1.本发明属于利用计算机视觉技术来自动识别电能表用电信息技术领域,特别涉及基于自适应贝塞尔曲线网络的电能表用电信息识别算法。
背景技术:
2.随着我国人工智能技术的不断发展和电力行业的转型与扩张,电能表作为获取用电信息的计量工具,在人们的日常生活中发挥着重要的作用。传统的人工抄表方法比较容易受到外界不稳定因素的影响,因此,快速、准确获得电表用电信息对于电力相关部门信息收集具有时代意义和研究价值。
3.通常,将电表摆放整齐,摄像镜头垂直于表盘平面,通过拍照的方式获取电表用电信息区域的图像。针对电表图像,利用计算机视觉技术进行用电信息检测与识别,可分为两类方法:基于手工图像特征的方法和基于深度学习的方法。前者是先通过手工方式获取图像特征,再对文本信息进行检测和识别的方法,如anis等
1.和zhang等
2.采用改进的二值化算法以及形态学操作,结合电表示数的几何特征定位,然后根据数字的笔画特征进行识别。基于手工设计特征进行检测的方法
[1
‑
2]
在光照充足时具有较高的识别精度,当环境不理想时,识别精度会变差。因此,基于手工设计特征方法不但消耗了大量的人力和时间,并且训练时间比较长,实际检测效果也并不理想。基于深度学习的方法,如laroca等
[3]
以yolo(you only look once你只需看一眼)算法为基础使用轻量级的yolov2
‑
tiny(you only look once version2 tiny你只需看一眼第二版轻量级)网络快速定位电表示数区域,然后分别使用cr
‑
net(character recognition network)
[4]
、卷积循环神经网络(crnn)
[5]
两种识别方法进行数字识别并做了对比实验,cr
‑
net的识别也只到89.5%;龚安等
[6]
在此基础上将网络升级,提出了轻量级的yolov3
‑
tiny(you only look once version3 tiny你只需看一眼第三版轻量级)网络的定位和识别模型,修改nms后计数器识别准确率达到了92.13%;li等
[7]
同样以yolo为基础,采用多阈值软切分方法进行识别,准确率达到了93.61%,比原始yolo算法提高了9个百分点;liu等
[8]
提出了自适应贝塞尔曲线网络(adaptive bezier curve network,abcnet),该网络集检测与识别于一体,检测端结合了残差网络
[9]
和特征金字塔网络
[10]
两种思想,使用贝塞尔曲线拟合文本框;识别端则采用了基于crnn的轻量级识别算法,速度快,检测的准确率达到了93.56%。显然,相比较于传统方法
[1,2]
,深度学习方法
[3
‑
7]
优势明显,不仅可以显著地提升检测速度,还可以提高检测精度。
技术实现要素:
[0004]
本发明的目的是提供基于计算机视觉技术的电能表用电信息识别算法,利用计算机视觉技术来自动识别电能表用电信息,实现电表数据远程获取,在日常生活中具有重要作用。
[0005]
采用的技术方案是:
[0006]
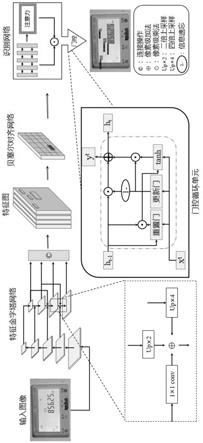
本技术方案提出基于计算机视觉技术的电能表用电信息识别算法。该框架集检
测、识别于一体,实现了端到端的文本定位和预测。首先,检测端结合了特征金字塔网络和残差网络思想,对输入图像进行特征提取,通过四个控制点生成贝塞尔曲线,更好地拟合文本框;然后,识别端采用了基于卷积循环神经网络的文本识别算法,引入门控循环单元替代长短期记忆单元,再结合注意力机制对目标区域文本进行识别;最后,进行五组消融实验,通过实验数据进行性能对比和评估分析。实验结果显示,该算法识别精度高达99.08%,推理速度快,可以运用于用电信息检测与识别的实际应用中。
[0007]
其优点在于:
[0008]
本技术方案基于深度学习算法,针对电能表用电信息的智能检测与识别进行了研究,检测准确率达到了95.28%,识别准确率达到了99.08%。主要贡献如下:
[0009]
(1)在电表信息文本检测方面,为了获得更丰富的全局语义,减轻信息稀释,本技术方案改进了特征提取网络。首先,在上采样过程中,以前两级集成的特征作为输入,使高层的语义信息传递到各个级别的特征映射,与位置信息更好的融合,从而捕获丰富的多尺度上下文信息;最后,将四个特征图以合并多个数组的方式连接起来,合成一个高级特征,这样不仅改善了梯度消失和网络退化问题,而且特征增强网络使该算法具备检测多尺度特征的能力。对比实验结果表明该算法的检测效果在准确率、召回率、和f值三个维度上均有提升。
