1.本技术涉及计算机技术领域,尤其涉及一种语音数据的识别方法、装置、设备及存储介质。
背景技术:
2.随着计算机人工智能关键技术(自动语音识别技术、语音合成技术以及声纹识别技术)的飞速发展,生活中出现了许多的人工智能产品或人工智能平台,让计算机能听、能看、能说、能感觉,是未来人机交互的发展方向,其中语音识别技术成为未来最被看好的人机交互方式之一。语音识别技术作为常见的人工智能应用,已进入人们生活的方方面面,如地图导航、智能家电、语音搜索、文字与语音互相转换等。
3.纵然语音识别技术近年来取得了巨大进展,但当语音数据中包括信息点(地图上的非地理意义但有意义的点,如商店、酒吧、加油站等)时,针对语音数据中信息点的识别仍然面临很大的挑战。由于现有语音数据识别方法中的语音识别模型通常只与某一特定地域的信息点网络结合,从而导致语音识别模型在针对包含其他地域信息点的语音数据进行识别时,信息点识别不准确,进而导致语音数据的识别准确率低。由此可见,在语音识别技术领域中,如何提升对包括信息点的语音数据的识别准确率成为当今研究的热点问题。
技术实现要素:
4.本发明实施例提供了一种语音数据的识别方法、装置、设备及存储介质,可提升语音数据中信息点识别的准确率,从而提高语音数据的识别准确率。
5.一方面,本发明实施例提供了一种语音数据的识别方法,包括:
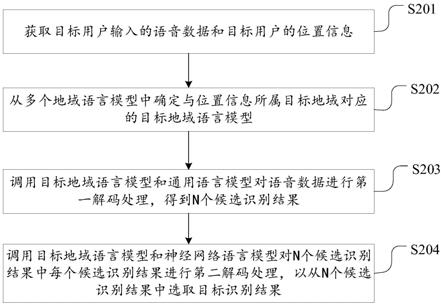
6.获取目标用户输入的语音数据和所述目标用户的位置信息;
7.从多个地域语言模型中确定与位置信息所属目标地域对应的目标地域语言模型,所述多个地域语言模型中任一地域语言模型是基于任一地域所包括的信息点进行训练得到的;
8.调用所述目标地域语言模型和通用语言模型对所述语音数据进行第一解码处理,得到n个候选识别结果;
9.调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果。
10.一方面,本发明实施例提供了一种语音数据的识别装置,包括:
11.获取单元,用于获取目标用户输入的语音数据和所述目标用户的位置信息;
12.确定单元,用于从多个地域语言模型中确定与所述位置信息所属目标地域对应的目标地域语言模型,所述多个地域语言模型中任一地域语言模型是基于任一地域所包括的信息点进行训练得到的;
13.处理单元,用于调用所述目标地域语言模型和通用语言模型对所述语音数据进行第一解码处理,得到n个候选识别结果;
14.所述处理单元,还用于调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果。
15.在一种实施方式中,所述处理单元在调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果时,具体用于执行:
16.获取所述n个候选识别结果中每个候选识别结果的第一融合概率,任一候选识别结果的第一融合概率是在对所述语音数据进行第一编码处理的过程中得到的;
17.调用所述目标地域语言模型和所述神经网络语言模型分别对所述每个候选识别结果进行处理,得到所述每个候选识别结果的第二融合概率;
18.基于所述每个候选识别结果的第一融合概率和所述每个候选识别结果的第二融合概率,从所述n个候选识别结果中选取目标识别结果。
19.在一种实施方式中,所述处理单元在基于所述每个候选识别结果的第一融合概率和所述每个候选识别结果的第二融合概率,从所述n个候选识别结果中选取目标识别结果时,具体用于执行:
20.将所述每个候选识别结果的第一融合概率和相应的候选识别结果的第二融合概率进行融合处理,得到所述每个候选识别结果的目标融合概率;
21.将所述n个候选识别结果中目标融合概率最大的候选识别结果作为目标识别结果。
22.在又一种实施方式中,所述处理单在所述将所述每个候选识别结果的第一融合概率和相应的候选识别结果的第二融合概率进行融合处理,得到所述每个候选识别结果的目标融合概率时,还具体用于执行:
23.获取所述n个候选识别结果中任一候选识别结果对应的声学概率,所述任一候选识别结果对应的声学概率是在对所述语音数据进行第一解码处理过程中得到的;
24.获取声学缩放参数以及融合比例参数,将所述声学概率进行对数运算,并将对数运算结果与所述声学缩放参数进行相乘运算,并按照所述融合比例参数将所述第一融合概率和所述第二融合概率进行融合处理;
25.将相乘运算结果和融合处理结果进行相加运算,得到所述任一候选识别结果的目标融合概率。
26.在又一种实施方式中,所述n个候选识别结果中包括目标候选识别结果,所述处理单元在获取所述n个候选识别结果中每个候选识别结果的第一融合概率时,具体用于执行:
27.调用所述目标地域语言模型对所述语音数据进行第一解码处理,得到所述目标候选识别结果的第一语言概率;
28.调用所述通用语言模型对所述语音数据进行第一解码处理,得到所述目标候选识别结果的第二语言概率;
29.采用第一融合参数对所述目标候选识别结果的第一语言概率和所述目标候选识别结果的第二语言概率进行融合处理,得到所述目标候选识别结果的融合语言概率;
30.基于所述目标候选识别结果的融合语言概率与所述目标候选识别结果的第二语言概率,得到所述目标候选识别结果的第一融合概率。
31.在又一种实施方式中,所述处理单元在调用所述目标地域语言模型和所述神经网络语言模型分别对所述每个候选识别结果进行处理,得到所述每个候选识别结果的第二融合概率时,具体用于执行:
32.获取所述目标候选识别结果的第一语言概率;
33.调用所述神经网络语言模型对所述目标候选识别结果进行第二解码处理,得到所述目标候选识别结果的第三语言概率;
34.采用第二融合参数对所述第一语言概率和所述第三语言概率进行融合处理,得到所述目标候选识别结果的第二融合概率。
35.再一种实施方式中,在所述确定单元基于所述位置信息确定所述语音数据对应的目标地域语言模型之前,所述确定单元还可用于:
36.获取目标地域的信息点数据,所述信息点数据包括至少一个信息点,以及所述至少一个信息点中每个信息点的信息点特征,其中,所述目标地域包括所述目标用户的位置信息所指示的位置,所述信息点特征包括以下一种或两种:信息点名称、信息点别名;
37.采用所述信息点特征对所述目标地域对应的地域语言模型进行训练,得到所述目标地域对应的目标地域语言模型。
