本发明属于语音认证技术领域,涉及一种基于特征融合的长序列生物哈希认证方法。
背景技术:
近年来,生物特征的认证系统得到了越来越多的应用,未受保护的生物特征数据的存储存在严重的隐私威胁。由于个人生物特征稀缺,一旦丢失,有关用户的敏感信息将暴露出来,从而导致安全隐患。目前,语音认证从语音采集到数据存储到语音哈希数据库都存在安全漏洞,同时认证方法中构造的哈希序列较短,同一哈希序列可能来自不同的语音片段,用户间的低区分性导致较高的误识率,造成认证效果较差。因此,语音生物内容认证中安全性和区分性的研究成为一项重要的挑战。
生物认证方法广泛采用人脸、掌纹、指纹、签名、虹膜等生物特征,鲜有涉及语音特征。近年来,语音感知哈希认证方法不仅可以实现很好的认证效果,同时还能抵抗信道传输过程中噪声干扰,但语音认证方法缺乏安全性。由于生物哈希计算效率和安全性,广泛应用于保护隐私的生物特征。因此,语音感知哈希与生物哈希相结合,不仅可以提高认证的效果,同时还能保证语音特征的安全性。目前,提取的语音信号特征包含:短时互相关系数、短时过零率、梅尔频率倒谱系数、线性预测倒谱系数、谱熵、小波系数、耳蜗图谱、调制复叠变换(modulatedcomplexlappedtransform)(mclt)、语谱图等以及各种特征之间的融合。
现有技术中语音认证方法的哈希序列短,造成区分性不够,常见低信噪比噪声环境下的鲁棒性低,认证方法复杂造成实时性低,语音生物特征的容易泄露。
技术实现要素:
本发明的目的是提供一种基于特征融合的长序列生物哈希认证方法,不仅兼顾区分性和鲁棒性,而且还满足高效的认证。
为实现上述目的,本发明所采用的技术方案是:一种基于特征融合的长序列生物哈希认证方法,具体按以下步骤进行:
注册阶段:
步骤1:对输入的语音信号s(n)进行预加重后,再进行分帧加窗处理,预加重语音信号x(n)被分为n帧,得到处理后信号x(n,m);其中,n(n=1,2,…,n)为帧的索引号,m(m=1,2,…,n)为每帧数据的索引号;
步骤2:鲁棒特征提取
1.mfcc特征提取
通过离散傅里叶变换将处理后信号转换为频域信号
2.cqcc特征提取
对处理后信号进行恒q变换,得变换后的频谱信号
3.求相邻帧空间余弦值
将提取的mfcc特征值和cqcc特征值统一设为mq(n,i)(n=1,2,…,n;i=1,2,…,l),且l=l1=l2;对mfcc特征值和cqcc特征值的行向量分别求均值mq(i)(i=1,2,…,l)和mq1(i)(i=1,2,…,l),然后将mq(i)和mq1(i)进行矩阵拼接,得矩阵λ1=[mq1mq]、λ2=[mqmq1],对矩阵λ1和矩阵λ2的每一列均求余弦值,得到生物特征向量f(n)(n=1,2,…,np);
步骤3:通过2d-simm产生一个伪随机矩阵,对伪随机矩阵进行施密特正交化,得到正交集矩阵;
步骤4:构造生物安全模板
提取正交集矩阵中的行向量,得正交行向量v1(n)(n=1,2,…,np);将生物特征向量f(n)与正交行向量v1(n)点乘,得到方阵ψ(n,n);
对方阵ψ(n,n)进行混沌移位,得到加密后方阵ψ*(n,n);将正交集矩阵中行向量v2(n)(n=1,2,…,np)对加密后方阵ψ*(n,n)进行投影降维,得到生物安全模板w(n);
w(n)=v2(n)·ψ*(n,n)=[w(1),w(2),…,w(np)]
步骤5:二值化处理生物安全模板w(n),生成一维二进制生物哈希长序列h(n),
其中,设h(1)=0,h(n)为每一帧生物哈希值;
然后将生物哈希长序列h(n)存储到云端,完成注册阶段;
认证阶段:
步骤1:认证用户提供认证语音,将该认证语音经过注册阶段的步骤1~步骤5,得到生物哈希长序列h(n);
步骤2:通过汉明距离计算认证语音得到的生物哈希长序列h(n)与储存在云端的生物哈希长序列h(n)的误码率ber(h,h):
式中,⊕是异或逻辑运算,np为生物哈希序列的长度;
利用ber假设检验来描述哈希匹配:
t0:如果两个语音片段的生物哈希长序列h(n)和生物哈希长序列h(n)具有相同的内容,则:ber(h,h)≤τ,认证通过;
t1:如果两个语音片段的生物哈希长序列h(n)和生物哈希长序列h(n)具有不同的内容,则:ber(h,h)>τ,认证失败;