[0010]
(2)在电表信息文本识别方面,本技术方案提出了基于改进crnn的文本识别算法。首先,为了提升识别精度,本技术方案的矫正网络选用贝塞尔对齐网络,采样网格不再受矩形框的条件限制,将采样点线性索引后进行双线性插值,实现图像矫正和文本对齐。然后,在识别算法中引入门控循环单元(gate recurrent unit,gru)
[12]
,代替长短期记忆(long
‑
short term memory,lstm)网络
[13]
对特征序列进行编码,使用结合注意力机制(attention mechanism)算法
[14]
代替连续时序分类算法(continuous temporal classification,ctc)对特征序列进行解码,得到最终的识别结果。通过消融实验验证了矫正网络可以提升模型性能;gru的引入可以优化模型精度、简化模型复杂度;注意力机制对识别效果有明显提升。
[0011]
(3)本技术方案所提出的网络框架,集检测与识别于一体,实现了端到端的文本定位和预测,网络结构简单、推理速度快、识别精度高,对复杂的背景问题具有抗干扰能力,适合识别在阴暗、强光、灰尘处放置的电表屏幕,对电力相关部门快速准确地收集用户用电信息提供了实用价值,从而解决了传统抄表方法费时费力以及现有识别算法精度不高、实用性不强的问题。
附图说明
[0012]
图1为网络整体结构。
[0013]
图2为骨干网络结构图。
[0014]
图3为用电信息文本框生成的实例结果。
[0015]
图4为改进的crnn模型。
[0016]
图5为双向gru结构。
[0017]
图6为注意力机制示意图。
[0018]
图7为电能表标注案例。
[0019]
图8为可视化结果展示。
具体实施方式
[0020]
电能表用电信息检测与识别是场景文本检测与识别的一个分支。得益于深度学习的快速发展,自然场景下的文字检测与识别技术研究虽然已经相对成熟,但仍是一个开放性研究问题。它主要包含两大模块:文字检测和文字识别。
[0021]
2.1文字检测:
[0022]
文本检测算法可以分为基于回归、基于分割、基于巨大脑神经元(giant cerebral neuron,gcn)和基于混合的四种类型。与一般对象不同,文本通常以具有各种纵横比的不规则形状存在。为了解决这个问题,rrd(rotation regression detection基于旋转的回归检测)
[15]
在ssd(single shot detector单射检测器)
[16]
的基础上重新设定锚框,以适应不规则形状的文本,减少纵横比变化所带来的误差。textboxes (文本框)
[17]
则是把卷积内核和锚框机制进行修改,以便适应各种文本形状的检测。但是复杂的锚框机制,导致这一类算法具有一定的局限性。tian等
[18]
提出的ctpn(connectionist text proposal network连续文本区域网络)是基于回归算法中比较经典的一个,创新之处在于引入垂直锚框机制,将不同尺寸的文本简化成多个固定宽度的候选框,能够检测多尺度多语言的文字,基于回归算法的不足之处在于检测弯曲文本时精度不高;为了解决深度学习算法在耗时和弯曲文本检测精度不高的问题,zhou等
[19]
在2017年提出east(efficient and accurate scene text detector高效精确的场景文本检测器)算法,该算法在速度上取得领先,能直接预测任意形状文本,省去了候选方案、文本区域形成等交互步骤;li等
[20]
提出了基于像素分割的渐进尺度扩展网络,使得该方法可以很好地适用于曲线文本以及距离较近的文本行区分。但基于分割算法容易受到分割精度、内核数量的影响;wang等
[21]
提出了一种新颖的文本检测方法,采用基于频谱的图卷积网络进行深度关系推理,可以适应更复杂情况下的任意形状文本检测,但是该方法的泛化能力不太理想。
[0023]
1.2文字识别:
[0024]
文字识别算法主要有三种类型:第一种是graves等
[22]
提出的连续时序分类算法,它被广泛应用于文本识别领域,主要解决输入序列和输出序列对应的问题,但是在进行去重操作时容易产生误差,把原本相邻的两个相同字符识别成一个。ctc的升级版本gtc(guided training of ctc ctc指导训练)
[23]
,是利用ctc进行监督和引导,然后再ctc分支中加入gcn图卷积神经网络提高模型表达能力,但是前向后向算法的实现很复杂。第二种方法是基于注意力机制算法,attention最早是被vaswani等