38.一方面,本发明实施例还提供了一种语音数据的识别设备,该识别设备包括输入接口和输出接口,还包括:
39.处理器,适于实现一条或多条指令;
40.计算机存储介质,所述计算机存储介质存储有一条或多条指令,所述一条或多条指令适于由所述处理器加载并执行:
41.获取目标用户输入的语音数据和所述目标用户的位置信息;基于所述位置信息从多个地域语言模型中确定所述语音数据对应的目标地域语言模型,所述多个地域语言模型中任一地域语言模型是基于所述任一地域语言模型对应的地域所包括的信息点进行训练得到的;调用所述目标地域语言模型和通用语言模型对所述语音数据进行第一解码处理,得到n个候选识别结果;调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果。
42.一方面,本发明实施例提供了一种计算机存储介质,其特征在于,所述计算机存储介质存储有一条或多条指令,所述一条或多条指令适于由处理器加载并执行:
43.获取目标用户输入的语音数据和所述目标用户的位置信息;基于所述位置信息从多个地域语言模型中确定所述语音数据对应的目标地域语言模型,所述多个地域语言模型中任一地域语言模型是基于所述任一地域语言模型对应的地域所包括的信息点进行训练得到的;调用所述目标地域语言模型和通用语言模型对所述语音数据进行第一解码处理,得到n个候选识别结果;调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果。
44.一方面,本发明实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品包括计算机程序,该计算机程序存储在计算机存储介质中;终端的处理器从计算机存储介质中读取该计算机程序,处理器执行该计算机程序,使得语音数据的识别设备执行:
45.获取目标用户输入的语音数据和所述目标用户的位置信息;基于所述位置信息从多个地域语言模型中确定所述语音数据对应的目标地域语言模型,所述多个地域语言模型中任一地域语言模型是基于所述任一地域语言模型对应的地域所包括的信息点进行训练得到的;调用所述目标地域语言模型和通用语言模型对所述语音数据进行第一解码处理,得到n个候选识别结果;调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果。
46.在本发明实施例中,语音数据的识别设备获取目标用户输入的语音数据以及目标用户所在的位置信息,进一步的,从多个地域语言模型中确定出与位置信息所属目标地域对应的目标地域语言模型,多个地域语言模型中任一地域语言模型是基于任一地域包括的信息点训练得到的。应当理解的,基于每个地域包括信息点为每个地域单独地建立了地域语言模型,可以解决了传统的语音数据识别方法中,由于通用语言模型通常只与某一特定地域的信息点网络结合而导致的信息点识别不准确的问题。进一步的,语音数据的识别设备通过将目标地域语言模型分别与通用语言模型、神经网络语言模型进行结合,以对语音数据进行第一解码处理和第二解码处理,通过多次解码处理选择对语音数据的识别结果,可以进一步提高对语音数据的识别准确率。
附图说明
47.为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
48.图1a是本发明实施例提供的一种语音数据的识别系统的示意图;
49.图1b是本发明实施例提供的一种语音数据识别过程的示意流程图;
50.图1c是本发明实施例提供的一种语音数据识别方法的应用场景示意图;
51.图2是本发明实施例提供的一种语音数据的识别方法示意图;
52.图3是本发明实施例提供的又一种语音数据的识别方法示意图;
53.图4是本发明实施例提供的一种语音数据的识别装置示意图;
54.图5是本发明实施例提供的一种语音数据的识别设备的架构示意图。
具体实施方式
55.本发明实施例提供了一种语音数据的识别方法,该语音数据的识别方法可应用于多种语音识别场景中,如地图导航应用程序和车载导航系统中对信息点的查询场景。本发明实施例通过将目标地域语言模型与通用语言模型动态结合,对语音数据进行第一解码处理,得到n个候选识别结果,其中,目标地域语言模式是指与产生语音数据的目标用户所在地域对应的地域语言模型,目标地域语言模型是基于目标地域中包括的信息点训练得到的,由此可知,将目标地域语言模型和通用语言模型动态结合进行一遍解码,可以提高对语音数据中信息点识别的准确性;再将该目标地域语言模型和神经网络语言模型进行动态结合,应用于语音数据的第二解码处理过程中,以从该n个候选识别结果中确定出目标识别结果,解决了不同地域中发音相同、相似的信息点的语音识别问题,可以显著地改善用户所在
地域的地图信息点的识别准确率,其中,信息点可以是任何地图上的非地理意义但有意义的点,比如商店,酒吧,加油站,医院,车站等。
56.基于上述的语音数据的识别方法,本发明实施例提供了一种语音数据的识别系统,该语音数据的识别系统的结构示意图可参见图1a,如图1a所示,该系统包括终端101、服务器102,该终端可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能机器人、智能手表等,但并不局限于此,所述服务器102可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn、以及大数据和人工智能平台等基础云计算服务的云服务器。所述终端101和所述服务器102之间可以通过有线或无线的通信方式进行直接或间接的连接,本技术在此不做限制。
57.在一个实施例中,本技术实施例提供的语音数据的识别方法可以应用在服务器中,也可以应用在终端中。本技术实施例以该语音数据的识别方法应用在服务器中为例进行阐述。如图1b所示,服务器获取目标用户在终端输入的语音数据和该终端所在的位置信息,利用位置服务基于该位置信息转换为地域信息,并通过该地域信息确定语音数据的识别过程中所用的目标地域语言模型,不同的地域对应不同的目标地域语言模型,例如北京市采用地域语言模型1,重庆市采用地域语言模型1,深圳市采用地域语言模型3。服务器将该目标地域语言模型和通用语言模型结合,对该语音数据进行第一解码处理,得到该语音数据对应的n个候选识别结果;服务器再将该目标地域语言模型和神经网络语言模型进行动态结合,对该n个候选识别结果进行第二解码处理,以从该n个候选识别结果中确定目标识别结果,然后服务器将该目标识别结果输出到终端。
