本申请涉及大数据交换技术领域,尤其涉及一种数据交换系统及方法。
背景技术
当前,各政府和企业一般都设计和建设了属于机构、业务本身的应用、流程以及数据的信息处理系统,独立、异构、涵盖各自业务内容的信息处理系统,设计建设的时期不同、业务模式不同,信息化建设缺乏有效的总体规划,重复建设;缺乏统一的设计标准,大多数系统都是由不同的厂商在不同的平台上,使用不同的语言进行开发的,数据传输受限、信息交互共享困难,存在大量的信息孤岛和流程孤岛。
技术实现要素:
本申请实施例提供了一种数据交换系统及方法,用以解决现有的大数据交换技术信息交互共享困难,存在大量信息孤岛的技术问题。
一方面,本申请实施例提供了一种数据交换系统,系统包括:应用服务总线模块,用于不同应用系统的服务接入及服务管理;数据服务总线模块,包括服务协议适配子模块、分布式消息队列子模块、分布式数据缓存子模块、分布式数据分发子模块、分布式服务调度子模块以及服务调用适配子模块,用于实现数据的传输;数据加工/离线分析扩展模块,用于对传输数据进行处理分析;安全管理模块,用于保障数据交换系统的应用访问安全及数据传输安全;平台管控模块,用于监控所述传输数据的处理分析过程以及数据传输过程。
本申请实施例提供的数据交换系统,通过采用通信、集成、服务交互、服务安全、服务质量、服务等级等技术及管理手段,对各信息系统进行二次规划、整体提升、高度集成,全面提升系统运行效率和效果,彻底解决数据孤岛和系统集成问题,从而实现全价值链智能运营一体化管理,确保信息流的全面受控,为决策提供准确的信息支持,很好的解决了信息孤岛的问题。同时,数据服务总线模块的建设,运用大数据技术,搭建集群部署,不仅解决了大数据传输的问题,而且提高了大数据传输效益,提升数据安全访问和读取速度,缩短响应时间,丰富智能监控服务。
在本申请的一种实现方式中,应用服务总线模块至少用于实现以下任一项或者多项功能:消息过滤功能、数据格式转换功能、智能路由功能、协议适配功能以及消息订阅与发布功能。实现了跨地域、跨部门、跨平台不同应用系统直接的服务集成和服务共享。
在本申请的一种实现方式中,所述数据加工/离线分析扩展模块包括数据加工子模块、数据稽查子模块、数据建模子模块以及工作流调度子模块。
在本申请的一种实现方式中,所述安全管理模块包括:Web安全子模块,用于保障传输数据接入所述数据交换系统之前的web安全;数据安全管理子模块,用于保障传输数据接入所述数据交换系统之后的数据安全;访问安全管理子模块,用于保障所述数据交换系统对结构化数据的访问安全。
在本申请的一种实现方式中,所述平台管控模块至少用于实现以下任一项或者多项功能:服务管理功能、统计管理功能、监控管理功能以及系统管理功能。
另一方面,本申请实施例还提供了一种数据交换方法,应用如上述的一种数据交换系统,方法包括:所述数据交换系统接收服务调用方发送的调用请求,并将所述调用请求与服务调用日志进行对比;在确定所述服务调用日志中不存在所述调用请求的情况下,将所述调用请求发送给服务提供方,并接收所述服务提供方返回的服务响应结果;将所述服务响应结果进行缓存,并发送至所述服务调用方。
在本申请的一种实现方式中,所述方法还包括:所述数据交换系统确定所述服务调用日志中存在所述调用请求;将所述调用请求与缓存的服务响应结果进行请求匹配,并在所述请求匹配成功的情况下,将所述服务响应结果发送至所述服务调用方。
在本申请的一种实现方式中,所述服务响应结果包括服务请求元数据以及服务数据文件;所述将所述服务响应结果进行缓存,具体包括:所述数据交换系统将所述服务请求元数据缓存至kafka消息队列中,以及将所述服务数据文件缓存至MongoDB GridFS分布式文件存储系统中;所述将所述服务响应结果发送至所述服务调用方,具体包括:所述数据交换系统在所述MongoDB GridFS分布式文件存储系统中确定所述调用请求对应的服务数据文件;将所述服务数据文件通过Storm流式计算框架发送给所述服务调用方。
