1.本发明涉及语音评测技术领域,具体涉及一种开放式的语音评测方法和设备。
背景技术:
2.语音评测技术是智能语音技术的一个重要部分、现在被广泛应用,但是目前传统的语音评测系统都是在给定特定文本内容的情况下,检测基于此特定文本内容的发音的质量的好坏,具体的,传统的语音评测系统在进行评测时,通常需要搜集大量发音质量较高的语音数据训练声学模型,然后通过参考文本、发音词典以及声学模型构建识别网络,最后通过gop(goodness of pronunciation)算法给出后验概率作为衡量学习者对某个音素的发音好坏。
3.而也正基于此,现有的语音评测系统存在以下缺陷:具体的,现有的语音评测系统,如果不传入参考文本,则无法进行评测。
4.由此,目前需要有一种更好的方案来解决现有技术中的问题。
技术实现要素:
5.本发明提供一种开放式的语音评测方法,能够解决现有技术中没有参考文本无法进行评测的技术问题。
6.本发明解决上述技术问题的技术方案如下:
7.本发明实施例提出了一种开放式的语音评测方法,包括:
8.通过语音识别模块与语音评测模块获取待评测的语音,并分别设置为第一语音与第二语音;
9.通过所述语音识别模块对所述第一语音进行文本识别,并确定识别到的文本的置信度;
10.若所述置信度低于阈值,则通过所述语音评测模块对所述文本进行拓展,得到拓展文本;
11.分别确定所述文本与所述拓展文本的后验概率;
12.若所述文本的后验概率小于所述拓展文本的后验概率,则基于所述拓展文本与所述第二语音进行gop评测;若所述文本的后验概率大于所述拓展文本的后验概率,则基于所述文本与所述第二语音进行gop评测。
13.在一个具体的实施例中,还包括:
14.若所述置信度高于阈值,则通过所述语音评测模块基于所述文本与所述第二语音进行评测,得到语音发音质量的评价值。
15.在一个具体的实施例中,所述语音识别模块包括:第一特征模块、第一声学模型和语言模型;其中,所述第一特征模块的输出端分别连接所述第一声学模型和所述语言模型;所述第一声学模型和所述语言模型连接;
16.所述第一特征模块输出的特征包括:mfcc特征、plp特征、filterbank特征;所述第
一声学模型包括:dnn、ftdnn、transformer;所述第一声学模型的训练数据包括native和non
‑
native的数据;
17.所述语言模型包括ngram、rnn。
18.在一个具体的实施例中,所述语音评测模块,包括:第二特征模块、第二声学模型、扩展识别文本模块、评测模块;其中,所述第二特征模块的输出端连接所述第二声学模型;所述扩展识别文本模块连接所述语音识别模块;所述扩展识别文本模块、所述语音识别模块以及所述第二声学模型均连接所述评测模块。
19.在一个具体的实施例中,所述拓展文本是基于对所述文本基于相似发音的原则进行拓展得到的。
20.本发明实施例还提出了一种开放式的语音评测设备,包括:
21.获取模块,用于通过语音识别模块与语音评测模块获取待评测的语音,并分别设置为第一语音与第二语音;
22.确定模块,用于通过所述语音识别模块对所述第一语音进行文本识别,并确定识别到的文本的置信度;
23.拓展模块,用于若所述置信度低于阈值,则通过所述语音评测模块对所述文本进行拓展,得到拓展文本;
24.第二确定模块,用于分别确定所述文本与所述拓展文本的后验概率;
25.评测模块,用于若所述文本的后验概率小于所述拓展文本的后验概率,则基于所述拓展文本与所述第二语音进行gop评测;若所述文本的后验概率大于所述拓展文本的后验概率,则基于所述文本与所述第二语音进行gop评测。
26.在一个具体的实施例中,还包括:
27.处理模块,用于若所述置信度高于阈值,则通过所述语音评测模块基于所述文本与所述第二语音进行评测,得到语音发音质量的评价值。
28.在一个具体的实施例中,所述语音识别模块包括:第一特征模块、第一声学模型和语言模型;其中,所述第一特征模块的输出端分别连接所述第一声学模型和所述语言模型;所述第一声学模型和所述语言模型连接;
29.所述第一特征模块输出的特征包括:mfcc特征、plp特征、filterbank特征;所述第一声学模型包括:dnn、ftdnn、transformer;所述第一声学模型的训练数据包括native和non
‑
native的数据;
30.所述语言模型包括ngram、rnn。
