1.本发明涉及聚类分割评价装置、聚类分割评价方法以及聚类分割评价程序。
背景技术:
2.在净水厂中,对从河川等取得的原水注入凝集剂,使包含在原水中的污浊物质凝集。凝集的污浊物质沉淀或被过滤。应注入的凝集剂的量根据表示原水的性质的值(浊度、温度、氢离子浓度等)而变化。因此,需要基于原水的性质来预测应注入的凝集剂的量。近年来,不限于净水厂,使用预测模型来预测社会基础设施的运转计划生成所需的各数值的技术正在普及。而且,为了更准确的预测,对最佳地说明运转计划的目标变量的说明变量进行选择的技术也正在普及。
3.专利文献1的特性值预测装置从说明变量的n个候补中生成1个变量的组合、2个变量的组合、3个变量的组合、
…
、n个变量的组合。这些组合的总数为
n
c1
n
c2
n
c3
…
n
c
n
。该预测装置使用属于各组合的说明变量的实测值以及该时间点的目标变量的实测值,生成预测模型。然后,该预测装置求出预测模型所输出的目标变量的预测值与实测值的差值(误差),将对误差的方差的对数附加了负的符号的值作为“基准值”。该预测装置从说明变量的数量较少的组合起依次计算出基准值。于是,随着说明变量的数量增加,基准值上升。该预测装置将该上升的程度变得比预定的阈值小之前的组合作为用于预测目标变量的说明变量的组合。
4.现有技术文献
5.专利文献
6.专利文献1:日本特开平7
‑
93284号公报
技术实现要素:
7.发明要解决的课题
8.在预测净水厂的凝集剂的注入量的情况下,说明变量大致被固定化为原水的浊度、温度、氢离子浓度等,缺乏选择其中的某一种的动机。相反,对于四季、天气等每个运转条件区分使用预测模型的必要性较大。专利文献1的特性值预测装置用于生成最佳的预测模型,但集中注意于说明变量的选择,欠缺根据运转条件区分使用预测模型的构思。
9.因此,本发明的目的在于,分割变量的多维空间以便能够根据运转条件使用高精度的多个预测模型。
10.用于解决课题的手段
11.本发明的聚类分割评价装置的特征在于,具备:实测值取得部,其取得表示净水厂所取得的原水的性质的值的实测值、以及表示注入到原水的药剂的量的值的实测值;聚类部,其在多维空间内,将对表示原水的性质的值的实测值以及表示注入到原水的药剂的量的值的实测值进行表示的点分割为多个聚类;以及回归分析部,其针对多个聚类的每一个,
使用实测值,对以表示原水的性质的值为说明变量、以表示药剂的量的值为目标变量的预测模型的参数进行最佳化,针对每个聚类的数量评价表示参数被最佳化的预测模型输出的药剂的量的值的预测值与表示药剂的量的值的实测值的差值,并基于评价的结果来决定聚类的数量。
12.关于其他手段,在用于实施发明的方式中进行说明。
13.发明效果
14.根据本发明,能够分割变量的多维空间以便能够根据运转条件使用高精度的多个预测模型。
附图说明
15.图1是说明聚类分割评价装置的结构等的图。
16.图2是实测值信息的一例。
17.图3是聚类信息的一例。
18.图4是说明聚类与预测模型之间的关系的图。
19.图5是说明聚类与预测模型之间的关系的图。
20.图6是说明聚类与预测模型之间的关系的图。
21.图7是说明聚类与预测模型之间的关系的图。
22.图8是说明误差的图。
23.图9是误差信息的一例。
24.图10是处理步骤的流程图。
具体实施方式
25.以下,参照附图等详细说明用于实施本发明的方式(称为“本实施方式”)。本实施方式是在净水厂向原水注入凝集剂的例子。但是,本发明也能够应用于对原水注入凝集剂以外的药剂(凝集辅助剂、氧化剂、吸附剂、消毒剂等)的例子。并且,更一般地,本发明也能够应用于某事件的性质以及该事件变化后的结果的数量关系的分析。
26.(聚类分割评价装置)
27.按照图1,说明聚类分割评价装置1的结构等。聚类分割评价装置1是一般的计算机,具备中央控制装置11、鼠标、键盘等输入装置12、显示器等输出装置13、主存储装置14、辅助存储装置15以及通信装置16。它们通过总线相互连接。辅助存储装置15存储有预测模型31、实测值信息32、聚类信息33以及误差信息34(详细后述)。