58.在一个示例性场景中,通过上述服务器对语音数据进行识别时,以终端中运行有地图导航应用程序为例,该地图导航应用程序可以通过用户输入的语音数据进行地点查询,且该地图导航应用程序可调用终端中的位置服务组件,以获取终端的位置信息。如图1c所示,图1c是本发明实施例提供的一种语音数据的识别的应用场景示意图。目标用户111通过点击运行在终端112中的地图导航app(application,应用程序)中的语音输入按钮1121,打开语音信号输入框1122,以获取用户输入的语音数据,假设该目标用户111输入的语音数据为“我要去a广场”,且目标用户111所在的“北京路”位于北京市。那么,地图导航app调用位置服务组件获取到该目标用户的位置信息为“北京市”,该语音数据为语音信号“我要去a广场”后,将该位置信息发送至服务器。服务器通过该位置信息确定目标地域语言模型为适用于识别北京方言的地域语言模型a,然后将地域语言模型a与通用语言模型结合,对该语音数据进行第一解码处理,得到n个候选识别结果,示例性地,假设n为2,该n个候选识别概率为“我要去a广场”和“我要去a2广场停车库”;服务器可再通过将地域语言模型a与神经网络语言模型结合,对上述2条候选识别结果进行第二解码处理,确定出该语音数据的识别结果为“我要去a广场”,然后将识别结果输入至终端112中进行显示。
59.请参见图2,图2是本发明实施例提供的一种语音数据的识别方法的示意图,如图2所示,该方法包括:
60.s201,获取目标用户输入的语音数据和目标用户的位置信息。
61.在一个实施例中,服务器可以通过指示地图导航app调用终端中的位置服务组件,以获取目标用户的位置信息,其中,该地图导航app运行在该终端中,该目标用户的位置信
息即为该终端所在的位置信息。
62.示例性地,假设目标用户位于北京市,正欲通过智能手机中安装的地图导航app指示前往a广场。地图导航app检测到目标用户打开语音输入框的操作后,在智能手机中显示语音数据框,并通过语音输入框获取目标用户输入的语音数据“我要去a广场”,然后,该地图导航app调用智能手机中的位置服务组件,获取到智能手机的位置信息为“北京市a区a街道”,然后地图导航app将语音数据“我要去a广场”和位置信息“北京市a区a街道”发送给服务器,以使得服务器将“北京市a区a街道”作为目标用户的位置信息。
63.s202,从多个地域语言模型中确定与位置信息所属目标地域对应的目标地域语言模型。
64.在一个实施例中,多个地域语言模型中任一地域语言模型是基于任一地域包括的信息点进行训练得到的,也就是说,不同的地域对应不同的地域语言模型,每个地域语言模型用于对该地域产生的语音数据进行识别处理(解码处理),如此一来可以避免由于不同地域包括相同信息点而引起的信息点识别不准确的问题。具体实施例中,地域语言模型可以是n元文法语言模型、递归神经网络类型的神经网络语言模型、卷积神经网络类型的神经网络语言模型等。其中,不同的地域可以理解为一个国家内不同的省市,例如可以将中国划分为34个省级地域,不同的区域也可以理解为一个方言区,例如将方言相同的重庆、四川和贵州作为一个地域,然后基于某个地域中的信息点名称训练与该地域对应的地域语言模型,以得到每个地域对应的地域语言模型,任一地域语言模型用于对该任一地域内产生的语音数据进行处理,通过此方式建立多个地域语言模型,解决了传统的语音数据识别方法中,由于通用语言模型通常只与某一特定地域的信息点网络结合而导致的用户不能进行跨地域信息点查询的问题,在实现跨区域信息点查询的同时,还能提升语音数据(尤其是包含信息点的语音数据)的识别准确度。
65.另外,由于目标地域语言模型是基于目标地域所包括的信息点训练得到的,那么在使用目标地域语言模型对包括信息点的语音数据进行识别时,只要语音数据中包括信息点即可,对输入语音数据的句式无要求。因此,本发明实施例可以支持对采用任意句式输入的语音数据进行识别,丰富了应用场景。
66.在一个实施例中,所述从多个地域语言模型中确定与所述位置信息所属目标地域对应的目标地域语言模型,包括:将该位置信息映射为地域索引,根据该地域索引确定位置信息所属目标地域;从多个地域语言模型中选择与该目标地域对应的地域语言模型作为目标地域语言模型。具体来说,服务器获取到目标用户的位置信息后,可以将该位置信息映射为地域索引,以使得服务器根据该地域索引确定目标用户所在的目标地域,进而根据该目标用户所在目标地域确定目标地域语言模型。该目标地域语言模型将用于语音数据的第一解码处理和第二解码处理中,该第一解码处理用于获取语音数据对应的n个候选识别结果,示例性地,n个候选识别结果可以具体为20条候选识别结果;该第二解码处理用于从n个候选识别结果中确定出目标识别结果,例如,从20条候选识别结果中确定出目标识别结果。
67.假设服务器获取到目标用户的位置信息为“北京市a区a街道”,语音数据为“我要去a广场”。服务器先将“北京市a区a街道”映射为地域索引“北京”,根据“北京”确定目标地域语言模型为适用于北京方言的地域语言模型a,然后将该地域语言模型a应用到对语音数据“我要去a广场”进行第一解码处理和第二解码处理的过程中。
68.s203,调用目标地域语言模型和通用语言模型对语音数据进行第一解码处理,得到n个候选识别结果。
69.在一个实施例中,通用语言模型可以是一个使用kneser
‑
ney平滑方式的n
‑
gram模型(n元模型),例如5
‑
gram模型,该通用语言模型可用于对任何地域内的语音数据进行解码处理。那么,n个候选识别结果可以是调用目标地域语言模型和通用语言模型,对语音数据进行第一解码处理过程中得到的所有的识别结果,比如调用目标地域语言模型和通用语言模型对语音数据进行第一解码处理后,共得到20个识别结果,那么n个候选识别结果可以是指这20个识别结果。
70.在其他实施例中,n个候选识别结果可以是从所有识别结果中选出的n个识别结果,比如从所有识别结果中选择出第一置信度排名靠前的n个识别结果,作为候选识别结果。具体地,当服务器得到m(m>n)个候选识别结果中每个候选识别结果的第一置信度后,可通过将每个候选识别结果的第一置信度进行由高到低的排序,选取前n个第一置信度中每个第一置信度对应的候选识别结果作为n个候选识别结果。
