本发明属于语音识别下的抑郁症检测领域,具体涉及一种谱减法降噪下多语音特征融合的抑郁症检测方法。
背景技术:
抑郁症是目前世界上最常见的精神疾病,已经成为全球范围内严重的公共卫生和社会问题,极大地损害了人类的身心健康,降低了人们的生活质量,给社会和个人造成了巨大的经济损失。现阶段,抑郁症主要是由专业医师在量表和问卷调查的基础上,结合自身经验对病人情况进行诊断。这种诊断模式严重依赖于医生的专业水平、病人的配合程度和病人对量表问题的理解程度,且费时费力,误诊率较高。随着深度学习的发展,越来越多的学者利用说话人的语音声学特征结合神经网络训练自动识别抑郁症,识别患者的精神状态。目前,自动郁抑症检测的方法可以分为两类:传统的机器学习方法和深度学习方法。传统机器学习方法选择梅尔频率倒谱系数(mfccs)、能量、过零率、共振峰特征、光谱特征等。提取特征后再采用诸如高斯混合模型(gmm)、支持向量回归(svr)等机器学习方法识别抑郁症。这种方法可以在不需要大量数据的情况下对模型进行训练,但可能会丢失一些关键特征,从而降低识别的准确性。而深度学习在提取高层语义特征上具有明显的优势,学者们设计cnn,lstm等网络来自动提取语音中和抑郁症相关的更深层次特征,取得了一定的研究进展。这些方法提取音频的mfccs特征、频谱图等特征输入到神经网络中,自动提取与抑郁症相关的深层次特征,最后进行决策分类。但是,并非所有的语音片段都包含与抑郁症相关的特征,比如静音和片段。这些语音片段不包含与抑郁症相关的特征,但是在训练过程中,将分类标签和整句的标签都设为抑郁症标签,降低了分类的准确率。因此,改进现有的抑郁症检测方法势在必行。
技术实现要素:
本发明的目的是基于上述技术现状,提供一种谱减法降噪下多语音特征融合的抑郁症检测方法。
一种谱减法降噪下多语音特征融合的抑郁症检测方法,其为利用抑郁症患者区别于正常人群的多种语音特征,构建多种语音特征融合的抑郁症检测方法,包括如下步骤:
步骤1:从抑郁数据集中获取语音信号样本以及对应样本标签的phq-8值,将其一一对应,并抽取一部分样本集合作为测试集,另一部分样本集合作为训练集;
步骤2:对语音信号进行分段处理,分离出被试者、虚拟采访者以及静默部分的语音部分,并去除后两项的语音部分,保留被试者的语音部分;
步骤3:对被试者的语音信号进行预处理,滤除噪声,增强语音信号;
步骤4:在步骤3增强的语音信号中提取mfcc特征、共振峰特征以及频谱图;
步骤5:将步骤4提取得到的mfcc特征、共振峰特征、频谱图融合输入改进的tcn模型中对训练集进行学习,得到训练模型;将测试集输入训练模型,输出其对应的phq-8值,并识别抑郁程度。
进一步,所述步骤2采用pyaudioanalysis模块对语音信号进行分段处理。
进一步,所述步骤3通过谱减法进行语音增强,具体步骤为:
(1)对抑郁者语音信号加汉明窗消去直流分量,带噪声语音信号y(n)表示为:
y(n)=p(n) d(n),0≤n≤n-1
其中p(n)为纯净信号,d(n)为噪声信号;
(2)将y(n)变换为频域表示:
yw(ω)=sw(ω) dw(ω)
其中,yw(ω),sw(ω),dw(ω)分别为y(n),s(n),d(n)的傅里叶变换,dw(ω)的傅里叶系数为nk,因此,
|yk|2=|sk|2 |nk|2 sk·nk* sk*·nk
其中,*表示复共轭,假定噪声与s(n)为不相关的,即互谱的统计均值为0,因此,
e[|yk|2]=e[|sk|2] e[|nk|2]
(3)采用发语音前的无声部分,通过多帧平均来估计噪声,如下:
|yk|2=|sk|2 λ(k)
其中,λ(k)为静默部分时|nk|2的统计平均值,即
(4)由第三步可得原始语音的估计值为:
(5)引入谱减功率修正系数m和谱减噪声系数
进一步,所述步骤4中提取mfcc特征的具体步骤为:
(1)预加重,通过一个高通滤波器来增强语音信号中的高频部分,并保持在低频到高频的整个频段中,能够使用同样的信噪比求频谱,选取的高通滤波器传递函数为:
s(n)=x(n)-a*x(n-1)
其中,x(n)为n时刻的采样频率,x(n-1)为上一时刻的采样频率,a为预加重系数,取值介于0.9-1.0之间,通常取a=0.97;
(2)加窗,使用汉明窗进行加窗处理,此处采样率为16khz,窗长25ms(400个采样点),窗间隔10ms(160个采样点),假设分帧后的信号为s(n),n=0,1,2…,n-1,其中n为帧的大小,进行加窗的处理则为:
