1.本发明涉及翻译技术领域,尤其是涉及一种融合句法信息的翻译质量自动评估方法。
背景技术:
2.随着神经机器翻译和自然语言技术的发展,如何自动地对翻译质量进行量化评估(翻译质量估计,quality estimation,qe)引起企业界和学术界的广泛关注。基于大数据驱动的翻译自动评估无需参考译文即可对翻译质量进行估计。目前,qe的方法主要可以归为三类:
①
基于特征工程;
②
基于神经网络;
③
基于预训练模型;方法
①
需要手动构建特征后输入传统的机器学习算法,此类方法以quest和quest 为代表,缺点是性能有限并且难以处理新的语言现象;方法
②
通常是两段式,在大量平行语料的基础上训练一个双语模型获得词表达,然后输入上层神经网络(如lstm),此类方法以predictor
‑
estimator为代表,缺点是需要大量的平行语料并且训练时间较长;方法
③
这一两年比较常用,利用多语言预训练模型(如mbert、xlm
‑
r)上接简单的全连接层即可获得较好的效果。纵观这些技术可以发现,现阶段的技术主要利用双语语义特征来对翻译质量进行估计。然而,语法特征在翻译质量估计中很少被考虑进去,制约模型的效果。
3.因此,本发明在预训练模型的基础上,通过图神经网络将句法信息纳入模型中,可以在一定程度上提高翻译质量估计的效果。
技术实现要素:
4.本发明的目的在于提供可提高翻译质量估计效果的一种融合句法信息的翻译质量自动评估方法。
5.本发明包括以下步骤:
6.1)获取输入文本的双语文本表示向;
7.2)将双语输入的文本分别构建句法依赖树,形成句法图;
8.3)利用图神经网络编码相关节点关系特征后拼接,上层接一个简单的sigmoid层输出质量分数;
9.4)模型的输出和数据标签的均方根误差误差作为损失,通过反向传播算法更新质量预测模型参数。
10.在步骤1)中,所述获取输入文本的双语文本表示向的具体方法可为:
11.(1)可采用双语预训练模型来获取输入文本的双语文本表示向;所述双语预训练模型包括xlm
‑
r或mbert;在模型训练过程中可进行参数微调;
12.(2)使用word2vec的方法;
13.(3)使用用开源工具包transformers获得已训练好的模型来搭建字向量表示层。
14.在步骤2)中,所述将双语输入的文本分别构建句法依赖树,形成句法图的具体方法可为:利用自建的句法依赖算法或者开源工具包,如nltk或spacy等抽取双语输入的句法
依赖关系;句子成分间的依赖关系使用有向图来表示;依赖关系图包含节点和节点之间的关系种类,用三元组表示,如:节点a,关系r,节点b。如此便将整个句子的句法依赖关系编码成三元组列表,[三元组1,三元组2,三元组3,
…
,三元组n];然后使用邻接矩阵将三元组列表转换为矩阵形式;邻接矩阵是个v*v的二维数组,其中v是图中的节点数量;设adj[][]是邻接矩阵,那么:
[0015][0016]
其中,(vi,vj)表示节点i到节点j的边;若(vi,vj)不存在,则adj[i][j]赋值为0;若(vi,vj)存在或者i=j,则adj[i][j]赋值为1。
[0017]
在步骤3)中,所述利用图神经网络编码相关节点关系特征是使用图神经网络将深度学习应用到图结构中,句法图的节点关系通过图神经网络进行编码,将双语输入分别编码成隐含向量hs和ht;所述图神经网络包括gnn、图卷积神经网络gcn、gat。
[0018]
所述上层接一个简单的sigmoid层输出质量分数,是将经过图神经网络编码后的双语表示hs和ht拼接后获得向量h=[hs:ht];此后连接一个全连接层作为输出层,输出层的激活函数为sigmoid获得输出out,即:
[0019]
out=sigmoid(wh b)
[0020]
其中,w是线性转换参数,b是偏置项;
[0021]
输出层的神经元的个数(即最终的输出个数)根据任务的具体情况而定;若是句子级的qe,神经元个数为1;若是单词级的qe,则神经元个数为单词的个数。
[0022]
与现有技术相比,本发明具有以下突出的优点和技术效果:
[0023]
本发明利用图神经网络巧妙地解决了在翻译质量自动评估中缺乏句法信息的引入问题,在翻译质量自动评估领域,尚未看到此类方法。本发明在预训练模型的基础上,加入图神经网络编码句法信息,使得模型能够同时表达语义和句法信息,比单独使用预训练模型能够在皮尔逊(pearson)相关系数上普遍提升约19%的效果。