31.在一个具体的实施例中,所述语音评测模块,包括:第二特征模块、第二声学模型、扩展识别文本模块、评测模块;其中,所述第二特征模块的输出端连接所述第二声学模型;所述扩展识别文本模块连接所述语音识别模块;所述扩展识别文本模块、所述语音识别模块以及所述第二声学模型均连接所述评测模块。
32.在一个具体的实施例中,所述拓展文本是基于对所述文本基于相似发音的原则进行拓展得到的。
33.本发明的有益效果是:
34.本方案对语音进行文本识别,后续基于识别出的文本与语音进行评测,实现了对任意送进来的语音,都可以给出发音质量的评价的技术效果。
附图说明
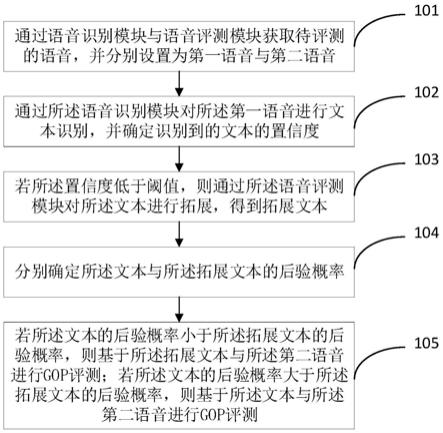
35.图1为本发明实施例提供的一种开放式的语音评测方法的流程示意图。
36.图2为本发明实施例提供的一种开放式的语音评测方法中语音识别模块工作的流程示意图;
37.图3为本发明实施例提供的一种开放式的语音评测方法中语音评测模块工作的流程示意图;
38.图4为本发明实施例提供的一种开放式的语音评测方法中文本拓展的示意图;
39.图5为本发明实施例提供的一种开放式的语音评测设备的结构示意图。
具体实施方式
40.以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
41.实施例1
42.本发明实施例1公开了一种开放式的语音评测方法,如图1所示,包括以下步骤:
43.步骤101、通过语音识别模块与语音评测模块获取待评测的语音,并分别设置为第一语音与第二语音;
44.具体的,所述语音识别模块包括:第一特征模块、第一声学模型和语言模型;其中,所述第一特征模块的输出端分别连接所述第一声学模型和所述语言模型;所述第一声学模型和所述语言模型连接;所述第一特征模块输出的特征包括:mfcc(mel frequency cepstrum coefficient,梅尔频率倒谱系数)特征、plp(perceptual linear predictive,感知线性预测系数)特征、filterbank(滤波器组)特征;所述第一声学模型包括:dnn(deep neural networks,深度神经网络)、ftdnn(一种语音识别的神经网络)、transformer(google的团队在2017年提出的一种nlp经典模型);所述第一声学模型的训练数据包括native(本地)和non
‑
native(非本地)的数据;所述语言模型包括ngram(一种基于统计语言模型的算法)、rnn(recurrent neural network,循环神经网络)。
45.具体的,如图2所示,语音识别模块主要包括三个部分,分别为前端的特征模块、声学模型模块和语言模型模块,目前主流的提特征输出包括mfcc、plp、filterbank特征等等;声学模型包括dnn、ftdnn、transformer结构等,训练声学模型的数据包括native和non
‑
native的数据,无论发音的好坏,只要能分辨发音和文本一致就可以使用;语言模型包括ngram、rnn结构等;输入语音送入到语音识别系统,得到识别文本和其对应的置信度。
46.所述语音评测模块,包括:第二特征模块、第二声学模型、扩展识别文本模块、评测模块;其中,所述第二特征模块的输出端连接所述第二声学模型;所述扩展识别文本模块连接所述语音识别模块;所述扩展识别文本模块、所述语音识别模块以及所述第二声学模型均连接所述评测模块。
47.而如图3所示,语音评测模块所用的声学模型,训练所需的数据必须是发音质量好的数据;
48.步骤102、通过所述语音识别模块对所述第一语音进行文本识别,并确定识别到的文本的置信度;具体的,若所述置信度高于阈值,则通过所述语音评测模块基于所述文本与所述第二语音进行评测,得到语音发音质量的评价值。
49.具体的,如图3所示,语音评测模块输入的语音和识别的文本,分别送入到语音评测系统,针对识别系统生成的文本,若置信度比较高,高于设定的阀值(也即对应cm>threshold),说明识别的结果可信度比较高,此时直接根据输入语音和文本进行评测,给出语音发音质量的评价;若置信度低于设定的阈值(cm<threshold),说明识别结果不太可信,此时就要对识别结果文本进行扩展,可以通过规则或者文本相似度进行筛选。
50.具体的,cm可以基于下列根据后验计算的公式来进行计算:
[0051][0052]
其中,p(s)是cm的值,s表示音素状态,x∈s、t表示t时刻特征;p(o
t
/s)是指t时刻观察矢量o在模型s下的似然分数;∑
