1.本技术涉及快递视频检测技术领域,尤其涉及一种基于视频的深度学习抛物行为检测方法。
背景技术:
2.物流分拣中经常会出现暴力分拣的情况,物流分拣员经常违反规定,直接把需要的包裹扔向分类区域,这往往会导致包裹的损坏,大大影响了物流企业服务的质量。
3.现有技术中,通常有几种常用的检测方法,第一种是建立了互联网抛物监管平台,由监控室工作人员点播来自各个物流中心和网点的监控录像,持续查看识别出违规抛物作业的情况,然后进行标记,整理并上传到数字监管平台,该方法不能实时大范围的监管,需要人工长时间的检测,人力和时间耗费大;第二种是通过物联网进行监管,通过多种传感器组合,收集快件的实时振动加速度,温湿度,光照强度等数据并传输到附数据接收设备上进行分析处理,结果反馈到企业数字监管平台,但该种方案硬件成本高,并且误检率高;第三种是通过人工智能进行监管,即通过例如帧间差分法、背景差分法、混合高斯、改进的vibe、特征匹配等,或基于这些算法进行组合来达到实现抛物行为的检测结果的,市场上的人工智能摄像头,或者人工智能设备,以及企业级服务器端人工智能检测系统都属于人工智能监管的范畴,但该种方法无法检测抛物人员,无法对抛物人员进行定位,抛物性质界定困难,而且传统算法大多不支持批量并行处理,不同场景下的算法兼容性也很差,只适合特定场景,小范围的使用。
技术实现要素:
4.本技术提供一种基于视频的深度学习抛物行为检测方法,以解决现有技术中,在物流分拣过程中,抛物检测环节存在的需要人工检测、耗时耗力,误检率高,以及应用范围小的问题。
5.本技术的上述目的是通过以下技术方案实现的:
6.本技术实施例提供一种基于视频的深度学习抛物行为检测方法,包括:
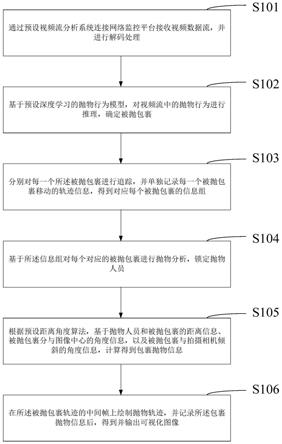
7.通过预设视频流分析系统连接网络监控平台接收视频数据流,并进行解码处理;
8.基于预设深度学习的抛物行为检测模型,对视频流中的抛物行为进行推理,确定被抛包裹;
9.分别对每一个所述被抛包裹进行追踪,并单独记录每一个被抛包裹移动的轨迹信息,得到对应每个被抛包裹的信息组;
10.基于所述信息组对每个对应的被抛包裹进行抛物分析,锁定抛物人员;
11.根据预设距离角度算法,基于抛物人员和被抛包裹的距离信息、被抛包裹分与图像中心的角度信息,以及拍摄相机倾斜的角度信息,计算得到包裹抛物信息;其中,所述包裹抛物信息包括被抛包裹的抛物距离信息和抛物等级信息;
12.在所述被抛包裹轨迹的中间帧上绘制抛物轨迹,并记录所述包裹抛物信息后,得
到并输出可视化图像。
13.进一步的,所述通过预设视频流分析系统连接网络监控平台接收视频数据流,并进行解码处理包括:
14.连接各中心和网点的网络摄像头,通过轮询逻辑算法获取多路rtsp监控视频流;
15.对所述rtsp监控视频流进行解码;
16.针对多路rtsp监控视频流,从多个输入源形成一批帧,完成批处理帧。
17.进一步的,所述深度学习抛物行为检测模型的训练过程包括:
18.人工在具有抛物行为的图像上进行分类标注,得到抛物图片和标注的文本信息,建立抛物行为数据集;
19.基于所述抛物行为数据集中的标注分类和数量,在darknet框架中配置yolov4算法的参数;
20.通过配置yolov4算法参数的darknet框架和yolov4算法,对所述抛物行为进一步的,所述人工在具有抛物行为的图像上进行分类标注的标注分类包括:
21.人类、人类头颅、被抛包裹和误检抛物物体。
22.进一步的,还包括基于所述被抛包裹的信息组中分析得到:被抛包裹的起始点、被抛包裹的终点、被抛包裹的运动轨迹、人类信息、人类头颅信息和被抛包裹的角度信息。
23.进一步的,所述基于所述信息组对每个对应的被抛包裹进行抛物分析,锁定抛物人员包括:
24.通过被抛包裹起始点到被抛包裹终点的多帧人物信息记录,汇总平均得到平均人物身体宽度;
25.判断是否存在在人物中心点不超过所述平均人物身体宽度的范围,与在被抛包裹起始点中心重合的人物;
26.若存在,则判断该人物为抛物人员;
27.若不存在,则判断抛物人员不在画面内。
28.进一步的,所述根据预设距离角度算法,基于抛物人员和被抛包裹的距离信息、被抛包裹与图像中心的角度信息,以及拍摄相机倾斜的角度信息,计算得到包裹抛物信息包括:
