1.本发明涉及负载均衡领域,具体涉及一种基于多核处理器的分组突发负载均衡方法及系统。
背景技术:
2.在10gbps以上的高速网络下,网络流量监控处理设备常常需要在一秒内处理数以百万计的网络数据包,并且在同一设备中执行多种数据包处理流程,例如深度包检测和活跃网络流统计等。通过设置不同的应用类型,此类设备即可用于数据中心等生产环境,也可用于校园和产业园区等场所,对通过部分节点的网络流量进行分析。
3.现有的部分工作采用生产者消费者模型,其中生产者与网卡对接,将网卡接收到的网络数据包按照预定规则分类,对应不同的上层处理流程,并放入与该类别相对应的缓冲区内;在任意类别下,对应有一组消费者从对应缓冲区中取出网络数据包,执行分析和处理任务。为了降低硬件成本,加速网络数据包的处理,现有的部分工作选择通用硬件,通过绕过操作系统内核协议栈等方法避免不必要的上下文切换和内存复制。其所使用的通用硬件常采用多核架构,其中的消费者和生产者均为线程,利用并行执行计算任务加速处理过程,从而进一步提高网络流量处理设备的性能。与此同时,为了保持每条网络流的状态,提高缓存利用率,避免计算结果错误,同时减少锁的使用,属于同一条网络流的数据包在某一时刻只能由一个消费者线程进行处理,因此生产者线程需要以网络流为粒度分发数据包。
4.在该场景下,生产者线程缓存数据包的速度与网络状况相关,包括网络速率变化以及流量成分等。而与此同时,现有工作中任意一缓冲区下的消费者线程数量和处理流程是固定的,其整体处理速度不会随着网络环境产生变化。因此存在一定时刻,部分消费者线程单位时间内的计算负载大幅上升,超过了其处理上限,持续消耗缓冲区容量,进而影响网络流量的处理效果,包括增加处理延迟等,严重甚至会引起丢包,此处称其为产生了拥塞。
5.针对上述问题,需要对处理过程中的拥塞进行快速检测和定位,并调整数据包分发规则,将计算任务转移至负担较轻的消费者线程进行处理,以充分利用缓冲区和多核处理器,规避拥塞带来的性能下降,并且调整的同时保持网络流状态。
6.由于基于通用硬件的流量处理常使用轮询方式替换传统的系统中断,处理器的使用率一直处于100%,无法直接体现处理器的使用效率,因此需要寻找合适的方法对处理器的处理负载进行量化,并进一步对该消费者处理的流量进行分析,确定需要重新映射的网络流。为了保证处理流程的正确性,需要在调整数据包分发规则时对数据包进行保序,避免数据包乱序。
技术实现要素:
7.为了解决上述技术问题,本发明提供一种基于多核处理器的分组突发负载均衡方法及系统。
8.本发明技术解决方案为:一种基于多核处理器的分组突发负载均衡方法,包括:
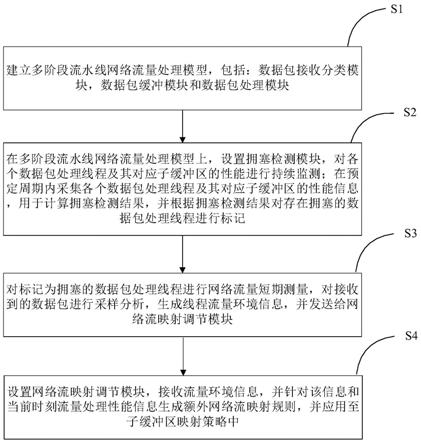
9.步骤s1:建立多阶段流水线网络流量处理模型,包括:数据包接收分类模块、数据包缓冲模块和数据包处理模块;
10.其中,所述数据包接收分类模块包含多个线程以及多个数据包分类规则;
11.所述数据包缓冲模块包含多个缓冲区域,每个所述缓冲区域包含多个子缓冲区,其中所述缓冲区域个数与所述分类规则个数相同;
12.所述数据包处理模块包含多个上层处理应用,每个所述上层处理应用对应一组数据包处理线程,其中所述数据包处理线程与所述子缓冲区一一对应;
13.步骤s2:在所述多阶段流水线网络流量处理模型上,设置拥塞检测模块,对各个所述数据包处理线程及其对应子缓冲区的性能进行持续监测;在预定周期内采集各个所述数据包处理线程及其对应子缓冲区的性能信息,用于计算拥塞检测结果,并根据所述拥塞检测结果对存在拥塞的所述数据包处理线程进行标记;
14.步骤s3:对标记为拥塞的所述数据包处理线程进行网络流量短期测量,对接收到的数据包进行采样分析,生成线程流量环境信息,并发送给网络流映射调节模块;