xcs
p(o
t
/x)是指音素集合s下的似然分数求和。
[0053]
再设定阈值去比较的,评测gop也有多种计算方法,如利用likehood,或者max(p(s))作为gop的计算方式。
[0054]
步骤103、若所述置信度低于阈值,则通过所述语音评测模块对所述文本进行拓展,得到拓展文本;所述拓展文本是基于对所述文本基于相似发音的原则进行拓展得到的。
[0055]
步骤104、分别确定所述文本与所述拓展文本的后验概率;
[0056]
步骤105、若所述文本的后验概率小于所述拓展文本的后验概率,则基于所述拓展文本与所述第二语音进行gop(goodness of pronunciation,发音质量)评测;若所述文本的后验概率大于所述拓展文本的后验概率,则基于所述文本与所述第二语音进行gop评测。
[0057]
具体的,如图4所示,会建立其两个评测网络(即对应图2的扩展识别文本的模块),一个是根据文本识别结果构建的评测网络,一个是根据文本相似发音的扩展词建立的评测网络,分别得到两个网络的后验证概率posterior1和posterior2,若posterior1>posterior2,直接通过文本以及第二模块得到的语音进行gop给出语音发音质量的评价;反馈发音质量差,则基于拓展文本与第二模块得到的语音进行gop给出语音发音质量的评价。
[0058]
实施例2
[0059]
本发明实施例2公开了一种开放式的语音评测设备,如图5所示,包括:
[0060]
获取模块201,用于通过语音识别模块与语音评测模块获取待评测的语音,并分别设置为第一语音与第二语音;
[0061]
确定模块202,用于通过所述语音识别模块对所述第一语音进行文本识别,并确定识别到的文本的置信度;
[0062]
拓展模块203,用于若所述置信度低于阈值,则通过所述语音评测模块对所述文本进行拓展,得到拓展文本;
[0063]
第二确定模块204,用于分别确定所述文本与所述拓展文本的后验概率;
[0064]
评测模块205,用于若所述文本的后验概率小于所述拓展文本的后验概率,则基于所述拓展文本与所述第二语音进行gop评测;若所述文本的后验概率大于所述拓展文本的后验概率,则基于所述文本与所述第二语音进行gop评测。
[0065]
在一个具体的实施例中,还包括:
[0066]
处理模块,用于若所述置信度高于阈值,则通过所述语音评测模块基于所述文本与所述第二语音进行评测,得到语音发音质量的评价值。
[0067]
在一个具体的实施例中,所述语音识别模块包括:第一特征模块、第一声学模型和
语言模型;其中,所述第一特征模块的输出端分别连接所述第一声学模型和所述语言模型;所述第一声学模型和所述语言模型连接;
[0068]
所述第一特征模块输出的特征包括:mfcc特征、plp特征、filterbank特征;所述第一声学模型包括:dnn、ftdnn、transformer;所述第一声学模型的训练数据包括native和non
‑
native的数据;
[0069]
所述语言模型包括ngram、rnn。
[0070]
在一个具体的实施例中,所述语音评测模块,包括:第二特征模块、第二声学模型、扩展识别文本模块、评测模块;其中,所述第二特征模块的输出端连接所述第二声学模型;所述扩展识别文本模块连接所述语音识别模块;所述扩展识别文本模块、所述语音识别模块以及所述第二声学模型均连接所述评测模块。
[0071]
在一个具体的实施例中,所述拓展文本是基于对所述文本基于相似发音的原则进行拓展得到的。
[0072]
以此,本发明实施例提出了一种开放式的语音评测方法和设备,该方法包括:通过语音识别模块与语音评测模块获取待评测的语音,并分别设置为第一语音与第二语音;通过所述语音识别模块对所述第一语音进行文本识别,并确定识别到的文本的置信度;若所述置信度低于阈值,则通过所述语音评测模块对所述文本进行拓展,得到拓展文本;分别确定所述文本与所述拓展文本的后验概率;若所述文本的后验概率小于所述拓展文本的后验概率,则基于所述拓展文本与所述第二语音进行gop评测;若所述文本的后验概率大于所述拓展文本的后验概率,则基于所述文本与所述第二语音进行gop评测。本方案对语音进行文本识别,后续基于识别出的文本与语音进行评测,实现了对任意送进来的语音,都可以给出发音质量的评价的技术效果。
[0073]
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