[24]
引入到深度学习中的,提供了一种代替传统rnn的新思路。yin等
[25]
在此基础上,提出了融合语句间相互影响的注意力方案;wojna等
[26]
提出了一种基于cnn(convolutional neural network卷积神经网络)、rnn(recurrent neural network循环神经网络)和一种新颖的注意力机制神经网络模型,将其应用于法国街道名称标识数据集
[27]
。基于注意力机制算法的不足之处在于存储需求和计算消耗更大,但是识别的准确率更高。第三种算法是文字识别领域的后起之秀,它提出一个全新的损失函数计算方法:聚合叉(aggregation cross
‑
entropy,ace)
[28]
,就是把每一个时间序列预测的概率进行聚合再归一化,计算简单,节省内存。对比三种算法,基于注意力机制算法可以在耗时和精度上取得平衡。
[0025]
2算法原理:
[0026]
abcnet是一个可以实现端到端可训练的网络框架,不需要预定义锚设置,计算开
销小,主要包含三个模块:主干网络、贝塞尔检测网络和基于注意力机制的识别模块,整体结构框架如图1所示。首先构建50层的残差神经网络作为骨干网络,用特征金字塔网络
[10]
来提取输入的图像特征,然后通过基于贝塞尔曲线检测算法的单阶段无锚(anchor
‑
free)网络
[29]
回归坐标点,通过坐标点的参数信息将电表显示屏中的文字框出,然后通过特征匹配算法,将区域内文字特征进行对齐,最后通过一个轻量级的文字识别模型进行文本识别,并以图像的形式输出最终的可视化结果。
[0027]
2.1骨干网络:
[0028]
本技术方案使用特征金字塔网络来聚合残差网络的2/3/4/5级特征作为主干网络,对文本的位置信息和语义信息进行预测。整个骨干网络结构如图2所示,它由包括五部分:自底而上的五级卷积、自顶而下的上采样过程、1*1卷积核侧向连接、3*3卷积滤波、特征融合。其中,卷积层每进行一级卷积之后,大小变成上一级的1/2,通道数变为2倍;上采样采用最近邻插值法,将特征图尺寸扩大2倍;侧向链接主要是起到改变通道数的作用,以便特征图相加。然后,将每一级的特征图用3*3卷积核进行滤波,减轻上采样过程带来的混叠影响;最后,将所得的特征图以合并多个数组的方式进行融合。因此,最终输出特征图的大小是原始输入图像的1/4,通道数为256。
[0029]
2.2贝塞尔算法相关理论:
[0030]
2.2.1贝塞尔曲线:
[0031]
贝塞尔曲线是由法国数学家bezier研究出的受控制点调整而变化的动态数学曲线
[30]
。它可以用伯恩斯坦多项式
[31]
来表示成一条参数化曲线c(t),其定义公式如下:
[0032][0033]
其中n代表贝塞尔曲线的阶数,b
i
代表第i个控制点,b
i,n
(t)代表伯恩斯坦多项式,其定义公式如下:
[0034][0035]
其中,代表多项式系数,根据经验以及论文验证得知:当n=3时,也就是三阶的贝塞尔曲线,便可以较好地拟合任意形状文本框。在检测电能表用电信息时,可以将边界框简化为一个由(多个,8个以上)8个控制点组成的边界框,8个控制点是指4个标注的顶点以及两条长边上的4个三等分点,然后通过两条长边上的4个控制点分别生成一条贝塞尔曲线,如图3所示。当标注点大于4时,本方法同样适用,可以通过最小二乘法,来获取4个控制点的最优参数组合,实现多边形标注的贝塞尔参数化。
[0036]
2.2.1贝塞尔对齐:
[0037]
自适应贝塞尔曲线网络框架是一个可以实现端到端训练的网络框架。为了达到端到端训练的目的,通常在连接识别网络分支前进行一步预处理操作——将候选文本区域的视觉特征对齐后输出一个新的特征图。特征对齐的目的明确,即找到合适的映射关系,方法也多种多样,比如:感兴趣区域对齐法(region
‑
of
‑
interest align,roi align)
[11]
、感兴
趣区域池化法(region
‑
of
‑
interest pooling,roi pooling)
[32]
和文本对齐采样法(text
‑
align
‑
sampling)
[33]
等。
[0038]
本技术方案构建一个贝塞尔对齐网络(bezier align network,ban),采用的方法是贝塞尔特征匹配法,是感兴趣区域对齐法的进阶版,它的创新之处在于采样网格可以是任意形状,不再受矩形框的条件限制。该对齐方法是根据特征图的像素点位置坐标,利用贝塞尔曲线上、下边界点坐标,将采样点线性索引后进行双线性插值,从而输出一个统一尺寸大小的矩形特征图,作为后续文字识别分支的基础。以像素点位置坐标gi(giw,gih)为例,通过比例公式(3)和线性索引公式(4)计算:
[0039][0040][0041]
其中,h
out
×
w
out
代表输出的矩形特征图的像素大小;t
p
、b
p
分别代表贝塞尔曲线的上、下边界点;o
p
代表采样点。
[0042]
2.3基于crnn的文本识别模块:
[0043]
得益于共享骨干网络和贝塞尔对齐网络的优异表现,识别分支的负担大大减轻了,所以本技术方案选用轻量级的识别网络结构即可。深度学习时代,文本识别通常采用的是卷积循环神经网络,它是一种结合了cnn和rnn的一种全新网络模型。该网络将提取出的图像深度特征,送入循环经网络预测每帧序列的标签分布,然后使用ctc进行解码,将特征序列转化为标签序列。本技术方案在此基础上进行改进,改进的模型结构如图4所示。本技术方案引入门控循环单元代替长短期记忆网络,使用基于注意力机制的解码器代替ctc,这样的改进不仅可以降低网络的复杂度,还可以提升网络的性能表现。
[0044]
2.3.1序列建模:
[0045]
由于经过贝塞尔特征对齐处理后的输出图像已经被调整成统一的高度和宽度,所以在构建卷积特征提取网络时,只选取卷积层、池化层和激活函数的叠加组合,就可以保证能够将输入图像特征比较完整地映射到隐藏层,所以可以舍弃全连接层。最终生成的卷积特征图,可以用于提取特征序列,特征序列的划分标准则是以列为单位,从左至右每一个像素点生成一个特征向量,也就是说特征序列的长就是特征图的列长,特征序列的宽则为固定数值,即一个像素点的大小。
[0046]
假设一共输入t条特征序列,每一条序列理论上都会对应一个标签,所以循环层发挥的主要作用就是对输入的特征序列进行标签标注和标签预测。在本环节中,最常用的算法是反向传播算法,一般采用的激活函数是tanh函数(双曲正切函数)或者logistic函数(逻辑函数(分对数的反函数)),所以在进行反向传播时极易造成梯度消失或者梯度爆炸现象的发生,导致训练时网络的权重参数受到影响。
[0047]
为了解决上述问题,以往的方法中大部分是在rnn的基础上构建一个长短期记忆网络。但是lstm网络结构复杂,参数量巨大,因此本技术方案拟采用的是门控循环单元网
络。
[0048]
gru是循环神经网络的一种,和lstm一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。它主要通过引入重置门(reset gate)和更新门(update gate)来修改循环神经网络中隐藏状态的计算方式。与lstm相比,gru内部少了一个“门控”,参数比lstm少,但能够达到与lstm相当的功能。
[0049]
考虑到单向的gru网络只能通过一个方向来捕捉其上下文的信息,因此使用双向gru从特征序列的两个方向进行序列建模,然后再拼接得到一个更好的特征序列,网络结构如图5所示。这样的特殊设计一举两得,不但能够缓解rnn的梯度消失或者梯度爆炸问题,而且可以捕捉到序列的上下文之间的内部联系。
[0050]
2.3.2解码网络:
[0051]
解码网络是由加入注意力机制的双向gru网络构成,核心思想是将序列建模所得的特征序列转换为字符序列,得到识别的最终结果。
[0052]
注意力机制是一种模仿人类视觉注意力的算法。起初,将注意力机制加入到序列到序列模型(sequence to sequence,seq2seq)
[34]
中用于处理图像中视觉特征对齐和词嵌入。标准的seq2seq模型通常将输入序列编码为固定长度的向量(最后一个为隐藏状态),解码器根据该向量生成输出序列。但是,假设所有必要的信息都在一个向量中进行编码是不合理的。因此,需要让解码器依赖于关注向量,该关注向量是基于输入隐藏状态的加权和,然后作为网络体系结构的一部分,注意力权重同网络一起训练,图6是注意力机制示意图。
[0053]
解码器首先通过注意力机制计算一个注意力向量相关公式如下:
[0054]
e
t,i
=w
t
tanh(ws
t
‑1 vh
i
b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)。
[0055][0056]
其中,w,w,v是可训练的权重值。然后把权重值作为系数,将编码器输出序列的列线性组合成一个向量g
t
:
[0057][0058]
g
t
作为译码器循环单元的输入,产生一个输出向量x