15.步骤s4:设置所述网络流映射调节模块,接收流量环境信息,并针对该信息和当前时刻流量处理性能信息生成额外网络流映射规则,并应用至子缓冲区映射策略中。
16.本发明与现有技术相比,具有以下优点:
17.1、本发明实现了对网络流量拥塞的快速检测,在微秒级别对其进行响应,能够实现对更小时间范围内流量突发的识别与处理。
18.2、本发明实现了网络流在线程间的动态调度,提高了对多线程模型计算能力的利用率,减少了网络流量突发对处理性能的影响。
19.3、本发明采用了采样的方式确定引起拥塞的网络流,避免了持续性流量统计所带来的性能消耗。
20.4、本发明实现了网络流动态调度过程中的数据包保序,避免上层应用对接收到的数据包进行重排序,在保证计算结果正确的前提下降低了上层应用的实现难度。
附图说明
21.图1为本发明实施例中一种基于多核处理器的分组突发负载均衡方法的流程图;
22.图2为本发明实施例中一种基于多核处理器的分组突发负载均衡方法中步骤s1:建立多阶段流水线网络流量处理模型的流程图;
23.图3为本发明实施例中子缓冲区映射策示意图;
24.图4为本发明实施例中一种基于多核处理器的分组突发负载均衡方法中步骤s2:在多阶段流水线网络流量处理模型上,设置拥塞检测模块,对各个数据包处理线程及其对应子缓冲区的性能进行持续监测;在预定周期内采集各个数据包处理线程及其对应子缓冲区的性能信息,用于计算拥塞检测结果,并根据拥塞检测结果对存在拥塞的数据包处理线程进行标记的流程图;
25.图5为本发明实施例中一种基于多核处理器的分组突发负载均衡方法中步骤s3:对标记为拥塞的数据包处理线程进行网络流量短期测量,对接收到的数据包进行采样分析,获取线程流量环境信息,并发送给网络流映射调节模块的流程图;
26.图6为本发明实施例中一种基于多核处理器的分组突发负载均衡方法中步骤s4:
设置网络流映射调节模块,接收流量环境信息,并针对该信息和当前时刻流量处理性能信息生成额外网络流映射规则,并应用至子缓冲区映射策略中的流程图;
27.图7为本发明实施例中基于多核处理器的分组突发负载均衡方法的流程示意图;
28.图8为采用rss方法和本发明提供的方法下不同线程中数据包自接收到处理完成的时延比较结果示意图;
29.图9为本发明实施例中一种基于多核处理器的分组突发负载均衡系统的结构框图。
具体实施方式
30.本发明提供了一种基于多核处理器的分组突发负载均衡方法,实现了对网络流量拥塞的快速检测,实现网络流在线程间的动态调度,以及调度过程中的数据包保序,避免上层应用对数据包进行重排序,降低上层应用的实现难度。
31.为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
32.本发明实施例使用dpdk(data plane development kit)作为基础软件方案。dpdk是intel公司开发的基于数据平面的数据包处理框架,为用户态应用程序提供各类接口,通过旁路操作系统网络协议栈,直接对网卡进行读写,以实现高速网络下数据包的快速接收、处理和发送。dpdk常采用多线程模型,可以通过设置线程亲和等方式,将多核处理器中的不同核心与线程进行绑定,减少线程调度的开销,以提高处理性能。本发明实施例使用的硬件设备至少包括一个处理器,其中该处理器包含多个核心;包含一个网卡,包含一个或多个硬件网卡队列,用于接收网络数据包。在本发明实施例中,使用的终端设备为安装有linux系统的pc设备,采用intel xeon phi 7210处理器和intel 82599网卡,其中处理器包括64个核心,支持4路超线程,单核主频为1.3ghz,网卡支持最高10gbps的网络传输带宽。
