1.本发明涉及通信中的模拟攻击检测技术领域,特别是涉及一种在设备到设备通信中模拟攻击检测的方法。
背景技术:
2.物理层安全性(pls)是一种积极的方法,可确保满足无线物理层的安全性要求。pls背后的关键思想是利用传输无线信道中的固有障碍来克服安全攻击或确保身份验证。另外,pls利用信道随机性和互易性,是密钥生成方法的基本概念。密钥的生成取决于无线信道的随机性和互易性而引起的信道变化。
3.在静态环境中,信道不会发生很多变化,因此随机性非常低。但是,在现实情况下,信道是动态的,很难预测发送方以及接收方之一的信道增益。因此,攻击者可以轻易地攻击通信并扮演冒充真实用户的假冒者。为了生成密钥,一种常用方法是观察时间段,即信道的相干时间。在相干时间内,系统被认为是静态的,并且密钥的生成速率降低了,较短的相干时间将显着增加无延迟获取系统信息的计算复杂度。
4.强化学习(rl)为人工智能领域带来了新奇事物。在rl方法中,用户将在动态设置中获得最佳方法,而无需了解系统的详细信息。在这项工作中,rl用于检测d2d通信中的伪装攻击。然而,由于无线通信的暴露性质,真实的d2d用户之间的信道增益难以实现。因此,攻击者可以通过假装为同一真实用户来轻松地干扰通信链路。冒充者/攻击者假装是真实的发送者,并尝试通过估计信道增益来生成密钥。
技术实现要素:
5.本发明提出一种设备到设备通信中模拟攻击检测的方法,能够识别试图在真实d2d用户之间生成伪密钥的伪装者,提高了检测精度和接收者的收益。
6.本发明设备到设备通信中使用强化学习辅助模拟攻击检测的方法,包括:
7.第一步,计算密钥生成率
8.假设a和b表示d2d对,i表示伪装者;
9.g
a,b
,g
b,a
,g
a,i
,g
b,i
分别是从a到b,b到a,a到i和b到i的信道增益;n
b
,n
a
和n
i
是方差为的链路的加性高斯白噪声;同样,g
i,a|b
是从i到a|b的信道增益,而n
a|b
是方差为的噪声;g
a,b
=g
b,a
=g1;g
a|b,i
=g
i,a|b
=g2,g1和g2均服从正态分布,均值为零,方差为和
10.令t
a
为d2d节点a传输的训练符号,在b处的估计信道增益为
[0011][0012]
其中是t
a
的共轭数;同样,在a处估计的信道增益为
[0013]
[0014]
类似地,t
i
表示为伪装者i发送的训练符号,d2d节点a|b和伪装者i的信道增益可以表示为:
[0015][0016]
d2d对之间的密钥生成率过程描述为互信息为
[0017][0018]
d2d的任何用户与伪装者之间的密钥生成率过程描述为互信息为
[0019][0020]
第二步,实施假设检验
[0021]
伪装者在一个时隙中以p
f
∈[0,1]表示的概率发送训练符号t
i
,接收端a|b估计信道增益,即和接收端对d2d链路中每个训练符号的信道增益进行采样;来自第n个发送端的第m个训练符号的信道记录表示为个发送端的第m个训练符号的信道记录表示为表示来自第n个发送端的第m个训练符号的信道记录;
[0022]
实施假设检验,假设h
o
要求训练符号确实由真实用户以估计的信道增益e
a,b
传输;相反,假设h
*
是对训练符号由仿真器以估计的信道增益e
a|b,i
传输;
[0023]
s是和之间的标准化欧几里得距离,固定测试阈值λ,当结果为λ≥0,如果则接收端确认h
o
,否则,接收端确认h
*
;因此,接收者验证假设检验是:
[0024][0025]
接收者拒绝假设检验是:
[0026][0027]
进一步地,还包括通过测量漏报率far评估模拟攻击检测,所述漏报率far是合法用户发送训练符号但接收者认为它是非真实用户,估计信道增益的概率:
[0028]
p
a
=p
a
(h
*
|h
o
)。
[0029]
进一步地,还包括通过测量错报率mdr评估模拟攻击检测,所述错报率mdr是非真实用户发送训练符号但被接收者视为合法用户的训练符号,估计信道增益的概率:
[0030]
p
b
=p
b
(h
o
|h
*
)
[0031]
所述接收者验证假设检验中的训练符号的概率为:
[0032]
p
a
(h
o
|h
o
)=1
‑
p
a
[0033]
所述接收者拒绝假设检验中的非真实训练符号的概率为:
[0034]
p
b
(h
*
|h
*
)=1
‑
p
b
[0035]