本申请实施例中的数据服务总线采用了Kafka消息队列、MongoDB GridFS分布式文件存储系统、Storm流式计算框架三大主流大数据技术。kafka实现数据请求队列、数据缓存块、大文件元数据缓存系统三大功能,MongoDB GridFS实现大文件分布式缓存系统,Storm实现并发数据读取和数据汇总功能。数据服务总线充分与大数据相关服务进行结合,利用大数据解决大文件及消息的高效传输问题,同时实现了不同应用系统间的信息交互。
在本申请的一种实现方式中,所述方法还包括:日志收集系统Flume采集所述数据交换系统中各个模块产生的日志数据,并将所述日志数据存储至kafka消息队列中;日志管理平台logstash将所述kafka消息队列中的日志数据接入到搜索服务器ElasticSearch中,并建立对应的索引数据;可视化平台kibana基于所述索引数据对所述日志数据进行可视化分析与展示。
在本申请的一种实现方式中,所述方法还包括:分布式文件系统HDFS以预设时间为间隔,接收来自所述kafka消息队列的日志数据,并将所述日志数据输入到预设分析引擎中;所述预设分析引擎对所述日志数据进行离线分析。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
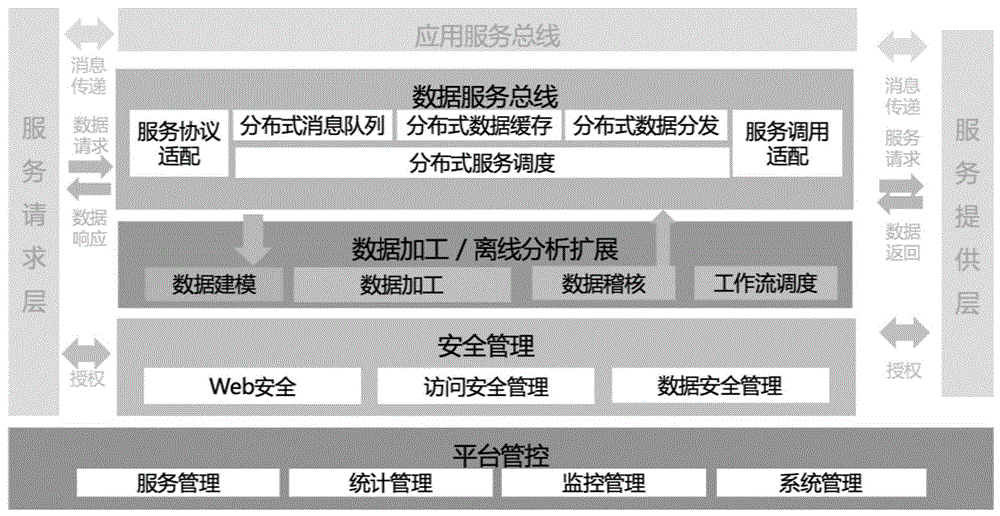
图1为本申请实施例提供的一种数据交换系统架构示意图;
图2为本申请实施例提供的一种数据交换方法数据流程图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
当前,各政府和企业一般都设计和建设了属于机构、业务本身的应用、流程以及数据的信息处理系统,独立、异构、涵盖各自业务内容的信息处理系统,设计建设的时期不同、业务模式不同,信息化建设缺乏有效的总体规划,重复建设;缺乏统一的设计标准,大多数系统都是由不同的厂商在不同的平台上,使用不同的语言进行开发的,信息交互共享困难,存在大量的信息孤岛和流程孤岛。
为了有效整合分散异构的信息资源,消除“信息孤岛”现象,提高政府和企业的信息化水平。要求新构建的数据共享交换系统要遵循标准的、面向服务架构的方式,基于先进的企业服务总线ESB技术,遵循先进技术标准和规范,为跨地域、跨部门、跨平台不同应用系统、不同数据库之间的互连互通提供包含提取、转换、传输和加密等操作的数据交换服务,实现扩展性良好的“松耦合”结构的应用和数据集成;同时要求数据共享交换系统,能够通过分布式部署和集中式管理架构,可以有效解决各节点之间数据的及时、高效地上传下达,在安全、方便、快捷、顺畅的进行信息交换的同时精准的保证数据的一致性和准确性。
本申请实施例提供了一种数据交换系统及方法,用以满足上述要求,解决上述不同应用系统之间存在大量信息孤岛、信息交互困难的技术问题。
下面通过附图对本申请实施例提出的技术方案进行详细的说明。
图1为本申请实施例提供的一种数据交换系统架构示意图。如图1所示,系统包括:应用服务总线模块、数据服务总线模块、数据加工/离线分析扩展模块、安全管理模块以及平台管控模块。
其中,应用服务总线模块以企业ESB服务总线为主体,包括消息过滤、格式转换、智能路由、协议适配、服务接入和消息订阅发布等基本功能,实现跨地域、跨部门、跨平台不同应用系统直接的服务集成和服务共享。
进一步地,数据服务总线模块包括服务协议适配子模块、分布式消息队列子模块、分布式数据缓存子模块、分布式数据分发子模块、分布式服务调度子模块和服务调用适配子模块等部分,主要实现大批量数据的高速传输,能接入多数据源,支持消息队列的持久化缓存,支持用户自定义拓扑的服务,支持向多消费者异步或实时分发服务,在服务分发过程中能兼容多种服务调用接口统一为客户提供服务响应。支持对数据的ETL处理,提供实时和离线处理方式,提供交互式查询服务,支持对大数据结构化、半结构化和非结构化文本的数据服务共享。
