基于改进pate的wgan
‑
gp隐私保护系统和方法
技术领域
1.本发明属于ai安全领域,涉及隐私学习、集成学习以及知识迁移的综合运用,通过权衡隐私性和准确性设计一种综合性能提升的模型。实现对训练数据的隐私保护,生成不再包含真实隐私信息且足够逼真的合成数据以供机器学习模型的训练,防御模型窃取攻击,保证了机器学习模型的安全性。具体涉及基于改进pate的wgan
‑
gp隐私保护方法。
背景技术:
2.随着信息共享时代的到来,信息发布、数据挖掘技术层出不穷,大量隐私价值即包含潜在的、有价值的知识被挖掘。隐私泄露的风险不可避免地以极高的速度迅速增加。在深度学习模型训练过程中,往往采用真实数据进行训练。然而在现有的应用中已经被证明:许多隐私敏感的训练数据能够从模型中恢复。攻击者通过分析能够直接恢复部分模型参数,或是间接地通过反复查询不透明模型,收集数据进行攻击,对机器模型的机密性进行破坏。
3.在现有的隐私保护方法的研究中,最常规的防御方法是采用差分隐私添加噪声的方式来对数据和模型进行隐私保护,通过在训练过程中添加从一个随机分布中的采样进行扰动能达到有效的隐私保护效果。基于隐私学习的机器学习模型可以分为两类:一类是基于noisysgd(noisy stochastic gradient descent,噪声随机梯度下降法),另一类是pate(private aggregation of teacher ensemble,教师系综的私有聚合)。
4.生成式对抗网络gan(generative adversarial networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。顾名思义,其最核心两个模块即:生成网络和判别网络。两种网络通过博弈的方式对抗训练,当达到平衡点时,生成网络便能生成足以混淆判别网络的、以假乱真的生成样本。在现阶段,有很多领域的任务都借助gan来进行性能提升,如cv领域中几乎所有任务都使用gan来提升性能。gan能够为机器学习模型提供大量的训练样本,甚至在理想状态下,能代替真实样本训练模型以达到保护用户隐私信息的目的。因此,利用差分隐私的方法训练gan有望能为以上面临问题提供解决之策。
5.基于噪声随机梯度下降法(noisysgd)的gan模型具有差分隐私的经验上最小化复杂网络损失函数。通过在判别器训练过程中在梯度计算时添加仔细校准过的噪声来实现隐私保护。考虑到生成器不接触真实数据以及差分隐私的后处理性质,生成器同样也是具有差分隐私属性的。基于教师系综的私有聚合(pate)的gan模型,同样是在判别器上进行隐私学习,训练一组隐私判别器模型构成一个“教师系综”,同样基于差分隐私的后处理定理,通过对教师系综的输出结果集成并引入校准过的噪声输出带有差分隐私的预测结果训练出一个具备差分隐私性质的“学生”判别器模型,使得无论是模型的参数或是训练集都不带有任何隐私敏感信息。对于以上两种保护模型的提出,其主要目的一是为了保护训练数据中的敏感信息,同时也为了能够通过从训练数据中学习相关分布、生成样本,为更多的任务提供有效、脱敏的训练样本集。
6.大部分隐私学习的机器模型都是采用noisysgd来实现隐私保护。基于noisysgd对于gan的变种优化模型的研究开展较为充足。但其方法训练的生成对抗网络在梯度裁剪中
每一轮都需加入适量精准计算后的噪声,因此仍会引入较大的噪声量。正因如此,基于noisysgd的训练方法通常会面临隐私预算耗尽而模型无法收敛的问题。同时,梯度裁剪时引入的噪声由于是随机分布中采样所得,对模型的训练优化中产生的影响不可预估,对模型的训练可能会往反方向产生效果。而基于pate的gan模型将添加噪声阶段统一至集成输出教师预测标记时,能够更有效的控制加入噪声的数量。同时,基于pate的方法运用半监督的训练方式,能够在控制隐私的情况下,更好地提高判别器的准确性,为生成器的训练提供更准确方向。本发明的方法研究立足于pate的方式,对集成算法进一步优化和对教师模型的准确挑选,通过优化教师判别器的分类效果进而优化学生判别器使模型达到最优。同时考虑使用gan的变种模型wgan