28.主存储装置14中的实测值取得部21、聚类部22、回归分析部23以及显示处理部24是程序。中央控制装置11将这些程序从辅助存储装置15读出并加载到主存储装置14,来实现各个程序的功能(详细后述)。辅助存储装置15也可以是独立于聚类分割评价装置1的结构。
29.净水厂3具有混合池4、凝集剂注入装置5以及絮凝物形成池7。从河川等自然环境取得的原水6a流入混合池4。凝集剂注入装置5向贮存于混合池的原水6a注入凝集剂9。注入了凝集剂9的原水6a被急速搅拌后,作为混合水6b流入到絮凝物形成池7。贮存在絮凝物形成池7中的混合水6b被慢速搅拌。于是,胶体状的污浊物质开始凝集。凝集的污浊物质之后
沉淀或被过滤。
30.通常用作凝集剂9的物质(药剂)是硫酸铝、聚氯化铝等。原水中的污浊物质带负电而相互排斥。当凝集剂9中和该带电时,污浊物质因分子间力相互吸引而较大地成长,成为絮凝物(block)。
31.作为表示原水的污浊程度的物理量,存在“浊度”。浊度是每1升原水的污浊物质的质量(mg)。根据某都道府县水道站的主页,一般的河川的水在晴天时的浊度通常为“5”。然而,有时在刚台风之后记录有浊度“2600”。净水厂决定凝集剂注入率,以使浊度下降到预定的基准值以下。凝集剂注入率是向每1升原水注入的凝集剂的质量(mg/升)。作为表示成为决定凝集剂注入率的主要原因的原水的性质的物理量,存在浊度、氢离子浓度(ph、中性=7)、温度(水温、℃)等。
32.因此,浊度计8a、ph计8b及温度计8c配置在混合池4中,注入量计8d配置在凝集剂注入装置5中。它们经由网络2与聚类分割评价装置1连接。
33.(预测模型)
34.本实施方式的预测模型31是以下的式1那样的1次式。
35.y=a0 a1x1 a2x2xa3x3ꢀꢀ
(式1)
36.在此,y是凝集剂注入率。x1是浊度。x2是氢离子浓度。x3是水温。a0、a1、a2和a3是常数(参数)。式1是以x1、x2以及x3为说明变量、以y为目标变量的函数。而且,通过使a0、a1、a2及a3的值进行各种变化,使4维空间中的预测模型31的形状及其位置进行各种变化。在此,将变量的数量(种类)设为“4”只不过是一例。变量的数量可以更多,即,预测模型的维度也可以更大。
37.现在,作为凝集剂注入率、浊度、氢离子浓度以及水温的过去的实测值的组合,假设存在多个“[y,x1,x2,x3]”。y、x1、x2及x3各自所表示的物理量与y、x1、x2及x3各自所表示的物理量相同。然而,为了便于说明,用大写字母表示实测值,用小写字母表示预测模型的变量。预测模型的输出(目标变量)y是“预测值”。将“y
‑
y”称为误差。聚类分割评价装置1使用实测值的组合,决定使误差的平方和“σ(y
‑
y)
2”最小的参数的组合“[a0,a1,a2,a3]”(详细后述)。
[0038]
(实测值信息)
[0039]
图2是实测值信息32的一例。在实测值信息32中,与存储在时刻栏101中的时刻相关联地,在目标变量栏102中存储有目标变量的实测值,在说明变量栏103中存储有说明变量的实测值。
[0040]
时刻栏101的时刻是通过浊度计8a、ph计8b、温度计8c及注入量计8d取得说明变量的实测值及目标变量的实测值的时刻。时刻t1、t2、t3、
…
省略地示出了时刻。数字越大,则是越靠后的时刻。
[0041]
目标变量栏102的目标变量的实测值是注入量计8d测量出的凝集剂注入率的实测值。“#”省略地示出了不同的值(以下相同)。
[0042]
说明变量栏103的说明变量的实测值是浊度计8a测量出的原水的浊度(栏103a)、ph计8b测量出的原水的氢离子浓度(栏103b)以及温度计8c测量出的原水的温度(栏103c)。
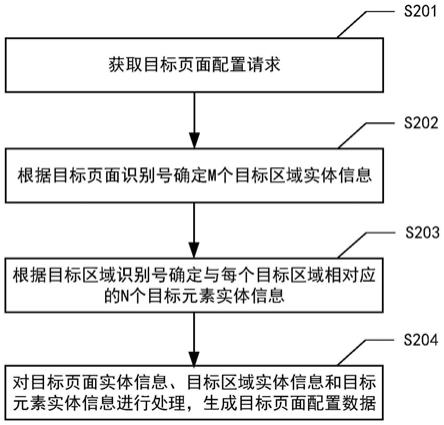
[0043]
(聚类)
[0044]
将在多维空间中描绘的多个点按位置相近的点彼此进行分组的情况一般称为“聚
类”。作为聚类的方法,公知有“k
‑
平均法”。聚类分割评价装置1也如以下的(1)~(5)那样使用k
‑
平均法。
[0045]
(1)聚类分割评价装置1使多个点分别适当地属于k个组的某一个。
[0046]
(2)聚类分割评价装置1按每个组计算出从某个组的重心到属于该组的点为止的距离的平方和d
i
。i是组的编号(i=1、2、
…
、k)。