71.在本发明实施例中,每个识别结果的第一置信度可以通过第一融合概率来体现,也就是说n个候选识别结果中,每个候选识别结果对应一个第一融合概率,任一候选识别结果对应的第一融合概率是调用目标地域语言模型和通用语言模型对语音数据进行第一解码处理时得到的。假设n个候选识别结果中包括目标候选识别结果。下面以目标候选识别结果为例,介绍在调用目标地域语言模型和通用语言模型对语音数据进行第一解码处理中,如何得到该目标候选识别结果的第一融合概率。
72.服务器通过调用目标地域语言模型对语音数据进行第一解码处理,得到目标候选识别结果w对应的第一语言概率p
l
(w),再通过调用通用语言模型对该语音数据进行第一解码处理,得到该目标候选识别结果w对应的第二语言概率p
g
(w)。然后,服务器采用第一融合参数对该目标候选识别结果w对应的第一语言概率p
l
(w)和第二语言概率p
g
(w)进行融合处理,得到该目标候选识别结果w的融合语言概率log p
′1(w),进而根据目标候选识别结果w的融合语言概率和第二语言概率,确定该目标识别候选结果的第一融合概率log p1(w)。
73.其中,第一融合参数可以例如是α(α为大于零的常数,通常取值接近于1,如α=1.1),用于控制通用语言模型得到的第二语言概率p
g
(w)和目标地域语言模型得到的第一语言概率p
l
(w)的融合比例,α的值越大,尾部信息点(被少量用户搜索的信息点,通常是大量信息点,因此这些信息点在识别过程中通常不会被识别到)融合后的概率越高,进而在识别过程中针对同音词的选择(在同一个发音单元对应所有单词结果中选取一个单词,如在“w
ò”
这个发音单元对应的“卧”、“沃”、“握”等单词中选择其中一个)时,被选中的几率越高。
74.在一个实施例中采用第一融合参数对目标候选识别结果的第一语言概率和目标候选识别结果的第二语言概率进行融合处理,得到目标候选识别结果的融合语言概率,可以包括:服务器基于第一融合参数α对该目标候选识别结果w对应的第一语言概率p
l
(w)和第二语言概率p
g
(w)进行对数线性插值,以完成融合处理得到融合语言概率log p
′1(w)。该对数线性插值方式可具体如公式(1)所示:
75.log p
′1(w)=log p
l
(w)
‑
αlog p
g
(w)......公式(1)
76.由前述描述可知,服务器采用本发明实施例中公式(1)的方式确定每个候选识别结果的融合语言概率,可以提高尾部信息点的识别概率。
77.在第一解码处理时,上述根据目标候选识别结果w的融合语言概率和第二语言概率,确定该目标识别候选结果的第一融合概率log p1(w)可以通过取该目标候选识别结果对应的log p
g
(w)和log p
′1(w)的最大值实现,实现方式可具体如公式(2)所示:
78.log p1(w)=max(log p
g
(w),log p
′1(w))........公式(2)
79.本实施例中,在服务器得到目标候选识别结果的融合语言概率之后,又基于该目标候选识别结果的融合语言概率和第一语言概率选取得到该目标候选识别结果的第一融合概率,保证了整个语音数据识别模型对头部信息点(被大量用户搜索的信息点,通常是少量信息点,因此在同音词的选择时经常被优先选择)的识别性能和整个的语音数据识别模型的鲁棒性。
80.示例性地,假设服务器采用目标地域语言模型和通用语言模型对语音数据“我要去a广场”进行第一解码处理后,得到了目标候选识别结果“我要去a广场停车库”。若该目标候选识别结果在目标地域语言模型中的第一语言概率为a,且该目标候选识别结果在通用语言模型中的第二语言概率为b,那么,服务器对目标候选识别结果的第一语言概率和第二语言概率进行如上述公式(1)处理后,即可得到该目标候选识别结果的融合语言概率c,然后对融合语言概率c和第二语言概率b进行如上述公式(2)所示的处理,即可得到该目标候选识别结果的第一融合概率d,即,选取b和c中较大的值作为该目标候选识别结果的第一融合概率d。
81.在又一个实施例中,服务器还可调用声学模型、目标地域语言模型以及通用语言模型对语音数据进行第一解码处理,得到n个候选识别结果,以及n个候选识别结果中每个候选识别结果w的第一语言概率p
l
(w)、第二语言概率p
g
(w)和声学概率p
a
(w)。
82.s204,调用目标地域语言模型和神经网络语言模型对n个候选识别结果中每个候选识别结果进行第二解码处理,以从n个候选识别结果中选取目标识别结果。
83.在一个实施例中,神经网络语言模型用于预测任一候选识别结果中某个词出现在上一个词后面的概率,以得到该任一候选识别结果对应的语言概率(第三语言概率),例如针对“我要去a广场”这一候选识别结果,神经网络语言模型可用于预测“要”字出现在“我”字后面的概率、“去”字出现在“要”字后面的概率,
…
,“场”字出现在“广”字后面的概率,最终得到“我要去a广场”整个句子对应的第三语言概率。那么,目标识别结果可以是第二解码过程中,服务器基于全部候选识别结果的目标融合概率确定的,例如,将目标融合概率最大的候选识别结果作为目标识别结果。其中,目标融合概率可以是服务器基于该任一候选识别结果的声学概率、第一置信度和第二置信度得到的,第二置信度可以是服务器基于该任一候选识别结果的第三语言概率和该任一候选识别结果的第一语言概率得到的。
84.具体实施例中,任一候选识别结果的第二置信度可用第二融合概率来表示,其中,每个候选识别结果对应一个第二置信度(第二融合概率),且任一候选识别结果的第二置信度(第二融合概率)是在第二解码处理过程中得到的。下面以目标候选识别结果w为例,介绍在调用目标地域语言模型和神经网络语言模型对目标候选识别结果w进行第二解码处理时,如何得到该目标候选识别结果w的第二融合概率和目标融合概率。
85.首先,服务器将目标候选识别结果w作为神经网络语言模型的输入数据,并通过调用神经网络语言模型对该目标候选识别结果w进行第二解码处理,获取到该目标候选识别结果w的第三语言概率p
n
(w)。然后,服务器采用第二融合参数β对该目标候选识别结果w的