其中,τ表示感知认证阈值;
步骤3:将认证的结果反馈给认证用户。
本发明认证方法是一种基于二维正弦调制映射(2d-simm)和常数q倒谱系数(cqcc)余弦值的长序列生物哈希认证方法,采用哈希长序列提高了抗碰撞性,提取的频域空间距离特征具有很强的鲁棒性,由2d-simm产生的伪随机矩阵能很好地保证生物特征的安全性,确保生物哈希序列的不可逆性。面对常见低信噪比噪声背景,同样具有良好的鲁棒性,同时还能够为生物特征提供安全的模板。
本发明认证方法与现有技术相比具有以下优点:
1)具有很好的综合性能,解决了现有生物哈希认证方法存在的问题。
2)提取的生物特征能够很好的应对音量、重采样、mp3压缩等多种内容保持操作的干扰。对于低信噪比下,babble等复杂噪声环境具有较好的匹配精度。
3)采用哈希长序列,可以有效降低不同语音片段被确认为相同片段的概率,提高认证率。
4)采用比值法来证明了生物哈希算法的带陷门单向性。采用2d-simm产生的生物安全模板具有较高的安全性,降低生物特征泄露有的风险。
附图说明
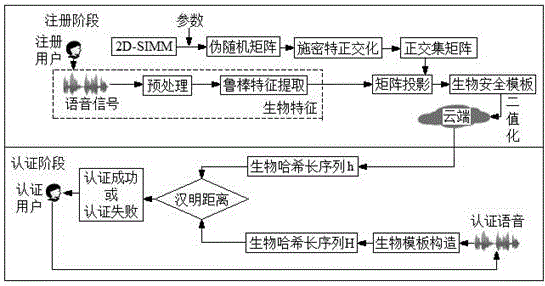
图1是本发明认证方法的流程图。
图2是本发明认证方法中提取mfcc特征的流程图。
图3是本发明认证方法中提取cqcc特征的流程图。
图4为一个语音和其余1199语音相匹配的ber直方图;
图5(a)、图5(b)分别为1065bits下的mfcc余弦值和1065bits下的cqcc余弦值;
图6(a)、图6(b)分别为mfcc余弦值(1065bits)frr-far曲线和cqcc余弦值(1065bits)frr-far曲线;
图7为本发明认证方法far-frr曲线;
图8为验证生物安全模板带陷门的单向性框图;
图9(a)、图9(b)分别为正确秘钥得到的特征、与原始特征的差异;
图10(a)、图10(b)分别为错误秘钥得到的特征、与原始特征的差异;
图11(a)、图11(b)分别为、与之间的汉明码距离;
图12(a)、图12(b)分别为正确混沌移位和错误混沌移位的生物安全模板。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明提供了一种基于特征融合的长序列生物哈希认证方法,其流程图如图1所示,该认证方法具体按以下步骤进行:
注册阶段:注册用户对原始语音进行特征提取,然后构造生物安全模板,最后将二值哈希长序列存储到云端。
步骤1:对输入的语音信号s(n)进行预加重,得到预加重语音信号x(n),然后,对预加重语音信号x(n)进行分帧加窗处理,窗函数选用汉明窗;预加重语音信号x(n)被分为n帧,得到处理后信号x(n,m)。其中,n(n=1,2,…,n)为帧的索引号,m(m=1,2,…,n)为每帧数据的索引号;处理后信号x(n,m)为时域信号。
步骤2:鲁棒特征提取
1.mfcc特征提取
通过离散傅里叶变换(dft)将时域信号转换为频域信号
2.cqcc特征提取
对时域信号进行恒q变换(cqt),得到变换后的频谱信号
例如:求取mfcc特征时采用16个mel滤波器,使得l1=16。求取cqcc时,cqt变换后,k的值为8;然后进行等间隔插值采样,得到l2为16。
3.求相邻帧空间余弦值
将提取的mfcc特征值和cqcc特征值统一设为mq(n,i)(n=1,2,…,n;i=1,2,…,l),且l=l1=l2;对mfcc特征值和cqcc特征值的行向量分别求均值mq(i)(i=1,2,…,l)和mq1(i)(i=1,2,…,l),然后将矩阵mq(i)和mq1(i)拼接,得矩阵λ1=[mq1mq]、λ2=[mqmq1],对矩阵λ1和矩阵λ2的每一列均求余弦值,得到生物特征向量f(n)(n=1,2,…,np);
步骤3:通过2d-simm产生一个伪随机矩阵,对伪随机矩阵进行施密特正交化,得到正交集矩阵;
接上例,通过2d-simm产生一个伪随机矩阵,设置2d-simm的初始值a=1,b=5,设置密钥k,同时,该伪随机矩阵长度与特征向量f(n)长度一致。初始值随机选取进行设置x0=0.2,y0=0.3,得到伪随机矩阵v(n,t)(n=1,2,…,n;t=1,2),对该伪随机矩阵进行施密特正交化,得到正交集矩阵v(n,t);