[0047]
(3)聚类分割评价装置1在将1个点的所属从某一组变为其他组的基础上,计算出d
k
=σd
i
。d
k
是k个组的d
i
的总和。聚类分割评价装置1针对改变所属的点以及新的所属目的地的所有组合的每一个反复进行该处理。
[0048]
(4)聚类分割评价装置1决定使d
k
最小那样的各点的所属。
[0049]
(5)聚类分割评价装置1在使k变化为1、2、3、
…
的基础上,反复进行(1)~(4)的处理。
[0050]
(聚类信息)
[0051]
图3是聚类信息33的一例。在聚类信息33中,与存储在时刻栏111中的时刻相关联地,在目标变量栏112中存储有目标变量的实测值,在说明变量栏113中存储有说明变量的实测值,在所属聚类id栏114中存储有所属聚类id。
[0052]
时刻栏111的时刻与图2的时刻相同。
[0053]
目标变量栏112的目标变量的实测值与图2的目标变量的实测值相同。
[0054]
说明变量栏113的说明变量的实测值是图2的说明变量的实测值中的原水的浊度(栏103a)。为了简化说明,图3的说明变量仅为“浊度”。
[0055]
所属聚类id栏114按聚类的数量分为聚类数1栏114a、聚类数2栏114b、聚类数3栏114c、聚类数4栏114d、
…
。而且,在分开的各栏中存储有聚类id。聚类id是唯一地确定聚类的标识符。各聚类与四季、天气等运转条件对应。通常,净水厂根据该运转条件来决定包含凝集剂注入率的各种数值(运转模式)。此外,如“c3”以及“c10”那样,即使所属的点在结果上相同,如果聚类的数量不同,则也对不同的聚类id进行编号(因为重新计算d
k
)。
[0056]
图4~图7是说明聚类与预测模型31的关系的图。图4对应于图3的聚类数1栏114a。图4的坐标平面的横轴为说明变量(浊度),纵轴为目标变量(凝集剂注入率)。在坐标平面上描绘有与时刻t1~t20对应的20个点
●
(在图5~图7中也同样)。圆c1表示聚类c1。直线31a表示预测模型31(图1)。关于预测模型的生成方法在后面叙述。
[0057]
图5对应于图3的聚类数2栏114b。圆c2表示聚类c2。圆c3表示聚类c3。直线31b表示预测模型31(图1)。直线31c也表示预测模型31(图1)。
[0058]
图6对应于图3的聚类数3栏114c。图7对应于图3的聚类数4栏114d。图6及图7的说明以图5的说明为准。
[0059]
此外,在图4~图7中,由于作图上的制约,圆c1等的中心不成为聚类c1等的重心(全部的点
●
的坐标值的平均)。
[0060]
在图4~图7中,聚类分割评价装置1针对每个聚类,仅使用属于该聚类的实测值
●
来生成预测模型。聚类分割评价装置1生成预测模型“y=a0 a1x
1”的方法如以下的(11)~(17)所示。
[0061]
(11)聚类分割评价装置1将随机产生的参数a0和a1的值代入到预测模型的a0和a1。
[0062]
(12)聚类分割评价装置1将实测值x代入到预测模型的x1,计算出y。
[0063]
(13)聚类分割评价装置1计算出误差“y
‑
y”。
[0064]
(14)聚类分割评价装置1在每个时刻使[x,y]的值变化,并反复进行上述(12)以及上述(13)的处理。
[0065]
(15)聚类分割评价装置1计算出各时刻的“(y
‑
y)
2”的总和即“σ(y
‑
y)
2”。
[0066]
(16)聚类分割评价装置1将随机生成的参数a0和a1的其他值代入到预测模型的a0和a1后,反复进行足够多次数的上述(12)~(15)的处理。
[0067]
(17)聚类分割评价装置1决定使“σ(y
‑
y)
2”最小的参数a
0s
以及a
1s
的值。在此,“s”表示“被最佳化”。
[0068]
(误差)
[0069]
图8是说明误差的图。图8的坐标平面的横轴为浊度,纵轴为凝集剂注入率。20个点
●
表示图3中的实测值的组合[x,y]。直线31a是预测模型31(图1),该式是“y=a
0s
a
1s
x
1”。对于每个点
●
,定义误差“y
‑
y”。如上所述,“σ(y
‑
y)
2”被最小化,但在关注各个点
●
的情况下,混存有几乎没有误差的情况和误差比较大的情况。
[0070]
