一种利用mpi的numpy优化方法及系统
技术领域
1.本发明涉及计算机并行计算技术领域,更具体地,涉及一种利用mpi的numpy优化方法及系统。
背景技术:
2.numpy(numerical python)是python语言的一个矩阵及多维数组计算库。它使用c实现各算法中的核心计算部分,使得它的运行效率可以达到编译语言的水平。它还可以通过连接blas(basic linear algebra subprograms,基础线性代数子程序库)与lapack(linear algebra package,线性数学库)以进一步提升线性代数运算的性能。numpy的常用领域包括科学计算、机器学习、数据分析、数据可视化等,而这些领域对性能的需求日渐提高,numpy是一个串行计算的计算库,并行计算是提升numpy性能的一种有效思路。
3.目前应用于提升numpy性能的方法有cupy框架、gain框架和dask框架。其中,cupy是利用nvidia公司的cuda(compute unified device architecture)架构实现利用gpu对numpy加速的框架,这个框架利用了gpu在矩阵计算时的性能优势,在高吞吐量的场景下获得了良好的性能。不过此框架并未对多核心cpu进行针对性优化,在沒有nvidia的gpu的情况下并不能获得良好的加速,使用的硬件受到较大的限制。
4.gain是一个基于以c实现的分布式数组计算框架global arrays。由于global arrays是针对通用的c数组进行设计的,额外的多层抽象为gain带来了大量的额外开销,使得其性能并不理想。
5.dask是一个使用master/worker架构对数据进行并行处理的计算框架,其中提供了一组与numpy基本一致的api(application programming interface,应用程序接口),它主要针对的是数据量比內存空间还要大的应用场景。它在计算节点间只能通过tcp协议(transmission control protocol,传输控制协议)进行数据交换,使得跨节点的数据访问延迟较高。它使用的master/worker架构虽然为应用带来了更好的可用性,但也会带来不少的额外开销,而且它并沒有对numpy实现完整的兼容。
技术实现要素:
6.本发明为克服上述现有技术中numpy在集群和多核计算环境下的性能不理想、兼容性差的缺陷,提供一种利用mpi的numpy优化方法,以及一种利用mpi的numpy优化系统。
7.为解决上述技术问题,本发明的技术方案如下:
8.一种利用mpi的numpy优化方法,包括以下步骤:
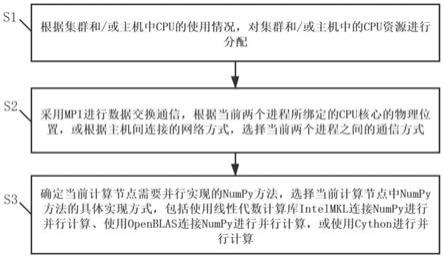
9.s1:根据集群和/或主机中cpu的使用情况,对集群和/或主机中的cpu资源进行分配;
10.s2:采用mpi进行数据交换通信,根据当前两个进程所绑定的cpu核心的物理位置,或根据主机间连接的网络方式,选择当前两个进程之间的通信方式;
11.s3:确定当前计算节点需要并行实现的numpy方法,选择当前计算节点中numpy方
法的具体实现方式,包括使用线性代数计算库intelmkl连接numpy进行并行计算、使用openblas连接numpy进行并行计算,或使用cython进行并行计算。
12.作为优选方案,所述s1步骤中,对集群和/或主机中的cpu资源进行分配的具体步骤包括:
13.获取集群和/或主机中cpu的使用情况,在保持使用的numa节点数最少的条件下优先选择相对空闲的cpu核心,并将待运行计算的进程绑定在所述相对空闲的cpu核心上。
14.作为优选方案,所述进程间的通信方式包括共享内存、rdma、socket中的一种。
15.作为优选方案,所述s2步骤中,选择当前两个进程之间的通信方式的具体步骤包括:
16.获取当前两个进程所绑定的cpu核心的物理位置,判断当前两个进程所绑定的cpu核心是否在同一计算节点:
17.若是,则使用共享内存作为通信方式;
18.否则进一步判断当前两个进程所绑定的cpu核心所在的两个计算节点间是否使用infiniband连接:若是,则使用rdma作为通信方式,否则使用socket利用tcp协议作为通信方式。
19.作为优选方案,所述s3步骤中,其具体步骤包括:
20.s3.1:确定当前计算节点需要并行实现的numpy方法;
21.s3.2:判断所述numpy方法是否能基于原生numpy方法利用划分数据进行有效并行,若是,则执行s3.3步骤;否则使用cython进行并行计算;
22.s3.3:判断当前集群和/或主机使用的处理器是否支持线性代数计算库intelmkl,若是,则选择使用线性代数计算库intelmkl连接numpy进行并行计算;否则使用openblas连接numpy进行并行计算。