33.实施例一
34.如图1所示,本发明实施例提供的一种基于多核处理器的分组突发负载均衡方法,包括下述步骤:
35.步骤s1:建立多阶段流水线网络流量处理模型,包括:数据包接收分类模块、数据包缓冲模块和数据包处理模块;
36.其中,数据包接收分类模块包含多个线程以及多个数据包分类规则;
37.数据包缓冲模块包含多个缓冲区域,每个缓冲区域包含多个子缓冲区,其中缓冲区域个数与分类规则个数相同;
38.数据包处理模块包含多个上层处理应用,每个上层处理应用对应一组数据包处理线程,其中数据包处理线程与子缓冲区一一对应;
39.步骤s2:在多阶段流水线网络流量处理模型上,设置拥塞检测模块,对各个数据包处理线程及其对应子缓冲区的性能进行持续监测;在预定周期内采集各个数据包处理线程及其对应子缓冲区的性能信息,用于计算拥塞检测结果,并根据拥塞检测结果对存在拥塞的数据包处理线程进行标记;
40.步骤s3:对标记为拥塞的数据包处理线程进行网络流量短期测量,对接收到的数据包进行采样分析,生成线程流量环境信息,并发送给网络流映射调节模块;
41.步骤s4:设置网络流映射调节模块,接收流量环境信息,并针对该信息和当前时刻流量处理性能信息生成额外网络流映射规则,并应用至子缓冲区映射策略中。
42.如图2所示,在一个实施例中,上述步骤s1:建立多阶段流水线网络流量处理模型,包括:数据包接收分类模块、数据包缓冲模块和数据包处理模块;
43.其中,数据包接收分类模块包含多个线程以及多个数据包分类规则;
44.数据包缓冲模块包含多个缓冲区域,每个缓冲区域包含多个子缓冲区,其中缓冲区域个数与分类规则个数相同;
45.数据包处理模块包含多个上层处理应用,每个上层处理应用对应一组数据包处理线程,其中数据包处理线程与子缓冲区一一对应,具体包括:
46.步骤s11:构造数据包接收分类模块:数据包接收分类模块包含多个并行执行的线程,当开始数据包接收分类模块后,属于该模块的所有线程同时开始执行;数据包接收分类模块包含多个线程{cthread1,cthread2,
…
,cthread
n
,...,cthread
n
},其中,cthread
n
是该模块中的第n个线程,n表示所述数据包接收分类模块中的线程个数。数据包接收分类模块用于从网卡中接收网络数据包,并按照分类与映射规则将其放入数据包缓冲模块的不同位置;在任意一个时刻,cthread
n
采用轮询的方式访问网卡上的硬件队列,如果队列中存在尚未处理的网络数据包,则将其从网卡中取出,存放于线程cthread
n
对应的用户态区域。其中,对于任意两个编号不同的线程和其对应的硬件网卡队列不同;对于网卡接收的任意一个数据包,一定会由该模块中的一个线程取出并进行处理。
47.在本发明实施例中,n设置为8,即数据包接收分类模块中包含8个线程,分别对应intel 82599网卡上的8个硬件队列。
48.数据包接收分类模块还包含多个数据包分类规则{rule1,rule2,
…
,rule
m
,...,rule
m
};rule
m
是数据包接收分类模块设定的第m条数据包分类规则;m为数据包接收分类模块中预设的数据包分类规则的条数。对于任意一个线程cthread
n
取出的数据包,线程将其与设定的数据包分类规则{rule1,rule2,
…
,rule
m
,...,rule
m
}依次进行比对,对于任意两个标号不同的数据包分类规则和若存在m1<m2,则m1对应的规则优先级高与m2对应的规则优先级。对于任意一个网络数据包,如果存在多条与之匹配的分类规则,则选择优先级最高的作为匹配结果。在上述分类规则中,rule