(误差信息)
[0071]
图9是误差信息34的一例。在误差信息34中,与存储在聚类数栏121中的聚类数相关联地,在误差栏122中存储有误差,在误差评价值栏123中存储有误差评价值。
[0072]
聚类数栏121的聚类数是聚类的数量。
[0073]
误差栏122的误差是“√(σ(y
‑
y)2/n)”。在此,n是聚类内的点
●
的数量。“√(σ(y
‑
y)2/n)”是图8中的误差的平方和的平均平方根。在标注有“#”的括号内记载有聚类id。
[0074]
误差评价值栏123的误差评价值是对误差进行加工而得到的任意的值,该值越小,对聚类数的评价越高。误差评价值例如是误差信息34的记录(行)中包含的误差的平均、误差的最小值、误差的方差等。另外,根据误差评价值的定义方法,也存在其值越大则对聚类数的评价越高的情况。
[0075]
(处理步骤)
[0076]
图10是处理步骤的流程图。作为开始处理步骤的前提,实测值信息32(图2)在完成的状态下存储在辅助存储装置15中。
[0077]
在步骤s201中,聚类分割评价装置1的实测值取得部21取得实测值。具体而言,实测值取得部21从辅助存储装置15取得实测值信息32(图2)。
[0078]
在步骤s202中,聚类分割评价装置1的聚类部22接受变量。具体而言,聚类部22接受用户经由输入装置12选择多个说明变量的一部分或全部这一处理。例如,在用户预测为说明变量中浊度的参数的值a1在除a0以外的所有参数中可能最大、即浊度对目标变量的影响可能最大的情况下,用户可以选择“浊度”。在此,假设用户选择了“浊度”。
[0079]
在步骤s203中,聚类部22接受聚类数的最大值等。具体而言,聚类部22接受用户经由输入装置12选择聚类数的最小值以及最大值、以及1个聚类中包含的点
●
(聚类信息33的记录数)的最小值这一处理。在此,设为用户输入了“1”作为聚类数的最小值,输入了“4”作为聚类数的最大值,输入了“4”作为1个聚类所包含的点
●
的最小值。
[0080]
在步骤s204中,聚类部22执行聚类。具体而言,第一,聚类部22从实测值信息32(图2)中删除“浊度”以外的说明变量的栏。
[0081]
第二,聚类部22使用所述k
‑
平均法,将实测值信息32(图2)的20个点
●“
[x,y]=
[浊度,凝集剂注入率]”分割为k个(k=1、2、3、4)聚类。此时,聚类部22使任意的聚类中都至少包含4个点
●
。
[0082]
在步骤s205中,聚类部22生成聚类信息33(图3)。具体地,聚类部22基于步骤s204中的“第二”聚类的结果来生成聚类信息33。
[0083]
在步骤s206中,聚类分割评价装置1的回归分析部23生成预测模型31。具体而言,回归分析部23接受用户在画面上记述预测模型的数学式这一处理,或者接受对一般的预测模型的设计原型进行画面显示并由用户进行选择这一处理。在此生成的预测模型31不需要是上述的式1那样的1阶式,可以是高阶式,也可以是包含指数、对数等的非线性的公式。但是,预测模型31包含关于在步骤s202中受理的各变量的参数(在该阶段,值是未知的)。
[0084]
在步骤s207中,回归分析部23使每个聚类的参数最佳化。具体而言,回归分析部23通过上述的方法,对每个聚类决定预测模型的参数。即,回归分析部23使用实测值信息32(图3)的时刻t1~t20的实测值中的属于处理对象的聚类的实测值,决定使“σ(y
‑
y)
2”最小的参数。
[0085]
在步骤s208中,回归分析部23生成误差信息34(图9)。具体而言,第一,回归分析部23生成误差信息34。这里生成的误差信息34具有4条记录,在聚类数栏121中存储有“1”、“2”、“3”以及“4”。误差栏122以及误差评价值栏123是空栏。
[0086]
第二,回归分析部23使用在步骤s207中最小的“σ(y
‑
y)
2”,算出误差“√(σ(y
‑
y)2/n)”,并存储于误差栏122。
[0087]
第三,回归分析部23基于各记录的误差,计算出误差评价值,并存储于误差评价值栏123。
[0088]
在步骤s209中,回归分析部23基于误差评价值来决定聚类数。此外,在本实施方式中,具体而言,回归分析部23决定误差评价值最小的记录的聚类数。