步骤4:构造生物安全模板
提取正交集矩阵中的行向量,得正交行向量v1(n)(n=1,2,…,np);将生物特征f(n)与正交行向量v1(n)点乘,得到方阵ψ(n,n);
为进一步增加生物模板的安全性,对方阵ψ(n,n)进行混沌移位,即行和列按照环形式循环位移;为降低计算复杂度和提高效率,将方阵ψ(n,n)的行和列都移动0.5n(n代表哈希序列的长度)位,得到加密后方阵ψ*(n,n);将正交集矩阵中行向量v2(n)(n=1,2,…,np)对加密后方阵ψ*(n,n)进行投影降维,得到生物安全模板w(n);
w(n)=v2(n)·ψ*(n,n)=[w(1),w(2),…,w(np)]
步骤5:构造生物哈希长序列
二值化处理生物安全模板w(n),生成一维二进制生物哈希长序列h(n),然后将生物哈希长序列h(n)存储到云端,完成注册阶段;
其中,设h(1)=0,h(n)为每一帧生物哈希值;
接上例,哈希序列长度为npbits。
认证阶段:
认证用户提供语音,构造生物哈希长序列,并与云端的生物哈希序列进行匹配认证,将结果反馈给认证用户。
步骤1:认证用户提供认证语音,将该认证语音经过注册阶段的步骤1~步骤5,得到生物哈希长序列h(n);
步骤2:通过汉明距离计算认证语音得到的生物哈希长序列h(n)与储存在云端的生物哈希长序列h(n)的误码率ber(h,h):
式中,⊕是异或逻辑运算,np为生物哈希序列的长度;
利用ber假设检验来描述哈希匹配:
t0:如果两个语音片段的生物哈希长序列h(n)和生物哈希长序列h(n)具有相同的内容,则:ber(h,h)≤τ
t1:如果两个语音片段的生物哈希长序列h(n)和生物哈希长序列h(n)具有不同的内容,则:ber(h,h)>τ
其中,τ表示感知认证阈值,通过设置匹配阈值τ的大小,实现生物哈希的认证;如果误码率小于阈值τ,那么生物哈希长序列h(n)和生物哈希长序列h(n)的生物特征是相同的,认证通过,否则认证失败;
步骤3:将认证的结果反馈给认证用户
为了评估认证方法的性能,由下面两个公式分别计算误识率(far)和误拒率(frr);
式中:τ为感知认证阈值;μ为ber均值;σ为ber标准差。一般采用frr和far来评价认证方法的鲁棒性和区分性;frr值越低,感知鲁棒性越强;far值越低,区分性越好。
通过以下仿真实验说明本发明性能的优越性:
一、实验条件与实验说明
实验语音数据来自timit(texasinstrumentsandmassachusettsinstituteoftechnology)和tts(texttospeech)语音库,原始语音数据库中有1200个不同的语音片段。每段语音片段的格式为wav,长度为4s,采用16位pcm,单声道,采样频率为16khz。
根据语音传输的环境,对语音数据库中的每一个语音进行内容保持操作。建立了包含音量、回声、噪声、重采样和mp3压缩等10种内容保持操作的语音数据库,共有12000段语音。
为了模拟真实环境中的混合噪声,在原有语音数据库中加入了noise-92噪声数据库。建立了86400段不同真实背景噪声的语音数据库,包括gnoisegen噪声、pink噪声、factoryfloornoise1、factoryfloornoise2、hfchannel噪声、machinegun噪声、babble噪声和volvo噪声的8种噪声。每一种噪声都有9种信噪比分别为-10db、-5db、0db、5db、10db、15db、20db、25db和30db。
实验硬件平台为intel(r)core(tm)i5-7500,4gb,3.4ghz。软件环境为win10操作系统下的matlabr2018b。
二、实验内容
1.区分性测试与分析