‑
gp,通过wasserstein散度分析两个分布,并引入梯度惩罚项,提高生成器的准确率并使模型能够稳定训练,避免梯度消失。
技术实现要素:
7.为克服现有技术的不足,本发明旨在提出一种模型训练稳定、生成效果好且具有严格隐私保证的方法。为此,本发明采取的技术方案是,基于改进pate的wgan
‑
gp隐私保护方法,基于设计的共识度检查条件和从高斯分布采样噪声进行差分隐私保护对聚合机制进行优化,利用教师判别器共识度与隐私成本之间成反比以及和准确性之间成正比的关系在集成过程中设计有条件的差分隐私聚合器,通过优化教师分类器集群,在保护原始敏感训练数据的基础上生成供其他机器学习模型进行训练的合成数据。
8.基于改进pate的wgan
‑
gp隐私保护系统,由五个部分组成,教师分类模型优选模块、优化的教师分类器集群模块、有条件的差分隐私聚合器模块、学生判别器模块、生成器模块;首先教师分类模型优选模块是通过k折交叉验证法对若干分类模型进行评估,比较不同类别下若干分类模型的分类效果,进而挑选出每一种类别对应分类效果较优的分类模型,保留该分类模型作为优化的教师分类器集群的模型结构;重置所挑选分类模型的参数后,将真实敏感数据集划分为等大小且不相交的若干子集,每一个子集对应训练一个优选出的分类模型即教师分类器,形成优化的教师分类器集群模块;对于生成器模块的合成样本,由优化的教师分类器集群模块分别做出分类预测,优化的教师分类器集群模块的输出结果经过具有条件筛选机制的有条件的差分隐私聚合器聚合并添加高斯噪声,学生判别器学习通过筛选后的分类结果及来自生成器的合成样本进行训练,通过知识迁移对生成样本进一步判别计算,输出结果反向传播优化生成器,反复进行对抗训练直至隐私预算耗尽或模型达到“零和博弈”平衡。
9.教师分类模型优选模块中:
10.使用k折交叉验证法评价模型,对教师分类模型进行优选;
11.运用不同的卷积神经网络模型,在训练数据集下分别训练分类模型,经过迭代后,对于各类别的准确性依次分析,取每一个类别的测试结果的平均值作为模型的分类效果,独立训练出一个分类模型,以此类推,对n种网络模型结构进行训练,训练得到n个结构不同的分类模型,将每个分类模型针对不同类别的分类效果进行分析整理,得到一个基于若干分类模型对于不同类别训练效果对比表,从该表中对每一种类别选出表现较优的前m个分类模型,作为对应该类别分类效果最优的教师分类模型,保留模型结构、重置所有模型参数以供后续优化的教师分类器集群的训练使用。
12.优化的教师分类器集群中:
13.将根据优化的教师分类器集群模块优选挑出的每一类的较优分类模型作为一个分类块,对该类别做二分类处理,每一个分类块由m个教师分类模型结构组成,总共有t个分类块,再将现有的真实敏感训练数据集d划分为n个不相交的、具有相同大小的子集d
i
,i=1,...,n,每一个子集对应分别训练每一个块中的一个分类模型,即一个子集d
i
独立训练一个优化的教师分类模型即优化的教师分类器,对应得到n个有相同学习任务的独自进行训练的优化的教师分类器集群,优化的教师分类器集群表示为其中,将t个分类块称作t个教研室,即训练得到的共n个教师t
ij
对应所属于t个教研室中;
14.每个优化的教师分类器的损失函数即为交叉熵函数,其表示为:
[0015][0016]
其中,m为当前批样本的数量大小,概率分布p
k
为模型t
ij
的期望输出,概率分布q
k
为教师分类器t
ij
的实际输出,在交叉熵之后连接一个softmax函数,将输出转化成概率结果。
[0017]
有条件的差分隐私聚合器模块中:
[0018]
对于输入样本x,n名优化的教师分类器按所属教研室类别j分别对x做二分类,对每一个教研室t
j
里的t个优化的教师分类器的预测进行聚合处理,进而产生一个结果,t个教研室可得到t个结果{y
j
:j∈[1,...,t]},通过对各教研室得到的结果引入从高斯分布中随机采样的噪声加以扰动,进而实现差分隐私保证,教研室内优化的教师分类器预测结果的一致性程度被称为共识度,设定一个阈值t作为优化的教师分类器集群预测一致性的检验值,即共识度检查;首先从具有差分隐私属性的各类别投票结果中,选出投票最多的类y