29.基于人物头部像素宽度,通过三角数学公式,判断人物和抛物包裹终点的距离,得到初步距离值;
30.基于所述初步距离值、被抛包裹与图像中心的角度信息和拍摄相机倾斜的角度信息,判断被抛包裹的实际角度变化,对初步距离值进行比例调节,得到真实距离值;
31.基于所述真实距离值,得到包括抛物等级信息和抛物距离信息的包裹抛物信息。
32.进一步的,还包括基于所述真实距离值和所述深度学习抛物行为检测模型进行误检排查,所述误检排查包括:
33.识别移动包裹轨迹角度变化情况,当移动包裹轨迹角度无变化时,则确定为在包裹在平移车辆内或移动传送带上,判断包裹不是被抛包裹;
34.识别被抛包裹的起始、中间件和结束的包裹中心点距离人物中心点的综合距离,当包裹始终处于人物的周边位置没有抛出,则确定为搬运行为,判断包裹不是被抛包裹;
35.通过人工标记误检抛物信息,生成误检标注数据集,经所述深度学习的抛物行为
检测模型训练后,通过深度学习的抛物行为检测模型判断包裹是否为被抛包裹。
36.本技术的实施例提供的技术方案可以包括以下有益效果:
37.本技术的实施例提供的技术方案中,首先通过预设视频流分析系统连接网络监控平台接收视频数据流,并进行解码处理;然后基于预设深度学习的抛物行为检测模型,对视频流中的抛物行为进行推理,确定被抛包裹;分别对每一个所述被抛包裹进行追踪,并单独记录每一个被抛包裹移动的轨迹信息,得到对应每个被抛包裹的信息组;基于所述信息组对每个对应的被抛包裹进行抛物分析,锁定抛物人员;根据预设距离角度算法,基于抛物人员和被抛包裹的距离信息、被抛包裹分与图像中心的角度信息,以及拍摄相机倾斜的角度信息,计算得到包裹抛物信息;其中,所述包裹抛物信息包括被抛包裹的抛物距离信息和抛物等级信息;最后,在所述被抛包裹轨迹的中间帧上绘制抛物轨迹,并记录所述包裹抛物信息后,得到并输出可视化图像。如此,本技术提供的基于视频的深度学习抛物行为检测方法,通过服务器端人工智能深度学习技术大大提高了抛物检测的准确率、实时性、效率和降低了成本,同时不需要改造现有的监控体系,也更能快速形成生产力,并且本技术中的深度学习神经网络算法模型,能够通过不断的添加学习各中心场景特征解决大范围场景不同的模型兼容,并且能够深度挖掘抛物行为的深层次信息,应用范围可以不断扩大。
38.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
附图说明
39.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本技术的实施例,并与说明书一起用于解释本技术的原理。
40.图1为本技术实施例提供的一种基于视频的深度学习抛物行为检测方法的流程示意图;
41.图2为本技术实施例提供的一种基于视频的深度学习抛物行为检测方法中深度学习的抛物行为检测模型构建的流程示意图;
42.图3为本技术实施例提供的基于视频的深度学习抛物行为检测方法中模型训练迭代图;
43.图4为本技术实施例提供的一种基于视频的深度学习抛物行为检测方法的视频流管道示意图。
具体实施方式
44.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。
45.现有技术方案中,主流的物流企业大多都是基于互联网的解决方案,虽然普及率最高,但检测能力低下,需要大量人工检索。部分物流企业采取了机器视觉技术解决方案,这些方案一般采用计算机视觉技术,使用机器替代人类的监测,常见的机器视觉算法原理是通过监控视频中上一帧和下一帧图片的变化,识别到物体的移动轨迹,这种方案灵敏度
效率很高,但分不清移动的物体是不是包裹,误检率高,需要二次人工筛选。在开发过程中传统计算机视觉算法需要对图片中抛物行为的特征进行提取,并把干扰进行的分类提取,比如抛物过程中,有可能是人类移动,有可能是传送上的包裹移动,有可能是车辆移动,动物移动等等干扰,并把所有的抛物检测的情况提取特征,比如黑夜里,白天,光线不足,有遮挡,小包裹,大包裹等等都需要提取特征处理,而随着类别数量的增加,特征提取变得越来越复杂繁琐,要确定哪些特征最能描述不同的目标类别,取决于cv工程师的判断和长期试错。此外,每个特征定义还需要处理大量参数,所有参数必须由cv工程师进行调整,人工成本很高。而且,通过这种算法模型检测的抛物行为虽然在当前场景下能够很精准的识别出来,但在全国不同的分拣中心和网点,场景不同模型的特征有很大差异,就会导致误检率很高,需要对误检的分类扩充现有模型的特征库,如此循环来提高准确度,对于cv工程师来说工作量巨大,需要的时间几乎不可估量,所以当前企业的解决方案是尽可能的降低误检率,并不得不配备人工进行二次筛选。