[0089]
在步骤s210中,聚类分割评价装置1的显示处理部24显示所决定的聚类的数量和误差评价值。具体而言,第一,显示处理部24将在步骤s209中决定的聚类数以及针对该聚类数的误差评价值显示于输出装置13。这里,假设显示“聚类数=4”。
[0090]
第二,显示处理部24将与4个聚类c7、c8、c9以及c10对应的预测模型31g、31h、31i以及31j(图7)存储于辅助存储装置15。然后,结束处理步骤。
[0091]
(预测模型的应用)
[0092]
在步骤s210的“第一”中显示了“聚类数=4”的前提下,说明之后的预测模型的应用方法。聚类c7与图3的时刻t1~t4对应。时刻t1~t4例如是前年的某个特定的季节(持续晴朗等)。回归分析部23在预测次年同月同日的凝集剂注入率的情况下,使用预测模型31g。聚类c10与图3的时刻t17~t20对应。时刻t17~t20例如是前年的某个其他特定季节(持续梅雨等)。回归分析部23在预测次年同月同日的凝集剂注入率的情况下,使用预测模型31j。对于其他聚类也是同样如此。
[0093]
(处理步骤的变形例)
[0094]
在上述中,聚类部22针对所有聚类数执行聚类,并且回归分析部23针对所有聚类数计算出误差评价值(循环处理)。但是,也可以按照聚类数k=1、2、3、4的降序或升序,反复进行聚类部22进行聚类、回归分析部23计算误差评价值的处理。在该情况下,聚类部22以及回归分析部23反复进行处理,直到误差评价值达到预定的阈值(目标)为止,或者直到误差
评价值相对于上次的比减少量成为预定的阈值以下为止。
[0095]
(本实施方式的效果)
[0096]
本实施方式的聚类分割评价装置的效果如下。
[0097]
(1)聚类分割评价装置能够按每个运转条件生成高精度的预测模型。
[0098]
(2)聚类分割评价装置能够显示可期待的误差评价值以及与运转条件对应的聚类数。
[0099]
(3)聚类分割评价装置使用户能够指定聚类的数量和大小。
[0100]
(4)聚类分割评价装置能够应用于净水厂的凝集剂注入率的预测。
[0101]
此外,本发明并不限定于上述的实施例,包含各种变形例。例如,上述的实施例是为了容易理解地说明本发明而详细说明的,并不限定于必须具备所说明的全部结构。另外,能够将某实施例的结构的一部分置换为其他实施例的结构,另外,也能够在某实施例的结构中添加其他实施例的结构。另外,对于各实施例的结构的一部分,能够进行其他结构的追加、删除、置换。
[0102]
另外,上述的各结构、功能、处理部、处理单元等的一部分或者全部例如也可以通过在集成电路中设计等而由硬件实现。另外,上述的各结构、功能等也可以通过处理器解释并执行实现各个功能的程序而由软件实现。实现各功能的程序、表、文件等信息能够放置在存储器、硬盘、ssd(solidstatedrive:固态硬盘)等记录装置、或者ic卡、sd卡、dvd等记录介质中。
[0103]
另外,控制线、信息线示出了认为说明上必要的部分,并不一定示出了产品上所有的控制线、信息线。实际上也可以认为几乎所有的结构都相互连接。
[0104]
附图标记说明
[0105]
1聚类分割评价装置
[0106]
2网络
[0107]
3净水厂
[0108]
4混合池
[0109]
5凝集剂注入装置
[0110]
6a原水
[0111]
6b混合水
[0112]
7絮凝物形成池
[0113]
8a浊度计
[0114]
8bph计
[0115]
8c温度计
[0116]
8d注入量计
[0117]
9凝集剂
[0118]
11中央控制装置
[0119]
12输入装置
[0120]
13输出装置
[0121]
14主存储装置
[0122]
15辅助存储装置
[0123]
16 通信装置
[0124]
21 实测值取得部
[0125]
22 聚类部
[0126]
23 回归分析部
[0127]
24 显示处理部
[0128]
31 预测模型
[0129]
32 实测值信息
[0130]
33 聚类信息
[0131]
34 误差信息。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。