j
′
:|y
j
′
|>|y
i
′
|{i,j∈1,...,t i≠j}进行判断;当|y
j
′
|>t∧|y
i
′
|<t{i,j∈1,...,t i≠j}时,将y
j
′
作为整个优化的教师分类集群的预测标签;而当|y
i
′
|<t{i∈1,...,t},将被认为全体教师判断样本x为“假样本”,即将第t 1个标签作为预测结果输出;否则,则认为教师之间未达成共识,不进行标签输出;
[0019]
对于聚合结果,就是优化的教师分类器集群投票数最高的一类,有两次集成,第一次是教研室{j:j∈0,...,q}下优化的教师分类器输出预测的集成;第二次是t个教研室的输出结果的再集成y
j
:{j∈1,...,t},共有t 1类,t种真实类别和1个“假”类别,首先对各教研室下优化的教师分类器的输出聚合后加入具有方差的高斯噪声后引入一个阈值做判断处理,只有超过阈值的最大投票才是被认为共识度足够高的预测结果,以下将此噪声阈值检查简化称为共识度检查,只有通过共识度检查,才能被噪声聚合后输出,对通过的结果,在最大的原始投票值中加入一个较小方差的高斯噪声,以此作为私有噪声聚合的输出结果;
[0020]
对于通过共识度检查的结果,简化为公式表达为:
[0021][0022]
其中,f
ij
(x)为优化的教师分类器t
ij
{i∈1,...,m}对于样本x是否为第j类的预测结果。则对于第j类教研室的投票结果聚合表示为f
j
(x)=|{n:f
ij
(x)=1}|。
[0023]
学生判别器模块中:
[0024]
学生判别器通过分析生成样本以及该样本对应的经过有条件的差分隐私聚合器输出的预测标签{(x
n
,y
n
):y
n
=m
σ
(x
n
),n∈0,...,q}进行训练,对优化的教师分类器集群知识迁移,进而不断学习。设置一个生成效果足够好的合成数据集作为新的数据集p
u
={u1,u2,...,u
n
},其中且
[0025]
学生判别器期望目标函数能尽可能取最大值,其目标函数为:
[0026][0027]
z是输入的随机噪声,p
z
是随机高斯噪声的分布,p
y
是p
u
和p
v
中任意样本之间连线的区域,u是从生成样本中选择的数据,学生判别器判别被标记为真实的样本u和被标记为生成的样本v之间的差别,基于wassertein距离来衡量,损失函数的最后一项是学生判别器的梯度惩罚项,其中是两类样本集中任意各取一样本之间连线的区域,y为从标记为真样本u和标记为假样本v之间采样的成对点之间的连线上的随机插值采样,y满足下式:
[0028]
y=εp
u
(1
‑
ε)p
v
[0029]
其中,ε~unif[0,1]
d
。
[0030]
对于学生判别器,目标是最大程度鉴别两类样本之间的差距,故而在学生判别器目标函数中,判别两类样本分布的w距离,并引入“梯度惩罚”项,保证判别器的梯度更新限制在可控的范围内。
[0031]
生成器模块中:
[0032]
生成器沿用wgan
‑
gp中的g。从高斯随机噪声中选取分布经过生成器的变换可得到生成样本,在对抗训练过程中,生成器通过学生判别器反向传播的梯度学习更新,映射随机噪声分布生成样本,其损失函数:
[0033][0034]
p
z
是随机高斯噪声的概率分布,z是生成器从高斯分布中随机采样得到的输入,生成器目标是生成逼真的图片使学生判别器无法辩别真假,即学生判别器对生成样本判别为假的概率最小化。
[0035]
本发明的特点及有益效果是:
[0036]
本发明分析了模型的auroc曲线,作为测量本发明模型epate
‑
wgan
‑
gp的预测能力的指标。通过对比dpgan、pate
‑
gan模型,对本发明的模型性能进行分析由于引入不同的隐私聚合机制而造成了不同的隐私损失(见图3)。同时,本发明还与wgan
‑
gp、gan和基于原始gan的pate
‑
gan、dpgan模型的生成样本质量进行对比分析(见表4)。本发明在两种不同的训练测试设置下验证生成的数据集的质量。设置a:在真实的训练集上训练预测模型,在真实的测试集上测试模型的性能;设置b:在合成训练集上训练,在真实测试集上测试。
