1.本发明涉及一种面向脑疾病分类的模块化特征选择方法,具体是利用模块化信息作为网络的先验知识来选择特征的一种方法,属于生物医学信息处理技术领域。
背景技术:
2.静息态功能性磁共振成像(rs
‑
fmri)为探索人脑功能提供了非侵入性的方法,并作为理解脑功能组织的重要工具而受到广泛关注。基于这一先进技术,功能脑图分析作为医学图像领域的一个新的研究热点,在识别和分类脑疾病如阿尔茨海默症(ad)及其早期即轻度认知障碍(mci)方面显示出巨大的潜力。
3.在脑图分析的研究当中,选择哪些特征进行分类是一个很有研究意义的问题。在实际在研究中,如图1所示,通常有三种基于不同粒度的特征用于脑疾病的分类:
4.第一种是基于全局性度量的特征(例如,全局聚类系数和全局效率)。这种特征设计起来很简单但是缺乏特异性,也就是说,它不能告诉到底是整个大脑的问题,还是特定节点或边的问题。
5.第二种特征是基于节点度量的特征(例如,局部聚类系数)。这种特征可以在节点级别定位与疾病相关的脑区,但同时它也忽略了边/链接的影响。而且,不同的节点度量倾向于捕获不同的网络属性,这需要额外的技巧或丰富的知识来设计有效的特征。
6.第三种特征是基于边/链接的特征(例如,边的权重)。这种特征不仅设计简单,而且可以自然地定位到功能链接上。在实际的操作中,一般将每一个功能脑图的邻接矩阵的上三角元素的列向量拼接成一个长的功能链接向量,然后将所有被试的功能连接向量组合成一个功能连接聚合矩阵来进行特征选择和分类。尽管基于边的特征设计简单,但是由于被试个数太少,这种高维的特征会导致维数灾难的问题。而且这种将邻接矩阵拼接成向量的操作忽略了模块化等脑图的拓扑结构。
7.实际上,模块化的研究有助于理解大脑的组织原理,在分析中具有重要的理论意义和实用价值。不少研究发现,的功能脑图不仅具有层次模块化组织,而且被试之间具有相当程度的相似性。因此,基于大脑呈现模块化这一事实,提出了一种新的特征选择方法,即基于group lasso的模块化特征选择方法。
技术实现要素:
8.本发明针对现有方法中的不足,提出了一种新的功能脑图特征选择方法方法,所要解决的问题是:利用模块化信息作为网络的先验知识来选择特征,本发明的方法,在准确性、敏感性、特异性、及auc几个指标上均明显优于现有技术,此方法对大脑认知功能研究具有重要的应用价值。
9.为了达到上述目的,本发明在参考了大量实验和方法后采取以下技术方案:
10.一种面向脑疾病分类的模块化特征选择方法,包括以下步骤:
11.步骤一:对采集到的每个被试的大脑功能磁共振图像进行预处理,包括:时间矫
正、头动矫正、空间配准、滤波、平滑操作;在预处理之后选定一种标准化大脑分区模板与预处理后的功能磁共振图像进行匹配,划分图像为若干个大脑区域,每个脑区分别对应大脑功能网络中的一个节点;
12.步骤二:提取所有脑区对应的平均时间序列,计算两两脑区的pearson相关系数,构建大脑功能脑图g(v,e,w),其中v表示网络中m个节点的集合,即大脑区域的集合,e表示边的集合,即脑区之间连接的集合,w∈r
m
×
m
为图的邻接矩阵;
13.步骤三:利用有符号的谱聚类方法找到脑图的模块化信息,具体的算法如下:
14.(1)根据邻接矩阵w构造有符号的度矩阵d;要构造的模块数目k;
15.(2)构造有符号的标准拉普拉斯矩阵l=i
‑
d
‑
1/2
wd
‑
1/2
;
16.(3)计算l的前k小个特征值对应的特征向量u1,...,u
k
;
17.(4)令u=(u1,...,u