m
为默认规则,其优先级最低,可以与任意数据包完成匹配。对于匹配到的最高优先级分类规则rule
m
,将其标识号m与数据包传递至数据包缓冲模块。
49.对于任意一个分类规则rule
m
包含分类标识信息分别表示匹配该分类规则的网络数据包对应的起始源ip网络地址,终止源ip网络地址,起始目的ip网络地址,终止目的ip网络地址,起始源端口号,终止源端口号,起始目的端口号和终止目的端口号。对于线程cthread
n
处理的任意一个数据包从中提取标识信息分别代表该数据包对应的源ip网络地址,目的ip网络地址,源端口号,目的端口号和协议号,如果不包含对应信息,则设对应项为空。进行规则匹配时,将数据包标识依次与分类标识进行比较,以源ip网络地址为例,如果大于且小
于则认为源ip网络地址符合该分类规则。如果源ip网络地址,目的ip网络地址,源端口号,目的端口号和协议号均符合上述要求,则认为数据包与该分类规则rule
m
匹配,此处标记该数据包为分类规则预先设置,在模块运行过程中不变。
50.步骤s12:构造数据包缓冲模块:数据包缓冲模块包含多个缓冲区域{area1,area2,
…
,area
m
,...,area
m
},area
m
是该模块中的第m个缓冲区域,m为数据包缓冲模块中预设的缓冲区域个数,与数据包分类规则的条数相同,并且一一对应;每个缓冲区域包含多个子缓冲区d为第m个缓冲区域中的子缓冲区个数;根据子缓冲区映射策略,将数据包存入对应的子缓冲区。
51.该模块中的任意两个缓冲区域和若m1≠m2,则其包含的子缓冲区交集为空,且所有缓冲区域中包含的子缓冲区并集为全集,即任意一个子缓冲区必定唯一存在于一个缓冲区域area
m
中。对于数据包接收分类模块中的任意一条分类规则rule
m
,一定唯一存在一个缓冲区域area
m
与之对应。对于传递至该模块的数据包及其分类规则标号m,数据包缓冲模块将其放入缓冲区域area
m
中。对于进入到缓冲区域area
m
中的任意一个数据包子缓冲区策略依据该数据包包含的数据信息,返回子缓冲区编号d,该模块依据该编号将其放入对应的子缓冲区中。对于子缓冲区映射策略,在任意一个时刻,接收属于同一个网络流的数据包作为输入,会返回相同的子缓冲区标识号。
52.在本发明实施例中,子缓冲区由固定长度的环形缓冲队列实现,为首尾相连的先入先出的数据结构,包含有一个读指针和一个写指针,其中读指针指向环形缓冲区中可读的数据位置,写指针指向环形缓冲区中可写的数据位置,此处称其访问者分别为写用户和读用户。在进行读取和写入时,会依据数据访问情况移动上述两个指针。本发明实施例中的环形缓冲队通过加锁保护,确保支持多个写用户和一个读用户。对于任意一个数据包将其在内存中的访问地址依据读指针写入环形缓冲队列,如果队列已满,则停止写入,并将该数据包对应的内存释放。在本发明实施例中,子缓冲区长度固定,最多能够存储4096个数据包的指针数据。
53.在本发明实施例中,如图3所示,子缓冲区映射策略由额外映射策略和基础映射策略两个部分组成。对于子缓冲区映射策略接收的任意一个网络数据包提取其标识信息首先使用额外映射策略,额外映射策略由哈希表实现,并采取读写锁同步其查询和修改。哈希表中包含多个哈希表项,存储键值对{key
h
,value
h
},其中key
h
是数据包标识信息,value
h
是目标子缓冲区标识号。因此,可以通过计算哈希值和对比表项判断是否存在与该数据包对应的额外映射规则。哈希值的计算算法为toeplitz。如果查询失败,则将哈希值作为基础映射策略的输入。具体地,基础映射策略计算目标子缓冲区标识号d
target
