦中选择的目标和弦。其中,当用户输入自己想到的文字组合,将文字组合作为想要创作的歌曲的歌词,例如,目标歌词可以是“好好爱自己,就有人会爱你,这乐观的说词”。预置和弦包括三和弦、七和弦、主四六和弦、二级六和弦等,具体此处不再赘述。
[0033]
可以理解的是,本发明的执行主体可以为基于和弦的歌曲旋律生成装置,还可以是服务器,具体此处不做限定。本发明实施例以服务器为执行主体为例进行说明。
[0034]
102、根据目标歌词生成目标音调向量,并根据目标和弦生成目标和弦向量。
[0035]
服务器根据目标歌词生成目标音调向量,并根据目标和弦生成目标和弦向量。
[0036]
其中,目标歌词的长度不限定,例如,歌曲《难忘今宵》的歌词为“难忘今宵,难忘今宵,无论天涯与海角,神州万里同怀抱,共祝愿祖国好、祖国好,难忘今宵、难忘今宵,无论天
涯与海角,神州万里同怀抱,共祝愿祖国好、祖国好,共祝愿祖国好,共祝愿祖国好;告别今宵、告别今宵,无论新友与故交,明年春来再相邀,青山在人未老、人未老,青山在人未老,青山在人未老,共祝愿祖国好,共祝愿祖国好”,包括129个汉字;而歌曲《甜蜜蜜》的歌词为“甜蜜蜜你笑得甜蜜蜜,好像花儿开在春风里,开在春风里,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里,梦里梦里见过你,甜蜜笑得多甜蜜,是你、是你、梦见的就是你,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里;梦里梦里见过你,甜蜜笑得多甜蜜,是你、是你、梦见的就是你,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里”,包括179个汉字。
[0037]
需要说明的是,不同的歌曲,对应的歌词长度可能不同,对应的汉字个数也不同,生成的音调数量也不同,而一个和弦可以对应多个汉字(即出现重复和弦),以使得目标音调向量和目标和弦向量的长度是相同的,便于对齐,具体此处不再赘述。
[0038]
103、对目标音调向量和目标和弦向量进行组合,生成目标音调和弦向量。
[0039]
服务器对目标音调向量和目标和弦向量进行组合,生成目标音调和弦向量。
[0040]
具体的,将歌词的音调以及和弦组成更加高维的向量。例如,将音调向量序列t=[t1,t2,t3,
…
,t
n
]与和弦向量序列c=[c1,c2,c3,
…
,c
n
]进行组合,得到高维向的量input,input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]]。
[0041]
104、将目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,输出特征向量包括目标歌词音高向量和目标歌词时值向量。
[0042]
服务器将目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,输出特征向量包括目标歌词音高向量和目标歌词时值向量。
[0043]
例如,若输入向量为input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]],经过训练好的transformer模型,得到输出特征向量output=[[p1,d1],[p2,d2],[p3,d3],
…
,[p
n
,d
n
],将该向量包括音高向量p1,p2,p3,
…
,p
n
与时值向量d1,d2,d3,
…
,d
n
。
[0044]
105、根据目标歌词音高向量和目标歌词时值向量生成目标歌曲旋律。
[0045]
具体的,服务器将目标歌词音高向量和目标歌词时值向量进行对齐;服务器基于目标歌词音高向量生成目标歌词的旋律线;服务器根据目标歌词时值向量生成目标歌词的节拍;服务器根据目标歌词的旋律线和目标歌词的节拍,生成目标歌曲旋律。
[0046]
本发明实施例,通过和弦、音高、音调和时值对初始的transformer模型进行训练,再通过训练好的transformer模型生成目标歌曲旋律,提高了歌曲旋律质量,提高了歌曲旋律的可听性,进而提高了歌曲旋律的生成效率。并且本方案可应用于智慧教育领域中,从而推动智慧城市的建设。
[0047]
请参阅图2,本发明实施例提供的基于和弦的歌曲旋律生成方法的另一个流程图,具体包括:
[0048]
201、获取预置的训练数据,预置的训练数据包括多首歌曲的数字乐谱。
[0049]
服务器获取预置的训练数据,预置的训练数据包括多首歌曲的数字乐谱。