t
和一个新的状态向量s
t
。
[0059]
(x
t
,s
t
)=rnn(s
t
‑1,(g
t
,f(y
t
‑1)))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)。
[0060]
式中(g
t
,f(y
t
‑1))为g
t
与y
t
‑1的one
‑
hot(独热编码)嵌入。rnn表示循环单元gru的阶跃函数,其输出和新的内部状态分别用x
t
和s
t
表示,最后,采用x
t
来预测当前步的字符:
[0061]
p(y
t
)=softmax(w
o
x
t
b
o
)
ꢀꢀꢀꢀꢀꢀ
(10)。
[0062]
y
t
~p(y
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)。
[0063]
这是一种隐式的语义模型,它可以帮助识别之前所学的语义信息。
[0064]
3实验过程及结果分析:
[0065]
为了验证所提出的电表检测与识别模型的有效性,本技术方案在电表数据集上进行了五组消融实验,分别是(1)选取近五年提出的不同的文本检测算法进行对比;(2)探究残差网络的结构和深度对模型的影响;(3)对比不同epoch(时期,一个epoch就是将所有训练样本训练一次的过程)对训练结果的影响;(4)对比文本矫正网络对识别准确度的影响;(5)对比ctc和attn(attention注意力)两种不同机制的识别准确度。
[0066]
3.1数据集:
[0067]
数据集方面,本实验收集并使用labelme标注软件标注2200张coco格式(common objects in context图像识别数据集)的低压场景电表数据集,其中2000张用于训练,剩余的200张用于测试。此外,还采用了数据增强,如随机尺度训练,最小训练尺寸在640像素到896像素之间随机选取,最大训练尺寸小于1600像素;在确保文字部分不被裁剪的情况下进行0.1比例随机尺度裁剪,因此数据集训练具有通用性。
[0068]
电能表标注案例图像如图7所示,左面是标注图像,右面是生成的对应标签。可以看出,针对每一幅电表图像,主要标注四个区域,其中右上角区域的用电时段信息和最下方的用电量数值是电表识别的重点对象。右上角区域的用电时段信息分为峰、平、谷、尖、总五种标签类型,其中“峰、平、谷、尖”表示四个用电时段,“总”代表当前总用电量;最下方的电量数值标签则由数字“0
‑
9”和小数点“.”构成。
[0069]
3.2实验细节:
[0070]
本网络的主干网络是采用了带有fpn(feature pyramid network特征金字塔网络)思想的50层resnet(residual network残差网络)。检测部分,本网络在输入图像的5个不同分辨率的特征图上进行实验;识别部分,本技术方案采用基于改进crnn的文本识别算法,并结合了注意力机制。本网络在一个gtx 2080tigpu显卡上进行训练,训练批次batch size(common objects in context图像识别数据集)为2。初始学习率为0.01,分别在迭代次数为160k和220k时乘以0.1,最大迭代次数为400k,整个训练时长大约为1天。其中k为千。
[0071]
3.3消融实验:
[0072]
3.3.1不同文本检测算法的消融实验:
[0073]
为了增强模型对更复杂情况的鲁棒性,本技术方案选取近五年提出的五种文本检测算法,在尽量保证公平公正的环境下进行对比实验,评价指标分别为准确率、召回率和综合评价指标(f值)。衡量检测效果采用针对任意方向自然场景文本检测提出的icdar 2015(international conference on document analysis and recogition文档分析与识别国际会议)
[35]
方法。表1展示了本技术方案算法和其他算法
[18
‑
21]
的icdar2015比较结果,从表1中可以看出,本技术方案改进后的算法在检测精度上更具有优越性,因此在接下来的实验中,选择该算法对电表信息进行检测定位。
[0074]
表1各算法在icdar2015的检测结果比较
[0075]
算法算法类型准确率/%召回率/%f值/%easthybrid83.2778.3380.72psenetsegmentation87.2685.3786.30drrggcn89.2484.6986.91abcnetregression93.5689.6091.54oursregression95.2890.8693.02