[0037]
附表3 auroc表(设置a下)
[0038][0039]
附表4生成样本性能表(设置b下)
[0040]
[0041][0042]
本发明通过研究隐私成本和模型效用之间的权衡发现,本发明提高了教师分类器集群的共识度,即使用本发明的优化的教师分类器集群和有条件的差分隐私聚合器,学生鉴别器的查询成本随着优化的的教师分类器集群之间共识度的提高而降低,生成模型的准确率随着共识度的提高而得到提高。也就是在本发明的模型的优化下,查询成本与效用之间出现了一致的改进效果。附图3为本发明模型在国际皮肤影像协会(international skin imaging collaboration,isic)数据集上的auroc曲线。本发明的模型能较pate
‑
gan和dpgan有更好的模型表现。通过使用pate机制,能使单个样本对判别器的影响被控制下来,进而产生较为严格的差分隐私保证。而在本发明使用了共识度检查之后,学生判别器的每一个查询的隐私成本也被限制为一个较小的固定值,比pate
‑
gan生成一个更为严格的隐私边界。
附图说明:
[0043]
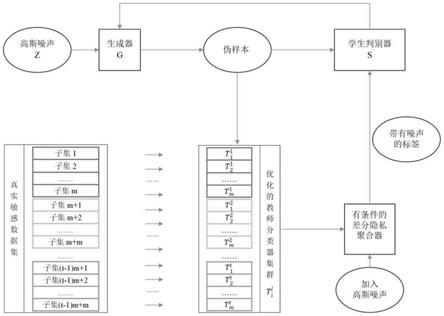
附图1整体架构图(epate
‑
wgan
‑
gp)。
[0044]
附图2优化的教师判别器模型预处理。
[0045]
附图3模型的auroc曲线。
具体实施方式
[0046]
本发明提出一种基于改进pate的wgan
‑
gp隐私保护框架,基于设计的共识度检查条件和从高斯分布采样噪声进行差分隐私保护对聚合机制进行优化。利用优化的教师分类器集群共识度与隐私成本之间成反比以及和准确性之间成正比的关系,在集成过程中设计有条件的差分隐私聚合器,通过优化的教师分类器集群使得整个模型能够在保护原始敏感训练数据的基础上生成足够逼真以供其他机器学习模型进行训练的合成数据。
[0047]
1.整体架构
[0048]
本发明设计的基于改进pate的wgan
‑
gp隐私保护框架(epate
‑
wgan
‑
gp)整体架构如附图1所示,主要由五个部分组成,教师分类模型优选模块、优化的教师分类器集群模块、有条件的差分隐私聚合器模块、学生判别器模块、生成器模块。通过10折交叉验证法对若干分类模型进行评估,比较不同类别下若干分类模型的效果,进而挑选出每一种类别对应分类效果较优的分类模型完成对教师分类模型的优选工作;重置所挑选模型的参数后,将真实敏感数据集划分为等大小且不相交的若干子集,每一个子集对应训练一个优化的教师分类器,组成优化的教师分类器集群。对于生成器的合成样本,优化的教师分类器集群分别做出分类预测,对优化的教师分类器集群的输出结果经过具有条件筛选机制的差分隐私聚合器聚合并添加高斯噪声,学生判别器学习通过筛选后的分类结果及来自生成器的合成样本训练,通过知识迁移对生成样本进一步判别预测,输出结果反向传播优化生成器。反复进行对抗训练直至隐私预算耗尽或模型达到“零和博弈”平衡。
[0049]
2.教师分类模型优选
[0050]
教师分类器集群作为整个模型的关键,通过知识迁移训练学生判别器,对整个模型的准确率的提升起到决定性影响。本发明使用k折交叉验证法(k=10)评价模型,对分类模型进行优选,目的是为了选择出较优的教师分类器,让不同的教师分类器在其擅长的领域进行分类,进而得到更好分类结果。
[0051]
运用不同的卷积神经网络模型,在训练数据集下分别训练教师分类模型。如附图2所示。首先,将用于训练的真实训练数据集d划分为10个等大小且不相交的子集d
i
(i=1,...,10),依次取9个子集作为训练集来训练模型处理多分类问题,剩下一个子集作为测试集来评价模型。经过10轮迭代后,对于各类别的准确性依次分析,取每一个类别的测试结果的平均值作为模型的分类效果。对该分类模型的10次训练结果进行分析整理,分析分类模型对不同类别(共t个类别)的分类效果。按照以上方法,对n种网络模型结构进行训练,可以训练得到n个结构不同的分类模型,将每个分类模型针对不同类别的分类效果进行分析整理,可得到一个基于若干教师模型对于不同类别训练效果对比表(表1)。在每一种类别中,从表中选出表现较优的前m个分类模型,作为对应该类别分类效果最优的教师分类模型,随后保留模型结构、重置所有模型参数以供后续优化的教师分类器集群的训练使用。