[0050]
需要说明的是,本实施例中数字乐谱至少包括歌词、音调、和弦、音高和时值,还可以包括其他音乐特征,例如,休止符、终止线、重音记号等,具体此处不做限定。
[0051]
可以理解的是,本发明的执行主体可以为基于和弦的歌曲旋律生成装置,还可以
是服务器,具体此处不做限定。本发明实施例以服务器为执行主体为例进行说明。
[0052]
例如,将歌曲《关键词》作为训练数据,那么需要确定该歌曲的数字乐谱,包括歌词“好好爱自己,就有人会爱你,这乐观的说词,幸福的样子,我感觉好真实,找不到形容词,沉默在掩饰,快泛滥的激情,只剩下语助词,有一种踏实,当你口中喊我名字,落叶的位置,谱出一首诗,时间在消逝,我们的故事开始,这是第一次,让我见识爱情,可以慷慨又自私,你是我的关键词,我不太确定,爱最好的方式,是动词或名词,很想告诉你,最赤裸的感情,却又忘词,聚散总有时,而哭笑也有时,我不怕潜台词,有一种踏实,是你心中有我名字,落叶的位置,谱出一首诗,时间在消逝,我们的故事开始,这是第一次,让我见识爱情,可以慷慨又自私,你是我的关键词,你藏在歌词,代表的意思,是专有名词,落叶的位置,谱出一首诗,我们的故事,才正要开始,这是第一次,爱一个人爱的,如此慷慨又自私,你是我的关键词”,还包括音调、音高、时值、和弦等信息。以第一句歌词“好好爱自己,就有人会爱你,这乐观的说词”为例,对应的音调分别为“3、3、4、4、3、4、3、2、4、4、3、4、4、1、0、1、2”,其中数字0、1、2、3、4分别表示汉字音调的轻声、第一声、第二声、第三声和第四声,对应的音高为“d5、e5、d5、e5、a4、e5、d5、e5、d5、e5、a4、e5、d5、e5、d5、e5、g4”,对应的时值分别为“0.25、0.25、0.25、0.25、0.5、0.5
‑
、0.25、0.25、0.25、0.25、0.5、0.5、0.25、0.25、0.25、0.25、1.0”,对应的和弦分别为“f、_、_、_、_、_、_、_、_、_、_、_、em、_、_、_、_、_”,对于剩下的歌词也有类似的对应关系,具体此处不再赘述。
[0053]
202、利用预置的训练数据对预置的初始模型进行训练得到transformer模型。
[0054]
具体的,服务器从预置的训练数据获取多个数字乐谱,其中,每个数字乐谱用于指示一首歌曲的歌词、音调、和弦、音高和时值;服务器从数字乐谱中提取歌曲的音调信息、和弦信息、音高信息和时值信息;服务器根据音调信息、和弦信息、音高信息和时值信息依次生成每首歌曲对应的音调向量t、和弦向量c、音高向量p和时值向量d,并将多首歌曲的音调向量t、和弦向量c、音高向量p和时值向量d分别进行组合得到音调向量序列t、和弦向量序列c、音高向量序列p和时值向量序列d;服务器利用音调向量序列t、和弦向量序列c、音高向量序列p、时值向量序列d对预置的初始模型进行训练得到transformer模型。
[0055]
可选的,服务器利用音调向量序列t、和弦向量序列c、音高向量序列p、时值向量序列d对预置的初始模型进行训练得到transformer模型具体包括:服务器将音调向量序列t=[t1,t2,t3,
…
,t
n
]与和弦向量序列c=[c1,c2,c3,
…
,c
n
]进行组合,得到第一高维向量input,input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]];服务器将音高向量序列p=[p1,p2,p3,
…
,p
n
]与时值向量序列d=[d1,d2,d3,
…
,d
n
]进行组合,得到第二高维向量output,output=[[p1,d1],[p2,d2],[p3,d3],
…
,[p
n
,d
n
];服务器将第一高维向量input作为输入向量,将第二高维向量output作为输出向量,对预置的初始模型进行训练得到transformer模型。
[0056]
可选的,服务器从数字乐谱中提取歌曲的音调信息、和弦信息、音高信息和时值信息具体包括:服务器将多个数字乐谱转换为xml格式,每个数字乐谱对应一首歌曲;服务器从xml格式的数字乐谱的中读取歌词信息,得到每个数字乐谱中的歌曲汉字;服务器根据每个数字乐谱中的歌词汉字确定每个歌曲中每个字对应的音调信息和音高信息;服务器根据每个数字乐谱确定对应的和弦信息及时值信息;服务器生成多首歌曲对应的音调信息、和弦信息、音高信息和时值信息。
[0057]