46.为了解决上述问题,本技术提供一种面向物联网多维传感器的数据融合方法和装置,以对对维传感器数据进行收集和融合,得到多维传感器数据的融合结果,从而更加全面、客观的反映客观事物,辅助相关工作人员做成更加正确的决策。具体实现方案通过以下实施例进行详细说明。
47.实施例
48.参照图1,图1为本技术实施例提供的一种基于视频的深度学习抛物行为检测方法的流程示意图,如图1所示,该方法至少包括以下步骤:
49.s101、通过预设视频流分析系统连接网络监控平台接收视频数据流,并进行解码处理。
50.具体的,本技术中的视频流分析系统具体可以采用deepstream视频流处理平台。deepstream是英伟达公司根据开源框架gstreamer实现的,deepstream是一个为多应用的视频分析提供的基础框架,在这个框架里,视频分析首先得输入视频,在创建智能分析系统之前,需要从视频像素中抽取需要的信息,以及解码后进行处理。这步完成后,下一步就可以做推理了。推理能完成目标识别、跟踪、分类、特征提取、从像素中创造或者提取内含的信息等功能。当得到推理出来的信息后,可以根据实际应用做很多事情,例如可能会在本机的显示器上,在原始的图像/像素上层,将这些信息聚合,并叠加组合,实时反馈显示出来。此外还可以,将原始图片附加上刚才识别出来的那些信息,重新进行视频编码,然后在磁盘上进行存储和以后的再次分析。还可以在推理得到了这些信息后,将信息传给数据分析后端,无论是包括实时处理、批处理、还是串流显示,然后能发送给依赖于这些信息的其他用户。deepstream框架的结构为一个数据流管道,提供了很多功能插件,也可以自定义一些功能插件,加入到管道中,串成一个链路,从视频输入开始,一个一个插件进行处理视频,直到结束。
51.在本技术中,由视频流平台提供rtsp视频地址,各中心和网点网络摄像头联网接入企业视频流监管平台,实现多路rtsp监控视频流输入。需要说明的是,这里用到pipeline的输入库sourcebin接入多路视频流,以批量的视频输入处理满载芯片的算力,提高处理能力。并且,在接入视频流的地方,可以使用轮询逻辑算法,一台机器每五分钟切换32路视频进行识别,这样用极少的机器可以轮询来自多个中心的监控。
52.在视频流输入后,需要对视频流进行解码处理。具体的,硬件解码视频流,利用加速器进行硬件加速,释放了硬件的最高性能,在实际应用中,可以采用gst
‑
nvvideo4linux2插件实现,通过英伟达gpu原生支持的硬件解码加速了解码速度和能力。
53.另外,对视频流进行处理时,其处理过程具体可以是通过预设的插件进行批处理帧,如通过gst
‑
nvstreammux插件,从多个输入源形成一批帧,多路输入的多路复用,达到一次推理多路的能力,性能大幅提升。
54.s102、基于预设深度学习的抛物行为检测模型,对视频流中的抛物行为进行推理,确定被抛包裹。
55.具体的,本技术提供的基于视频的深度学习抛物行为检测方法中的深度学习的抛物行为检测模型为:首先通过用户在具有抛物行为的图像中标注与抛物行为有关的或者干扰的分类,汇聚大量的抛物图片和文本信息,得到抛物行为数据集;然后基于上述分类,在darknet框架中配置yolov4算法的参数,通过darknet框架自我训练迭代调优,从而自动提取出对于目标类别最具描述性和最显著的特征汇聚成深度学习模型。然后将得到的深度学习的抛物行为检测模型挂载到视频流检测系统上进行推理。
56.需要说明的是,本技术基于gst
‑
