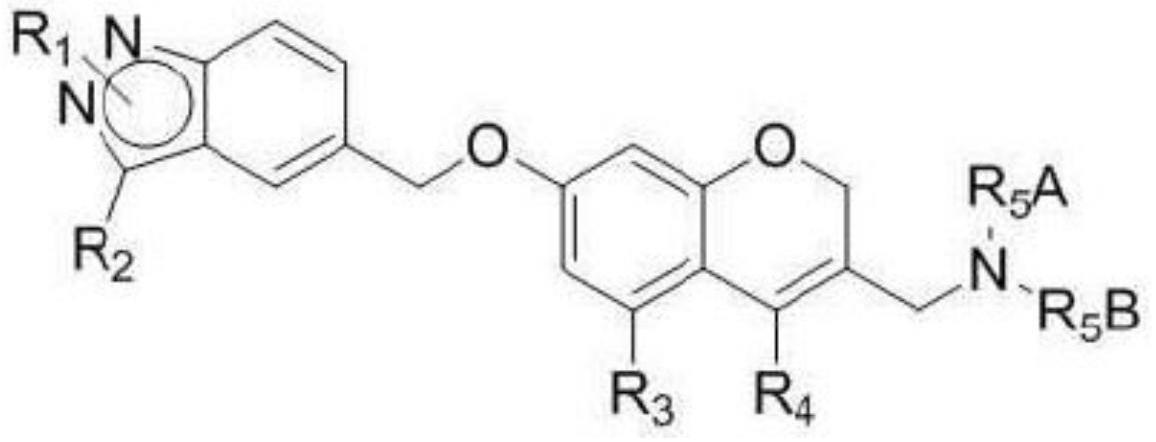
cho细胞衍生的蛋白分泌因子和包含它的表达载体
技术领域
1.本发明涉及一种cho细胞衍生的蛋白分泌因子,其中编码所述蛋白分泌因子的核酸序列和编码靶蛋白的基因被可操作连接的表达盒,包含所述表达盒的表达载体,其中引入有所述表达载体的转化细胞,以及使用所述转化细胞生产靶蛋白的方法。
背景技术:
2.对于在体内难以获得的有用蛋白质组分来说,可以使用微生物或动物细胞系统通过基因重组技术大规模生产重组蛋白。重组蛋白可以被调节,使得它们可以在细胞内表达或分泌到细胞外。然而,细胞内表达的缺点在于蛋白质经常作为不溶性团块积累,并且由于分离和纯化困难而导致生产率降低。另一方面,通过细胞外分泌可以容易地获得具有正确蛋白质折叠的可溶性蛋白。因此,为了在蛋白质产量和质量控制方面获得更合适的细胞外分泌,优化的重组蛋白质表达系统是重要的。
3.为了生产重组蛋白,诸如宿主细胞、感兴趣的基因、表达载体、选择标记、启动子和信号肽序列的组分是必不可少的。重组蛋白的质量和生产率随着这些组分的选择而变。
4.就信号肽而言,它位于待生产的重组蛋白的n-端区域处,因此与重组蛋白的表达水平相关,并且是允许细胞外分泌的组分。取决于使用哪种信号肽,可以观察到表达水平的差异,并且由于信号肽的错误切割,信号肽序列可能保留在所述蛋白质的n-端处,影响重组蛋白的质量。
5.因此,选择不引起错误切割并且可以诱导高表达的信号肽是重要的。
6.同时,常规信号肽大多使用人类来源的信号肽,并且主要使用cho细胞作为表达宿主细胞。在宿主细胞之间信号肽可以组合使用,但可能会导致质量问题。
7.在这些情况下,本发明人为了提高cho细胞中的表达水平和解决错误切割问题付出了许多努力。结果,他们开发了一种新的信号肽,它是由源自于cho细胞的第17至31位氨基酸序列组成的多肽,并通过确认所述信号肽可以显著提高表达并在切割位点处100%切割以防止错误切割,完成了本发明。
技术实现要素:
8.[技术问题]
[0009]
本发明的一个目的是提供一种蛋白分泌因子,其由seq id no:1、seq id no:2或seq id no:3的氨基酸序列组成。
[0010]
本发明的另一个目的是提供一种表达盒,其中编码由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子的核酸序列和编码靶蛋白的基因被可操作连接。
[0011]
本发明的又一个目的是提供一种用于分泌靶蛋白的表达载体,所述表达载体包含表达盒,其中编码由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子的核酸序列和编码靶蛋白的基因被可操作连接。
[0012]
本发明的又一个目的是提供一种转化细胞,其中所述表达载体被引入到宿主细胞中。
[0013]
本发明的又一个目的是提供一种生产靶蛋白的方法,所述方法包括:
[0014]
i)培养包含用于分泌靶蛋白的表达载体的转化细胞,所述表达载体包括表达盒,其中编码由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子的核酸序列和编码靶蛋白的基因被可操作连接;和
[0015]
ii)从培养的细胞的培养基或培养上清液回收所述靶蛋白。
[0016]
[技术解决方案]
[0017]
在下文中将更详细地描述本发明。同时,本文中公开的每个解释和示例性实施方式可以应用于其他解释和示例性实施方式。也就是说,本文中公开的各种不同因素的所有组合均属于本发明的范围。此外,本发明的范围不应受到下文中提供的特定公开内容的限制。
[0018]
此外,本领域普通技术人员可能仅使用常规实验即可识别或确认本文描述的本发明的特定方面的许多等效物。此外,这些等效物也打算被包括在本发明中。