第三语言概率p
n
(w)和该目标候选识别结果w的第一语言概率p
l
(w)进行融合处理,得到该目标候选识别结果w的第二融合概率log p2(w),其中,第二融合参数β为常数,用于平衡目标地域语言模型和神经网络语言模型。示例性地,服务器可通过第二融合参数β(如β=0.2)对该目标候选识别结果w的第三语言概率p
n
(w)和该目标候选识别结果w的第一语言概率p
l
(w)进行如公式(3)所示的线性对数插值处理,以实现上述融合处理。
86.log p2(w)=βlog p
l
(w) (1
‑
β)log p
n
(w)
……
公式(3)
87.当服务器获取到目标候选识别结果w的第二融合概率log p2(w)后,采用融合比例参数λ和声学缩放参数η,基于该目标候选识别结果的第一融合概率log p1(w)和声学概率p
a
(w)得到该目标候选识别结果的目标融合概率s(w)。示例性地,服务器对声学概率进行对数运算,并将对数运算结果log p
a
(w)与声学缩放参数η进行相乘运算,得到运算结果,并通过融合比例参数λ将该目标候选识别结果w的第一融合概率p1(w)和第二融合概率p2(w)进行融合处理,得到融合结果;然后将该目标候选识别结果w的相乘运算结果和融合结果进行相加运算,得到该目标候选识别结果w的目标融合概率s(w)。
88.其中,按照融合比例参数λ将第一融合概率和第二融合概率进行融合处理,包括:对第一融合概率融合比例参数λ进行对数运算得到log p1(w),以及对第二融合概率p2(w)进行对数运算得到log p2(w),最后,根据融合比例参数对log p1(w)和log p2(w)进行融合处理。根据上述描述,目标候选识别结果的目标融合概率可以表示为如公式(4)所示。
89.s(w)=ηlog p
a
(w) λlog p1(w) (1
‑
λ)log p2(w)
……
公式(4)
90.其中,声学缩放参数η是一个常数,用于平衡声学模型和语言模型,第二融合参数λ用于控制第一融合概率和第二融合概率的融合比例,示例性地,η=0.84,λ=0.5。那么,服务器可以通过上述方法得到n个候选识别结果中每个候选识别结果的目标融合概率。然后,当目标候选识别结果的目标融合概率为n个候选识别结果中目标融合概率最大的时,服务器可确定该目标候选识别结果为目标识别结果。
91.本实施例中,服务器在进行目标识别结果的选择时,针对n个候选识别结果中任一候选识别结果,不仅使用了第二融合参数对该任一识别结果的第一语言概率和第三语言概率进行融合得到了第二融合概率,还使用了融合比例参数和声学缩放参数对该任一候选识别结果的第一融合概率、第二融合概率以及声学概率进行融合,以得到目标融合概率,此种融合方式进一步提升了语音数据的识别准确率。
92.示例性地,假设语音数据“我要去a广场”对应的两个(n=2)候选识别结果为“我要去a广场停车库”和“我要去a广场”,且两个候选识别结果的目标融合概率如下:我要去a广场停车库”的目标融合概率为
“‑
100”(对数概率值),“我要去a广场”的目标融合概率为
“‑
90”(对数概率值),那么,服务器将把候选识别结果“我要去a广场”作为目标识别结果。
93.本技术实施例中,在本发明实施例中,语音数据的识别设备获取目标用户输入的语音数据以及目标用户所在的位置信息,进一步的,从多个地域语言模型中确定出与位置信息所属目标地域对应的目标地域语言模型,多个地域语言模型中任一地域语言模型是基于任一地域包括的信息点训练得到的。应当理解的,基于每个地域包括信息点为每个地域单独地建立了地域语言模型,可以解决了传统的语音数据识别方法中,由于通用语言模型通常只与某一特定地域的信息点网络结合而导致的信息点识别不准确的问题。进一步的,语音数据的识别设备通过将目标地域语言模型分别与通用语言模型、神经网络语言模型进
行结合,以对语音数据进行第一解码处理和第二解码处理,通过多次解码处理选择对语音数据的识别结果,可以进一步提高对语音数据的识别准确率。
94.请参见图3,图3是本发明实施例提供的又一种语音数据的识别方法示意图,如图3所示,该方法包括:
95.s301,获取目标用户输入的语音数据和目标用户的位置信息。
96.在一个实施例中,步骤s301包括的一些可行的实施方式已在图2实施例中相关步骤进行详细描述,在此不再赘述。
97.s302,从多个地域语言模型中确定与位置信息所属目标地域对应的目标地域语言模型。
98.在一个实施例中,由于现有技术中仅采用通用语言模型对语音数据进行解码的方法(通用的语言模型建模方法)难以有效描述全部的信息点数据,因此本实施例采用了分地域进行语言建模的方案来提升信息点的识别率。具体地,服务器可在确定目标地域语言模型之前对地域语言模型进行训练,以得到目标地域语言模型。具体地,服务器可获取目标地域的信息点数据,信息点数据包括至少一个信息点,以及该至少一个信息点中每个信息点的信息点特征,其中,目标地域包括目标用户的位置信息所指示的位置,信息点特征包括以下一种或两种:信息点名称、信息点别名,服务器再采用信息点特征对目标地域对应的地域语言模型进行训练,得到目标地域对应的目标地域语言模型。
99.具体实施例中,目标地域为目标用户的位置信息所指示的位置所在的区域,如目标用户的位置信息为“a市b街区”时,其对应的目标地域为a市,那么,此种情况下,信息点数据由a市内的所有信息点中每个信息点的名称以及信息点的别名组成,例如,由信息点x及其别名信息点x1,信息点y及其别名信息点y1组成。然后,服务器采用这些信息点数据对a市对应的地域语言模型进行训练,得到a市对应的目标地域语言模型,该目标地域语言模型适用于对a市所用的方言语音数据进行识别处理。
100.s303,调用目标地域语言模型和通用语言模型对语音数据进行第一解码处理,得到n个候选识别结果。
101.在一个实施例中,第一解码处理的具体过程可以如下所述:服务器可预设数据库,该数据库中存在由所有字词组成的网络关系,该网络关系用于指示语言模型将单个的字词进行排序,以组成候选识别结果。服务器可调用声学模型对语音数据进行第一解码处理,以得到语音数据对应的p个发音序列,以及p个发音序列中每个发音序列对应的声学概率其中,发音序列由单个的字词对应的发音单元组成。然后服务器调用目标地域语言模型和通用语言模型对p个发音序列中任一发音序列对应的字词进行第一解码处理,得到q个候选识别结果,以及q个候选识别结果中每个候选识别结果对应的第一语言概率,其中,该q个候选识别结果均有一个声学概率,且该声学概率为该q个候选识别结果对应的任一发音序列的声学概率。