的计算公式为:其中,mod为取模运算。
54.在本发明实施例中,对于任意一个映射调整前后的目标子缓冲区一定
属于同一个缓冲区域,最终由同一个上层应用进行处理。
55.步骤s13:构造数据包处理模块:数据包处理模块包含m个上层处理应用,每个上层处理应用对应一组数据包处理线程其中,为数据包处理模块中第m个上层处理应用中的第d个线程;第m个上层处理应用中的线程与缓冲区域area
m
中的子缓冲区一一对应,处理线程从子缓冲区取出数据包,并执行分析处理。
56.在本发明实施例中,处理线程采用轮询方式,持续循环访问子缓冲区的读指针。具体地,在本发明实施例中,每次访问子缓冲区如果存储的数据包指针数量大于32个,则在本次访问中依次取出读指针指向的前32个数据包指针;如果数量小于32个,则依次将其全部取出。处理线程依据读取到的数据包指针访问其内容并进行处理,处理结束或者访问子缓冲区为空时,立即再次访问。在本发明实施例中,处理线程的处理器使用率持续为100%。
57.在本发明实施例中,上层处理应用包括深度包检测和heavy
‑
hitter流检测。其中,深度包检测由ndpi库实现,该开源库是由opendpi发展而来,基于c语言编写,支持多种协议识别;heavy
‑
hitter流检测则使用lossy
‑
counting算法对各条网络流中的数据包数量进行统计。
58.如图4所示,在一个实施例中,上述步骤s2:在多阶段流水线网络流量处理模型上,设置拥塞检测模块,对各个数据包处理线程及其对应子缓冲区的性能进行持续监测;在预定周期内采集各个数据包处理线程及其对应子缓冲区的性能信息,用于计算拥塞检测结果,并根据拥塞检测结果对存在拥塞的数据包处理线程进行标记,具体包括:
59.步骤s21:根据预定的周期,采集各个数据包处理线程及其对应子缓冲区的性能信息,在采集周期内,拥塞检测模块阻塞执行,利用下述公式(1)计算轮询效率
[0060][0061]
其中,为上个周期内所有子缓冲区访问中子缓冲区为空的访问次数,为上个周期内所有子缓冲区访问中子缓冲区不为空的访问次数;直接反映该处理线程在当前负载下的拥塞情况,并间接反映流量是否存在突发;
[0062]
在本发明实施例中执行周期性的性能数据采集,任意两次采集之间间隔时间为duration,将duration设置为5微秒。在间隔时间内,拥塞检测模块阻塞执行,间隔时间结束后,对各项数据进行采集和记录。
[0063]
在本步骤中,所采集的性能数据包括采集时所有子缓冲区的空间占用数以及所有数据包处理线程在上次间隔时间内的轮询效率
[0064]
步骤s22:设置阻塞检测算法如下述公式(2),将轮询效率和数据包处理线程数作为输入,返回拥塞检测结果;
[0065][0066]
其中,thres_count是子缓冲区空间占用数阈值,thres_effiency是轮询效率阈值,
[0067]
为子缓冲区的空间占用数,为轮询效率;
[0068]
当和分别大于相应阈值thres_count和thres_effiency,拥塞检测算法返回true值,认为存在拥塞;反之返回false值,认为不存在拥塞;
[0069]
对于步骤s21中采集到的不同组别的性能数据,分别利用上述公式,并将所有输出为true值的对应线程标识号m和d进行记录。
[0070]
步骤s23:根据步骤s22记录所有处理线程标识号,设置对应的拥塞标记。
[0071]
依据步骤s22中记录的所有处理线程标识号,对处理线程分别进行标记。在本发明实施例中,步骤s13中设置的数据包处理模块中,每个线程对应拥有一个独占的拥塞标记,该拥塞标记存在三种状态,分别为正常,拥塞和等待。该模块依据记录的所有标识号依次确定对应的处理线程,设置对应的标记为拥塞。