nvinfer改造成ztodsinfer插件(使用抛物检测模型构建)进行推理,可以对32路合并输入的数据进行推理,融入了深度学习而来的抛物行为检测模型,准确率很高,ztodsinfer插件里挂载了由深度学习框架和算法实际训练而来的抛物行为检测模型,在这里作为视频流推理用的推理器,这样推理得来需要的视频信息,包括确定被抛包裹。
57.s103、分别对每一个所述被抛包裹进行追踪,并单独记录每一个被抛包裹移动的轨迹信息,得到对应每个被抛包裹的信息组。
58.具体的,可以采用基于gst
‑
nvtracker插件的预设程序或算法,对推理完得到的信息数据,进行目标跟踪插件。对每一次抛物的包裹进行追踪,能够单独记录每一个包裹移动的轨迹信息,形成某个包裹的抛物信息组,方便后续根据每个包裹的编号进行深度信息挖掘。
59.s104、基于所述信息组对每个对应的被抛包裹进行抛物分析,锁定抛物人员。
60.具体的,基于追踪到的抛物目标信息即被抛包裹的信息组中的信息,分析得到被抛包裹的起始点、被抛包裹的终点、被抛包裹的运动轨迹、人类信息、人类头颅信息和被抛包裹的角度信息等。基于被抛包裹的起始点、人物信息和包裹轨迹信息,判断人物的中心点附近不超过自身身体宽度的情况下,是否和包裹的起始点中心重合,如果有,锁定该人物为抛物人员。需要说明的是,这里通过包裹起始点到抛物的终点多帧的人物信息记录汇总取平均方法避免可能漏检抛物人员的问题,实现99.9%的准确率,在没有符合抛物的人员的情况下,判定抛物人员锁定失败,不在画面之内。
61.s105、根据预设距离角度算法,基于抛物人员和被抛包裹的距离信息、被抛包裹分与图像中心的角度信息,以及拍摄相机倾斜的角度信息,计算得到包裹抛物信息。
62.其中,所述包裹抛物信息包括被抛包裹的抛物距离信息和抛物等级信息。
63.具体的,基于锁定的抛物人员信息,根据人物头部的像素宽度,利用类三角数学方式,判断人物和包裹终点的距离得到初步距离值。然后,基于初步距离值和图片中心点相对于移动包裹的角度、包裹相对于相机的倾斜角度判断包裹的实际角度变化等信息,对初步
距离值进行比例调节,得到相对真实距离值。最后,基于真实距离值以及抛包裹的运动轨迹等信息,得到包括抛物距离信息、抛物等级信息等的包裹抛物信息。
64.需要说明是,本技术提供的基于视频的深度学习抛物行为检测方法中,拍摄设备可以是单目相机,本技术中为通过图像中人物的数据以及各种角度,和距离角度分析算法确定的确定实际距离和角度变化。通过对视频流数据的分析处理,可以得到人物头颅宽度、相机倾斜角度、和地面情况。人物头部的宽度一般在25厘米左右,一般比较固定,这里根据人物的头颅信息对比占比整张图片的像素比例,可以得到图片画面的远近,根据一般相机向下的特征,一般为20
‑
40度,在二维的图片中,左右平行抛物的角度损失不会很大,一旦相对于图片的高度有向上或者向下的角度变化,将会因为二维的特征而失真,经过试验当角度在60度的时候失真最为严重,这里采用安角度大小变化相对距离角度的失真比例,从而还原实际距离变化的角度变化,从而保证后续对抛物进行判定等级时的准确性。
65.s106、在所述被抛包裹轨迹的中间帧上绘制抛物轨迹,并记录所述包裹抛物信息后,得到并输出可视化图像。
66.具体的,本技术实施例中,得到包裹抛物信息后,在移动包裹轨迹的中间帧上绘制轨迹可视化构件,如抛物距离信息,抛物等级信息等。另外deepstream提供多种输出方式,本技术实施例gst
‑
nvmsgbroker插件提供连接云端,通过gst
‑
nvmsgconv插件提供输出负载,即把可视化处理的图像信息通过输出rtsp视频流、以及发送数据到云端两种方式进行上传。
67.本技术实施例提供的基于视频的深度学习抛物行为检测方法,首先是针对深度学习选择框架,制作抛物行为检测需要的数据集制作,其次在框架中,对深度学习的算法选择以及调参,模型的迭代和训练,得到深度学习的抛物行为检测模型,再将深度学习的抛物行为检测模型挂载至视频流检测系统,通过视频流检测系统和距离角度分析算法,对抛物人员进行锁定,并且计算距离和角度,判断抛物等级后上传至企业数据管理平台。整个过程节省人力和时间成本,误判率低,并且只要有一定的原始数据,自动的分析学习提取迭代出需要的模型,从而轻松实现全国大范围的拓展。同时,基于深度学习识别到抛物行为数据,可以进行二次开发得到更深度的信息,比如抛物人员的锁定,抛物等级的划分,抛物距离的测算,抛物角度的分析等深度信息,方便企业相关人员对抛物信息的跟深层次的掌握。