[0052]
附表1在原始数据集上不同教师模型拟合效果表
[0053]
[0054][0055]
3.优化的教师分类器集群
[0056]
在训练优化的教师分类器集群阶段,本发明将根据教师分类模型优选模块挑出每一类较优的教师分类模型组成一个分类块,对该类别做二分类处理。每一个分类块由m个优化的教师分类器组成,总共有t个分类块。再将现有的真实敏感训练数据集d划分为n个不相交的、具有相同大小的子集d
i
(i=1,...,n),每一个子集对应分别训练每一个块中的一个优化的教师分类器,即一个子集d
i
独立训练一个教师分类器,对应可以得到n个有相同学习任务的独自进行训练的教师分类器,优化的教师分类器集群表示为本发明将t个分类块称作t个教研室,即训练得到的共n个优化的教师分类器t
ij
对应所属于t个教研室中。
[0057]
优化的教师分类器t
ij
的损失函数即为交叉熵函数,其表示为:
[0058][0059]
其中,m为当前批样本的数量大小,概率分布p
k
为模型t
ij
的期望输出,概率分布q
k
为教师模型t
ij
的实际输出。交叉熵越小,两个分布之间的距离越小则模型预测效果越准确。在交叉熵之后连接一个softmax函数,将输出转化成概率结果。
[0060]
4.有条件的差分隐私聚合器
[0061]
对于输入样本x,n名优化的教师分类器按所属教研室类别j分别对x做二分类,对
每一个教研室里的优化的教师分类集群t
j
中t个教师的预测进行聚合处理,进而产生一个预测聚合结果,t个教研室可得到t个结果{y
j
:j∈[1,...,t]}。通过对各教研室得到的结果引入从高斯分布中随机采样的噪声加以扰动,进而实现差分隐私保证。对于教研室内优化的教师分类器集群预测结果的一致性程度称之为共识度。如表2(算法1)所示,
[0062]
附表2算法1:有条件的差分隐私聚合器
[0063][0064]
本发明设定一个阈值t作为优化的教师分类器集群预测一致性的检验值,即共识度检查。首先从具有差分隐私属性的各类别投票结果中,选出投票最多的类y
j
′
:|y
j
′
|>|y
i
′
|{i,j∈1,...,t i≠j}进行判断;当|y
j
′
|>t∧|y
i
′
|<t{i,j∈1,...,t i≠j}时,将y
j
′
作为整个优化的教师分类器集群的预测标签;而当|y
i
′
|<t{i∈1,...,t},将认为全体优化的教师分类器集群判断样本x为“假样本”,即将第t 1个标签作为预测结果输出;否则,则认为教师之间未达成共识,不进行标签输出。当优化的教师分类器集群的预测一致性越高时,即大部分教师有着相同的输出时,输出的聚合结果也将越有效。
[0065]
对于聚合结果,就是优化的教师分类器集群投票数最高的一类。有两次集成。第一次是教研室{j:j∈0,...,q}下优化的教师分类器输出预测的集成。第二次是t个教研室的输出结果的再集成y
j
:{j∈1,...,t}(共有t 1类,t种真实类别和1个“假”类别)。首先对各教研室下优化的教师分类器的输出聚合后加入具有方差的高斯噪声后引入一个阈值做判断处理,只有超过阈值的最大投票才是被认为共识度足够高的预测结果,以下将此噪声阈值检查简化称为共识度检查。只有通过共识度检查,才能被噪声聚合后输出。对通过的结果,在最大的原始投票值中加入一个较小方差的高斯噪声,以此作为噪声聚合的输出结果。
[0066]
对于通过共识度检查的结果,简化为公式表达为:
[0067][0068]
其中,f
ij
(x)为优化的教师分类器t
ij
{i∈1,...,m}对于样本x是否为第j类的预测结果。则对于第j类教研室的投票结果聚合表示为f
j
(x)=|{n:f
ij
(x)=1}|。
[0069]
5.学生判别器