[0072]
在本发明实施例中,拥塞标记已经设置为拥塞或等待的处理线程在步骤s2中对其则不再执行性能信息采集、拥塞检测和处理线程标记。
[0073]
如图5所示,在一个实施例中,上述步骤s3:对标记为拥塞的数据包处理线程进行网络流量短期测量,对接收到的数据包进行采样分析,获取线程流量环境信息,并发送给网络流映射调节模块,具体包括:
[0074]
步骤s31:数据包处理线程执行指定的数据包处理流程,同时对相应的拥塞标记进行持续检测,如有拥塞,则开启采样阶段,对期间内该线程接收的网络流标识及其产生的计算负载进行记录;
[0075]
在本发明实施例中,采样窗口规定为处理2048个网络数据包,对于任意一个数据包提取其标识信息并使用该信息唯一确定从属的网络流,即拥有相同标识信息的数据包属于同一条网络流。采样开始时,设置一个空的哈希表,哈希表中包含多个哈希表项,存储键值对{key
h
,value
h
},其中key
h
是数据包标识信息,value
h
是采样窗口中标识信息与该键值相同的数据包数量,用于描述对应网络流的造成的负载。
[0076]
步骤s32:采样阶段结束后,按照计算负载从多到少对记录的网络流标识进行排序,将网络流标识和计算负载作为拥塞状态下的流量环境信息;
[0077]
采样阶段结束后,对记录的网络流按照计算负载从大到小进行排序,作为采样窗口内线程接收的流量环境信息。在本发明实施例中,使用快速排序算法对键值对{key
h
,value
h
}进行排序,最终获得排序处理结果{key1,value1,key2,value2,...,key
h
,value
h
,...,key
h
,value
h
},使得对于任意两个数据包数量信息和若h 1
<h2,则
[0078]
步骤s33:将流量环境信息发送至网络流映射调节模块,并等待该模块的响应信息;在等待响应期间,对应线程继续执行数据包处理流程,设置拥塞标记为等待状态,并阻
止拥塞检测模块对其进行设置;
[0079]
将步骤s32中记录的流量环境信息传递至网络流映射调节模块,并且在相应调度决策生成前设置该线程为等待状态。在本发明实施例中,网络流映射调节模块功能为指定流映射调节决策,与数据包处理线程通过队列传递信息,队列中保存指向内存中流量环境信息的指针。执行流量环境信息传递流程前,设置拥塞标记为等待;如果由于队列已满等导致信息传递失败,代表一定无后续响应,设置拥塞标记为正常。
[0080]
步骤s34:接收到网络流映射调节模块的响应信息后,数据包处理线程清除拥塞标记,并重复执行步骤s31~s33。
[0081]
在信息传递成功后,数据包处理线程继续执行原有数据包处理流程,并同时等待响应信息,并且在接收到响应信息后结束等待状态,之后重复执行步骤s31~s33。在本发明实施例中,线程接收到响应信息后,清除拥塞标记并将其标记为正常。
[0082]
如图6所示,在一个实施例中,上述步骤s4:设置网络流映射调节模块,接收流量环境信息,并针对该信息和当前时刻流量处理性能信息生成额外网络流映射规则,并应用至子缓冲区映射策略中,具体包括:
[0083]
步骤s41:根据流量环境信息以及处理线程性能数据,构建流映射调节决策{no
old
,no
new
,id},其中,no
old
为原线程标识{m,d},no
new
为新的线程标识{m,d'},id为需要额外调度的数据包标识信息{sip,dip,sport,dport,prot};
[0084]