68.进一步的,本技术提供的基于视频的深度学习抛物行为检测方法,还包括基于所述真实距离值和所述深度学习抛物行为检测模型进行误检排查,所述误检排查包括:识别移动包裹轨迹角度变化情况,当移动包裹轨迹角度无变化时,则确定为在包裹在平移车辆内或移动传送带上,判断包裹不是被抛包裹;识别被抛包裹的起始、中间件和结束的包裹中心点距离人物中心点的综合距离,当包裹始终处于人物的周边位置没有抛出,则确定为搬运行为,判断包裹不是被抛包裹;通过人工标记误检抛物信息,生成误检标注数据集,经所述深度学习的抛物行为检测模型训练后,通过深度学习的抛物行为检测模型判断包裹是否为被抛包裹。
69.在一些具体的实施过程中,排除各类误检干扰功能可通过如下方式进行实现,如移动物体轨迹角度无变化时确定为平移,可排除平移的车辆,部分传送带上移动包裹,无法排除的对误检的数据进行落图并通过人工或脚本自动生成标注数据集,然后进行模型再分类训练,从而识别到抛物和误检移动的特征区别,避免误检。比如排除人员挥舞或者搬运导
致的抛物检测触发,这里通过逻辑分析进行排除,判断抛物的开始和中间件以及结束的包裹中心点距离人物的中心点的综合距离,当处于人物的周边位置没有抛出,则识别为搬运行为。而部分无法判断的,则加入到误检系列分类训练出特征进行排除。
70.另外,还可以通过在制作数据集时,人工标注一些物件抛物物体,对物件抛物物体加入到学习模型中,以及在后期不断添加数据,从而在运行学习模型时,可以自动进行误检排查。
71.图2为本技术实施例提供的一种基于视频的深度学习抛物行为检测方法中深度学习的抛物行为检测模型构建的流程示意图。
72.深度学习,首先需要大量精细标注的数据作为“燃料”,通过标注带有抛物行为的图片,把人物,抛起的货物,移动的车辆,传送带上移动的货物等信息用标注工具(一种打开图片能够识别在图上手动圈出的物体的坐标的工具)分类标注出来,大量的标注信息被保存成文件,这些图片和标注文件就形成了深度学习的基础数据集,深度学习框架就是要根据这些基础数据来学习各个分类的特征。其次,深度学习需要相应功能的算法框架作为“动力系统”,而算法就是这个框架的“发动机”,深度学习算法框架吸收了传统算法处理的优点,并且加入了数据增强、参数调节、神经网络损失函数和激活函数等能力,大大提高了模型训练的能力。在确定好数据集以及框架算法后,进行深度学习的模型训练,即把数据“燃料”放到深度学习框架“动力系统”中,由算法“发动机”处理,得出当前“燃料“处理后的“机械动力、电力、尾气”等特征组合,这个处理过程就是模型训练。模型训练需要持续的添加大量数据,对每一次的数据都由算法经过分析得出分类特征,在大量的训练过后,我们会得到一个非常接近真实的特征集合。
73.如图2所示,本技术实施例提供的基于视频的深度学习抛物行为检测方法中深度学习的抛物行为检测模型构建包括:
74.s201、人工在具有抛物行为的图像上进行分类标注,得到抛物图片和标注的文本信息,建立抛物行为数据集。
75.具体的,本技术实施例通过用户在具有抛物行为的图像中标注跟抛物行为有关的或者干扰的分类,汇聚大量的抛物图片和标注的文本信息。在实际应用中,可以根据微软coco数据集的格式制作的抛物行为数据集。其中标注可以采用多种主流标注工具,可以采用的是labelme工具,生成的是darknet框架支持的microsoft coco数据集。标注分类是分为人类,人类头部,抛物的包裹,误检的移动物体四类,大量标注这四类信息,制作数据集。
76.需要说明的是,因为在后续流程需要根据人物头部信息定位人物和包裹之间的距离,确定抛物行为抛起的是包裹,而因为各种原因导致的干扰,会导致误判误检,所以分成另一类标注出来,进行误检排出,这样就能排除它的干扰,这样制作出来的数据集对抛物行为的信息基本提取完毕,为后续深度学习提供了基础数据。其中,标注信息包括:0:人类信息(红)、1人类头颅信息(黄)、2抛起包裹信息(绿)和3误检抛物物体信息(蓝)。
77.s202、基于所述抛物行为数据集中的标注分类和数量,在darknet框架中配置yolov4算法的参数。