[0076]
其中psenet为progressive scale expansion network渐进尺度扩展网络。
[0077]
hybrid:混合。
[0078]
segmentation:分割
[0079]
drrg:deep relational reasoning graph深度关系推理图。
[0080]
regression:回归。
[0081]
ours:我们的方法,本技术方案的方法。
[0082]
3.3.2残差网络结构和深度对模型的影响:
[0083]
为了避免深度神经网络的梯度消失、梯度爆炸和网络退化的问题,本技术方案选取残差网络作为特征提取的主干网络,残差网络可以分为两类:一类是basicblock(基本块)结构模型,比如resnet18,resnet34;另一类是bottleneck(瓶颈块)结构模型,比如resnet 50,resnet101,resnet152等。本技术方案选取具有代表性的resnet34,resnet50,resnet101三个不同结构和深度的残差网络进行消融实验,具体的实验结果如表2所示,从表中可以看出,resnet50得益于bottleneck结构的特殊性,在参数量和精度之间取得了平衡。
[0084]
表2不同深度的残差网络对比结果
[0085]
骨干网络模型结构准确率/%召回率/%f值/%参数量/
×
106resnet 34basicblock91.3093.7692.5163.47resnet 50bottleneck99.0899.3099.1946.16resnet 101bottleneck99.1299.4599.2885.21
[0086]
3.3.3 epoch对准确率的影响:
[0087]
epoch是深度学习算法的一个重要超参数,数据集完整地训练一次,epoch记为1。epoch数量增加,网络的权重系数更新的次数也会随之增加。为了减少模型的错误率,同时避免过拟合现象的发生,本技术方案在四个不同epoches次数下开展消融实验,训练结果对比如表3所示,在相同的权重衰减作用下,针对本技术方案的电表数据集,模型在epoches=400,iou(intersection over union交并比)大于或等于0.5和0.75两个标准下,训练结果都达到基本稳定。
[0088]
表3 epoch对准确率的影响
[0089][0090][0091]
3.3.4矫正网络的有效性研究:
[0092]
为了验证bezieralign矫正网络在本技术方案所提出的检测识别模型上对识别性能具有提升的作用,分别使用带有ban网络和没有ban网络的模型在数据集上进行消融实验,然后将两个结果进行对比,如表4所示:
[0093]
表4矫正网络有效性的对比结果
[0094]
算法推理速度/fps准确率/%召回率/%f值/%
without ban22.898.0699.1598.60with ban22.599.0899.3099.19
[0095]
根据表4的结果可以看出,经过矫正网络处理的识别算法,在数据集上具有更高的识别准确率,性能更好,且在推理速度方面,并没有引入太多的额外消耗。
[0096]
3.3.5基于不同机制的识别准确度分析:
[0097]
识别分支,本技术方案训练了三个模型,分别验证了使用gru代替lstm、加入注意力机制替换ctc对模型精度、耗时和参数量的影响。实验结果如表5所示,gru和lstm的识别准确率不分伯仲,gru微微领先,且gru模型大幅度减少了参数量,降低了耗时;引入注意力机制后,模型可以更好地获取特征信息,准确率提升了3.33%,在耗时、参数量和精度之间取得了平衡。
[0098]
表5不同机制的识别准确度对比结果
[0099]
骨干网络序列建模识别机制准确率/%耗时/ms/image参数量/
×
106resnet50lstmctc95.6913.252.72resnet50gructc95.759.842.58resnet50gruattention99.0816.546.16
[0100]
3.4实验结果:
[0101]
两种识别算法的可视化结果对比如图8所示,其中左侧为gru ctc算法识别结果,右侧为gru attention算法识别结果。通过三组对比组图分别可以看出,基于attention算法具有以下三点优势:(1)处理相邻的两个相同字符时,attention算法可以避免去重操作所带来的的误差;(2)受拍摄噪声、图片模糊等因素影响时,attention算法可以将电能表用电信息相对准确地检测并识别出来;(3)当表盘污渍导致电能表信息被遮挡时,attention算法识别结果的可信度更高。