[0019]
为了实现上述目的,本发明的一个方面提供了一种源自于cho细胞的新的蛋白分泌因子。具体来说,本发明提供了一种由seq id no:1、seq id no:2、seq id no:3、seq id no:4、seq id no:5、seq id no:6、seq id no:7、seq id no:8、seq id no:9或seq id no:10的氨基酸序列组成的蛋白分泌因子。更具体来说,所述蛋白分泌因子可以由seq id no:1、seq id no:2或seq id no:3的氨基酸序列组成,但不限于此。
[0020]
本发明的“蛋白分泌因子”是指连接到靶蛋白以诱导所述靶蛋白的细胞外分泌的因子,并且可能由多肽组成。所述蛋白分泌因子可以促进作为内源蛋白和/或外源蛋白的靶蛋白的分泌,并且具体来说可以促进抗体的轻链和/或重链的细胞外分泌,但不限于此。
[0021]
本发明中的蛋白分泌因子可以与“信号序列”或“信号肽(sp)”互换使用。
[0022]
本发明的蛋白分泌因子可以具有seq id no:1、seq id no:2或seq id no:3的氨基酸序列,但不限于此。此外,本发明的蛋白分泌因子还可以包括由seq id no:4、seq id no:5、seq id no:6、seq id no:7、seq id no:8、seq id no:9或seq id no:10的氨基酸序列组成的蛋白分泌因子,但不限于此。
[0023]
在本发明的一个特定实施方式中,所述蛋白分泌因子可以源自于cho细胞,但不限于此。当在本文中使用时,术语“cho细胞”是中华仓鼠卵巢细胞,并且可以是在本领域中常用于转化的宿主细胞。此外,可以对cho细胞衍生的蛋白分泌因子进行选择,以提高在作为宿主细胞的cho细胞中的表达水平。
[0024]
在本发明中,所述由seq id no:1的氨基酸序列组成的蛋白分泌因子可以是组织蛋白酶b(cat),并且可以与本发明中的cat分泌序列互换使用。所述由seq id no:2的氨基酸序列组成的蛋白分泌因子可以是c-c基序趋化因子(cc),并且可以与本发明中的cc分泌序列互换使用。所述由seq id no:3的氨基酸序列组成的蛋白分泌因子可以是核连蛋白-2(nuc),并且可以与本发明中的nuc分泌序列互换使用。
[0025]
另外,所述由本发明的seq id no:4的氨基酸序列组成的蛋白分泌因子可以是丛生蛋白(clus),并且可以与本发明中的clus分泌序列互换使用。所述由seq id no:5的氨基酸序列组成的蛋白分泌因子可以是色素上皮衍生因子(pig),并且可以与本发明中的pig分
泌序列互换使用。所述由seq id no:6的氨基酸序列组成的蛋白分泌因子可以是前胶原c-内肽酶增强物1(proco),并且可以与本发明中的proco分泌序列互换使用。所述由seq id no:7的氨基酸序列组成的蛋白分泌因子可以是巯基氧化酶(sulf),并且可以与本发明中的sulf分泌序列互换使用。所述由seq id no:8的氨基酸序列组成的蛋白分泌因子可以是脂蛋白脂肪酶(lip),并且可以与本发明中的lip分泌序列互换使用。所述由seq id no:9的氨基酸序列组成的蛋白分泌因子可以是巢蛋白-1(nid),并且可以与本发明中的nid分泌序列互换使用。所述由seq id no:10的氨基酸序列组成的蛋白分泌因子可以是蛋白质二硫键异构酶(pro),并且可以与本发明中的pro分泌序列互换使用。
[0026]
所述编码由seq id no:1的氨基酸序列组成的组织蛋白酶b信号肽的核酸序列可以是seq id no:11的多核苷酸序列,所述编码由seq id no:2的氨基酸序列组成的c-c基序趋化因子信号肽的核酸序列可以是seq id no:12的多核苷酸序列,并且所述编码由seq id no:3的氨基酸序列组成的核连蛋白-2信号肽的核酸序列可以是seq id no:13的多核苷酸序列。