k
),将u中的每一行作为一个点,使用k
‑
means 进行聚类,得到模块划分(a1,...,a
k
);
18.步骤四:利用模块化信息重新排列邻接矩阵,使得同一个模块里的节点能够彼此相邻;
19.步骤五:使用具有先验模块化信息的group
‑
lasso选择判别性特征;
20.步骤六:将选择的判别性特征输入到线性svm分类器中得到分类结果。
21.做为对本技术方案的进一步优化:
22.所述的步骤四包括以下具体步骤:
23.(1)对每个被试的邻接矩阵w重新排列,使属于同一个模块的节点彼此相邻;
24.(2)将每一个重排的邻接矩阵的上三角元素的列向量拼接成一个维数为 m(m
‑
1)/2的向量,即功能连接向量;
25.(3)将每个被试的功能连接向量共同组合成一个功能连接聚合矩阵x= [x
w x
b
]∈r
n
×
d
,其中n表示被试的个数,d=d
w
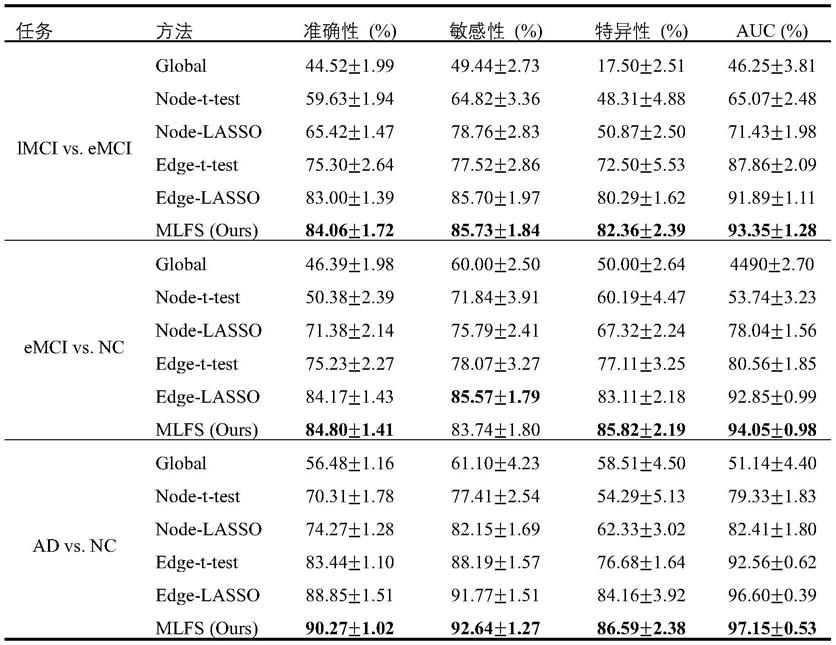
d
b
表示全部的特征数目即边的数目;聚合矩阵x由两部分组成,第一部分是它包含每个模块内部的d
w
条边,把每个模块作为一个特定的组;第二部分是的组;第二部分是它包含k个模块间的d
b
条边,把每条边作为一个单独的组;这样, d个特征可以被分成g=k d
b
个组,每个被试的功能脑图都可以用模块内的特征边和模块间的特征边来表示。
[0026]
所述的面向脑疾病分类的模块化特征选择方法,包括以下步骤:
[0027]
由于x∈r
n
×
d
是针对n个样本的设计矩阵,并且被自然地划分为g个组,定义d
g
为第g(g=1,...,g)个组中的特征个数,y∈r
n
为标签向量,那么,模块化特征选择方法可表述为:
[0028][0029]
其中,λ>0是正则化参数,ω是每个特征的加权系数,它也被分成g个组,ω
g
表示第g个组对应的加权系数;上述式子中的第二项可以生成一个稀疏解,并且使得ω中有些元素被压缩成零,这样有助于选择那些在ω中系数为非零的特征边。
附图说明
[0030]
图1:表示不同粒度的特征度量(分别是基于全局的度量、基于节点的度量和基于
边的度量)。
[0031]
图2:表示脑疾病分类的基本框架,包括四个主要部分:(a)数据预处理;(b)脑图构建;(c)基于mlfs的特征选择;(d)基于支持向量机(svm)的分类。
[0032]
图3:表示基于mlfs特征选择方法的框架,包括三个主要部分:(a)基于有符号谱聚类的模块结构提取;(b)根据提取的模块结构进行邻接矩阵重排; (c)基于group lasso的特征选择。
具体实施方式
[0033]
为了加深对本发明的理解,下面将结合附图和实施例对本发明做进一步详细描述,该实施例仅用于解释本发明,并不对本发明的保护范围构成限定。
[0034]
如图2和图3所示,一种面向脑疾病分类的模块化特征选择方法,步骤如下:
[0035]
1.数据获取与数据预处理:在实例中,使用来自阿尔茨海默病神经成像倡议(adni)数据库的一个数据集,共对174名被试(48名正常对照(ncs)、95 名mci和31名ad)进行了563次扫描,值得注意的是,本研究的被试是一次或多次扫描,间隔至少半年,因此这563次扫描可分为nc 154例、mci 310 例(emci 165例、lmci 145例)和ad 99例,然后,对所有研究对象的rs
‑
