1.本发明涉及视觉导航领域,特别是视觉室内定位领域,尤其是指一种基于计算机视觉的室内定位方法。
背景技术:
2.室内环境下的高精度定位问题一直以来都是一个技术难题。受限于多径和室内复杂多变环境的影响,传统的室内定位方法都存在这样或那样的问题而无法实现高精度定位,例如:
3.直接采用伪卫星进行数据解算定位,受多径影响,定位精度无法保证;
4.wi
‑
fi、蓝牙的基于信号强度值的定位方法受室内环境变化影响较大,定位精度无法保证;
5.利用信号指纹的定位方法存在指纹库建立时间长且随时间变化的问题。
6.基于计算机视觉的定位方法具有定位时间短、定位结果准确的优点,在室内建筑中有较好的应用前景。但是,现有技术中尚缺少相关尝试。
技术实现要素:
7.有鉴于此,本发明提出一种基于计算机视觉的室内定位方法,其基于深度学习的图像匹配及n点透视投影问题求解来实现定位,能够很好地解决现有技术中室内复杂环境下定位性能变差的问题,提升室内导航定位的精度。
8.为了实现上述目的,本发明采用的技术方案为:
9.一种基于计算机视觉的室内定位方法,包括以下步骤:
10.(1)采集室内rgb图像和深度图像并保存,记录采集图片时相机的位姿,建立室内地图库t
mn
;
11.(2)将地图库中保存的rgb图像作为训练样本输入到深度学习网络模型中,对网络模型进行训练,当损失函数数值不再降低时保存网络模型参数;
12.(3)当有终端进入室内时,下载深度学习网络模型参数,并使用终端相机拍摄室内照片,利用深度学习网络从地图库中识别出与终端拍摄照片最相似的匹配图片,并提取对应的深度图像和相机位姿;
13.(4)提取终端拍摄照片和匹配图片的特征点,对特征点进行匹配并计算得到匹配点在世界坐标系下的坐标;
14.(5)根据匹配点在世界坐标系下的坐标以及图像坐标,利用n点透视投影模型求解方法,求解出终端在拍摄照片时在世界坐标系下的位姿,再根据室内地图将坐标转换为真实位置并在地图上显示;
15.完成基于计算机视觉的室内定位。
16.进一步的,步骤(1)的具体方式为:根据面积大小将室内空间分成m
×
n个网格,采用激光测距仪获取每个网格中心点的平面坐标,在每个网格中心架设rgb
‑
d相机,使相机距
地面的高度为h米,并与地面保持平行;通过这些相机采集rgb图像和深度图像,并记录采集图片时相机的位姿,从而建立m
×
n大小的室内地图库。
17.进一步的,所述深度学习网络模型结合lbp特征进行场景识别;步骤(2)中对网络模型进行训练时,利用下式进行lbp特征提取:
[0018][0019][0020]
式中,(x
c
,y
c
)为中心像素点的坐标,n的大小为8,i
c
,i
n
分别为中心像素和邻域像素的灰度值,s(
·
)为符号函数;
[0021]
训练过程的目的是学习得到网络各层的参数值,以拟合给定的训练数据;具体方式为,建立对数似然函数,使其在训练集上的值最大化,即得到网络层参数;假设训练集包含n个样本,则对数似然函数为:
[0022][0023]
式中,p(v
(i)
|θ)表示可见单元与隐单元的联合分布,argmax为求函数最大值所对应的自变量集合的函数,θ为网络参数。
[0024]
进一步的,步骤(4)的具体方式为:
[0025]
分别提取终端拍摄照片和匹配图片的surf特征点并进行匹配;
[0026]
利用随机采样一致性方法对错误匹配点进行剔除;
[0027]
提取匹配点像素坐标,查找深度图像中对应点的深度,根据相机成像模型和相机位姿,计算得到匹配点在世界坐标系下的坐标。
[0028]
本发明与现有技术相比具有如下有益效果:
[0029]
1、本发明通过采集室内不同位置和方向的rgb和深度图像,建立地图库,通过基于深度学习网络方法实现相似图片查找,通过构建n点透视投影模型方程求解相机位姿来实现室内的高精度导航定位。