[0027]
此外,所述编码由seq id no:4的氨基酸序列组成的丛生蛋白信号肽的核酸序列可以是seq id no:14的多核苷酸序列,所述编码由seq id no:5的氨基酸序列组成的色素上皮衍生因子(pig)信号肽的核酸序列可以是seq id no:15的多核苷酸序列,所述编码由seq id no:6的氨基酸序列组成的前胶原c-内肽酶增强物1(proco)信号肽的核酸序列可以是seq id no:16的多核苷酸序列,所述编码由seq id no:7的氨基酸序列组成的巯基氧化酶(sulf)信号肽的核酸序列可以是seq id no:17的多核苷酸序列,所述编码由seq id no:8的氨基酸序列组成的脂蛋白脂肪酶(lip)信号肽的核酸序列可以是seq id no:18的多核苷酸序列,所述编码由seq id no:9的氨基酸序列组成的巢蛋白-1(nid)信号肽的核酸序列可以是seq id no:19的多核苷酸序列,并且所述编码由seq id no:10的氨基酸序列组成的蛋白质二硫键异构酶(pro)信号肽的核酸序列可以是seq id no:20的多核苷酸序列。
[0028]
尽管本发明的蛋白分泌因子被描述为“由特定氨基酸序列组成的分泌因子”,但显然只要所述分泌因子具有与由相应序列号的氨基酸序列组成的分泌因子相同或对应的活性,则它不排除可能通过所述氨基酸序列上游或下游的无意义序列添加而发生的突变、可能天然发生的突变或其沉默突变。即使存在所述序列添加或突变,它也落于本发明的范围之内。
[0029]
例如,只要与由所述多核苷酸组成的核酸分子相同或相应的分泌因子可以起到信号肽的作用,则与上述序列显示出85%或更高,特别地90%或更高,更特别地95%或更高,甚至更特别地98%或更高或甚至更特别地99%或更高的同源性和/或同一性的核酸序列也可以不受限制地包括在本发明中。此外,显然在所述序列的一部分中具有缺失、修饰、替换或添加的核酸序列也可以被包括在本发明的范围之内,只要所述核酸序列具有这种同源性即可。
[0030]
当在本文中使用时,术语“同源性”或“同一性”是指两个给定氨基酸序列或核酸序列之间的相关性程度,并且可以被表示为百分率。术语“同源性”和“同一性”通常可以彼此互换使用。
[0031]
保守多核苷酸或多肽序列的序列同源性或同一性可以通过标准的比对算法来确定,并且可以与由所使用的程序建立的默认空位惩罚一起使用。基本上,通常预期同源或同
一的序列在中等或高严紧条件下与所述序列全长的全部或至少约50%、60%、70%、80%或90%或更多杂交。还考虑了含有简并密码子而不是所述杂交多肽中的密码子的多核苷酸。
[0032]
任两个多核苷酸或多肽序列是否具有同源性、相似性或同一性,可以通过已知的计算机算法例如“fasta”程序(pearson等,(1988)[proc.natl.acad.sci.usa 85]:2444),使用默认参数来确定。或者,它可以通过needleman-wunsch算法(needleman和wunsch,1970,j.mol.biol.48:443-453)来确定,所述算法使用emboss软件包的needleman程序来进行(emboss:欧洲分子生物学开放软件套件(emboss:the european molecular biology open software suite),rice等,2000,trends genet.16:276-277)(优选为5.0.0版或随后的版本),也可以使用gcg程序包(devereux,j.等,nucleic acids research 12:387(1984))、blastp、blastn、fasta(atschul,s.f.