不同语音内容的感知哈希值的ber基本服从正态分布。有1200个不同的语音,利用二项式系数计算所有可用的ber值的数目为1200×1199/2=719400。图4显示了一个语音和其余1199个语音相匹配的ber直方图,由图可知其ber均值服从正态分布图,接近0.5,说明区分性较好。如图5所示,不同内容语音的哈希序列的ber基本服从正态分布,图5中(a)表示1065bits下的mfcc余弦值;(b)表示1065bits下的cqcc余弦值。如图5所示,ber正态分布曲线越好,生物哈希序列的随机性和抗碰撞性能越好。实验结果表明:不同语音的ber值的概率分布均与标准正态分布的概率曲线有较高的重合度。随着哈希序列的增加,ber范围更接近0.5,分布的值更贴近理论值。
接上例,选取的序列长度1065bits相较于640bits和799bits在ber范围方面更小,效果最优。相比mfcc余弦值算法,cqcc余弦值算法实际值的波动较小,效果更好。
根据隶莫佛-拉普拉斯中心极限定理,汉明距近似服从
接上例,生物哈希序列的长度为bits,理论正态分布参数的平均值和标准偏差为。表1描述了不同鲁棒特征和不同哈希序列长度的正态分布参数。
表1不同鲁棒特征和不同哈希序列长度的正态分布参数
由表1可以看出,随着哈希序列长度的增加,本发明认证方法的实际值更接近理论值,实际曲线越来越接近理论曲线,说明本发明认证方法生成的哈希序列长度具有良好的随机性和抗碰撞性能。同时,cqcc余弦值与mfcc余弦值实际值曲线差距较小,都与理论曲线较近,说明这两种方法都具有很好的区分性。
2.鲁棒性测试与分析
原始语音进行如表2所示的内容保持操作,产生12000段操作语音。
表2内容保持操作
通过对1200个语音片段的感知哈希值进行两两比较,得到719400ber数据,当哈希长度设置为640bits、799bits、1065bits时,得到图6所示的far-frr曲线图:不同哈希序列长度mfcc余弦值的frr和far曲线均相交,其不能很好的平衡区分性和鲁棒性,而本发明认证方法中不同哈希序列长度的frr和far曲线没有重叠,可以准确的区分内容保持操作和不同内容的语音,说明本发明认证方法可以很好的平衡区分性和鲁棒性。
图7是上例中得到的far-frr曲线图,采用的哈希序列长度为1065bits,得到的frr-far曲线没有重叠,frr和far最终下落点的区间为[0.2350.425],实验结果说明本发明认证方法具有良好的区分性和鲁棒性,能够准确识别内容保持操作和不同内容的语音。
3.真实噪声环境下的匹配率测试与分析
为了评估本发明认证方法对噪声的鲁棒性,引入了匹配率pr,
其中,ta为感知内容相同语音片段之间被系统正确接受的语音片段个数;tr为被系统错误拒绝的语音个数;fa为感知内容不同语音片段之间被系统错误接受的语音片段个数。阈值τ选取为far曲线的最小比特误码率。不同方法中阈值τ的选取:本发明认证方法中为0.4173,mfcc余弦值法为0.4264,对于工厂噪声1、高斯白噪声、高频信道噪声和机枪噪声,本发明认证方法的匹配精度高于其他方法。对于所有的噪声,本发明认证方法在信噪比大于10db时,匹配率均达到了100%,本发明认证方法仅在工厂噪声2和volvo噪声下匹配率略低于mfcc余弦特征。其他噪声,mfcc余弦值特征的表现效果较差。从整体来看,本发明认证方法的鲁棒性更强,能更好的实现极端噪声环境下的生物认证。因此,本发明认证方法对于低信噪比下不同噪声具有较强的鲁棒性,能够满足复杂环境下语音匹配的需求。
4.单向性和安全性的测试与分析
为了验证生物哈希算法带陷门的单向性,提出一种基于对数比值法的带陷门的单向性验证算法。图8中a部分为生物安全模板生成方向,b部分为生物安全模板生成的逆方向,c部分为验证提取生物哈希算法的带陷门的单性。
随机提取语音库中语音段x,其语音原始特征f通过图8中a部分的方向得到生物安全模板w,然后要得到语音特征f′则通过b部分的方向,最后计算两个生物特征序列之间的区别。两个序列之间的对数比值差异法定义为:
其中,f′为由生物安全模板得到特征值,f为原始特征值,rc为生物特征的差异状态。
随机提取原始语音库中的语音片段来验证生物哈希算法带陷门的单向性。图9和图10分别为正确秘钥和错误秘钥得到的特征f′1、f′2与原始特征f差异。图9(a)表示为正确秘钥的特征与原始特征的比基本一致,图9(b)为正确秘钥的特征与原始特征比的具体差异;图10(a)表示错误秘钥的特征与原始特征的比不本一致,图10(b)为错误秘钥的特征与原始特征比的具体差异。对比图9和图10可以看出,使用正确密钥提取的特征f′1与原始特征f仅略有差异,两者之间的距离分布在(-2.1×10-15,1.3×10-15)处。使用错误密钥提取的特征f′2与原始特征f完全不同,两者之间的距离分布-4.1周围,由于其中误差仅为10-8,误差太小,因此在图10(b)中则显示为直线。相比正确秘钥,错误秘钥产生的特征序列与原始特征序列差距较大,因此说明生物哈希带陷门的单向性。