附图说明
[0024]
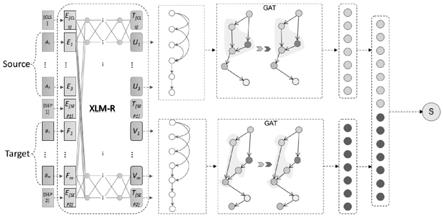
图1为本发明的模型架构图。
[0025]
图2为句法图的生成。
具体实施方式
[0026]
以下实施例将结合附图对本发明作进一步的说明。
[0027]
本发明实施例分为三个步骤:获取字向量表示;句法图生成及图神经网络;质量预测模型。同时这三个步骤也体现在图1的模型架构图中,下面分别对这三个部分进行说明。
[0028]
字向量表示:
[0029]
首先,需要获得输入的双语文本表示向量。本发明建议使用双语预训练模型,如xlm
‑
r(conneau等,2019)或者mbert(devlin等,2018)来获得输入文本的字向量表示,并在模型训练过程中进行参数微调。当然,使用word2vec的方法也可行。可以使用用开源工具包transformers(参考:https://github.com/huggingface/transformers)获得已训练好的
模型来搭建字向量表示层。如图1,源语言source和目标语言target经过xlm
‑
r后分别获得字向量e1,e2,
…
,e
n
和f1,f2,f
m
。
[0030]
句法树生成及图神经网络:
[0031]
该部分是本发明的核心部分。主要包含两大块内容:句法图生成和图神经网络。
[0032]
①
句法图生成
[0033]
利用自建的句法依赖算法或者开源工具包,如nltk或spacy等抽取双语输入的句法依赖关系。句子成分间的依赖关系可以使用有向图来表示(图2)。依赖关系图包含节点和节点之间的关系种类,可以用三元组表示,如(节点a,关系r,节点b)。如此便将整个句子的句法依赖关系编码成三元组列表,[三元组1,三元组2,三元组3,
…
,三元组n]。然后使用邻接矩阵将三元组列表转换为矩阵形式。邻接矩阵是个v*v的二维数组,其中v是图中的节点数量。设adj[][]是邻接矩阵,那么:
[0034][0035]
其中,(vi,vj)表示节点i到节点j的边。若(vi,vj)不存在,则adj[i][j]赋值为0。若(vi,vj)存在或者i=j,则adj[i][j]赋值为1。
[0036]
②
图神经网络
[0037]
图神经网络可以把深度学习应用到图结构中。句法图的节点关系可以通过图神经网络进行编码,常用的图神经网络有gnn,图卷积神经网络(graph dd)gcn,gat都可以编码节点关系。本实施例以gat为例。gat采用多头注意力机制(multi
‑
heads attention),可以为不同节点分配不同权重,训练时依赖于成对的相邻节点,而不依赖具体的网络结构。假设graph包含n个节点,每个节点的特征向量(通过2.1中获取)为则gat的输出如下所示:
[0038][0039]
其中,k表示注意力头的总数,表示节点i和节点j的第k个注意力头。w
k
是线性转换参数。ni代表i的邻居节点。σ表示激活函数,通常使用带泄露修正线性单元函数(leakyrelu)。如图1,通过这一步,将双语输入分别编码成隐含向量hs和ht。
[0040]
质量预测模型:
[0041]
将经过图神经网络编码后的双语表示hs和ht拼接后获得向量h=[hs:ht]。在此后连接一个全连接层作为输出层,激活函数为sigmoid以获得输出out,即:
[0042]
out=sigmoid(wh b)
[0043]
其中,w是线性转换参数,b是偏置项。输出层神经元的个数(即最终的输出个数)根据任务的具体情况而定。例如:若是句子级的qe,神经元个数为1;若是单词级的qe,则神经元个数为单词的个数。模型的输出作为质量分数,与数据的标签的均方根误差作为损失,通过反向传播算法进行整个模型参数的更新。
[0044]
本发明提出一种融合句法的翻译质量估计技术,在预训练模型的基础上,加入图神经网络编码句法信息,使得模型能够同时表达语义和句法信息。在2020年国际机器翻译大赛(wmt2020)的qe数据集中进行相关实验,结果表明,加入句法信息比单纯的预训练模型
比单独使用预训练模型能够在皮尔逊(pearson)相关系数上普遍提升约19%的效果。可见本发明方案可提高翻译质量估计效果,效果较好。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