102.具体地,目标地域语言模型和通用语言模型可通过任一发音序列中的任一发音单元和网络关系,在该数据库中查找对应的字词,以及排列在该字词后面的下一个字词。对于任一候选识别结果的第一语言概率,可通过将组成该任一候选识别结果中的所有字词在目标地域语言模型中的概率进行运算得到,对于任一候选识别结果的第二语言概率,可通过将组成该任一候选识别结果中的所有字词在通用语言模型中的概率进行运算得到。
103.示例性地,假设现有语音数据为“我要去a广场”对应的一个发音序列{wo,yao,qu,a,guang,chang},那么,服务器可在声学模型得到发音序列中的任一发音单元后,根据该发音单元进行字词查找,例如根据发音单元“wo”调用目标地域语言模型和通用语言模型在数据库中查找到字词“我”、“窝”、“握”等,并得到“我”、“窝”、“握”各自对应的概率;然后服务器基于该数据库中的网络关系,查找可能排列在“我”后面的字词(第二个字词),以及这些字词对应的概率,例如查找到“要”、“邀”、“能”、“是”等,然后服务器根据发音单元“yao”确定第二个字词可能为“要”、“邀”,并得到“要”在目标地域语言模型中对应的概率a和在通用语言模型中对应的概率a,以及得到“邀”在目标地域语言模型中对应的概率b和在通用语言模型中对应的概率b,以此方式最终得到整个发音序列对应的2个候选识别结果:“我要去a广场”、“我要去a广场停车库”。对于“我要去a广场”的第一语言概率,可通过“我”、“要”、“去”、“a”、“广”、“场”这些字词在目标地域语言模型中的概率进行运算得到;对于“我要去a广场”的第二语言概率,可通过“我”、“要”、“去”、“a”、“广”、“场”这些字词在通用语言模型中的概率进行运算得到。
104.s304,获取n个候选识别结果中每个候选识别结果的第一融合概率。
105.在一个实施例中,具体实施方式请参见步骤s203中的详细描述,在此不再赘述。
106.s305,调用目标地域语言模型和神经网络语言模型分别对每个候选识别结果进行处理,得到每个候选识别结果的第二融合概率。
107.s306,基于每个候选识别结果的第一融合概率和每个候选识别结果的第二融合概率,从n个候选识别结果中选取目标识别结果。
108.在一个实施例中,步骤s305至步骤s306的具体实施方式请参见步骤s204中的详细描述,在此不再赘述。
109.经过实验发现,在服务器获取到目标用户的语音数据测试集之后,分别使用传统语音数据的识别方法和本技术中的语音数据的识别方法对语音数据测试集进行处理,以得到不同语音数据的识别方法对应的字符错误率,实验结果如下表所示:
110.测试数据传统识别方法的错误率本技术方法的错误率测试集15.02%3.90%测试集24.38%3.82%
111.其中,测试集1和测试集2都是通过腾讯地图app业务,从全国31个地域中的用户对应的语音数据中采集得到的,字符错误率越低表示语音数据的识别方法对应的识别系统性能越好、识别准确率越高。由上表可见,本技术提供的语音数据的识别方法能够显著提高信息点的识别准确率。
112.本技术实施例中,服务器基于每个地域的信息点为每个地域单独地建立了地域语言模型,并通过用户的位置信息确定该次语音数据的识别过程所要用的目标地域语言模型,解决了传统的语音数据识别方法中,由于通用语言模型通常只与某一特定地域的信息点网络结合而导致的信息点识别不准确的问题;又通过将目标地域语言模型分别与通用语言模型、神经网络语言模型进行结合,以对语音数据进行第一解码处理和第二解码处理,进一步改善了用户输入的语音数据的识别准确率。
113.基于上述语音数据的识别方法实施例的描述,本发明实施例还公开了一种语音数据的识别装置,所述语音数据的识别装置可以是运行于上述所提及的服务器中的一个计算
机程序(包括程序代码)。该语音数据的识别装置可以执行图2或图3所示的方法。请参见图4,所述语音数据的识别装置可以包括:获取单元401,确定练单元402和处理单元403。
114.获取单元401,用于获取目标用户输入的语音数据和所述目标用户的位置信息;
115.确定单元402,用于从多个地域语言模型中确定与所述位置信息所属目标地域对应的目标地域语言模型,所述多个地域语言模型中任一地域语言模型是基于所述任一地域所包括的信息点进行训练得到的;
116.处理单元403,用于调用所述目标地域语言模型和通用语言模型对所述语音数据进行第一解码处理,得到n个候选识别结果;
117.处理单元403,还用于调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果。
118.在一种实施方式中,所述处理单元403在调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果时,具体用于执行:
119.获取所述n个候选识别结果中每个候选识别结果的第一融合概率,任一候选识别结果的第一融合概率是在对所述语音数据进行第一编码处理的过程中得到的;
120.调用所述目标地域语言模型和所述神经网络语言模型分别对所述每个候选识别结果进行处理,得到所述每个候选识别结果的第二融合概率;
121.基于所述每个候选识别结果的第一融合概率和所述每个候选识别结果的第二融合概率,从所述n个候选识别结果中选取目标识别结果。
122.在又一种实施方式中,所述处理单元403在基于所述每个候选识别结果的第一融合概率和所述每个候选识别结果的第二融合概率,从所述n个候选识别结果中选取目标识别结果时,具体用于执行:
123.将所述每个候选识别结果的第一融合概率和相应的候选识别结果的第二融合概率进行融合处理,得到所述每个候选识别结果的目标融合概率;
124.将所述n个候选识别结果中目标融合概率最大的候选识别结果作为目标识别结果。
125.在又一种实施方式中,所述处理单元403在所述将所述每个候选识别结果的第一融合概率和相应的候选识别结果的第二融合概率进行融合处理,得到所述每个候选识别结果的目标融合概率时,还具体用于执行:
126.获取所述n个候选识别结果中任一候选识别结果对应的声学概率,所述任一候选识别结果对应的声学概率是在对所述语音数据进行第一解码处理过程中得到的;
127.获取声学缩放参数以及融合比例参数,将所述声学概率进行对数运算,并将对数运算结果与所述声学缩放参数进行相乘运算,并按照所述融合比例参数将所述第一融合概率和所述第二融合概率进行融合处理;
128.将相乘运算结果和融合处理结果进行相加运算,得到所述任一候选识别结果的目标融合概率。
129.在又一种实施方式中,所述n个候选识别结果中包括目标候选识别结果,所述处理单元403在获取所述n个候选识别结果中每个候选识别结果的第一融合概率时,具体用于执
行:
130.调用所述目标地域语言模型对所述语音数据进行第一解码处理,得到所述目标候选识别结果的第一语言概率;
131.调用所述通用语言模型对所述语音数据进行第一解码处理,得到所述目标候选识别结果的第二语言概率;
132.采用第一融合参数对所述目标候选识别结果的第一语言概率和所述目标候选识别结果的第二语言概率进行融合处理,得到所述目标候选识别结果的融合语言概率;
133.基于所述目标候选识别结果的融合语言概率与所述目标候选识别结果的第二语言概率,得到所述目标候选识别结果的第一融合概率。
134.在又一种实施方式中,所述处理单元403在调用所述目标地域语言模型和所述神经网络语言模型分别对所述每个候选识别结果进行处理,得到所述每个候选识别结果的第二融合概率时,具体用于执行:
135.获取所述目标候选识别结果的第一语言概率;
136.调用所述神经网络语言模型对所述目标候选识别结果进行第二解码处理,得到所述目标候选识别结果的第三语言概率;
137.采用第二融合参数对所述目标候选识别结果的第一语言概率和所述目标候选识别结果的第三语言概率进行融合处理,得到所述目标候选识别结果的第二融合概率。
138.再一种实施方式中,在所述确定单元402基于所述位置信息从多个地域语言模型中确定所述语音数据对应的目标地域语言模型之前,所述确定单元402还可用于:
139.获取目标地域包括的信息点数据,所述信息点数据包括至少一个信息点,以及所述至少一个信息点中每个信息点的信息点特征,任一信息点的信息点特征包括以下一种或两种:信息点名称以及信息点别名;
140.采用所述每个信息点的信息点特征进行地域语言模型训练,得到所述目标地域对应的目标地域语言模型。
141.根据本发明的一个实施例,图2和图3所示的语音数据的识别方法所涉及各个步骤可以是由图4所示的语音数据的识别装置中的各个单元来执行的。例如,图2所述的步骤s201可由图4所述的语音数据的识别装置中获取单元401来执行,步骤s202可由图4所示的语音数据的识别装置中的确定单元402来执行,步骤s203和步骤s204均可由图4所示的语音数据的识别装置中的处理单元403来执行;再如,图3所示的步骤s301和步骤s304均可由图4所示的语音数据的识别装置中的获取单元401来执行,步骤s302可由图4所示的语音数据的识别装置中的确定单元402来执行,步骤s303、步骤s305以及步骤s306均可由图4所示的语音数据的识别装置中的处理单元403来执行。
142.根据本发明的另一个实施例,图4所示的语音数据的识别装置中的各个单元是基于逻辑功能划分的,上述各个单元可以分别或全部合并为一个或若干个另外的单元来构成,或者其中的某个(些)单元还可以再拆分为功能上更小的多个单元来构成,这可以实现同样的操作,而不影响本发明的实施例的技术效果的实现。在本发明的其它实施例中,上述语音数据的识别装置也可以包括其它单元,在实际应用中,这些功能也可以由其它单元协助实现,并且可以由多个单元协作实现。
143.根据本发明的另一个实施例,可以通过在包括中央处理单元(cpu)、随机存取存储
介质(ram)、只读存储介质(rom)等处理元件和存储元件的例如计算机的通用计算设备上运行能够执行如图2或图3所示的相应方法所涉及的各步骤的计算机程序(包括程序代码),来构造如图4中所示的语音数据的识别装置,以及来实现本发明实施例的语音数据的识别方法。所述计算机程序可以记载于例如计算机存储介质上,并通过计算机存储介质装载于上述计算设备中,并在其中运行。
144.在本发明实施例中,处理单元基于每个地域的信息点为每个地域单独地建立了地域语言模型,并通过确定单元基于用户的位置信息确定该次语音数据的识别过程所要用的目标地域语言模型,解决了传统的语音数据识别方法中,由于通用语言模型通常只与某一特定地域的信息点网络结合而导致的信息点识别不准确的问题;又通过处理单元将目标地域语言模型分别与通用语言模型、神经网络语言模型进行结合,以对语音数据进行第一解码处理和第二解码处理,进一步改善了用户输入的语音数据的识别准确率。
145.基于上述方法实施例以及装置实施例的描述,本发明实施例还提供一种语音数据的识别设备。请参见图5,该语音数据的识别设备至少包括处理器501、输入接口502、输出接口503以及计算机存储介质504,且计算机设备内的处理器501、输入接口502、输出接口503以及计算机存储介质504可通过总线或其他方式连接。
146.所述计算机存储介质504是计算机设备中的记忆设备,用于存放程序和数据。可以理解的是,此处的计算机存储介质504既可以包括语音数据的识别设备中的内置存储介质,当然也可以包括计算机设备所支持的扩展存储介质。计算机存储介质504提供存储空间,该存储空间存储了计算机设备的操作系统。并且,在该存储空间中还存放了适于被处理器501加载并执行的一条或多条的指令,这些指令可以是一个或一个以上的计算机程序(包括程序代码)。需要说明的是,此处的计算机存储介质可以是高速ram存储器,也可以是非不稳定的存储器(non
‑
volatile memory),例如至少一个磁盘存储器;可选的还可以是至少一个位于远离前述处理器的计算机存储介质。所述处理器501(或称cpu(central processing unit,中央处理器))是计算机设备的计算核心以及控制核心,其适于实现一条或多条指令,具体适于加载并执行一条或多条指令从而实现相应方法流程或相应功能。
147.在一个实施例中,可由处理器501加载并执行计算机存储介质504中存放的一条或多条指令,以实现上述有关图2和图3所示的语音数据的识别方法实施例中的相应方法步骤;具体实现中,计算机存储介质504中的一条或多条指令由处理器501加载并执行如下步骤:
