1.本发明属于计算机领域,具体涉及一种基于神经网络的合同信息提取方法、系统和存储介质。
背景技术:
2.随着办公自动化领域的不断发展,以电子化办公逐渐替代纸质化办公,有效降低了在办公场所中纸质文件的使用。并且由于人工智能的发展,算法与计算速度的提高,更基于合同信息电子化,客户逐渐倾向于使用人工智能的方式提取合同信息中的内容,以降低人工对合同信心处理的工作量,提高办公效率。
3.目前传统的合同内容提取方式为:人工提取或规则提取,这两种方式有明显的两个弊端:1、人工维护成本高、效率低;2、规则匹配泛化能力差、存在局限性、维护频繁,因为在识别不同模板的合同时,需要修改为待识别合同模板的规则,有的合同可能几十上百页,识别效率低。在合同信息提取中存在很多不理想的情况,难以满足客户的预期要求。
4.因此,亟需一种新型且实用的合同信息提取方法以克服现有技术中的缺陷,真正的降低人工合同信息提取的工作量。
技术实现要素:
5.为了弥补目前行业发展现状的不足,本发明提供了一种基于神经网络加规则匹配的合同信息提取方法,单次训练后,可直接用于非通用模板合同内容的提取,自动将获取的内容分类到各方信息栏内,且云端部署,安全性高。
6.为实现上述目的,本发明的一方面提出了一种基于神经网络的合同信息提取方法,包括:
7.从合同文本中提取出原始文本数据,并对原始文本数据预处理得到预处理文本数据;
8.通过ner实体识别模型对所述预处理文本数据进行命名实体识别得到所述预处理文本数据中的命名实体;
9.通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性;
10.根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全。
11.在本发明的一些实施方式中,从合同文本中提取出原始文本数据,并对原始文本数据预处理得到预处理文本数据包括:
12.将所述原始文本数据中的空格及标点符号删除。
13.在本发明的一些实施方式中,ner实体识别模型基于lstm神经网络并由kears和tensorflow框架训练而成。
14.在本发明的一些实施方式中,通过词性识别模型对所述预处理文本数据进行识别
获取预处理文本数据中所有分词的词性包括:
15.使用jieba分词工具在对预处理文本数据进行分词的同时对所分的分词进行词性标注。
16.在本发明的一些实施方式中,通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性还包括:
17.根据所述预处理文本数据中的命名实体在所述预处理文本数据中截取所述命名实体前后预定个数的分词组成的连续文本段落;
18.通过人工审核所述连续文本段落中的分词的词性标注结果,将词性标注有误的分词建立人工词性表;
19.响应于使用所述jieba分词工具对所述预处理文本进行分词,将所述人工词性表添加到所述jieba分词的词性表。
20.在本发明的一些实施方式中,通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性还包括:
21.根据所述预处理文本数据中的命名实体在所述原始文本数据中截取所述命名实体前后预定个数的分词组成的连续文本段落。
22.在本发明的一些实施方式中,根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全包括:
23.判断所述命名实体在所述原始文本数据中的位置的前后的分词的词性是否与所述命名实体的词性相同;
24.响应于所述命名实体在所述原始文本数据中的位置的前后的分词的词性与所述命名实体的词性相同,将所述命名实体在所述原始文本数据中的位置的前后的分词和所述命名实体合并为一个命名实体。
25.在本发明的一些实施方式中,根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全还包括:
26.响应于所述命名实体和所述命名实体在所述原始文本数据中的位置的前后的分词之间存在标点符号,则禁止所述将所述命名实体在所述原始文本数据中的位置的前后的分词和所述命名实体合并为一个命名实体。
27.本发明的另一方面还提出了一种基于神经网络的合同信息提取系统,包括:
28.文本处理模块,所述文本处理模块配置用于从合同文本中提取出原始文本数据,并对原始文本数据预处理得到预处理文本数据;
29.文本识别模块,所述文本识别模块配置用于通过ner实体识别模型对所述预处理文本数据进行命名实体识别得到所述预处理文本数据中的命名实体;
30.文本词性标注模块,所述文本词性标注模块配置用于通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性;
31.文本实体补全模块,所述文本实体补全模块配置用于根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全。
32.本发明的再一方面还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述实施方式中任
意一项所述方法的步骤。
