1.本发明涉及烟草工业领域,尤其涉及一种用于卷烟实时数采的数据缺失值填充方法。
背景技术:
2.现阶段的烟草生产一线,已从传统意义上的机械化、自动化向智能化、智慧化发展,尤其是物联网的进一步推广,现阶段已不仅仅是传统意义上的rs232、rs485、profinet、profibus、profibus
‑
dp、plc子网、wincc中控网络等。在此基础上,新增了物联网、nbiot网络、工业以太网等网络,随着设备数量、传感器数量的海量剧增,传统意义上对应的数采协议收到卷烟工业现场干扰噪声信号的影响将逐渐加大,造成实时数采数据缺失、数采数据错位等风险,严重影响现有设备的控制效能及信息系统的分析结果。
3.目前采用的解决方法是加大传感器校验量并设置多级校验机制,而设备本身检测有大概5%的误差,随着增设设备的数量增加必然会导致误差叠加累计,一旦过程中某传感器出现差错,将导致数据错误的“蝴蝶效应”,使得检测校验的效能近乎失效。
技术实现要素:
4.鉴于上述,本发明旨在提供一种用于卷烟实时数采的数据缺失值填充方法,解决新增了物联网、nbiot网络、工业以太网等复杂网络的同时,消除卷烟工业现场干扰噪声信号影响的问题,实现了实时数采数据的缺失值的自动填充。
5.本发明采用的技术方案如下:
6.一种用于卷烟实时数采的数据缺失值填充方法,其中包括:
7.在进行实时数据采集过程中,当检测到数据缺失时,根据已采集的数据以及预先构建的预测模型,预测出缺失的待填入数据;
8.根据预设的置信区间,校验所述待填入数据是否有效;
9.若有效,则将待填入数据补进实时数采数据的缺失位置。
10.在其中至少一种可能的实现方式中,所述预测模型被配置为:具有基于现场实际数据以及算法仿真数据所形成的虚实映射自学习机制。
11.在其中至少一种可能的实现方式中,所述方法还包括:在数采过程中,根据实际数据情况动态更新并迭代所述预测模型的参数。
12.在其中至少一种可能的实现方式中,所述根据实际数据情况动态更新并迭代所述预测模型的参数包括:根据卷烟原料等级、环境温湿度数据,并结合当前生产对应的牌号、批次号以及涉及的设备参数,持续训练并优化所述预测模型的参数。
13.在其中至少一种可能的实现方式中,所述预测模型的构建方式包括:
14.按照数据采样频率、数据结构、数据字段划分为若干个分组,并根据品牌、批次、工序段对所述分组进行分类及汇总;
15.检索并获取历史生产数据;
16.根据已确定的若干分组对所述历史生产数据进行整理,并向对应分组中导入所述历史生产数据得到样本集,所述历史生产数据包含原始的数采数据;
17.将所述样本集中的数据与真实生产情况进行关联,得到数据分布特征及映射特征;
18.根据所述样本集中的数据、所述数据分布特征以及所述映射特征训练所述预测模型,使所述预测模型输出预测期望值。
19.在其中至少一种可能的实现方式中,在所述预测模型的训练阶段,将预先设定的置信区间作为输入,使所述预测模型输出符合置信区间的预测期望值。
20.本发明的设计构思在于,通过大数据统计分析,以机器学习的方式,对实时数采数据的缺失值进行自动填充,结合自学习模型,将数采数据对应的预测值填入至缺失位置,并检测填充的缺失值是否在预测值的置信区间范围内。在此过程中,动态根据实际数据情况进行更新和迭代。本发明解决了卷烟工业现场干扰噪声信号影响的问题,实现了实时数采数据缺失值的自动填充,在确保控制精度的同时,并能保证信息系统分析结果的正确性、准确性。
附图说明
21.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步描述,其中:
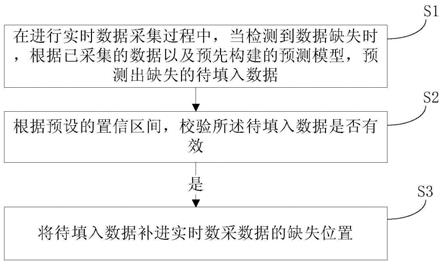
22.图1为本发明实施例提供的用于卷烟实时数采的数据缺失值填充方法的流程图。
具体实施方式
23.下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
24.本发明提出了一种用于卷烟实时数采的数据缺失值填充方法的实施例,具体来说,如图1所示,可以包括:
25.步骤s1、在进行实时数据采集过程中,当检测到数据缺失时,根据已采集的数据以及预先构建的预测模型,预测出缺失的待填入数据;
26.步骤s2、根据预设的置信区间,校验所述待填入数据是否有效;
27.若有效,则执行步骤s3、将待填入数据补进实时数采数据的缺失位置。
28.进一步地,所述预测模型被配置为:具有基于现场实际数据以及算法仿真数据所形成的虚实映射自学习机制。
29.进一步地,所述方法还包括:在数采过程中,根据实际数据情况动态更新并迭代所述预测模型的参数。
30.进一步地,所述根据实际数据情况动态更新并迭代所述预测模型的参数包括:根据卷烟原料等级、环境温湿度数据,并结合当前生产对应的牌号、批次号以及涉及的设备参数,持续训练并优化所述预测模型的参数。
31.进一步地,所述预测模型的构建方式包括:
32.按照数据采样频率、数据结构、数据字段划分为若干个分组,并根据品牌、批次、工
序段对所述分组进行分类及汇总;
33.检索并获取历史生产数据;
34.根据已确定的若干分组对所述历史生产数据进行整理,并向对应分组中导入所述历史生产数据得到样本集,所述历史生产数据包含原始的数采数据;
35.将所述样本集中的数据与真实生产情况进行关联,得到数据分布特征及映射特征;
36.根据所述样本集中的数据、所述数据分布特征以及所述映射特征训练所述预测模型,使所述预测模型输出预测期望值。
37.进一步地,在所述预测模型的训练阶段,将预先设定的置信区间作为输入,使所述预测模型输出符合置信区间的预测期望值。
38.综上所述,本发明的设计构思在于,通过大数据统计分析,以机器学习的方式,对实时数采数据的缺失值进行自动填充,结合自学习模型,将数采数据对应的预测值填入至缺失位置,并检测填充的缺失值是否在预测值的置信区间范围内。在此过程中,动态根据实际数据情况进行更新和迭代。本发明解决了卷烟工业现场干扰噪声信号影响的问题,实现了实时数采数据缺失值的自动填充,在确保控制精度的同时,并能保证信息系统分析结果的正确性、准确性。
39.本发明实施例中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示单独存在a、同时存在a和b、单独存在b的情况。其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项”及其类似表达,是指的这些项中的任意组合,包括单项或复数项的任意组合。例如,a,b和c中的至少一项可以表示:a,b,c,a和b,a和c,b和c或a和b和c,其中a,b,c可以是单个,也可以是多个。
40.以上依据图式所示的实施例详细说明了本发明的构造、特征及作用效果,但以上仅为本发明的较佳实施例,需要言明的是,上述实施例及其优选方式所涉及的技术特征,本领域技术人员可以在不脱离、不改变本发明的设计思路以及技术效果的前提下,合理地组合搭配成多种等效方案;因此,本发明不以图面所示限定实施范围,凡是依照本发明的构想所作的改变,或修改为等同变化的等效实施例,仍未超出说明书与图示所涵盖的精神时,均应在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