23.作为优选方案,所述s3步骤中,还包括以下步骤:判断当前集群和/或主机使用的处理器所使用的指令集是否为arm架构,若是,则使用arm架构中的neon指令集对代码的编译进行优化。
24.作为优选方案,采用mpi进行数据交换通信时,采用数据结构形式将多维矩阵数据存储在集群和/或主机的内存中。
25.作为优选方案,所述数据结构形式包括分布式多维数组数据结构。
26.作为优选方案,采用mpi进行数据交换通信时,使用mpi4py库进行数据交换时的数据序列化。
27.本发明还提出了一种利用mpi的numpy优化系统,应用于上述任一技术方案提出的利用mpi的numpy优化方法,其具体包括:
28.cpu核心分配模块,用于根据集群和/或主机中cpu的使用情况,对集群和/或主机中的cpu资源进行分配;
29.进程通信方式判定模块,用于选择当前两个进程之间的通信方式;
30.底层计算实现选择模块,用于选择程序中函数的具体实现方式,包括使用线性代数计算库intelmkl连接numpy进行并行计算、使用openblas连接numpy进行并行计算,或使用cython进行并行计算。
31.与现有技术相比,本发明技术方案的有益效果是:本发明对集群、主机中的cpu资
源进行分配,有效提升numpy性能;以mpi作为数据通信的实现,提供了一个对现有numpy程序良好兼容,高性能的numpy并行版本的实现方式;对进程通信方式、底层计算方式进行选择,能够进一步提高numpy在集群和多核计算环境下的性能,同时能够实现有效且完整的兼容。
附图说明
32.图1为利用mpi的numpy优化方法的流程图。
33.图2为进程间通信方式选择流程示意图。
34.图3为底层计算实现选择流程示意图。
具体实施方式
35.附图仅用于示例性说明,不能理解为对本专利的限制;
36.为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
37.对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
38.下面先对本发明实施例中所用到的缩略语和关键术语做一个简要的说明:
39.mpi(message passing interface):一个常用在非共享內存环境的并行计算应用程序接口,提供了点对点通信和广播等一些可以实现数据交換的函数。除了以tcp协议提供计算节点间的数据交換,它还支持在infiniband上实现的rdma(remote direct memory access)技术,以进一步提升并行计算的效率。
40.numa(non
‑
uniform memory access):一种为多处理器的电脑设计的内存架构,在这种架构之中,cpu核心访问不同物理內存的时间并不是相等的。cpu核心访问自己的本地內存比非本地內存(对于另一个cpu核心来说可能是本地的)要更快。
41.cython:一种结合了c和python的语言,可以在python语言编写的程序內加上变量和函数的类型,并且编译成动态库再供python调用。因为变量类型已知而且需要编译提供了很多优化的空间,所以良好的cython程序性能可以与c编写的程序相当。
42.openblas:blas(basic linear algebra subprograms)和lapack(linear algebra package)的一个综合开源实现,在线性代数计算上有良好的性能表现。其中blas和lapack是两个线性代数计算应用程序接口标准。
43.intel mkl(intel math kernel library):与openblas类似,区別是它是intel公司实现的版本,针对了intel cpu进行优化。
44.arm(advanced risc machine):一种由arm公司设计的精简指令集处理器架构,被广泛应用在嵌入式系统、移动装置等领域,由于其低功耗的特性,近年在超级计算领域也被视作一种高效的选择。
45.simd(single instruction multiple data):单指令多数据流,是一种处理器利用一个控制器及多个处理微元对一组数据(或称为向量)作出相同操作的技术。
46.neon:arm架构当中的一个结合了64位和128位的simd指令集,可以对向量计算进行加速,支持8,16,32和64位整数及单精度浮点数的计算,最高可同时进行16个计算。
47.infiniband:一个用于高性能计算的计算机网络通信标准,具有极高的吞吐量和极低的延迟,是一种超级电脑和高性能计算集群常用的技术,传输速率可达100gbps。
48.rdma(remote direct memory access):远程直接数据存取,是一种跨节点数据通信技术,它可以绕过远端主机的操作系统直接存取它內存中的数据,由于不经过操作系统,节省了大量cpu资源的同时可以大大提高数据吞吐量以及降低存取延迟。infiniband支持这一技术。