等,j molec biol 215]:403(1990);《大型计算机指南》(guide to huge computers),martin j.bishop主编,academic press,san diego,1994和[carillo等,(1988)siam j applied math 48:1073)来确定。例如,同源性、相似性或同一性可以使用美国国家生物技术信息中心(national center for biotechnology information)(ncbi)的blast或clustalw来确定。
[0033]
多核苷酸或多肽的同源性、相似性或同一性可以通过使用例如gap计算机程序例如needleman等,(1970),j mol biol.48:443来比较序列信息,如smith和waterman,adv.appl.math(1981)2:482中所公开的来确定。概括来说,所述gap程序将同源性、相似性或同一性定义为通过用相似对齐的符号(即核苷酸或或氨基酸)的数目除以所述两个序列中较短者中符号的总数而获得的值。用于gap程序的默认参数可以包括(1)一元比较矩阵(含有对于同一者来说为1并且对于非同一者来说为0的值)和gribskov等,(1986),nucl.acids res.14:6745的加权比较矩阵,正如在schwartz和dayhoff主编的《蛋白质序列和结构图谱》(atlas of protein sequence and structure),national biomedical research foundation,pp.353-358(1979)中所公开的(或ednafull替代矩阵(ncbi nuc4.4的emboss版本));(2)每个空位3.0的罚分和每个空位中的每个符号额外的0.10罚分(或10的空位开放罚分和0.5的空位扩展罚分);和(3)对末端空位无罚分。因此,当在本文中使用时,术语“同源性”或“同一性”是指序列之间的相关性。
[0034]
本发明的另一方面提供了一种表达盒,其中编码由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子的核酸序列和编码靶蛋白的基因被可操作连接。
[0035]
本发明的“蛋白分泌因子”如上所述。
[0036]
当在本文中使用时,术语“靶蛋白”可以是指在宿主细胞中内源表达的蛋白质或由引入到其中的外源基因表达的蛋白质。对靶蛋白的类型没有特别限制,只要细胞外分泌效率通过本发明的信号肽序列得以提高即可。
[0037]
所述靶蛋白可以是抗体、抗体片段(fab或scfv)、融合蛋白、蛋白质支架、人生长激素、血清蛋白、免疫球蛋白、细胞因子、α-、β-或γ-干扰素、粒细胞-巨噬细胞集落刺激因子(gm-csf)、血小板衍生生长因子(pdgf)、磷脂酶活化蛋白(plap)、胰岛素、肿瘤坏死因子(tnf)、生长因子、激素、降钙素、降钙素基因相关肽(cgrp)、脑啡肽、生长调节素、促红细胞生成素、下丘脑释放因子、生长分化因子、细胞黏附蛋白、催乳素、绒毛膜促性腺激素、组织纤溶酶原激活物、生长激素释放肽(ghpr)、胸腺体液因子(thf)、天冬酰胺酶、精氨酸酶、精
氨酸脱氨酶、腺苷脱氨酶、过氧化物歧化酶、内毒素酶、过氧化氢酶、糜蛋白酶、脂肪酶、尿酸酶、腺苷二磷酸酶、酪氨酸酶、胆红素氧化酶、葡萄糖氧化酶、葡萄糖苷酶、半乳糖苷酶、葡萄糖脑苷脂酶或葡萄糖醛酸酶,并且具体来说,它可以是抗体的重链蛋白或轻链蛋白,但不限于此。
[0038]
当在本文中使用时,术语“可操作连接”是指上述基因序列、启动子序列和信号肽序列之间的功能联系,以启动和介导编码本技术的蛋白分泌因子的核酸序列和编码靶蛋白的基因的转录。可操作连接可以使用本领域中已知的基因重组技术来制备,位点特异性dna连接可以使用本领域中已知的连接酶来制备,但不限于此。
