本发明涉及音频信息采集和处理技术领域,具体涉及一种用于英语语音的信息采集方法。
背景技术:
随着远程教育的普及,“网课”作为一种现场课程的替代和补充起到了很重要的作用,特别是在英语教学中,教学者通常希望能够给出完美的语音以完成课堂或者培训教学,因此,通过语音智能化方法来实时纠正发音就能解决教学者的痛点。
现有技术中普遍通过将教学语音与标准语音对比给出评分或者对声音进行美化的方式来实现语音评价或者纠正。如cn202010891349.4就公开了一种自适应英语语音的生成方法,采集目标语音信号;对采集的所述目标语音信号进行信号分析和处理,得到对应的待保留信号;针对得到的所述待保留信号,参照英语语音对应的标准语音信号,对所述待保留信号进行缺陷识别;根据缺陷识别结果,将包含所述目标语音信号的语音数据输入对应的英语语音输出模型中,获取语音输出结果,得到生成的英语语音,以提高英语语音输出的精准性和智能性。
然而参照英语语音的标准语音信号时并未考虑到发音者与标准语音信号之间的本质差别例如口腔发音位置不同、声调不同、语气不同等,会使得所谓“缺陷”识别不准确,导致在输入对应的英语语音输出模型中输出的英语语音失真,语句不连贯等问题。
同时,现有技术中的语音美化往往不能适应不同发音者的特点,美化后的语音不够平滑,体验效果较差。
技术实现要素:
本发明的目的在于提供一种用于英语语音的信息采集方法,以解决背景技术中提到的发音者与标准语音信号之间的本质差别例如口腔发音位置不同、声调不同、语气不同等而导致的识别不准,语音不连贯、输出失真等问题。
为实现上述目的,本发明提供如下技术方案:
一种用于英语语音的信息采集方法,具体的步骤如下:
s1、采集音频信号并放大;
s2、将放大后的音频信号进行模拟滤波;
s3、将模拟滤波后的信号转换为数字信号并提取数字音频信号的音频特征参数:起音时间、频谱质心、频谱通量、基音频率、尖锐度等;
s4、将上述音频特征参数与标准音源数据库中的音源模型匹配,然后将数字音频信号与音源模型中的音节、音位匹配得出匹配度,根据匹配度差距大小进行音素纠正;
s5、将纠正后的音素组合进数字音频信号;
s6、对合成后的数字音频信号进行模糊滤波,并输出音频信号。
所述s4中的标准音源数据库中的音源模型有多个不同类型的;
所述s4中的匹配度计算方法具体如下:采用皮尔森相关系数的方式来计算匹配度,起音时间、频谱质心、频谱通量、基音频率、尖锐度等多个特征参数作为向量,然后计算上述向量的相关系数,所述相关系数即可作为匹配度。
所述s4中的音素纠正是指以音素为单位与音源模型进行比较,两者得出的音素差值较大的(超出范围的)即按照音源模型中的音素为基础进行纠正,如果音素差值根据音素相关系数确定,所述音素相关系数包括音调、音长、音高、清、浊、爆破等,如/θ/是个清辅音,声带不震动,要注意与/ð/,/s/,/z/的区别,如果发/θ/音时,尖锐度以及能量较大时则判定差值较大,需要纠正。
所述s6中的模糊滤波实现方式为:结合工作在时域的相位模糊滤波器,根据未纠正音素与音源模型中的差值对纠正后的音素进行能量平滑处理。
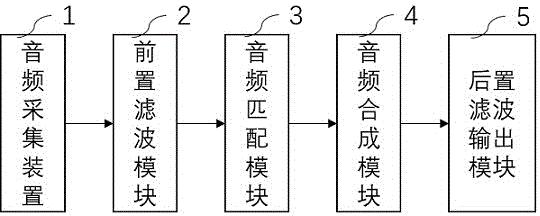
本发明还公开了一种英语发音信息采集系统,包括音源采集装置、前置滤波模块、音频匹配模块、音频合成模块以及后置滤波输出模块;
所述音频采集装置用于采集音频信号并放大;
所述前置滤波模块用于将放大后的音频信号进行模拟滤波。
所述音频匹配模块将模拟滤波后的信号转换为数字信号并提取数字音频信号的起音时间、频谱质心、频谱通量、基音频率、尖锐度等音频特征,并将上述音频特征与标准音源数据库中的音源模型匹配,然后将数字音频信号与音源模型中的音节、音位匹配得出匹配度,根据匹配度差距大小进行音素纠正。