49.tcp(transmission control protocol):传输控制协议,一种面向连接、可靠的、基于字节流的传输层通信协议,因为连接机制及确保可靠性的机制会帶来额外开销,所以吞吐量相对较infiniband低,延迟也相对较高。
50.下面结合附图和实施例对本发明的技术方案做进一步的说明。
51.实施例1
52.本实施例提出一种利用mpi的numpy优化方法,如图1所示,为本实施例的利用mpi的numpy优化方法的流程图。
53.本实施例提出的利用mpi的numpy优化方法中,包括以下步骤:
54.s1:根据集群和/或主机中cpu的使用情况,对集群和/或主机中的cpu资源进行分配。
55.进一步的,对集群和/或主机中的cpu资源进行分配的具体步骤包括:
56.获取集群和/或主机中cpu的使用情况,在保持使用的numa节点数最少的条件下优先选择相对空闲的cpu核心,并将待运行计算的进程绑定在所述相对空闲的cpu核心上。
57.考虑到使用numa架构的cpu集群,其在numa架构中因为cpu存取非本地内存时性能会下降,本实施例中采用对集群和/或主机中的cpu资源进行分配,有效提升numpy性能。
58.s2:采用mpi进行数据交换通信,根据当前两个进程所绑定的cpu核心的物理位置,或根据主机间连接的网络方式,选择当前两个进程之间的通信方式。
59.进一步的,进程间的通信方式包括共享内存、rdma、socket中的一种。
60.其中,共享内存通信方式的数据吞吐量最大,rdma次之,socket最小;共享内存通信方式的访问延迟最低,rdma次之,socket最高。因此在本实施例中,当进程所绑定的cpu核心同在一台主机內时应选择使用共享內存的方式,否则在主机间连接的网络方式为infiniband的时候应使用rdma,其他情况则使用socket利用tcp协议作为进程间的通信方式。如图2所示,为本实施例的进程间通信方式选择流程示意图。
61.本实施例中选择当前两个进程之间的通信方式的具体步骤包括:
62.获取当前两个进程所绑定的cpu核心的物理位置,判断当前两个进程所绑定的cpu核心是否在同一计算节点:
63.若是,则使用共享内存作为通信方式;
64.否则进一步判断当前两个进程所绑定的cpu核心所在的两个计算节点间是否使用infiniband连接:若是,则使用rdma作为通信方式,否则使用socket利用tcp协议作为通信方式。
65.s3:确定当前计算节点需要并行实现的numpy方法,选择当前计算节点中numpy方法的具体实现方式,包括使用线性代数计算库intelmkl连接numpy进行并行计算、使用openblas连接numpy进行并行计算,或使用cython进行并行计算。
66.进一步的,考虑到原生numpy具有优秀的性能,应优先考虑基于numpy的函数利用数据划分等方式进行并行计算。在可以使用numpy函数作为实现基础的情况下,若使用的硬件为intel cpu时,应使用intel经过深度优化的线性代数计算库intel mkl,否则使用openblas连接到numpy,它们对于线性代数计算的深度优化可以使程序获得更好的性能。在不能基于numpy的函数实现的情况下,由于使用python代码实现一般情况下性能并不理想,这时应使用cython进行代码的改造实现,以编译成动态库再使用python代码加载的方式获得更好的性能同时保持良好的兼容性。
67.如图3所示,为本实施例的底层计算实现选择流程。其具体步骤如下:
68.s3.1:确定当前计算节点需要并行实现的numpy方法;
69.s3.2:判断所述numpy方法是否能基于原生numpy方法利用划分数据进行有效并行,若是,则执行s3.3步骤;否则使用cython进行并行计算;
70.s3.3:判断当前集群和/或主机使用的处理器是否支持线性代数计算库intelmkl,若是,则选择使用线性代数计算库intelmkl连接numpy进行并行计算;否则使用openblas连接numpy进行并行计算。
71.进一步的,判断当前集群和/或主机使用的处理器所使用的指令集是否为arm架构,若是,则利用arm架构中的simd指令集neon对代码进行优化,使其在arm平台架构上能够提供更好的性能。
72.进一步的,本实施例采用mpi进行数据交换通信时,使用mpi4py库进行数据交换时的数据序列化,由于进程中的核心代码使用c实现,使用mpi4py库进行数据交换对numpy中的基本数据结构ndarray有针对性的优化,能够进一步提高数据交换的效率。
73.进一步的,本实施例在采用mpi进行数据交换通信时,采用分布式多维数组数据结构将多维矩阵数据存储在集群和/或主机的内存中。
74.本实施例采用的分布式多维矩阵数据结构形式为一个二维的4*4的矩阵,其表达公式如下:
[0075][0076]
分布式多维矩阵数据结构中各成员变量的解释如下表所示:
[0077]
成员变量描述进程0进程1dtype数组元素的类型int64int64ndim数组的维数22shape数组的形状(每维的长度)(4,4)(4,4)teardim分割的维度00low每维的起始索引(0,0)(2,0)high每维的结束索引(2,4)(4,4)avail_nprocs在这个数组上使用的cpu核心数量22array本地数组第1
‑
2行第3
‑
4行
[0078]
其中,dtype为多维矩阵当中元素的数据类型,与numpy相同,支持int32、int64、float32、float64等类型,这个值在不同进程中应相同,本实施例中为int64。
[0079]
ndim为多维矩阵的维数,这个值在不同进程中应相同,本实施例中为二维矩阵,所以ndim值为2。
[0080]
shape定义与numpy中相同,为多维矩阵的形状,即矩阵每维的长度,这个值在不同进程中应相同。本实施例中为4*4的二维矩阵,所以shape的值为长度为2的tuple(4,4)。
[0081]
teardim为分割的维度,这个值在不同进程中应相同。本实施例中以行进行划分,每个进程存储矩阵中的2行,所以分割维度为第0维,值为0。
[0082]
low和high为每维的起始和结束索引,描述了每个进程当中所存储的是整个矩阵当中的哪些部分,这个值应为一个长度为ndim的tuple,在不同进程的值应不同。本实施例中进程0存储了矩阵的[0,2)行的[0,4)列,所以low和high的值为(0,0)和(2,4),进程1同理。
[0083]
avail_nprocs为此分布式矩阵所使用的进程/cpu核心数量,这个值在不同进程中应相同,本实施例中使用的进程数为2,所以avail_nprocs值为2。
[0084]
array为每个进程当中实际存储的矩阵数据,为确保性能和兼容性,使用一个numpy的ndarray作为存储的数据结构。本实施例中进程0的此值为一个2*4的ndarray,即图中红色的部分。同理进程1中此值为图中蓝色的部分。
[0085]
利用上述分布式多维数组数据结构,可以高效地对numpy进行并行实现的同时获得良好的性能。
[0086]
实施例2
[0087]
本实施例提出一种利用mpi的numpy优化系统,应用实施例1提出的一种利用mpi的numpy优化方法。
[0088]
本实施例提出的利用mpi的numpy优化系统中,包括:
[0089]
cpu核心分配模块,用于根据集群和/或主机中cpu的使用情况,对集群和/或主机中的cpu资源进行分配;
[0090]
进程通信方式判定模块,用于选择当前两个进程之间的通信方式;
[0091]
底层计算实现选择模块,用于选择程序中函数的具体实现方式,包括使用线性代数计算库intelmkl连接numpy进行并行计算、使用openblas连接numpy进行并行计算,或使用cython进行并行计算。
[0092]
在具体实施过程中,先通过cpu核心分配模块获取集群和/或主机中cpu的使用情况,在保持使用的numa节点数最少的条件下优先选择相对空闲的cpu核心,并将待运行计算的进程绑定在所述相对空闲的cpu核心上。
[0093]
采用mpi进行数据交换通信,并通过进程通信方式判定模块选择当前两个进程之间的通信方式,具体的,获取当前两个进程所绑定的cpu核心的物理位置,判断当前两个进程所绑定的cpu核心是否在同一计算节点:若是,则使用共享内存作为通信方式;否则进一步判断当前两个进程所绑定的cpu核心所在的两个计算节点间是否使用infiniband连接:若是,则使用rdma作为通信方式,否则使用socket利用tcp协议作为通信方式。
[0094]
通过底层计算实现选择模块选择程序中函数的具体实现方式,具体的,先确定当前计算节点需要并行实现的numpy方法,然后判断所述numpy方法是否能基于原生numpy方
法利用划分数据进行有效并行,若否,则使用cython进行并行计算;若是,则进一步判断当前集群和/或主机使用的处理器是否支持线性代数计算库intelmkl,若是,则选择使用线性代数计算库intelmkl连接numpy进行并行计算;否则使用openblas连接numpy进行并行计算。
[0095]
进一步的,判断当前集群和/或主机使用的处理器所使用的指令集是否为arm架构,若是,则使用arm架构中的neon指令集对代码的编译进行优化。
[0096]
相同或相似的标号对应相同或相似的部件;
[0097]
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
[0098]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