数据加工/离线分析扩展模块包括数据建模子模块、数据加工子模块、数据稽查子模块以及工作流调度子模块。在系统的实际应用过程中,会将海量的数据成功的接入到本地集群,之后,通过数据加工/离线分析扩展模块来对这些离线数据进行加工和清洗以得到需要的数据结果。且在本申请实施例的一个可能实现方式中,数据加工/离线分析扩展模块是以项目为单位对数据进行操作管理的。
如图1所示,在数据交换系统的实际应用过程中,应用服务总线模块在服务请求层与服务提供层之间进行消息传递,以实现不同应用系统间的服务接入。另外,数据请求层将数据请求发送给数据服务总线模块,然后数据服务总线模块将该服务请求转发至服务提供层;服务提供层对上述服务请求进行分析处理后,返回数据给数据服务总线。进一步地,数据服务总线模块将服务提供层返回的数据发送至数据加工/离线分析扩展模块进行数据清洗及加工处理,然后将加工处理完成后的数据响应给服务请求层。上述过程中的数据流向过程参见附图2及其相关说明,本申请实施例在此不做赘述。
进一步地,本申请实施例提供的数据交换系统还包括安全管理模块,主要用于保障数据交换系统的应用访问安全及数据传输安全,使安全贯穿数据交换管理的整个生命周期。具体地,安全管理模块主要包括web安全子模块,访问安全子模块以及数据安全子模块。其中,web安全子模块用于保障数据接入数据交换系统之前的wed安全;数据安全子模块用于保障数据接入数据交换系统之后数据安全;以及访问安全子模块用于保障数据交换系统访问不同应用系统及结构化数据的访问安全。
此外,本申请实施例提供的数据交换系统还包括平台管控模块。且该平台管控模块至少用于实现以下任一项或者多项功能:服务管理功能、统计管理功能、监控管理功能以及系统管理模块功能。或者说该平台管控模块包括服务管理子模块、统计管理子模块、监控管理子模块以及系统管理模块子模块。需要说明的是,平台管控模块包含的子模块与平台管控模块实现的功能是一一对应的,例如服务管理子模块实现服务管理功能。通过上述各个子模块实现各个管控功能,实现对系统服务供需方,从基础数据加工都数据服务提供的监控,体现平台级管控能力。
以上为本申请实施例提供的系统实施例,基于同样的发明构思,本申请实施例还提供了一种数据交换方法。图2为本申请实施例提供的一种数据交换方法数据流程图。该方法基于上述数据交换系统实现,应用上述数据交换系统。
本申请实施例中的数据流总共包含2个维度,数据服务总线模块的数据传输数据流及平台管控模块的监控数据流。
其中,数据服务总线数据传输数据流主要支撑数据服务总线的数据交换、数据共享。数据结果协议适配后统一写入到“分布式消息总线/缓存”模块中。由Storm服务根据下游使用方的订阅,运行Storm任务做数据分发,同样结果协议适配提供给服务使用方。且在本申请实施例中,数据服务总线采用了Kafka消息队列、MongoDB GridFS分布式文件存储系统、Storm流式计算框架三大主流大数据技术。其中,kafka实现数据请求队列、数据缓存块、大文件元数据缓存系统三大功能;MongoDB GridFS实现大文件分布式缓存系统;Storm实现并发数据读取和数据汇总功能。数据服务总线充分与大数据相关服务进行结合,利用大数据解决大文件及消息的高效传输。
如图2所示,本申请实施例提供的数据交换方法,主要由服务调用方、服务提供方以及数据交换系统三者参与。且数据交换系统中主要是数据服务总线模块的参与。在本申请实施例的一个可能实现方式中,数据交换方法主要包括以下过程:首先,数据交换系统接收服务调用方发送的调用请求,并将调用请求与服务调用日志进行对比,以判断调用请求对应的数据是否存在于服务调用日志中,或者判断服务调用日志中的调用请求与当前服务调用方法发送的调用请求是否一致;若是,则确定服务调用日志中存在该调用请求;然后将调用请求与缓存的服务响应结果进行请求匹配,并在请求匹配成功的情况下,将服务响应结果发送至服务调用方,即将该调用请求对应的服务响应结果发送至服务调用方。若否,则确定在服务调用日志中不存在调用请求;此时,将该调用请求发送给服务提供方,并接收服务提供方返回的服务响应结果;然后将服务响应结果进行缓存,并发送至服务调用方。