所述音频合成模块用于将纠正后的音素组合进数字音频信号;
所述后置滤波输出模块用于对合成后的数字音频信号进行模糊滤波,并输出音频信号。
所述音频采集装置包括采集生物音频的传感器以及信号放大器,所述传感器与信号放大器连接,所述信号放大器与所述前置滤波模块连接,所述前置滤波模块为高通滤波器,用于滤除高频噪声。
所述音频匹配模块进一步包括高速a/d转换器,以便于更好的反映音频细节。
所述音频匹配模块还包括与高速a/d转换器连接的音频特征提取模块,所述音频特征提取模块用于实现数字音频信号分析和音频特征提取,所述音频特征提取包括如下参数的提取:起音时间,反映音符能量在上升阶段的时长;频谱质心,用于反映信号音色明朗度的信号频谱中的能量集中点;频谱通量,用于反映音符起始点的特征的信号相邻帧之间的变化程度;基音频率,用于反映单音信号的音高对应的频率;尖锐度,用于反映尖锐度的高频部分的能量。
所述音频匹配模块还包括存储有大量不同类型音源模型的英文音源数据库的存储模块,所述音源模型根据所述音频特征进行分类。
所述音频匹配模块能够计算数字音频信号的音频特征与音源模型的匹配度,根据匹配度以语句为单位决定是否切换音源模型进行音素纠正,所述匹配度按照起音时间、频谱质心、频谱通量、基音频率、尖锐度等多个音频特征参数的匹配度综合计算,所述匹配度可采用皮尔森相关系数的方式来计算,起音时间、频谱质心、频谱通量、基音频率、尖锐度等多个特征参数作为向量,然后计算上述向量的相关系数,所述相关系数即可作为匹配度。
所述音素纠正是指以音素为单位与音源模型进行比较,两者得出的音素差值较大的(超出范围的)即按照音源模型中的音素为基础进行纠正。
所述后置滤波输出模块中的后置滤波采用模糊数字滤波器进行滤波,根据未纠正音素与音源模型中的差值对纠正后的音素进行能量平滑处理,可结合工作在时域的相位模糊滤波器。
与现有技术相比,本发明为了克服由于口腔发音位置不同、声调不同、语气不同等而导致的识别不准,根据发音人的发音特点、以及音源模型中的语句、音节、音位匹配不同的音源模型,匹配后再进行音素级别的纠正;纠正后的音素合成到数字音频信号后进行模糊滤波,可以使得语音更平滑,更自然。
附图说明
图1为一种英语发音信息采集系统框图。
图2为一种音频采集具体示意图。
图3为音频匹配模块具体示意图。
图4为用于英语语音的信息采集方法步骤图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
如图4所示,还提供了一种用于英语语音的信息采集方法,所述信息采集方法具体的步骤如下:
s1、采集音频信号并放大;
s2、将放大后的音频信号进行模拟滤波;
s3、将模拟滤波后的信号转换为数字信号并提取数字音频信号的音频特征参数:起音时间、频谱质心、频谱通量、基音频率、尖锐度等;
s4、将上述音频特征参数与标准音源数据库中的音源模型匹配,然后将数字音频信号与音源模型中的音节、音位匹配得出匹配度,根据匹配度差距大小进行音素纠正;
s5、将纠正后的音素组合进数字音频信号;
s6、对合成后的数字音频信号进行模糊滤波,并输出音频信号。
所述s4中的标准音源数据库中的音源模型有多个不同类型的。
所述s4中的匹配度计算方法具体如下:采用皮尔森相关系数的方式来计算匹配度,起音时间、频谱质心、频谱通量、基音频率、尖锐度等多个特征参数作为向量,然后计算上述向量的相关系数,所述相关系数即可作为匹配度。