33.通过本发明提出的一种基于神经网络的合同信息提取方法,对通过实体识别模型识别后的命名实体,将其在预处理文本数据或原始文本数据中前后的分词的词性进行判断,若词性相同则补充到命名实体,从而解决了命名实体模型识别在某些情况下无法有效识别出相应地特别长的命名实体的情况,有效提高了合同信息提取中命名实体识别的准确性,提高了命名实体模型的可信度。
附图说明
34.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
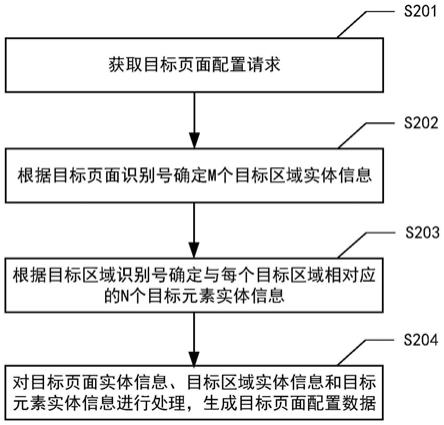
35.图1为本发明提出的一种基于神经网络的合同信息提取方法的一个实施例的方法流程图;
36.图2为本发明提供的一种基于神经网络的合同信息提取系统的系统结构图;
37.图3为本发明提供的一种基于神经网络的合同信息提取的计算机存储介质的结构示意图。
具体实施方式
38.为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明实施例进一步详细说明。
39.如图1所示,本发明实施例的第一个方面,提出了一种基于神经网络的合同信息提取方法,包括:
40.步骤s01、从合同文本中提取出原始文本数据,并对原始文本数据预处理得到预处理文本数据;
41.步骤s02、通过ner实体识别模型对所述预处理文本数据进行命名实体识别得到所述预处理文本数据中的命名实体;
42.步骤s03、通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性;
43.步骤s04、根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全。
44.在本实施例中,本发明所提供的基于神经网络的合同信息提取方法应用于web服务器端,用户可将载有合同信息的合同文件通过客户端或浏览器的方式上传到对应的服务器中,合同文件以二进制的方式保存在服务器端,当用户调用相应的租户的api
‑
key格式进行认证调用时,服务器端按照本发明的方法步骤对对应的合同信息进行信息提取并进行命名实体识别。
45.在步骤s01中,通过相关的文档读取工具读取合同文件中的内容,并对文件内容预处理。例如通过python语言中的pdfminer工具读取合同文件为pdf类型的合同文件,并将内容提取成原始文本数据。对于docx文件类型的合同文件采用python语言的docx工具提取出
合同文件中的文本内容并保存为原始文本数据。在文本提取后对原始文本数据进行预处理,去除原始文本数据中的无用字符,并保存为预处理文本数据。
46.在步骤s02中,对预处理文本数据进行实体识别,调用已经训练好的ner实体识别模型,将预处理文本数据输入到ner实体识别模型中,并保存实体识别模型的输出命名实体。
47.在步骤s03中,通过词性识别模型对预处理文本数据进行分词操作并对分词的词性进行标注,获取分词表和分词表中每一分词的词性。
48.在步骤s04中,根据步骤s02中的命名实体,在预处理文本数据中查找命名实体的位置,并向前后获取命名实体位置前后的分词的词性。根据词性是否相同而将命名实体和其前后分词进行合并。
49.在本发明的一些实施方式中,从合同文本中提取出原始文本数据,并对原始文本数据预处理得到预处理文本数据包括:
50.将所述原始文本数据中的空格及标点符号删除。
51.在本实施例中,为防止无效符号或者某些重复无意义的字符对ner实体命名模型的影响,将相应的字符从原始文本数据中删除。具体地,对原始文本数据的预处理包括将原始文本数据中的空格、标点符号删除。
52.在本发明的一些实施方式中,ner实体识别模型基于lstm神经网络并由kears和tensorflow框架训练而成。
53.在本实施例中,ner实体识别模型采用lstm神经网络算法,使用kears和tensorflow工具,并基于人民日报中文数据(约7万句,250万词左右)训练而成,用于提取合同内的地址、人名、地名等通用实体。
54.在本发明的一些实施方式中,通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性包括:
55.使用jieba分词工具在对预处理文本数据进行分词的同时对所分的分词进行词性标注。
56.在本实施例中,在对预处理文本数据进行分词和词性标注生成时,采用jieba分词工具对数据进行分词和词性生成处理。
57.在本发明的一些实施方式中,通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性还包括:
58.根据所述预处理文本数据中的命名实体在所述预处理文本数据中截取所述命名实体前后预定个数的分词组成的连续文本段落;
59.通过人工审核所述连续文本段落中的分词的词性标注结果,将词性标注有误的分词建立人工词性表;
60.响应于使用所述jieba分词工具对所述预处理文本进行分词,将所述人工词性表添加到所述jieba分词的词性表。
61.在本实施例中,在一些情况下,ner实体识别模型可能无法分辨出某些实体,比如一些人姓名较为奇怪,比如姓名中的部分词为动词的时候,或者是某些地址的名称也存在动词或者一些其他词,导致ner实体识别模型和jieba分词工具均无法有效处理,导致识别精度下降的问题。为解决ner实体识别模型和jieba分词工具对某些特定词的词性的判断不