148.获取目标用户输入的语音数据和所述目标用户的位置信息;
149.从多个地域语言模型中确定与所述位置信息所属目标地域对应的目标地域语言模型,所述多个地域语言模型中任一地域语言模型是基于所述任一地域所包括的信息点进行训练得到的;
150.调用所述目标地域语言模型和通用语言模型对所述语音数据进行第一解码处理,得到n个候选识别结果;
151.调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所述n个候选识别结果中选取目标识别结果。
152.在一种实施方式中,计算机存储介质504中所述调用所述目标地域语言模型和神经网络语言模型对所述n个候选识别结果中每个候选识别结果进行第二解码处理,以从所
述n个候选识别结果中选取目标识别结果指令,具体由处理器501加载并执行:
153.获取所述n个候选识别结果中每个候选识别结果的第一融合概率,任一候选识别结果的第一融合概率是在对所述语音数据进行第一编码处理的过程中得到的;
154.调用所述目标地域语言模型和所述神经网络语言模型分别对所述每个候选识别结果进行处理,得到所述每个候选识别结果的第二融合概率;
155.基于所述每个候选识别结果的第一融合概率和所述每个候选识别结果的第二融合概率,从所述n个候选识别结果中选取目标识别结果。
156.在又一种实施方式中,计算机存储介质504中所述基于所述每个候选识别结果的第一融合概率和所述每个候选识别结果的第二融合概率,从所述n个候选识别结果中选取目标识别结果指令,具体由处理器501加载并执行:
157.将所述每个候选识别结果的第一融合概率和相应的候选识别结果的第二融合概率进行融合处理,得到所述每个候选识别结果的目标融合概率;
158.将所述n个候选识别结果中目标融合概率最大的候选识别结果作为目标识别结果。
159.在又一种实施方式中,计算机存储介质504中所述将所述每个候选识别结果的第一融合概率和相应的候选识别结果的第二融合概率进行融合处理,得到所述每个候选识别结果的目标融合概率指令,具体由处理器501加载并执行:
160.获取所述n个候选识别结果中任一候选识别结果对应的声学概率,所述任一候选识别结果对应的声学概率是在对所述语音数据进行第一解码处理过程中得到的;
161.获取声学缩放参数以及融合比例参数,将所述声学概率进行对数运算,并将对数运算结果与所述声学缩放参数进行相乘运算,并按照所述融合比例参数将所述第一融合概率和所述第二融合概率进行融合处理;
162.将相乘运算结果和融合处理结果进行相加运算,得到所述任一候选识别结果的目标融合概率。
163.在又一种实施方式中,所述n个候选识别结果中包括目标候选识别结果,计算机存储介质504中所述获取所述n个候选识别结果中每个候选识别结果的第一融合概指令,具体由处理器501加载并执行:
164.调用所述目标地域语言模型对所述语音数据进行第一解码处理,得到所述目标候选识别结果的第一语言概率;
165.调用所述通用语言模型对所述语音数据进行第一解码处理,得到所述目标候选识别结果的第二语言概率;
166.采用第一融合参数对所述目标候选识别结果的第一语言概率和所述目标候选识别结果的第二语言概率进行融合处理,得到所述目标候选识别结果的融合语言概率;
167.基于所述目标候选识别结果的融合语言概率与所述目标候选识别结果的第二语言概率,得到所述目标候选识别结果的第一融合概率。
168.在又一种实施方式中,计算机存储介质504中所述调用所述目标地域语言模型和所述神经网络语言模型分别对所述每个候选识别结果进行处理,得到所述每个候选识别结果的第二融合概率指令,具体由处理器501加载并执行:
169.获取所述目标候选识别结果的第一语言概率;
170.调用所述神经网络语言模型对所述目标候选识别结果进行第二解码处理,得到所述目标候选识别结果的第三语言概率;
171.采用第二融合参数对所述目标候选识别结果的第一语言概率和所述目标候选识别结果的第三语言概率进行融合处理,得到所述目标候选识别结果的第二融合概率。
172.在又一种实施方式中,在计算机存储介质加载所述基于所述位置信息从多个地域语言模型中确定所述语音数据对应的目标地域语言模型指令之前,处理器501还用于加载并执行如下步骤:
173.获取目标地域包括的信息点数据,所述信息点数据包括至少一个信息点,以及所述至少一个信息点中每个信息点的信息点特征,任一信息点的信息点特征包括以下一种或两种:信息点名称以及信息点别名;
174.采用所述每个信息点的信息点特征进行地域语言模型训练,得到所述目标地域对应的目标地域语言模型。
175.在本发明实施例中,处理器基于每个地域的信息点为每个地域单独地建立了地域语言模型,并通过处理器基于用户的位置信息确定该次语音数据的识别过程所要用的目标地域语言模型,解决了传统的语音数据识别方法中,由于通用语言模型通常只与某一特定地域的信息点网络结合而导致的信息点识别不准确的问题;又通过处理器将目标地域语言模型分别与通用语言模型、神经网络语言模型进行结合,以对语音数据进行第一解码处理和第二解码处理,进一步改善了用户输入的语音数据的识别准确率。
176.本技术实施例还提供了一种计算机存储介质,该计算机存储介质中存储了上述语音数据的识别方法的计算机程序,该计算机程序包括程序指令,当一个或多个处理器加载并执行该程序指令,可以实现实施例中对语音数据的识别方法的描述,在此不再赘述。对采用相同方法的有益效果的描述,在此不再赘述。可以理解的是,程序指令可以被部署在一个或多个能够相互通信的设备上执行。
177.需要说明的是,根据本技术的一个方面,还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。语音数据的识别设备中的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该语音数据的识别设备执行上述图2和图3所示的语音数据的识别方法实施例方面的各种可选方式中提供的方法。
178.并且,应理解的是,以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。