为了进一步验证生物哈希算法带陷门的单向性,首先从语音库中随机抽取150个语音,分别计算f′1、f′2与f之间的汉明码距离,汉明码距离如图11所示。图11(a)为f′1与f之间的汉明码距离,由图所示:正确秘钥得到的特征f′1与原始特征f之间的汉明距离范围为(-3.7×10-18,6.9×10-18)。图11(b)为f′2与f之间的汉明码距离,由图所示:错误秘钥得到的特征f′2与原始特征f之间的汉明距离范围为(0.10,0.19),进一步验证了生物哈希算法是带陷门的单向性,同时也证明了生物哈希算法的安全性。
为了增强本发明认证方法的安全性,在构造生物模板时采用了混沌移位。图12对比了正确混沌移位和错误混沌位移得到生物安全模板,图12(a)表示正确混沌移位的生物安全模板分布在区间(-5.5×10-4,-0.2×10-4)中,而图12(b)中错误混沌移位的生物安全模板分布在区间(0.2×10-3,1.9×10-3)中,正确混沌移位的生物安全模板和错误混沌移位的生物安全模板的数值完全不同,因此得出,不知道正确混沌移位时,也得不到正确的生物安全模板。
5.实时性分析
实时性是语音内容认证中一个非常重要的评价标准。为了评估本发明认证方法的实时性,需要从语音数据库中随机选择200个语音片段,然后计算平均运行时间。采用相同的运行环境,语音片段为4s,表3给出了本发明认证方法与mfcc余弦值算法的结果。
表3本发明认证方法以及mfcc余弦值的实时性
如表3所示,就本发明认证方法而言,随着哈希序列长度的增加,虽然实时性在降低,但相差较小,满足实时认证的要求。本发明认证方法相较其他哈希序列长度,虽然实时性偏低,但区分性有很大提高。与mfcc余弦值相比,当哈希序列都为1065bits时,mfcc余弦值为本发明认证方法的1.08倍。本发明认证方法在实时性方面效果表现非常好,能够满足实时认证的要求。
综上所述,本发明提出的基于2d-simm和cqcc余弦值特征融合的长序列生物哈希认证方法具有很好的综合性能,解决了现有生物哈希认证算法存在的问题。通过实验分析可以得到以下结论:采用哈希长序列,可以有效降低不同语音片段被确认为相同片段的概率,提高认证率。提取的生物特征能够很好的应对音量、重采样、mp3压缩等多种内容保持操作的干扰。对于低信噪比下,babble等复杂噪声环境具有较好的匹配精度。采用比值法来证明了生物哈希算法的带陷门单向性。采用2d-simm产生的生物安全模板具有较高的安全性,降低生物特征泄露有的风险。
现有技术中的语音认证方法将提取的语音特征直接进行哈希构造并保存到云端,这样很容易造成语音特征的泄露。在构造哈希时,语音特征的利用效率较差,构造出的哈希序列太短而造成哈希序列区分性不够,认证出现偏差。本发明提出了一种基于二维正弦调制映射(2d-simm)和常数q倒谱系数(cqcc)余弦值融合的长序列生物哈希认证方法。首先提取语音信号的cqcc,然后求取相邻语音帧cqcc空间余弦距离的特征值,最后将特征值与2d-simm产生的伪随机矩阵进行投影映射,构造出生物哈希长序列。通过实验对提出的mfcc(梅尔倒谱系数)空间余弦距离和cqcc空间余弦距离两种鲁棒特征方案进行评估,采用timit(texasinstrumentsandmassachusettsinstituteoftechnology)和tts(texttospeech)语音库中的语音进行测试。实验结果表明,本发明认证方法采用cqcc空间余弦距离特征得到的效果更好,不仅兼顾区分性和鲁棒性,而且满足高效的认证。面对常见低信噪比噪声背景,本发明认证方法具有良好的鲁棒性,同时还能为生物特征提供安全的模板。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

