本发明涉及系统控制领域,具体地说,是一种新的原子钟信号预测方法、装置及系统。
背景技术:
时间的一个显著特征是可利用电波来传递高准确度量值。随着通信技术水平的提高,时间信息的同步与准确性作用巨大,因此对时间频率传递和准确性的要求不断提高。根据原子钟本身的漂移特性,使用者需要通过溯源至更高精度的标准源进行时间频率比对来保持原子钟的准确运行。但是现有的算法采用的计算模式较为复杂,通常需要在每个迭代预测过程中将p组数据均进行最小二乘法拟合,并利用误差的倒数归一化后进行权重赋值。在预测数据时间尺度较长、分组数量较多时,计算最终结果耗费的计算量很大。因此需要一种能有效解决上述问题的新的原子钟信号预测方法。
技术实现要素:
本发明的目的在于提供一种新的原子钟信号预测方法,为实现上述目的,本发明采用的技术方案如下:
本发明包括以下步骤:
a获取历史数据时间段内的时间点数据;
b将时间点数据随机分为p个子集;
c对所述子集拟合更新后的曲线,计算所述曲线的权重值;
d获取原子钟预测的输出结果,所述原子钟预测模型由基于最小二乘支持向量算法选取的核函数构建获取;
e根据所述原子钟预测的输出结果,返回步骤c进一步计算输出结果。
进一步地,所述权重值的计算方法如下:。
具体地,所述输出结果的计算方法如下:
一种原子钟信号预测装置,包括:
数据获取模块,获取预设时间段内的数据;
数据拆分模块,将所述数据分成多组非重合子集数据;
数据处理模块,计算所述多组非重合子集数据中的至少两组非重合子集数据所对应的估计和/或预测数据;
校正控制模块,通过所述至少两组估计和/或预测数据产生校准后数据。
进一步地,所述数据获取模块,包括:数据更新单元,用于获取更新的数据。
进一步地,所述数据处理模块,还包括数据保持单元,保持至少一组非重合子集数据所对应的估计和/或预测数据不变。
进一步地,所述数据处理模块,还包括数据变更单元,仅依据更迭的数据重新计算至少一组非重合子集数据所对应的估计和/或预测数据。
一种原子钟信号预测系统,包括所述的原子钟信号预测装置,并进一步包括原子钟信号预测生成装置。
与现有技术相比,本发明具有以下有益效果:
本发明采用的新算法可以提高运算效率,并在预测迭代的过程中检测和筛选出离群点,降低预测的不确定性,有效地提高了原子钟预测的准确度和稳定性,在时间频率系统对比及控制系统的应用等领域存在一定的潜能和研究价值。
附图说明
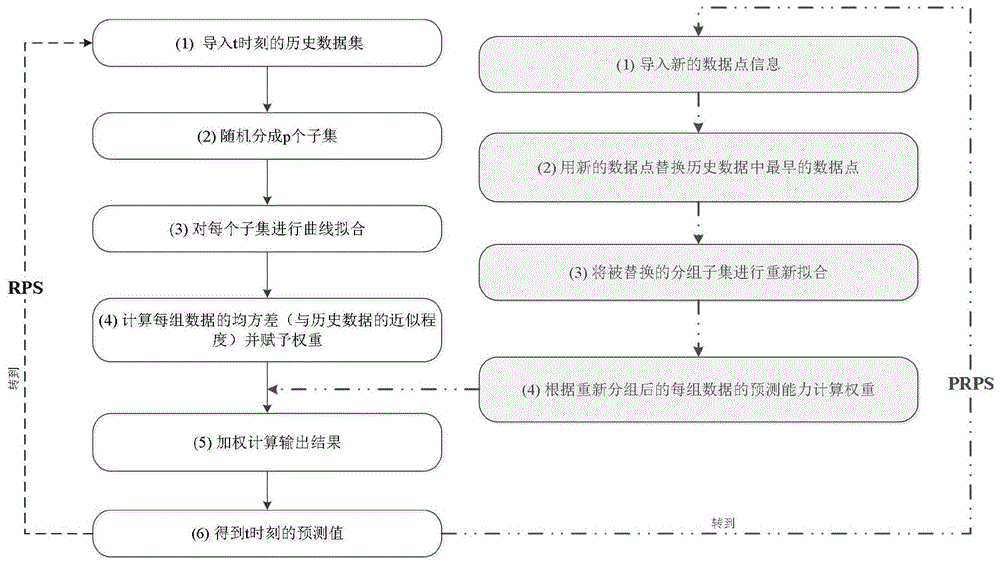
图1为原算法(randompursuitstrategy,rps)和本发明(pseudorandompursuitstrategy,prps)两种算法的流程示意图;
图2为原算法(rps)和本发明(prps)两种算法预测误差对比示意图;
图3为原算法(rps)和本发明(prps)两种算法不确定度对比示意图;
图4为原算法(rps)和本发明(prps)两种算法运行时间随分组数量的变化结果示意图;
图5为原算法(rps)和本发明(prps)所计算时标的allan标准偏差对比示意图;
具体实施方式
下面根据实施例对本发明作进一步说明,本发明的方式包括但不仅限于以下实施例。
本发明包括以下步骤:
a获取历史数据时间段内时间点数据;
b将时间点数据随机分为p个子集;
c对所述子集拟合更新后的曲线;
d计算所述曲线的权重值;
e获取原子钟预测的输出结果,所述原子钟预测模型由基于最小二乘支持向量算法选取的核函数构建获取;