[0030]
2、本发明采用基于深度学习的图像匹配及n点透视投影问题求解来实现室内定位,相对于现有的室内定位方法,定位精度大幅提高。
[0031]
3、本发明能够很好地解决现有技术中室内复杂环境下定位性能变差的问题,提升室内导航定位精度,为室内高精度定位问题的解决提供了新的思路。
附图说明
[0032]
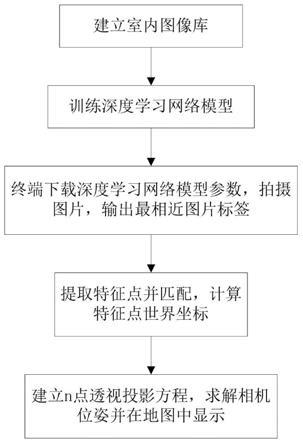
图1为本发明实施例的方法流程图。
具体实施方式
[0033]
下面结合附图对本发明做更进一步的说明。
[0034]
一种基于计算机视觉的室内定位方法,包括以下步骤:
[0035]
(1)将室内空间分成m
×
n的平面网格,采用激光测距仪获取每个网格中心点平面
坐标,在每个网格中心利用rgb
‑
d相机,使相机距地面高度h米,并与地面保持平行,采集rgb图像和深度图像保存,并记录采集图片时相机的位姿,然后建立m
×
n大小的室内地图库t
mn
;
[0036]
(2)将地图库中保存的rgb图像作为训练样本输入到已经构建好的深度学习网络模型中,对网络进行训练,当损失函数数值不在降低时保存网络模型参数;
[0037]
(3)任意终端进入室内后,下载深度学习网络模型参数,并使用终端相机拍摄室内照片,根据深度学习网络识别出最相似的照片并提取对应的深度图和相机位姿;
[0038]
(4)分别提取终端拍摄照片和网络模型输出的照片的surf特征点,进行匹配并对错误匹配点进行剔除,提取匹配点像素坐标,查找深度图中对应点的深度,根据相机成像模型和相机位姿,计算得到匹配点在世界坐标系下的坐标。
[0039]
(5)得到匹配点在世界坐标系下的坐标和图像坐标后,利用n点透视投影问题求解方法,即可求解出终端在拍摄照片时在世界坐标系下的位姿,再根据室内地图将最大值对应的坐标转换为真实位置在地图上显示;
[0040]
完成基于计算机视觉的室内定位。
[0041]
其中,步骤(2)中网络模型训练具体包含:lbp特征提取、dbn训练等步骤。lbp算子用公式表示为:
[0042][0043]
其中,(x
c
,y
c
)为中心像素点的坐标;n大小为8;i
c
,i
n
分别为中心像素和邻域像素的灰度值;s(
·
)为符号函数。
[0044]
训练过程的目的是学习得到rbm网络各层的参数值,以拟合给定的训练数据。具体来说,建立对数似然函数,使其在训练集上的值最大化,即得到网络层参数。假设训练集包含n个样本,对数似然函数为:
[0045][0046]
其中,p(v
(i)
|θ)表示可见单元与隐单元的联合分布,θ为网络参数,argmax为计算机和数学领域的公知函数,此处不再赘述。
[0047]
其中,步骤(5)中利用n点透视投影问题,求解出终端在拍摄照片时在世界坐标系下的位姿,具体流程如下:
[0048]
假设给定一个已经过标定的摄像头(即相机的焦距、光心位置和畸变参数已知)、世界坐标系下的空间参考点p
i
,i=1,...,n和对应参考点在相机坐标系下的点v
i
,i=1,...,n,通过3d/2d参考点之间的对应关系得到两个坐标系之间的转换方程为:
[0049]
λ
i
v
i
=rp
i
t (3)
[0050]
其中,λ
i
为v
i
点的深度,v
i
满足||v
i
||=1,r为旋转矩阵,t为平移向量。
[0051]
空间参考点p
i
在图像坐标系下的投影点为p
i
'=[x'y']
t
,对于投影点的观测存在一定的不确定性,其不确定性用二维协方差矩阵来描述。计算公式如(4)所示:
[0052][0053]
通过坐标系变换矩阵a将图像坐标系下的点转换到相机坐标系下:
[0054][0055]
其中,j
a
为坐标系变换a的雅克比矩阵,因此相机坐标系下的点p的不确定性表示为:
[0056][0057]
其中,协方差矩阵的秩为2,为奇异矩阵且不可逆。将点的坐标归一化得向量:
[0058][0059]
其中,协方差矩阵由下述公式得出:
[0060][0061]
同样,协方差矩阵是奇异矩阵,各分量之间相关,不满足最大似然求解法各元素独立的要求,因此引入零空间来表示向量v:
[0062][0063]
其中,函数f(
·
)为奇异值分解函数,为向量v变换到向量v
r
的雅克比矩阵,
[0064][0065]
确定性由向量v到向量v
r
的转换表示为:
[0066][0067]
通过下式可以得到相机的位姿。
[0068][0069]
将上式展开,其中p
i
=[p
x p
y p
z
]
t
,可得:
[0070][0071]
将上式用齐次线性方程组表示为:
[0072]
bu=0 (14)
[0073]
其中,b为齐次方程组的系数,
[0074][0075]
通过上式求解相机旋转矩阵和平移向量至少需要6对2d/3d对应点。
[0076]
将参考点的不确定性描述矩阵加入齐次线性方程得:
[0077][0078]
最终的表达式为:
[0079]
b
t
cbu=nu=0 (16)
[0080]
其中,u满足约束条件||u||=1。对系数矩阵进行奇异值分解:
[0081]
n=udv
t (17)
[0082]
其中,旋转矩阵和平移向量由上式求解的特征向量获得:
[0083][0084]
其中,平移向量仅代表方向,尺度因子通过下式计算,平移向量为:
[0085][0086]
通过奇异值分解得旋转矩阵为:
[0087][0088]
r=u
r
v
rt (21)
[0089]
通过上述计算过程得到相机的旋转矩阵和平移向量。
[0090]
以下为一个更具体的例子:
[0091]
如图1所示,一种基于计算机视觉的室内定位方法,包括以下步骤:
[0092]
步骤1:建立室内地图库,将室内空间分成m
×
n的网格,采用激光测距仪获取每个
网格中心点平面坐标,在每个网格中心利用rgb
‑
d相机,使相机距地面高度h米,并与地面保持平行,采集rgb图像和深度图像保存,并记录采集图片时相机的位姿,然后建立m
×
n大小的室内地图库t
mn
;
[0093]
步骤2:将地图库中保存的rgb图像作为训练样本输入到已经构建好的深度学习网络模型中,对网络进行训练,当损失函数数值不在降低时保存网络模型参数;
[0094]
网络训练过程描述为:获取地图库中的每幅图像的文件名及对应的标签,定义训练的模型(包括初始化参数,卷积、池化层等参数、网络),然后开始训练,当损失函数数值不再显著降低时此时网络模型参数分类准确率达到最优,将网络参数进行保存。
[0095]
步骤3:任意终端进入室内后,可通过wifi下载深度学习网络模型参数,并使用终端相机拍摄室内照片,根据深度学习网络识别出最相似的照片并提取对应的深度图和相机位姿;
[0096]
(4)分别提取终端拍摄照片和网络模型输出的照片的surf特征点,进行匹配并对错误匹配点进行剔除,提取匹配点像素坐标,查找深度图中对应点的深度,根据相机成像模型和相机位姿,计算得到匹配点在世界坐标系下的坐标。
[0097]
(5)得到匹配点在世界坐标系下的坐标和图像坐标后,利用n点透视投影问题求解方法,即可求解出终端在拍摄照片时在世界坐标系下的位姿,根据参考真值点对应的经纬度坐标转化为真实的经纬度坐标,并在室内地图上进行显示。
[0098]
完成基于计算机视觉的室内定位。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。