当训练符号从发送端发送而被接收端接收,则更新信道记录即否
则,将其更新为
[0036]
本发明有益效果:
[0037]
使用q
‑
learning技术来克服d2d通信中的伪装攻击,以确保用户的真实性。这有助于识别试图在真实d2d用户之间生成伪密钥的伪装者。
[0038]
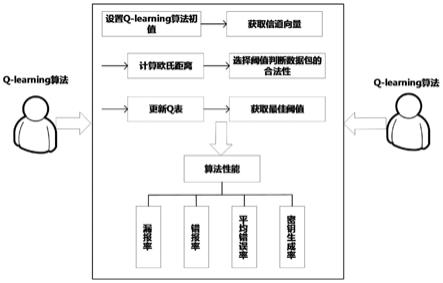
在假设检验中得出最佳阈值。这有助于区分真实用户和非真实用户。从假设的经验来看,它也有助于提高检测精度和接收者的收益(获得或丢失)。
[0039]
通过分别测量漏报率(far),错报率(mdr),平均错误率(aer)和密钥生成(skg)率(skgr)来评估所提出技术的性能。零和博弈,q
‑
learning和m.waqas通过可信和不可信的继电器生成安全设备通信间的社会意识密钥中用到的方法进行比较。结果表明,q
‑
learning优于传统方法。
附图说明
[0040]
图1:本发明方法流程示意图;
[0041]
图2接收端far检测基于零和博弈,对比m.waqas论文中的方法和q
‑
learning;
[0042]
图3接收端mdr检测基于零和博弈,对比m.waqas论文中的方法和q
‑
learning;
[0043]
图4接收端aer检测基于零和博弈,对比m.waqas论文中的方法和q
‑
learning;
[0044]
图5 skg速率基于零和博弈,对比m.waqas论文中的方法和q
‑
learning。
[0045]
图2
‑
图4中,三条线从上到下分别表示零和博弈、对比m.waqas论文中的方法和q
‑
learning方法,图5中条状图从左到右分别表示零和博弈、对比m.waqas论文中的方法和q
‑
learning方法。
具体实施方式
[0046]
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。可以理解的是,此处所描述的具体实施例仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
[0047]
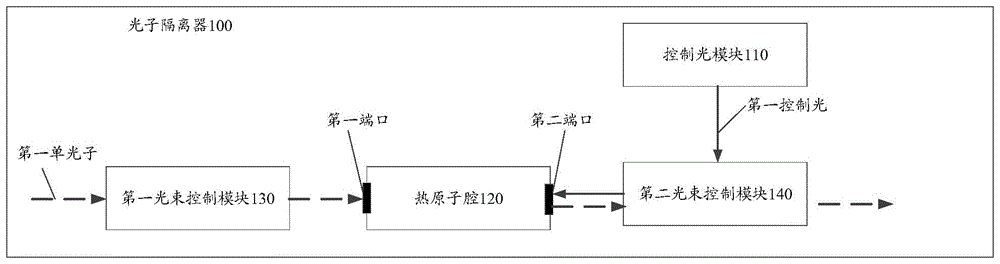
图1为本发明方法流程示意图。
[0048]
在pls的传统概念中考虑了d2d对,即a和b表示alice(a)和bob(b)。伪装者用i表示。在信道估计阶段,a和b分别对信道进行估计。具体地,在第一时隙中,alice(a)发送训练符号t
a
,而bob(b)和伪装者节点(i)接收信号y
b
=g
a,b
t
a
n
b
,并且y
i
=g
a,i
t
a
n
i
。同样,bob(b)在第二个时隙中传送训练符号d
b
,alice(a)和伪装者(i)接收信号,即y
a
=g
b,a
t
b
n
a
和y
i
=g
b,i
t
b
n
i
。在第三时隙中,伪装者(i)发送训练符号t
i
,并且信号由a|b确认,即y
a|b
=g
i,a,b
t
i
n
a|b
。
[0049]
a|b表示a或b是来自伪装者i,g
i,a,b
表示伪装者i到a和b到时的信道增益。g
a,b
,g
b,a
,g
a,i
,g
b,i
分别是从a到b,b到a,a到i和b到i的信道增益。n
b
,n
a
和n
i
是方差为的链路的加性高斯白噪声(awgns)。同样,g
i,a|b
是从i到a|b的信道增益,而n
a|b
是方差为的噪声。认为网络伪装了时分双工(tdd)协议,并且提出了信道互易性。所以,有g
a,b
=g
b,a
=g1;g
a|b,i
=g
i,a|b
=g2。g1和g2均服从正态分布,均值为零,方差为和即和
d2d对a,b和伪装者i可以分别估计信道增益g1和g2。令t
a
为d2d节点a传输的训练符号。在b处的估计信道增益为
[0050][0051]
其中是t
a
的共轭数。同样,在a处估计的信道增益为
[0052][0053]
类似地,t
i
表示为伪装者i发送的训练符号。d2d节点a|b和伪装者i的信道增益可以表示为:
[0054][0055]
d2d对之间的最佳密钥生成率(skgr)的基本描述可以说明为互信息
[0056]
令p为发射功率,c
t
是信道相干时间,skgr为
[0057][0058]
类似地,d2d的任何用户与伪装者之间的skgr过程可以描述为互信息是
[0059][0060]