根据所述原子钟预测的输出结果,返回步骤c进一步计算输出结果。
具体的算法实例如下,表一是生成的仿真数据,一共有57个数,初始使用的是前49个数据,随机分组为p=7组,对其进行分组最小二乘拟合,首先按照公式(1)计算得到每组数据的拟合误差,其中:y'(t)是预测序列,y(t)是原始数据。
得到的误差表现了这组数据的预测能力,误差越小,预测能力越强,所以每组数据的权重应根据拟合误差的反比进行赋权:
表1原始数据
初始拟合的每组数据的误差,分配的权重如下表2所示:
完成第一次拟合之后,prps算法将新读取的数据(编号50)替代原有数据组中最早的数据(编号1),不再进行随机分组,而是将被替换的子集单独拟合,减小了计算复杂度。然后根据新的拟合结果再次分配权重,表2下方显示了第一次替换的数据编号。
表2分组预测结果以及迭代过程
在第二次预测过程中,编号为50的新读取数据,替换了第5组中编号为1的最早数据。
所述输出结果的计算方法如下:
如图1所示,原算法在每个迭代预测过程中通常将p组数据均进行最小二乘法拟合,并利用误差的倒数归一化进行权重赋值,计算最终结果。本发明每次只进行单一子集的曲线拟合,后重复更新数据以提高时间计算精度,同时减小了整体的计算量,在预测数据时间尺度较长,分组数量较多时更有优势。仿真实验结果表明,这种简化并不会影响原有的预测效果,并且在离群点的检测方面还有不错的效果。
为了模拟原子钟数据的真实情况,随机生成一组具有频率偏差、频率漂移和随机游走噪声的数据,每个原子钟的时间序列表示为:
y(t)=[a ε1*gn1(μ1,σ1)] [b ε2*gn2(μ2,σ2)]t
其中a和b分别表示频率和频率漂移,gn1(μ1,σ1)和gn2(μ2,σ2),为高斯噪声,具有均值μ和方差σ(σ1=σ2=0),ε1和ε2是高斯噪声能量的可调系数。模拟中使用的参数为a0=μ0=μ1=0,b1=10-15,σ1=2×10-30,σ2=10-34。
图2为两种算法预测误差对比,图3为两种算法的不确定度对比,图4为运行时间随分组数量的变化结果,本发明算法与原算法相比,两者具有几乎相同的预测能力,但本发明算法在长时间尺度上具有更小的不确定度,鲁棒性更强;另外本发明算法在时间复杂度上有明显的优势,该优势随着分组数量的增加愈加明显。
利用本发明算法检测离群点
本发明算法中两个相邻测量值之间的相关性用于异常值的识别,对于原算法,每个随机组之间彼此独立:
而对于本发明算法,当前预测值的偏差与之前的预测值并不独立。t 1时刻本发明算法的不确定性为:
可以看出,本发明算法中的前一个误差会对后一个误差产生影响。由于本发明算法一次只计算n组数据中的其中一组,假设tth处的均方差为
为了剔除异常值对allan方差的影响,展示不同方法在数据波动情况下的效果,通过调整实验数据中异常值的比例,并计算相应的allan偏差,得到如图5所示的结果。结果表明,新的预测方法能在剔除异常值后减小allan偏差,因为明显的异常值被剔除的概率很大,而小部分误判的正常值即使被剔除也不会影响预测结果。
上述实施例仅为本发明的优选实施方式之一,不应当用于限制本发明的保护范围,但凡在本发明的主体设计思想和精神上作出的毫无实质意义的改动或润色,其所解决的技术问题仍然与本发明一致的,均应当包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。