(3)离散傅立叶变换(dft),得到频谱上的能量分布,dft的定义如下:
采用dft长度n=512,结果值保留前257个系数。
(4)使用梅尔刻度滤波器组过滤,对于快速傅里叶变换(fft)得到的幅度谱,分别跟每一个滤波器进行频率相乘累加,得到该滤波器对应频段的能量值;
(5)对每个滤波器产生的输出频谱能量取对数后便可得到系数sm,再利用dct将sm转换到时域,便就得到mfcc系数c(m):
其中,x(k)、h(k)分别是时域信号,将频域拆分为两部分时域信号,分别为x(k)、h(k)。
进一步,所述步骤4中提取共振峰的具体步骤为:
(1)对语音信号进行加窗分帧,计算浊音基音周期(1:nn)点;
(2)取倒谱的前1:nn点,加nn点汉明窗,对语音信号进行快速傅里叶变换(fft)及对数运算;
(3)将对数谱平滑处理,然后对峰值定位。
进一步,所述步骤4利用短时傅里叶变换获得频谱图,在傅立叶变换中,使用时间窗口函数g(t-u)与源信号分f(t)的相乘,实现在u附近的加窗口和平移,然后进行傅立叶变换,短时傅立叶变换如下:
gf(ε,u)=∫f(t)g(t-u)ejεtdt
t表示时间,ε为角频率,u为前u时间段内,t-u为从u时刻到t时刻,j为系数。
进一步,所述步骤5将mfcc特征、共振峰特征、频谱图融合输入改进的tcn模型中对训练集进行学习,具体步骤如下:
(1)特征输入,将mfcc特征、共振峰特征、频谱图输入到改进的tcn模型中,改进的tcn模型在temporal-block中添加了一个裁剪层(chomp),保证网络每一层的特征长度相等;
(2)模型训练,语音数据的输入通道为513,训练时使用adam优化器,训练20个epoch,dropout为0.05,batchsize为64,初始学习率为2e-2,通过二元交叉熵损失和均方误差(mse)回归更新参数;
(3)抑郁症判别,输出phq-8得分,用此得分进行分类和回归,判别被试者是否患抑郁症,若得分大于18,则分类为抑郁者,否则为正常人;通过phq-8得分和患者问卷调查结果对比,计算mse,评估该模型的可信度。
本发明的有益效果如下:
(1)本专利采用改进的谱减法,在语音增强上达到了良好的效果,很好地分离出抑郁症相关的特征,静音和片段。相比之前的卷积神经网路,在daic-woz数据集上,均方误差(mse)降低了18%,phq-8值预测准确率得到提升;
(2)多特征融合的抑郁症患者语音识别,更具有说服力,所选特征容易提取,计算量较小,节约内存,计算速度快。
附图说明
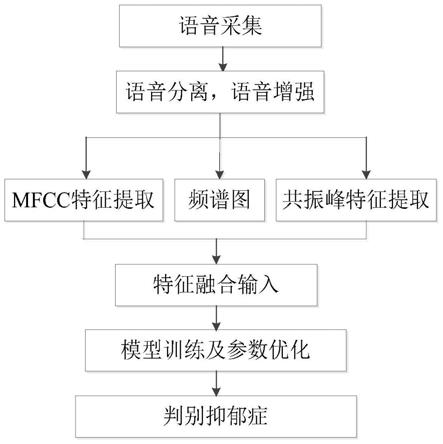
图1为抑郁症检测流程图;
图2为抑郁类语音增强实现框图法流程图;
图3为mfcc特征提取过程;
图4为共振峰提取框图;
图5为改进的tcn模型图;
图6为空洞卷积模块图;
图7为改进的残差模块图。
具体实施方式
下面结合具体实施例对本发明作进一步详细描述。这些实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于以下实施例。
实施例
如图1所示,其为本发明实施例提供的抑郁症检测流程图,具体包括以下步骤:
s101、语音采集,本实施例从一个语音抑郁症识别比赛的数据库daic-woz中采集语音样本文件,随机将107名患者的语音数据作为训练集,35名患者的语音数据作为测试集。所述采集语音样本文件的过程是通过虚拟机器人ellie以访谈方式对被试者进行提问,并记录语音对话。
s102、语音分离,采用pyaudioanalysis模块将语音样本文件中被试者、虚拟采访者以及静默部分的语音实现分段处理,并去除后两项的语音部分,保留被试者的语音部分。
s103、语音增强,如图2所示,利用改进的谱减法
(1)将带噪声的语音加汉明窗进行平滑处理,德奥短时相位谱,带噪声语音信号y(n)表示为:
y(n)=p(n) d(n),0≤n≤n-1
其中p(n)为纯净信号,d(n)为噪声信号。
(2)计算静默部分时|nk|2的统计平均值λ(k):
(3)将带噪声的语音进行傅里叶变换,将y(n)变换为频域表示:
yw(ω)=sw(ω) dw(ω)
其中,yw(ω),sw(ω),dw(ω)分别为y(n),s(n),d(n)的傅里叶变换,dw(ω)的傅里叶系数为nk,因此,
|yk|2=|sk|2 |nk|2 sk·nk* sk*·nk