可选的,服务器将第一高维向量input作为输入向量,将第二高维向量output作为输出向量,对预置的初始模型进行训练得到transformer模型具体包括:服务器将第一高维向量input输入到预置的初始模型中的编码组件中首端的编码器,编码组件包括多个依次连接的编码器,每个编码器包括多头注意力层和前馈网络层;服务器将编码组件中末端的编码器输出的结果输入到解码组件中的每个多头注意力层,解码组件包括多个依次连接的解码器,每个解码器包括掩膜多头注意力层、多头注意力层和前馈网络层;服务器将第二高维向量output输入到预置的初始模型中的解码组件中首端的编码器的掩膜多头注意力层;服务器从解码组件中末端的编码器的输出结果输入到线性网络中,得到transformer模型。
[0058]
203、获取用户输入的目标歌词和用户预先选择的目标和弦。
[0059]
服务器获取用户输入的目标歌词和用户预先选择的目标和弦,其中,目标歌词为用户输入的文字组合,目标和弦为用户在预置和弦中选择的目标和弦。其中,当用户输入自己想到的文字组合,将文字组合作为想要创作的歌曲的歌词,例如,目标歌词可以是“好好爱自己,就有人会爱你,这乐观的说词”。预置和弦包括三和弦、七和弦、主四六和弦、二级六和弦等,具体此处不再赘述。
[0060]
204、根据目标歌词生成目标音调向量,并根据目标和弦生成目标和弦向量。
[0061]
服务器根据目标歌词生成目标音调向量,并根据目标和弦生成目标和弦向量。
[0062]
其中,目标歌词的长度不限定,例如,歌曲《难忘今宵》的歌词为“难忘今宵,难忘今宵,无论天涯与海角,神州万里同怀抱,共祝愿祖国好、祖国好,难忘今宵、难忘今宵,无论天涯与海角,神州万里同怀抱,共祝愿祖国好、祖国好,共祝愿祖国好,共祝愿祖国好;告别今宵、告别今宵,无论新友与故交,明年春来再相邀,青山在人未老、人未老,青山在人未老,青山在人未老,共祝愿祖国好,共祝愿祖国好”,包括129个汉字;而歌曲《甜蜜蜜》的歌词为“甜蜜蜜你笑得甜蜜蜜,好像花儿开在春风里,开在春风里,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里,梦里梦里见过你,甜蜜笑得多甜蜜,是你、是你、梦见的就是你,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里;梦里梦里见过你,甜蜜笑得多甜蜜,是你、是你、梦见的就是你,在哪里在哪里见过你,你的笑容这样熟悉,我一时想不起,啊、在梦里”,包括179个汉字。
[0063]
需要说明的是,不同的歌曲,对应的歌词长度可能不同,对应的汉字个数也不同,生成的音调数量也不同,而一个和弦可以对应多个汉字(即出现重复和弦),以使得目标音调向量和目标和弦向量的长度是相同的,便于对齐,具体此处不再赘述。
[0064]
205、对目标音调向量和目标和弦向量进行组合,生成目标音调和弦向量。
[0065]
服务器对目标音调向量和目标和弦向量进行组合,生成目标音调和弦向量。
[0066]
具体的,将歌词的音调以及和弦组成更加高维的向量。例如,将音调向量序列t=[t1,t2,t3,
…
,t
n
]与和弦向量序列c=[c1,c2,c3,
…
,c
n
]进行组合,得到高维向的量input,input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]]。
[0067]
206、将目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,输出特征向量包括目标歌词音高向量和目标歌词时值向量。
[0068]
服务器将目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,输出特征向量包括目标歌词音高向量和目标歌词时值向量。
[0069]
例如,若输入向量为input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]],经过训练好的transformer模型,得到输出特征向量output=[[p1,d1],[p2,d2],[p3,d3],
…
,[p
n
,d
n
],将该向量包括音高向量p1,p2,p3,
…
,p
n
与时值向量d1,d2,d3,
…
,d
n
。
[0070]
207、根据目标歌词音高向量和目标歌词时值向量生成目标歌曲旋律。
[0071]
具体的,服务器将目标歌词音高向量和目标歌词时值向量进行对齐;服务器基于目标歌词音高向量生成目标歌词的旋律线;服务器根据目标歌词时值向量生成目标歌词的节拍;服务器根据目标歌词的旋律线和目标歌词的节拍,生成目标歌曲旋律。
[0072]