伪装者在一个时隙中以p
f
∈[0,1]表示的概率发送训练符号t
i
。接收端a|b近似于信道增益,即和a|b分别与训练符号t
a
,t
b
和t
i
相关。接收端对d2d链路中每个训练符号的信道增益进行采样。因此,来自第n个发送端的第m个训练符号的信道记录表示为我们也用表示来自第n个发送端的第m个训练符号的信道记录。和分别是每个发送端训练符号的信道向量和信道记录。
[0061]
实施假设检验,以从训练符号(即具有信道向量的训练符号)中从真实发送端或伪装者接收信道增益的有效性进行检验。因此,我们指出了用户的信道增益,该信道增益以的信道记录传输训练符号。假设h
o
要求训练符号确实由真实用户以估计的信道增益e
a,b
传输。相反,假设h
*
是对不真实发送端的测试,即训练符号由仿真器以估计的信道增益e
a|b,i
传输。因此,接收者对假冒行为的检测是基于随后的假设检验,即和
[0062]
如果信道向量即和信道记录不能区分,则由发送端发送的训练符号和估计的信道增益将被视为合法用户,即e
a,b
。否则,训练符号由非合法用户即e
a|b,i
发送。在这一阶段,计算假设检验的统计量为:
[0063]
[0064]
在(6)中,||
·
||是弗罗贝尼厄斯范数,s是和之间的标准化欧几里得距离。任意维向量之间可以算出欧式距离,当维度为2的时候,则是在笛卡尔坐标系下可以计算的两点之间距离。在本发明中为了要控制新的信道向量和上一条信道向量之间的距离在一定范围内,所以使用的标准化欧氏距离,以上一条信道向量作为标准,计算新的信道向量和上一条信道向量之间的距离(差距)。
[0065]
我们固定了测试阈值,即λ。因此,当结果为λ≥0,如果则接收端确认h
o
,否则,接收端确认h
*
。因此,假设检验是
[0066][0067]
合法用户之间的skgr为r
a,b
,如式(4)所示。另一方面,
[0068][0069]
合法用户的接收端和伪装者之间的skgr为r
a|b,i
。接下来,阐述了far和mdr的可能性。
[0070]
定义1:far是合法用户发送训练符号但接收者认为它是非真实用户并因此估计信道增益的概率,
[0071]
p
a
=p
a
(h
*
|h
o
)
ꢀꢀꢀꢀ
(9)
[0072]
其中,p
a
(
·
|
·
)是条件概率。
[0073]
定义2:mdr是非真实用户发送训练符号但被接收者视为合法用户的训练符号,并估计信道增益的概率。
[0074]
p
b
=p
b
(h
o
|h
*
)
ꢀꢀꢀꢀ
(10)
[0075]
因此,接收者验证(7)中的训练符号的概率表示为:
[0076]
p
a
(h
o
|h
o
)=1
‑
p
a
ꢀꢀ
(11)
[0077]
同样,接收者拒绝(8)中的非真实训练符号的概率为:
[0078]
p
b
(h
*
|h
*
)=1
‑
p
b
ꢀꢀ
(12)
[0079]
(7)和(8)中的精度检测依赖于测试阈值即λ。因此,一旦训练符号从发送端发送而被接收端接收,则更新信道记录即,否则,将其更新为
[0080]
对于伪装检测技术,可以利用零和博弈。在零和博弈中,每个用户(合法或非合法)参与者的使用收益或成本均由其他用户(合法或非合法)的使用成本或收益精确平衡。因此,可以通过零和博弈来计算用户估计彼此的信道增益的增益和成本。接收端的增益可以定义为丢弃训练符号和非合法发射端的估计信道增益。另一方面,成本可以定义为丢弃训练符号和合法发射端的估计信道增益。为此,我们考虑d2d通信网络的一般情况。令d为真实d2d对d
i
,即d
i
∈d的集合。发射端和接收端节点分别由集合t表示,t
x
为t
x
∈t,而r表示为r
x
∈r。最后,网络中的伪装者由i和i∈i的集合表示。接收者通过pls身份验证来识别伪装攻击。未经认证的用户选择概率为p
i
∈[0,1]的训练符号,未经认证的用户的所有训练符号的集合由y∈p
i
表示;可以相信没有真实身份的用户,例如∑p
i
可以彼此协作以发送不真实的训练符号,假设只有一个非合法用户可以在一个时隙中作为假冒者进行攻击,接收端获得伪
造训练符号的概率为∑p
i
。
[0081]
伪装检测技术的准确性取决于接收端的效用功能。此外,用于估计合法发送端的信道增益的接收端的增益由g1表示,而用于丢弃训练符号的接收端的增益和对非合法发送端的估计的信道增益由g0表示。相应地,g1是接收者丢弃合法节点的训练符号的成本。此外,g0是接收端接受来自非真实用户的虚假训练符号的成本。伪装攻击的贝叶斯风险定义为:
[0082]
e(λ,y)=(g1(1
‑
p
a
(λ))
‑
c1p
a
(λ))(1
‑
∑
i
p
i
) (g0(1
‑
p
b
(λ))
‑
c0p
b
(λ))(1
‑
∑
i
p
i
) (13)
[0083]
在上式中,(g1(1
‑
p
a
(λ))
‑
c1p
a
(λ))(1
‑
∑
i
p
i
)与从合法发送端的训练符号的估计信道增益估计的效用增益有关,而(g0(1
‑
p
b
(λ))
‑
c0p
b
(λ))∑
i
p
i
是伪装攻击下的增益。非真实用户和零和博弈中的接收端的效用由u
i
(λ,y)和如(13)中的贝叶斯风险所示,非真实用户和接收端的效用是
[0084][0085]
用单个攻击者进行的pls伪装检测由表示。它由接收端r
x
和攻击者i组成。因此,接收端选择其阈值λ∈[0,∞]
…
,攻击者确定攻击频率,即p1∈[0,1]。
[0086]
在动态环境中,可以使用q
‑
learning获得信息不足的最优策略。还指示接收端不知道信道模型,并且伪装训练符号以生成skg。因此,接收端可以通过伪装检测中的反复试验来达到最佳阈值。通常,最佳阈值λ*会随着伪装攻击的次数而降低。而且,每个代理都应该学习如何在q
‑
learning算法中达到最佳策略。接收端建立假设检验,以估计在该时隙中确认的每个训练信号的发送器。从l 1个值中选择测试阈值即λ,即λ∈{1/l}
0≤l≤l
。状态在接收端c
t
时观察到,并由表示,其中代表在c
t
‑1时的far和mdr。用表示,其中s是接收端检测到的所有状态的集合。错误率被量化为l 1个级别,例如p
a
,p
b
∈[1/l}
0≤l≤l
。接收者根据状态选择其动作以利用表示的估计效用总和,即
[0087][0088]
测试阈值的最佳值λ
*
由下式指定
[0089][0090]
是基于状态和动作λ的q学习中的q值,以获得测试阈值λ
*
的最佳值。此外,接收端通过基于ε
‑
greedy策略的概率来指定次优操作。所以在每一个状态下选择最优行动的概率是1
‑
ε,概率为
[0091][0092]
在(15)式中,是立即收益函数。q
‑
learning中的伪装检测很大程度上取决于学习率,即μ∈(0,1]。它需要当前q函数即折扣因子δ表示对当前奖励的折扣,用δ
∈(0,1]表示。状态s的最大q函数值由σ(s)给出。接收端依下式更新其q值:
[0093][0094][0095]
节点任意分布在200
×
200m2的正方形区域中。我们将n(0,1)是通道增益的分布。对于所有awgn通道,此外,用户的发射功率设置为p=23dbm,信道范围的相干时间c
t
为20个符号。根据第三节中定义的集合,总共划分了50个节点,以使40个节点被视为d2d对(40/2=20个对),而其余10个节点被视为伪装者。
[0096]
图2清楚地表明,在q
‑
learning情况下far较低,显然,接收端更精确地注意到训练符号的估计信道增益。因此,真实用户发送训练符号的可能性较低,但是接收者将其识别为非真实用户。如图2所示,当节点数为50时,用于q
‑
learning的far概率分别和零和博弈和通过可信和不可信的继电器生成安全设备通信间的社会意识密钥中完成的工作分别高52%和43%。
[0097]
同样,q
‑
learning技术中的mdr优于零和博弈和现有工作,使用此方法,接收端比固定检测更准确地区分真实用户和非真实用户。从图3可以看出,当节点数为50时,q
‑
learning的mdr分别比其他两种方法分别高13%和42%。
[0098]
为进一步比较解决方案,将far和mdr结合在一起使用aer,如图4所示,可以看出,基于q
‑
learning的接收端的检测精度分别比其他两种方案高16%和32%。
[0099]
如图4所示,具有50个节点的基于q
‑
learning的skgr分别比传统方法高出22%和30%。
[0100]
基于q
‑
learning的解决方案结合了信道变化的动态性,通道变化越大,通道中的随机性就越高,因此,密钥生成的速率也越高。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。