78.s203、通过配置yolov4算法参数的darknet框架和yolov4算法,对所述抛物行为数据集进行训练,得到深度学习的抛物行为检测模型。
79.yolo(you only look once)是joseph redmon针对darknet框架提出的核心目标
检测算法,完全基于darknet框架,给yolo系列算法最佳的支持。yolov4算法是相比之前的yolo系列有更快的推理速度(fps>80),采用了mosaic数据增强(采用4张图片,随机缩放、裁剪、排布的方式进行拼接),丰富了数据集,减少了训练所需的gpu,在backbone主干网络中使用了mish激活函数得到更好的准确性和泛化,在neck中使用fpn自顶向下传达强语义特征,特征金字塔自底向上传达强顶为特征,双向传导进一步提升特征提取的能力,因此产生了较好的效果。在实际部署实用中,yolov4只需要较少样本就能模型就能快速的收敛。部署能够达到很好的推理效果。
80.darknet是一个较为轻型的完全基于c与cuda的开源深度学习框架,其主要特点就是容易安装,没有任何依赖项(opencv都可以不用),移植性非常好,支持cpu与gpu两种计算方式。相比于来自谷歌的tensorflow和开源的pytorch来说,darknet并没有那么强大,但这也成了darknet的优势,darknet体量很小,支持c/cuda/cudnn,使用cpu、gpu更快更高效,非常灵活,底层代码简单明了可以很好的拓展和改造。
81.在本技术实施例提供的基于视频的深度学习抛物行为检测方法中,计算机视觉技术中的目标检测算法是非常适合对抛物行为的检测,所以可以选用深度学习darknet yolov4作为推理抛行为的深度学习框架和目标检测算法。darknet是一个轻量的高效的拓展性极强的框架,虽然功能没有主流的大型集成化框架功能齐全,但是优点是darknet可以对目标检测算法yolov4的原生支持,速度和效率最高,且特别轻量运行速度最快。在实际应用中,首先需要在darknet中配置目标检测算法yolov4的参数,根据上述数据集中分类的数目进行四类分类,我们需要调整算法的参数,net层:配置每次迭代的输入数量,宽高,迭代次数,学习率等信息;shortcut层:配置卷积的跨层连接;route层:当前层引出之前卷积所得到的特征层;yolo层前的conv层:bn操作选择以及filters数量等;yolo层的配置:关于anchors索引值、类别、多尺度训练、拟合等信息的配置,配置这些主要是为了提高学习和迭代的高效准确。根据数据集标注分类和数量完成框架和算法的配置后,就可以开始数据在框架和算法中的训练了,从而得出需要的特征模型。然后将模型挂载在deepstream视频流处理的平台上,就可以根据视频的输入,实时分析当前视频中出现的抛物行为。
82.图3为本技术实施例提供的基于视频的深度学习抛物行为检测方法中模型训练迭代图,图3中,map为学出的模型在所有类别上的好坏,其越接近100%说明越准确;loss为持续损失变化曲线,其越接近0越好;current avg loss为当前平均的损失值;iteration:迭代次数。从图3中可以看出,本技术实施例提供的深度学习模型,效果很好。
83.图4为本技术实施例提供的一种基于视频的深度学习抛物行为检测方法的视频流管道示意图,如图4所示:
84.本技术实施例对数据训练而来的模型进行应用选用的是目前市场上最先进的方案,来自英伟达gpu服务器下的视频流开放平台deepstream5.0。deepstream视频流分析系统是由一组不同功能的模块化插件组合成管道的自定义系统,这些插件相连接以形成多个功能组合的处理管道。每个插件代表一个功能块。本发明将深度学习目标检测和其他复杂的处理任务引入到流处理管道中,以实现对视频流中抛物行为的感知和处理。本发明基于7种功能插件模块,建造一个高效的抛物检测视频分析管道(pipeline),包括用是实现多rtst视频流输入的source_bin插件、用于解码的gst_nvvideo4linux2插件、用于批处理的gst
‑
nvstreammux插件,用于推理的ztodsinfer插件、用于目标追踪的gst
‑
nvtracker插件、