其中,*表示复共轭,假定噪声与s(n)为不相关的,即互谱的统计均值为0,因此,
e[|yk|2]=e[|sk|2] e[|nk|2]
采用发语音前的无声部分,通过多帧平均来估计噪声,如下:
|yk|2=|sk|2 λ(k)
(4)带噪声的语音傅里叶变换后的值与噪声功率谱λ(k)求差值,若差值大于0,则与短时相位谱在频谱中合成语音,否则由实验确定一个大于0的常数,合成语音,最后进行短时逆傅里叶变换,获得增强后的语音,差值的计算如下:
(5)引入谱减功率修正系数m和谱减噪声系数
s104、提取mfcc特征,共振峰特征以及频谱图;
所述mfcc特征的提取过程如图3所示,具体步骤如下:
(1)将连续语音进行预加重,本实施例选取的高通滤波器传递函数为:
s(n)=x(n)-a*x(n-1)
其中,x(n)为n时刻的采样频率,x(n-1)为上一时刻的采样频率,a为预加重系数,取值介于0.9-1.0之间,通常取a=0.97;
(2)进行分帧,本实施例中所使用的采样率为16khz,窗长25ms(400个采样点),窗间隔为10ms(160个采样点)。
(3)加窗,使用汉明窗进行加窗处理,此处采样率为16khz,窗长25ms(400个采样点),窗间隔10ms(160个采样点),分帧后的信号为s(n),n为帧的大小,进行加窗的处理规则为:
(4)离散傅立叶变换(dft)
采用dft长度n=512,结果值保留前257个系数。
(5)使用梅尔刻度滤波器组过滤,对于快速傅里叶变换(fft)得到的幅度谱,分别跟每一个滤波器进行频率相乘累加,得到该滤波器对应频段的能量值。
(6)对每个滤波器产生的输出频谱能量取对数后便可得到系数sm。
(7)利用dct将sm转换到时域,便就得到mfcc系数c(m)。
其中,x(k)、hm(k)分别是时域信号,将频域拆分为两部分时域信号,分别为x(k)、hm(k)。
所述共振峰的提取过程如图4所示,具体步骤如下:
(1)对语音信号进行加窗分帧,计算浊音基音周期(1:nn)点;
(2)取倒谱的前1:nn点,加nn点汉明窗,对语音信号进行快速傅里叶变换(fft)及对数运算;
(3)将对数谱平滑处理,然后对峰值定位。
所述频谱图通过短时傅里叶变换获得,在傅立叶变换中,使用时间窗口函数g(t-u)与源信号分f(t)的相乘,实现在u附近的加窗口和平移,然后进行傅立叶变换。短时傅立叶变换如下:
gf(ε,u)=∫f(t)g(t-u)ejεtdt
t表示时间,ε为角频率,u为前u时间段内,t-u为从u时刻到t时刻,j为系数.
s105、将mfcc特征、共振峰特征、频谱图融合输入改进的tcn模型中对训练集进行学习,具体步骤如下:
(1)特征输入,将mfcc特征、共振峰特征、频谱图输入到改进的tcn模型中。图5为改进的tcn模型图,其主要包括空洞卷积模块与残差模块。在改进的tcn模型中,所使用的空洞卷积模块如图6所示,卷积核大小为3,d为空洞卷积的扩张率,每层计算卷积时相隔d-1个位置进行,从下往上padding依次分别为2、4、8。改进的tcn模型中的残差模块如图7所示,残差块中temporal-block中添加了一个裁剪层(chomp),保证网络每一层的特征长度相等。tcn网络取每个输出通道的最后一个值进行拼接作为最后的特征,在此处连接一个过渡模块(transition)将特征进一步处理,transition模块将池化层改用卷积核大小核为3的conv1d和batchnorm1d层替换,该模块利用一维卷积对特征进行处理的同时可减少通道数量,从而有效降低最后的特征维度,而batchnorm1d层具有抑制过拟合的能力。
(2)模型训练,语音数据的输入通道为513,训练时使用adam优化器,训练20个epoch,dropout为0.05,batchsize为64,初始学习率为2e-2,通过二元交叉熵损失和均方误差(mse)回归更新参数;
(3)抑郁症判别,输出phq-8得分,用此得分进行分类和回归,判别被试者是否患抑郁症,若得分大于18,则分类为抑郁者,否则为正常人;通过phq-8得分和患者问卷调查结果对比,计算mse,评估该模型的可信度。
通过具体实施方式的说明,应当可对本发明为达成预定目的所采取的技术手段及功效得以更加深入且具体的了解,然而所附图示用于提供参考与说明,并非用来对本发明加以限制。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