所述s4中的音素纠正是指以音素为单位与音源模型进行比较,两者得出的音素差值较大的(超出范围的)即按照音源模型中的音素为基础进行纠正,如果音素差值根据音素相关系数确定,所述音素相关系数包括音调、音长、音高、清、浊、爆破等,如/θ/是个清辅音,声带不震动,要注意与/ð/,/s/,/z/的区别,如果发/θ/音时,尖锐度以及能量较大时则判定差值较大,需要纠正。
所述s6中的模糊滤波实现方式为:结合工作在时域的相位模糊滤波器,根据未纠正音素与音源模型中的差值对纠正后的音素进行能量平滑处理。
实施例2
如图1所示,本发明提供的一种具体实施方式为一种英语发音信息采集系统,包括音频采集装置1、前置滤波模块2、音频匹配模块3、音频合成模块4以及后置滤波输出模块5;
所述音频采集装置1用于采集音频信号并放大,
所述前置滤波模块2用于将放大后的音频信号进行模拟滤波,
所述音频匹配模块3将模拟滤波后的信号转换为数字信号并提取数字音频信号的起音时间、频谱质心、频谱通量、基音频率、尖锐度等音频特征,并将上述音频特征与标准音源数据库中的音源模型匹配,然后将数字音频信号与音源模型中的音节、音位匹配得出匹配度,根据匹配度差距大小进行音素纠正;
所述音频合成模块4用于将纠正后的音素组合进数字音频信号;
所述后置滤波输出模块5用于对合成后的数字音频信号进行模糊滤波,并输出音频信号。
进一步的改进在于,如图2所示,所述音频采集装置1包括采集生物音频的传感器1-1以及信号放大器1-2,所述传感器1-1与信号放大器1-2连接,所述信号放大器1-2与所述前置滤波模块2连接,所述前置滤波模块2为高通滤波器2’,用于滤除高频噪声。
进一步的改进在于,如图3所示,所述音频匹配模块3进一步包括高速a/d转换器3-1,以便于更好的反映音频细节。
进一步的改进在于,所述音频匹配模块3还包括与高速a/d转换器3-1连接的音频特征提取模块3-2,所述音频特征提取模块3-2用于实现数字音频信号分析和音频特征提取,所述音频特征提取包括如下参数的提取:起音时间,反映音符能量在上升阶段的时长;频谱质心,用于反映信号音色明朗度的信号频谱中的能量集中点;频谱通量,用于反映音符起始点的特征的信号相邻帧之间的变化程度;基音频率,用于反映单音信号的音高对应的频率;尖锐度,用于反映尖锐度的高频部分的能量。
进一步的改进在于,所述音频匹配模块3还包括存储有大量不同类型音源模型的英文音源数据库的存储模块3-3,所述音源模型根据所述音频特征进行分类。
进一步的改进在于,所述音频匹配模块3能够计算数字音频信号的音频特征与音源模型的匹配度,根据匹配度以语句为单位决定是否切换音源模型进行音素纠正,所述匹配度按照起音时间、频谱质心、频谱通量、基音频率、尖锐度等多个音频特征参数的匹配度综合计算,所述匹配度可采用皮尔森相关系数的方式来计算,起音时间、频谱质心、频谱通量、基音频率、尖锐度等多个特征参数作为向量,然后计算上述向量的相关系数,所述相关系数即可作为匹配度。
进一步的改进在于,所述音素纠正是指以音素为单位与音源模型进行比较,两者得出的音素差值较大的(超出范围的)即按照音源模型中的音素为基础进行纠正。
进一步的改进在于,所述后置滤波输出模块5中的后置滤波采用模糊数字滤波器进行滤波,根据未纠正音素与音源模型中的差值对纠正后的音素进行能量平滑处理,可结合工作在时域的相位模糊滤波器。
本发明为了克服由于口腔发音位置不同、声调不同、语气不同等而导致的识别不准,根据发音人的发音特点、以及音源模型中的语句、音节、音位匹配不同的音源模型,匹配后再进行音素级别的纠正;纠正后的音素合成到数字音频信号后进行模糊滤波,可以使得语音更平滑,更自然。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