用于抛物分析的ztodstoanalysis插件,以及用于分值器gsttee上的gst
‑
nvmsgbroker插件、demuxer插件、gst_nvmsgconv插件和msg_broker插件。
85.本技术实施例构建的多路视频的编解码,视频分析模型挂载,抛物信息挖掘分析,以及视频数据传输的抛物行为检测视频流处理管道,在满足多路视频输入解码批处理功能的同时,并利用加速器进行硬件加速,释放了硬件的最高性能。视频输入到deepstream管道中后经过管道中挂载的已训练的抛物检测模型进行推理分析,追踪每个包裹和人物等信息,管道中同时挂载了对于抛物行为检测后结果的再次分析的gst
‑
ztodsanalysis插件,作为信息输出的gst
‑
nvmsgconv插件,作为kafka通信的gst
‑
nvmsgbroker插件等。
86.对比市场上智能设备方案,本技术的优势是通过gpu服务器深度学习技术,直接省去了硬件改造的成本和时间的投入,对比少数其他物流企业的计算机视觉技术,我们的深度学习框架更先进,算法只用了yolov4和自研的抛物距离角度鉴定算法,保持了最快的速度和准确性,且我们的识别不仅仅是抛物行为的检测上,同时在抛物的距离,等级划分上有更精准的处理逻辑,在对抛物行为的人员定位上,我们的反向推理逻辑,根据抛物的方向,逆向查找可能抛物的人员,再根据距离角度分析算法,分析出包裹最可能来自的是哪个人员,这样过滤了很多画面中没人,或者不是画面中的人员抛物的不良检测,并把距离和抛物等级直接在视频的每一帧中标记,大大省略了再次人工排除的工作。
87.另外,在本技术提供的基于视频的深度学习抛物行为检测方法中,神经网络深度学习算法框架还可以采用tensorflow或者pytorch等,他们提供了更多的api接口,可以完成更复杂的功能,但是损失了性能,且体量很大,对yolo系列算法的兼容不如darknet原生框架高效。距离角度分析算法可以基于摄像头和人物的宽高相对图像像素占比计算得到,但准确率因为人物的动作拉大了宽高的数值,产生较大波动,不如头颅的宽高树值稳定。而且,基于本发明的系统可以拓展其他硬件平台,比如使用国内的寒武纪云计算gpu服务器,或者华为的云计算gpu服务器,虽然硬件性能接近,但因为软件的兼问题会导致效率有折扣。
88.可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
89.需要说明的是,在本技术的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本技术的描述中,除非另有说明,“多个”的含义是指至少两个。
90.流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本技术的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本技术的实施例所属技术领域的技术人员所理解。
91.应当理解,本技术的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场
可编程门阵列(fpga)等。
92.本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
93.此外,在本技术各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
94.上述提到的存储介质可以是只读存储器,磁盘或光盘等。
95.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本技术的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
96.尽管上面已经示出和描述了本技术的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本技术的限制,本领域的普通技术人员在本技术的范围内可以对上述实施例进行变化、修改、替换和变型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