[0102]
本技术方案改进了abcnet框架,并将其应用于电能表检测及示数识别。实验表明基于abcnet的文本检测与识别算法,在精度和速度上都有所提升,对电力相关部门快速准确地收集用户用电信息具有应用价值和时代意义。
[0103]
文中人名未翻译。
[0104]
参考文献:
[0105]
[1]anis a,khaliluzzaman m,yakub m,et al.基于水平和垂直二值模式的数字电表读取识别.2017年第三届国际电气信息和通信技术会议,2017:1
–
6。
[0106]
[2]zhang y,yang x,hong t,et al.基于图像轮廓拓扑特征的数字电表识别方法.2019ieee宽带多媒体系统与广播国际研讨会.济州岛,韩国:ieee计算机协会。
[0107]
[3]laroca r,barroso v,diniz ma,et al.自动抄表的卷积神经网络.电子成像杂志,2019,28(1):013023。
[0108]
[4]silva sm,jung cr..基于深度卷积神经网络的巴西车牌实时检测与识别.2017年第30届sibgrapi图形、模式和图像会议.尼泰罗伊,巴西.2017.55
–
62。
[0109]
[5]shi bg,bai x,yao c.基于图像序列识别的端到端可训练神经网络及其在场景文本识别中的应用.ieee模式分析与机器智能汇刊,2017,39(11):2298
–
2304。
[0110]
[6]龚安,张洋,唐永红.基于yolov3网络的电能表示数识别方法.计算机系统应用,2020,29(1):196
–
202。
[0111]
[7]厉建宾,张旭东,吴彬彬.结合深度神经网络和多阈值软切分的电能表示数自动识别方法.计算机应用,2019,39(s1):223
‑
227。
[0112]
[8]liu,yuliang,hao chen,chunhua shen,tong he,lianwen jin,and liangwei wang.2020.基于自适应贝塞尔曲线网络的实时场景文本识别.2020年ieee/cvf计算机视觉与模式识别会议,9809
–
18。
[0113]
[9]he,k.,zhang,x.,ren,s.,&sun,j.(2016).图像识别的深度残差学习.2016年ieee计算机视觉与模式识别会议,770
‑
778。
[0114]
[10]lin,t.,doll
á
r,p.,girshick,r.b.,he,k.,hariharan,b.,&belongie,s.j.(2017).用于目标检测的特征金字塔网络.2017年ieee计算机视觉与模式识别会议,936
‑
944。
[0115]
[11]kaiming he,georgia gkioxari,piotr dollr,and ross girshick.掩码循环卷积神经网络.机器视觉国际会议会刊,2017。
[0116]
[12]dey,r.,&salem,f.(2017).门控循环单元神经网络的变体.2017ieee第60届国际中西部电路与系统研讨会,1597
‑
1600。
[0117]
[13]hochreiter,s.,&schmidhuber,j.(1997).长短期记忆.神经计算,9,1735
‑
1780。
[0118]
[14]fukui,h.,hirakawa,t.,yamashita,t.,&fujiyoshi,h.(2019).注意分支网络:视觉解释注意机制的学习.2019ieee/cvf计算机视觉和模式识别会议,10697
‑
10706。
[0119]
[15]liao,m.,zhu,z.,shi,b.,xia,g.,&bai,x.(2018).面向场景文本检测的旋转敏感回归.2018 ieee/cvf计算机视觉和模式识别会议,5909
‑
5918。
[0120]
[16]liu,w.,anguelov,d.,erhan,d.,szegedy,c.,reed,s.e.,fu,c.,&berg,a.单发多盒检测器.欧洲计算机视觉国际会议,2016。
[0121]
[17]liao,m.,shi,b.,&bai,x.(2018).面向单发场景的文本检测器.ieee图像处理会议,27,3676
‑
3690。
[0122]