本发明实施例,通过和弦、音高、音调和时值对初始的transformer模型进行训练,再通过训练好的transformer模型生成目标歌曲旋律,提高了歌曲旋律质量,提高了歌曲旋律的可听性,进而提高了歌曲旋律的生成效率。并且本方案可应用于智慧教育领域中,从而推动智慧城市的建设。
[0073]
上面对本发明实施例中基于和弦的歌曲旋律生成方法进行了描述,下面对本发明实施例中基于和弦的歌曲旋律生成装置进行描述,请参阅图3,本发明实施例中基于和弦的歌曲旋律生成装置的一个实施例包括:
[0074]
获取模块301,用于获取用户输入的目标歌词和所述用户预先选择的目标和弦;
[0075]
第一生成模块302,用于根据所述目标歌词生成目标音调向量,并根据所述目标和弦生成目标和弦向量;
[0076]
组合模块303,用于对所述目标音调向量和所述目标和弦向量进行组合,生成目标音调和弦向量;
[0077]
输入模块304,用于将所述目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,所述输出特征向量包括目标歌词音高向量和目标歌词时值向量;
[0078]
第二生成模块305,用于根据所述目标歌词音高向量和所述目标歌词时值向量生成目标歌曲旋律。
[0079]
本发明实施例,通过和弦、音高、音调和时值对初始的transformer模型进行训练,再通过训练好的transformer模型生成目标歌曲旋律,提高了歌曲旋律质量,提高了歌曲旋律的可听性,进而提高了歌曲旋律的生成效率。并且本方案可应用于智慧教育领域中,从而推动智慧城市的建设。
[0080]
请参阅图4,本发明实施例中基于和弦的歌曲旋律生成装置的另一个实施例包括:
[0081]
获取模块301,用于获取用户输入的目标歌词和所述用户预先选择的目标和弦;
[0082]
第一生成模块302,用于根据所述目标歌词生成目标音调向量,并根据所述目标和弦生成目标和弦向量;
[0083]
组合模块303,用于对所述目标音调向量和所述目标和弦向量进行组合,生成目标音调和弦向量;
[0084]
输入模块304,用于将所述目标音调和弦向量输入训练好的transformer模型中,得到输出特征向量,所述输出特征向量包括目标歌词音高向量和目标歌词时值向量;
[0085]
第二生成模块305,用于根据所述目标歌词音高向量和所述目标歌词时值向量生成目标歌曲旋律。
[0086]
可选的,基于和弦的歌曲旋律生成装置还包括:
[0087]
数据获取模块306,用于获取预置的训练数据,所述预置的训练数据包括多首歌曲
的数字乐谱;
[0088]
训练模块307,用于利用所述预置的训练数据对预置的初始模型进行训练得到transformer模型。
[0089]
可选的,训练模块307包括:
[0090]
乐谱获取单元3071,用于从预置的训练数据获取多个数字乐谱,其中,每个数字乐谱用于指示一首歌曲的歌词、音调、和弦、音高和时值;
[0091]
信息获取单元3072,用于从数字乐谱中提取歌曲的音调信息、和弦信息、音高信息和时值信息;
[0092]
序列生成单元3073,用于根据所述音调信息、和弦信息、音高信息和时值信息依次生成歌曲的音调向量t、和弦向量c、音高向量p和时值向量d,并将多首歌曲的音调向量t、和弦向量c、音高向量p和时值向量d分别进行组合得到音调向量序列t、和弦向量序列c、音高向量序列p和时值向量序列d;
[0093]
模型训练单元3074,用于利用所述音调向量序列t、和弦向量序列c、音高向量序列p、时值向量序列d对所述预置的初始模型进行训练得到所述transformer模型。
[0094]
可选的,模型训练单元3074包括:
[0095]
第一组合子单元30741,用于将音调向量序列t=[t1,t2,t3,
…
,t
n
]与和弦向量序列c=[c1,c2,c3,
…
,c
n
]进行组合,得到第一高维向量input,input=[[t1,c1],[t2,c2],[t3,c3],
…
,[t
n
,c
n
]];
[0096]
第二组合子单元30742,用于将音高向量序列p=[p1,p2,p3,
…
,p
n
]与时值向量序列d=[d1,d2,d3,
…
,d
n
]进行组合,得到第二高维向量output,output=[[p1,d1],[p2,d2],[p3,d3],
…
,[p
n
,d
n
];
[0097]
训练子单元30743,用于将所述第一高维向量input作为输入向量,将所述第二高维向量output作为输出向量,对所述预置的初始模型进行训练得到所述transformer模型。