本模块将步骤s33中的流量环境信息设置信息传递队列,队列中保存指向内存中流量环境信息的指针,并在模块运行开始后对该队列进行循环访问。如果队列为空,则不执行任何处理并再次访问;如果队列不为空,则取出其中第一条流量环境信息{no,info1,info2,...,info
i
,...,info
i
},其中no为发送该信息的原处理线程的标识号,其详细标识{m,d},info
i
为采集中获得的任意一条网络流信息,其包含数据{id
i
,packets
i
,packets_total
i
}。在上述网络流信息中,id
i
为需要额外调度的数据包标识信息{sip
i
,dip
i
,sport
i
,dport
i
,prot
i
},其定义与步骤s31中相同;packets
i
为采样窗口内该网络流的数据包数量;packets_total
i
为采样窗口内采样的所有数据包数量。
[0085]
接收信息后,由计算负载从多到少对信息中包含的网络流进行遍历,并为其挑选新的处理线程。在本发明实施例中,生成流映射调节决策时,以packets
i
从大到小,对所有info
i
进行排序。
[0086]
排序完成后,依次对各个网络流进行处理,选择调度后不会引起拥塞的新线程。对任意一个网络流信息info
i
,在本发明实施例中,处理时首先计算网络流在原本线程中的计算负载占比,其计算公式(3)如下所示:
[0087][0088]
计算完成后,根据no={m,d}读取原处理线程的子缓冲区负载,即步骤s22中的子缓冲区的空间占用数并计算该网络流的计算负载,其计算公式(4)如下所示:
[0089]
[0090]
依据上述结果count_flow
i
,访问属于同一组的所有其他线程即d'∈d且d'≠d,获取其子缓冲区的空间占用数,按照如下公式(5)进行计算:
[0091][0092]
其中,max_count是子缓冲区最大空间数。
[0093]
如果计算结果will_congest为true,则代表该网络流调度到新线程后会引起新的阻塞,不符合调度要求;反之如果will_congest为false,则代表该网络流调度到新线程后不会引起新的阻塞,符合调度要求。在本发明实施例中,如果网络流信息info
i
能够寻找到其他线程中的任意一个使will_congest为false,则认为找到新的处理线程,并停止遍历,记录新的线程标识{m,d'}和当前选择的网络流信息info
i
,并生成待应用流映射调节决策{no
old
,no
new
,id},其中no
old
和id分别是记录info
i
中包含的no和id数据,no
new
为记录的新的线程标识{m,d'}。如果对于所有其他线程will_congest计算结果均为true,则按照排序后的结果选择下一个网络流信息进行计算。如果对于所有网络流信息,均不能找到新的处理线程,则认为无法调度,跳转至步骤s45。
[0094]
步骤s42:依据流映射调节决策,对步骤s12中设置的子缓冲区映射策略进行修改,将id作为键值,重新进行查询获得no
new
;
[0095]
在本发明实施例中,应用决策{no
old
,no
new
,id}时,修改子缓冲区映射策略中的额外映射策略,具体地说,采取读写锁同步的方式修改步骤s12中哈希表的键值对{key
h
,value
h
}映射,使得以上述应用决策中的id作为键值,查询获得的值value
h
等于no
new
。
[0096]
步骤s43:分配临时缓冲区并与数据流进行绑定,在数据流已经进入子缓冲区的数据包全部处理完成前,对符合该映射规则的数据包进行暂时存储;
[0097]
基于步骤s42中应用的映射规则,分配临时缓冲区并与之绑定,在该网络流已经进入子缓冲区的数据包全部处理完成前,对符合该映射规则的数据包进行暂时存储。