fmri 扫描都使用fsl feat软件通过标准程序进行预处理,包括时间层校正,头动校正,带通滤波,以及有害协变量(即白质、脑脊液和运动参数)的回归,带通滤波在[0.015hz,0.15hz]的频率区间内进行,在所有预处理之后,选定一种标准化大脑分区模板,采用可变形配准方法与预处理后的核磁图像进行匹配,将图像划分为m个大脑区域,每个脑区分别对应脑功能网络中的一个节点,在本实例中,将人脑依据aal(anatomical automatic labeling)模板划分为116个脑区,116个脑区分别表示大脑功能网络中的116个节点;
[0036]
2.脑图构建:提取所有脑区对应的平均时间序列,计算两两脑区的pearson 相关系数,构建大脑功能脑图g(v,e,w),其中v表示网络中m个节点的集合(即大脑区域的集合),e表示边的集合(即脑区之间连接的集合),w∈r
m
×
m
为图的邻接矩阵;
[0037]
3.提取模块化信息:利用有符号的谱聚类找到脑图的模块化信息,具体来说,首先将所有被试的邻接矩阵做平均,得到统一的邻接矩阵w,然后使用有符号谱聚类将脑图聚成预先指定数量的模块,使每个模块内包含权值较大的正边和较少的负边,定义任意节点i,j∈v(i,j=1,...,m),节点i的符号度定义为:
[0038][0039]
其中w
ij
∈w是两个边的权重,那么有符号的度矩阵可以表示为:
[0040]
d=diag(d1,...,d
m
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0041]
因此,有符号的规范化拉普拉斯矩阵定义如下:
[0042]
l=i
‑
d
‑
1/2
wd
‑
1/2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0043]
将v划分为k个模块(a1,...,a
k
),那么有符号的标准割sncut的定义如下:
[0044][0045]
其中,x
k
是a
k
的一个指示向量,它包含着模块划分的信息,最小化上面的目标函数
相当于求解一个广义特征值方程,具体的有符号谱聚类算法如下所示:
[0046]
(1)根据邻接矩阵w构造有符号的度矩阵d;要构造的模块数目k;
[0047]
(2)构造有符号的标准拉普拉斯矩阵l=i
‑
d
‑
1/2
wd
‑
1/2
;
[0048]
(3)计算l的前k小个特征值对应的特征向量u1,...,u
k
;
[0049]
(4)令u=(u1,...,u
k
),将u中的每一行作为一个点,使用k
‑
means 进行聚类,得到模块划分(a1,...,a
k
)。
[0050]
4.邻接矩阵重排:在找到的模块信息之后,需要对每个被试的邻接矩阵w 重新排列,使属于同一个模块的节点彼此相邻(如图3中步骤b所示),然后,将重排的邻接矩阵拉成一行向量来表示每个被试,并且将所有的被试堆叠形成一个聚合矩阵x=[x
w x
b
]∈r
n
×
d
,其中n表示被试的个数,d=d
w
d
b
表示全部的特征数目(即边的数目),聚合矩阵x由两部分组成,第一部分是它包含每个模块内部的d
w
条边,把每个模块作为一个特定的组;第二部分是它包含k个模块间的d
b
条边,把每条边作为一个单独的组。这样,d个特征可以被分成g=k d
b
个组,每个被试的功能脑图都可以用模块内的特征边和模块间的特征边来表示;
[0051]
5.模块化特征选择:为了选择具有判别性的模块和边,采用group lasso 特征选择方法,如前所述,x∈r
n
×
d
是针对n个样本的设计矩阵,并且被自然地划分为g个组,定义d