准确的情况,对ner实体识别模型和jieba分词的结果进行纠正。
62.具体地,根据ner模型的输出的命名实体,在预处理文本数据中截取命名实体前后的至少5个分词组成的连续文本段落,并查询该文本段落在分词表中对应的词性。交由人工根据合同文件原文对该文本段落内的词性以及真实的实体进行判断,并将判断结果保存到人工词性表中。例如,对某些地名的处理时,某地名为:“某某市某某区某某打鱼村”。打鱼村,在分词时可能将打鱼分为一个动作的动词,而不会将“打鱼村”判定为一个地名,因此可能存在识别不准确的问题。因此,需要人工对于某些特殊的词进行识别,并且将识别的结果制定成特殊的词性表分配给ner实体识别和jieba分词模型进行训练,以提高其准确性。
63.在本发明的一些实施方式中,通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性还包括:
64.根据所述预处理文本数据中的命名实体在所述原始文本数据中截取所述命名实体前后预定个数的分词组成的连续文本段落。
65.在本实施例中,在确定命名实体的上下文关系时,通过原始文本数据中以至少前后5个分词的方式组成连续文本,通过原始文本数据的段落符号即标点符号的位置关系可准确得出命名实体的界限,防止出现去除标点符号后,两句话的末尾和开头完美衔接成一句话或一个名字的情况,出现识别差错。
66.在本发明的一些实施方式中,根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全包括:
67.判断所述命名实体在所述原始文本数据中的位置的前后的分词的词性是否与所述命名实体的词性相同;
68.响应于所述命名实体在所述原始文本数据中的位置的前后的分词的词性与所述命名实体的词性相同,将所述命名实体在所述原始文本数据中的位置的前后的分词和所述命名实体合并为一个命名实体。
69.在本实施例中,若ner实体识别模型识别出的命名实体在原始文本数据的前后分词词性与命名实体的词性相同,则将该命名实体的前后分词和该命名实体组成一个命名实体。例如地址:“北京市朝阳区大屯路”,在命名实体“朝阳区”的前后均是名词词性表示地理的名词,因此将“北京市朝阳区大屯路”作为一个整体的命名实体。
70.在本发明的一些实施方式中,根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全还包括:
71.响应于所述命名实体和所述命名实体在所述原始文本数据中的位置的前后的分词之间存在标点符号,则禁止所述将所述命名实体在所述原始文本数据中的位置的前后的分词和所述命名实体合并为一个命名实体。
72.在本实施例中,若命名实体的前后存在标点符号或段落分割符号“/n”,则停止命名实体与前后分词的合并。
73.如图2所示,本发明的另一方面还提出了一种基于神经网络的合同信息提取系统,包括:
74.文本处理模块1,所述文本处理模块1配置用于从合同文本中提取出原始文本数据,并对原始文本数据预处理得到预处理文本数据;
75.文本识别模块2,所述文本识别模块2配置用于通过ner实体识别模型对所述预处
理文本数据进行命名实体识别得到所述预处理文本数据中的命名实体;
76.文本词性标注模块3,所述文本词性标注模块3配置用于通过词性识别模型对所述预处理文本数据进行识别获取预处理文本数据中所有分词的词性;
77.文本实体补全模块4,所述文本实体补全模块4配置用于根据所述预处理文本数据中的命名实体在所述原始文本数据中的位置前后的分词词性对所述预处理文本数据中的命名实体进行补全。
78.如图3所示,本发明的再一方面还提供了一种计算机可读存储介质401,所述计算机可读存储介质存储有计算机程序402,所述计算机程序402被处理器执行时实现上述实施方式中任意一项所述方法的步骤。
79.通过本发明提出的一种基于神经网络的合同信息提取方法,对通过实体识别模型识别后的命名实体,将其在预处理文本数据或原始文本数据中前后的分词的词性进行判断,若词性相同则补充到命名实体,从而解决命名实体模型识别在某些情况下无法有效识别出相应地特别长的命名实体的情况,有效提高了合同信息提取中命名实体识别的准确性,提高了命名实体模型的可信度。
80.以上是本发明公开的示例性实施例,但是应当注意,在不背离权利要求限定的本发明实施例公开的范围的前提下,可以进行多种改变和修改。根据这里描述的公开实施例的方法权利要求的功能、步骤和/或动作不需以任何特定顺序执行。此外,尽管本发明实施例公开的元素可以以个体形式描述或要求,但除非明确限制为单数,也可以理解为多个。
81.所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本发明实施例公开的范围(包括权利要求)被限于这些例子;在本发明实施例的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,并存在如上所述的本发明实施例的不同方面的许多其它变化,为了简明它们没有在细节中提供。因此,凡在本发明实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明实施例的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。