[0098]
在本实发明施例中,所分配的缓冲区为一段连续的固定长度内存空间,其数据结构表现为队列,经由步骤s42中映射的数据包会将其内存指针存入该队列,而非存入子缓冲区。如果队列已满,则继续申请同等大小的内存空间,继续执行上述操作。
[0099]
步骤s44:依据步骤s42中的no
old
,访问其对应的处理线程,在该线程将剩余的标识信息为id的数据包处理完成后,释放临时缓冲区,并将其中的数据包依次放入标识信息为no
new
的子缓冲区;
[0100]
在本发明实施例中,在缓冲区分配完成后,依据标识信息id访问处理线程和子缓冲区,对访问时子缓冲区中存储的数据包指针数量count进行记录,并在处理线程中设置一次性触发器。在该线程处理完count个网络数据包后,触发器引发对应流程,将步骤s43中临时缓冲区中的数据包按照放入的顺序,依次放入映射规则指定的子缓冲区中。同时,对放入的子缓冲区中存访的数据包指针数量进行检测,如果子缓冲区已满,则暂停放入。在临时缓冲区清空后,释放其占用的内存空间。
[0101]
在本发明实施例中,设置完触发器后,直接跳转至步骤s45。
[0102]
步骤s45:重复执行步骤s41~s44。
[0103]
图7展示了本发明提供的一种基于多核处理器的分组突发负载均衡方法的流程示意图。
[0104]
图8为某校园数据中心流量环境下rss和本发明提供的方法下不同线程中数据包自接收到处理完成的时延比较的结果,可以看出本发明提供的方法有着更好的负载均衡效果。
[0105]
本发明提供的方法实现了对网络流量拥塞的快速检测,在微秒级别对其进行响应,能够实现对更小时间范围内流量突发的识别与处理。同时,本发明提供的方法实现了网络流在线程间的动态调度,提高了对多线程模型计算能力的利用率,减少了网络流量突发对处理性能的影响。此外,本发明提供的方法通过采样的方式确定引起拥塞的网络流,避免了持续性流量统计所带来的性能消耗。本发明提供的方法实现了网络流动态调度过程中的数据包保序,避免上层应用对接收到的数据包进行重排序,在保证计算结果正确的前提下降低了上层应用的实现难度。
[0106]
实施例二
[0107]
如图9所示,本发明实施例提供了一种基于多核处理器的分组突发负载均衡系统,包括下述模块:
[0108]
构建多阶段流水线网络流量处理模型模块51,用于建立多阶段流水线网络流量处理模型,包括:数据包接收分类模块、数据包缓冲模块和数据包处理模块;其中,数据包接收分类模块包含多个线程以及多个数据包分类规则;数据包缓冲模块包含多个缓冲区域,每个缓冲区域包含多个子缓冲区,其中缓冲区域个数与分类规则个数相同;数据包处理模块包含多个上层处理应用,每个上层处理应用对应一组数据包处理线程,其中数据包处理线程与子缓冲区一一对应;
[0109]
拥塞检测模块52,用于在多阶段流水线网络流量处理模型上,设置拥塞检测模块,对各个数据包处理线程及其对应子缓冲区的性能进行持续监测;在预定周期内采集各个数据包处理线程及其对应子缓冲区的性能信息,用于计算拥塞检测结果,并根据拥塞检测结果对存在拥塞的数据包处理线程进行标记;
[0110]
生成线程流量环境信息模块53,用于对标记为拥塞的数据包处理线程进行网络流量短期测量,对接收到的数据包进行采样分析,生成线程流量环境信息,并发送给网络流映射调节模块;
[0111]
网络流映射调节模块54,用于设置网络流映射调节模块,接收流量环境信息,并针对该信息和当前时刻流量处理性能信息生成额外网络流映射规则,并应用至子缓冲区映射策略中。
[0112]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。