[0070]
为了保护隐私信息不被模型窃取而泄露,学生判别器与生成器的对抗训练可能会在反向传播过程中传递训练参数,因此决定了学生判别器不能学习到任何敏感信息。
[0071]
学生判别器通过分析生成样本以及该样本对应的经过有条件的差分隐私聚合器输出的预测标签{(x
n
,y
n
):y
n
=m
σ
(x
n
),n∈0,...,q}进行训练,将优化的教师分类器集群知识迁移,进而不断学习。由于模型会隐性记忆训练数据的相关参数,出于隐私保护的考虑,学生判别器只评估来自生成器合成的样本,而不是真实的数据,所以需要学生判别器能够学习到类似于真实分布的生成样本,学生判别器才能够得到更好的训练。为满足以上设定,能够更好地优化训练学生判别器,本发明设置一个新的合成数据集p
u
={u1,u2,...,u
n
},其中且且
[0072]
学生判别器期望目标函数能尽可能取最大值,其目标函数为:
[0073][0074]
z是输入的随机噪声,p
z
是随机高斯噪声的分布,p
y
是p
u
和p
v
中任意样本之间连线的区域,u是从生成样本中选择的数据,学生判别器判别被标记为真实的样本u和被标记为生成的样本v之间的差别,基于wassertein距离来衡量。此处的学生判别器不再是常规的二分类问题,而是转为解决回归问题。损失函数的最后一项是学生判别器的梯度惩罚项,其中y是p
u
和p
v
中任意样本之间连线的区域,即y为从标记为真样本u和标记为假样本v之间采样的成对点之间的连线上的随机插值采样。y满足下式:
[0075]
y=εp
u
(1
‑
ε)p
v
[0076]
其中,ε~unif[0,1]
d
。
[0077]
对于学生判别器,目标是最大程度鉴别生成样本与真实样本的差距,故而在学生判别器目标函数中,判别生成样本分布和真实样本分布的w距离,并引入“梯度惩罚”项,保证判别器的梯度更新限制在可控的范围内。
[0078]
6.生成器
[0079]
生成器沿用wgan
‑
gp中的g。从高斯随机噪声中选取分布经过生成器的变换可得到生成样本。在对抗训练过程中,生成器通过学生判别器反向传播的梯度学习更新,映射随机噪声分布生成样本。其损失函数与wgan
‑
gp生成器的损失函数类似:
[0080][0081]
p
z
是随机高斯噪声的概率分布,z是生成器从高斯分布中随机采样得到的输入,生成器目标是生成逼真的图片使学生判别器无法辩别真假,即学生判别器对生成样本判别为假的概率最小化。
[0082]
本发明迭代训练生成器g、学生判别器s。每次迭代对学生判别器的参数更新,再反向传播更新生成器。
[0083]
本发明最终的实现形式是一个基于差分隐私的生成式对抗网络数据隐私保护模型。利用该模型能对包含敏感信息的训练数据进行差分隐私保护,通过wgan
‑
gp框架的生成器生成极为逼真的生成样本,为机器学习模型提供不包含真实隐私的训练数据集。本发明的具体实施方式如下:
[0084]
通过k折交叉验证法(本发明中k取10)对教师分类模型进行优选。选出具有较好分
类效果的n个(m*t=n,t为类别数,m为每个类别块的模型数)分类模型后,将训练数据集划分为n个等大小且不重叠的子数据集,依次分别独立训练每一个优化的教师分类器,组成j个分类块(教研室)。生成器首先从高斯分布中随机采样噪声合成生成样本,每一个分类块下的优化的教师分类器对生成样本做分类预测,将教研室内的优化的教师分类器输出的投票结果聚合,一个分类块输出一个投票结果,通过有条件的差分隐私聚合器对结果进行噪声添加和共识度检查。当通过检查时,对j个分类块的结果噪声聚合后输出一个最终的分类标签,学生判别器通过学习优化的教师分类器集群输出的标签和生成器生成的样本,进行训练,并反向传播优化生成器。当共识度检查未通过时,则放弃输出优化的教师分类器集群对该生成样本的分类结果。如此循环训练,通过对抗博弈的方式优化生成器和学生判别器。当隐私预算用尽或模型训练完成时,可产生不包含任何真实敏感信息的生成样本集。
[0085]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。