[18]tian z,huang w,he t,et al.利用连接文本建议网络检测自然图像中的文本.欧洲计算机视觉会议,2016:56
‑
72。
[0123]
[19]zhou x,yao c,wen h,et al.高效准确的场景文本检测器.ieee国际计算机视觉与模式识别会议2017:2642
‑
2651。
[0124]
[20]li,x.,wang,w.,hou,w.,liu,r.,lu,t.,&yang,j.(2019).基于渐进尺度扩展网络的形状鲁棒文本检测.2019年ieee/cvf计算机视觉与模式识别会议,9328
‑
9337。
[0125]
[21]zhang,s.,zhu,x.,hou,j.,liu,c.,yang,c.,wang,h.,&yin,x.(2020).面向任意形状文本检测的深度关系推理图网络.2020ieee/cvf计算机视觉与模式识别(cvpr),9696
‑
9705。
[0126]
[22]graves,a.,fern
á
ndez,s.,gomez,f.,&schmidhuber,j.(2006).连接时间序列分类:用循环神经网络标记非分段序列数据.第23届机器学习国际会议论文集。
[0127]
[23]hu,w.,cai,x.,hou,j.,yi,s.,&lin,z.(2020).面向高效和准确的场景文本识别的ctc指导训练.arxiv,abs/2002.01276。
[0128]
[24]vaswani,a.,shazeer,n.m.,parmar,n.,uszkoreit,j.,jones,l.,gomez,a.n.,kaiser,l.,&polosukhin,i.(2017).无可或缺的注意力.arxiv,abs/1706.03762。
[0129]
[25]yin,w.,sch
ü
tze,h.,xiang,b.,&zhou,b.(2016).基于注意力的句子对建模卷积神经网络.计算语言学协会汇刊,4,259
‑
272。
[0130]
[26]wojna,z.,gorban,a.n.,lee,d.,murphy,k.,yu,q.,li,y.,&ibarz,j.(2017).基于注意力的街景图像结构化信息提取.2017第14届国际文献分析与识别会议,01,844
‑
850。
[0131]
[27]smith,r.,gu,c.,lee,d.,hu,h.,unnikrishnan,r.,ibarz,j.,arnoud,s.,&lin,s.(2016).法国街道名称标志数据集.arxiv,abs/1702.03970。
[0132]
[28]xie,z.,huang,y.,zhu,y.,jin,l.,liu,y.,&xie,l.(2019).序列识别的聚合交叉熵.2019年ieee/cvf计算机视觉与模式识别会议,6531
‑
6540。
[0133]
[29]tian,z.,shen,c.,chen,h.,&he,t.(2019).全卷积单阶段目标检测.2019ieee/cvf计算机视觉国际会议,9626
‑
9635。
[0134]
[30]liu,y.,chen,h.,shen,c.,he,t.,jin,l.,&wang,l.(2020).基于自适应贝塞尔曲线网络的实时场景文本识别.2020年ieee/cvf计算机视觉与模式识别会议,9806
‑
9815。
[0135]
[31]george g.lorentz.伯恩斯坦多项式.美国数学学会,2013。
[0136]
[32]hui li,peng wang,and chunhua shen.基于卷积循环神经网络的端到端文本识别.机器视觉国际会议会刊,5238
–
5246,2017。
[0137]
[33]tong he,zhi tian,weilin huang,chunhua shen,yu qiao,and changming sun.基于精确对齐和注意力的一种端到端的文本识别器.机器视觉与模式识别国际会议会刊,5020
–
5029,2018。
[0138]
[34]sutskever,i.,vinyals,o.,&le,q.v.利用神经网络进行序列到序列学习.神经信息处理系统进展大会,2014。
[0139]
[35]zhou,x.,zhou,s.,yao,c.,cao,z.,&yin,q.(2015).icdar 2015场景文本识别比赛.arxiv,abs/1506.03184。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