g
为第g(g=1,...,g)个组中的特征个数,y∈ r
n
为标签向量,那么,提出的模块化特征选择方法可表述为:
[0052][0053]
其中,λ>0是正则化参数,ω是每个特征的加权系数,它也被分成g个组(ω
g
表示第g个组对应的加权系数),公式(5)中的第二项可以生成一个稀疏解,并且使得ω中有些元素被压缩成零,这样有助于选择那些在ω中系数为非零的特征(边),通过这种方式,提取具有判别性的模块和边用于后续的疾病分类任务,另外,可以使用slep工具箱求解上述目标函数;
[0054]
6.svm分类:使用带有默认参数(即c=1)的线性svm进行ad/mci识别和mci转换预测是基于以下两点考虑的:(1)实验的主要目的是验证所提出的 mlfs特征选择方法的有效性,然而,考虑到分类框架中不同步骤对最终结果的影响,很难得出脑图构建、特征选择和分类器哪一步对最终精度贡献更大,因此,使用了最简单和最流行的分类方法,(2)对于一些复杂的深度学习方法,如rcnn、brainnetcnn、graphcnn,在没有足够的训练样本(受试者)的情况下,如何调整超参数并训练出好的模型是一个挑战,最近的研究表明,经典的机器学习算法往往比深度神经网络表现更好。
[0055]
对比实验及说明:为了评价所提方法的有效性,从adni公共数据库采集了563张静息状态功能磁共振图像来识别正常被试与ad/mci(任务ad vs. nc和任务emci vs.nc),以及早期mci(emci)到晚期mci(lmci)的转换(任务lmci vs.emci)。对比方法有:
[0056]
(1)global,仅使用一个全局特征进行分类;
[0057]
(2)node
‑
t
‑
test,使用所有的节点特征,再进行t
‑
test(t检验)特征选择后分类;
[0058]
(3)node
‑
lasso,使用所有基于节点的特征,再进行lasso(最小绝对收缩和选择算
子)特征选择后分类;
[0059]
(4)edge
‑
t
‑
test,使用所有基于边的特征,再进行t
‑
test特征选择后分类;
[0060]
(5)edge
‑
lasso,使用所有基于节点的特征,再进行lasso特征选择后分类;
[0061]
(6)mlfs(ours),即本发明的方法。
[0062]
实验结果(均值
±
标准差)包括4个指标:(1)准确性,被正确分类的样本在所有样本中所占的比例;(2)敏感性,被正确分类的病人的比例;(3)特异性,被正确预测的正常人的比例;(4)auc,特征曲线roc曲线下面积 auc。
[0063]
表1:对比实验数据表
[0064][0065]
对比实验说明:如表1实验结果所示,无论在哪个任务下,的方法与以前的方法相比都得到了提高。说明的方法在识别脑疾病方面显示出巨大的潜力,对研究大脑的认知功能障碍具有更准确地参考价值。
[0066]
本发明的优点在于:
[0067]
本发明它利用模块化信息来识别脑图中的判别性特征,用于脑疾病分类。该方法首先通过有符号的谱聚类算法搜索脑图中的模块化结构,然后通过模块化诱导的group lasso方法选择判别性特征,最后使用支持向量机(svm)进行分类。
[0068]
以上所述仅为本发明的较佳实施例,并不用以限制本发明。凡在本发明的精神和原则之内所作的任何修改,等同替换和局部补充,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