[0098]
可选的,信息获取单元3072具体用于:
[0099]
将多个数字乐谱转换为xml格式,每个数字乐谱对应一首歌曲;从xml格式的数字乐谱的中读取歌词信息,得到每个数字乐谱中的歌曲汉字;根据每个数字乐谱中的歌词汉字确定每个歌曲中每个字对应的音调信息和音高信息;根据每个数字乐谱确定对应的和弦信息及时值信息;生成多首歌曲对应的音调信息、和弦信息、音高信息和时值信息。
[0100]
可选的,训练子单元30743具体用于:
[0101]
将第一高维向量input输入到预置的初始模型中的编码组件中首端的编码器,所述编码组件包括多个依次连接的编码器,每个编码器包括多头注意力层和前馈网络层;将编码组件中末端的编码器输出的结果输入到解码组件中的每个多头注意力层,所述解码组件包括多个依次连接的解码器,每个解码器包括掩膜多头注意力层、多头注意力层和前馈网络层;将第二高维向量output输入到预置的初始模型中的解码组件中首端的编码器的掩膜多头注意力层;从解码组件中末端的编码器的输出结果输入到线性网络中,得到transformer模型。
[0102]
可选的,第二生成模块305具体用于:
[0103]
将目标歌词音高向量和目标歌词时值向量进行对齐;基于所述目标歌词音高向量生成目标歌词的旋律线;根据所述目标歌词时值向量生成目标歌词的节拍;根据所述目标
歌词的旋律线和所述目标歌词的节拍,生成目标歌曲旋律。
[0104]
本发明实施例,通过和弦、音高、音调和时值对初始的transformer模型进行训练,再通过训练好的transformer模型生成目标歌曲旋律,提高了歌曲旋律质量,提高了歌曲旋律的可听性,进而提高了歌曲旋律的生成效率。并且本方案可应用于智慧教育领域中,从而推动智慧城市的建设。
[0105]
上面图3至图4从模块化功能实体的角度对本发明实施例中的基于和弦的歌曲旋律生成装置进行详细描述,下面从硬件处理的角度对本发明实施例中基于和弦的歌曲旋律生成设备进行详细描述。
[0106]
图5是本发明实施例提供的一种基于和弦的歌曲旋律生成设备的结构示意图,该基于和弦的歌曲旋律生成设备500可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(central processing units,cpu)510(例如,一个或一个以上处理器)和存储器520,一个或一个以上存储应用程序533或数据532的存储介质530(例如一个或一个以上海量存储设备)。其中,存储器520和存储介质530可以是短暂存储或持久存储。存储在存储介质530的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对基于和弦的歌曲旋律生成设备500中的一系列指令操作。更进一步地,处理器510可以设置为与存储介质530通信,在基于和弦的歌曲旋律生成设备500上执行存储介质530中的一系列指令操作。
[0107]
基于和弦的歌曲旋律生成设备500还可以包括一个或一个以上电源540,一个或一个以上有线或无线网络接口550,一个或一个以上输入输出接口560,和/或,一个或一个以上操作系统531,例如windows serve,mac os x,unix,linux,freebsd等等。本领域技术人员可以理解,图5示出的基于和弦的歌曲旋律生成设备结构并不构成对基于和弦的歌曲旋律生成设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
[0108]
本发明还提供一种计算机可读存储介质,该计算机可读存储介质可以为非易失性计算机可读存储介质,该计算机可读存储介质也可以为易失性计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在计算机上运行时,使得计算机执行所述基于和弦的歌曲旋律生成方法的步骤。
[0109]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0110]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read
‑
only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0111]
以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前
述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