具体地,服务调用方向数据交换系统的数据传输统一接入端模块发送调用请求后,数据交换系统将该调用请求与服务调用日志进行对比分析。如果服务调用日志里没有相同调用即确定该调用请求为第一次调用,此时,数据传输统一接入端模块向服务调用适配器发送传输请求,服务调用适配器向服务提供方发送服务调用命令,然后接收服务提供方返回的服务响应结果,并将该服务响应结果发送给服务调用适配器。服务调用适配器将返回的服务响应结果以数据包的形式存入到分布式消息缓存中;具体地,服务调用适配器将服务请求元数据存储在kafka消息队列中,将服务数据文件则存储在MongoDB系统里。然后再将文件数据包通过Strom传输给服务协议适配器,最后服务协议适配器将服务响应结果响应给服务调用方,以此完成一次服务调用。
而如果服务调用日志里有相同调用请求,则直接从kafka分布式消息缓存队列里缓存的若干服务请求元数据中匹配相同请求,然后找到该请求对应的服务数据文件在MongoDB中的存储位置,直接通过Strom将该服务数据文件从MongoDB GridFS系统里将数据包分发和汇总给服务协议适配器,最后将结果响应给服务调用方,以此完成服务调用。
进一步地,平台管控模块的监控数据流包含从应用服务总线的各服务、数据服务总线的各类Agent采集的日志数据,且该日志数据是汇总到Kafka消息队列中的。此部分的数据流程根据业务场景会包含数据传输质量实时分析及数据传输质量离线分析两个过程。
在本申请实施例的一种可能实现方式中,日志收集系统Flume采集数据交换系统中各个模块产生的日志数据,并将日志数据存储至kafka消息队列中;数据传输质量实时分析主要是日志管理平台logstash将kafka消息队列中的日志数据接入到搜索服务器ElasticSearch中,并建立对应的索引数据;可视化平台kibana基于索引数据对日志数据进行可视化分析与展示。而数据传输质量离线分析主要是分布式文件系统HDFS以预设时间为间隔,接收来自kafka消息队列的日志数据,并将日志数据输入到预设分析引擎中;然后通过预设分析引擎对日志数据进行离线分析。
具体地,如图2所示,通过Flume日志采集,对数据交换系统中的各模块的日志进行采集,并将采集到的日志数据存储到Kafka分布式消息队列里,对这些日志数据进行两方面的应用。一方面进行数据传输质量的实时分析,通过Logstash接入到ElasticSearch建立索引,再由Kibana进行可视化分析与展现。需要说明的是,该分析过程还会对接告警系统,在数据实时分析出现异常时完成服务报警。另一方面进行数据传输质量离线分析,将日志数据定时从Kafka消息队列中通过Flume接入到HDFS中,后续可以使用大数据的分析引擎如使用MapReduce,HiveSQL,Spark SQL等工具,进行数据离线统计分析。
更进一步地,如图2所示,上述告警系统还对接有服务状态监控模块,该服务状态监控模块获取来自分布式协调系统Zookeeper一直在维护的服务状态,并在监控到服务状态异常时,实现系统告警。
本申请实施例提供的一种数据交换系统及方法,具有以下有益的技术效果:在企业ESB基础上引用大数据技术构建数据服务总线,解决大数据传输的问题;遵循先进技术标准和规范,为跨地域、跨部门、跨平台不同应用系统、不同数据库之间的互连互通提供包含提取、转换、传输和加密等操作的数据交换服务,实现扩展性良好的“松耦合”结构的应用和数据集成;同时数据共享交换系统提供通过分布式部署和集中式管理架构,有效解决各节点之间数据的及时、高效地上传下达,在安全、方便、快捷、顺畅的进行通信基础上加强上下级联动,实现垂直部门和跨部门的应用协调工作与数据共享,增强与上级总线平台的联动,打通上级联动通路,实现数据共享,提高数据利用率。
本申请中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。