[0039]
当在本文中使用时,术语“表达盒”是指调控一个或多个基因及其表达的序列,例如包括各种不同的顺式作用转录调控元件的任何组合的核酸序列。本发明的表达盒还可以包括各种不同元件,例如本领域中公认的表达调控所必需的核酸序列如启动子和增强子,以及编码蛋白分泌因子和靶蛋白的核酸序列。调控基因的表达的序列,也就是说调控基因的转录及其转录产物的表达的序列,通常被称为“调控单元”。大多数调控单元位于靶基因的编码序列的上游,使得它可操作连接到所述编码序列。此外,表达盒可以包括3
′
非翻译区,其包括在3
′
端处的多腺苷酸化位点。
[0040]
本发明的表达盒可以是通过将编码由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子的核酸序列和编码靶蛋白的基因可操作连接,允许所述靶蛋白在宿主细胞中的细胞外分泌和表达的多核苷酸的组合。
[0041]
本发明的另一方面提供了一种表达盒,在其中将编码靶蛋白的基因可操作连接到编码由seq id no:11至seq id no:20的氨基酸序列组成的蛋白分泌因子的核酸序列。
[0042]
本发明的“蛋白分泌因子”、“靶蛋白”、“可操作连接”和“表达盒”如上所述。
[0043]
在本发明中,所述由seq id no:11的多核苷酸序列编码的蛋白分泌因子可以是组织蛋白酶b(cat),所述由seq id no:12的多核苷酸序列编码的蛋白分泌因子可以是c-c基序趋化因子(cc),所述由seq id no:13的多核苷酸序列编码的蛋白分泌因子可以是核连蛋白-2(nuc),所述由seq id no:14的多核苷酸序列编码的蛋白分泌因子可以是丛生蛋白(clus),所述由seq id no:15的多核苷酸序列编码的蛋白分泌因子可以是色素上皮衍生因子(pig),所述由seq id no:16的多核苷酸序列编码的蛋白分泌因子可以是前胶原c-内肽酶增强物1(proco),所述由seq id no:17的多核苷酸序列编码的蛋白分泌因子可以是巯基氧化酶(sulf),所述由seq id no:18的多核苷酸序列编码的蛋白分泌因子可以是脂蛋白脂肪酶(lip),所述由seq id no:19的多核苷酸序列编码的蛋白分泌因子可以是巢蛋白-1(nid),并且所述由seq id no:20的多核苷酸序列编码的蛋白分泌因子可以是蛋白质二硫键异构酶(pro)。
[0044]
本发明的另一方面提供了一种用于分泌靶蛋白的表达载体,所述表达载体包括表达盒,其中将编码由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子的核酸序列和编码靶蛋白的基因可操作连接。
[0045]
本发明的“蛋白分泌因子”、“靶蛋白”、“可操作连接”和“表达盒”如上所述。
[0046]
当在本文中使用时,术语“用于分泌靶蛋白的表达载体”是指一种表达载体,在其中将所述蛋白分泌因子和编码所述靶蛋白的基因可操作连接,以便当将所述载体引入到宿
主细胞中并在其中表达时,诱导所述靶蛋白的细胞外分泌。
[0047]
当在本文中使用时,术语“表达载体”通常是指作为载体的双链dna片段,编码靶蛋白的靶dna片段被插入到其中。可以不受限制地使用本领域中用于表达蛋白质的表达载体。一旦所述表达载体进入宿主细胞,所述表达载体可以独立于宿主染色体dna进行复制,并且可以表达插入的靶dna。为了提高转染的基因在宿主细胞中的表达水平,所述转染的基因必须被可操作连接到在所选的表达宿主细胞中运转的转录和翻译控制序列。
[0048]
对在本发明中使用的表达载体没有特别限制,只要它可以在宿主细胞中复制即可,并且可以使用本领域中已知的任何载体。惯常使用的载体的实例可以包括天然或重组质粒、粘粒、病毒和噬菌体。例如,作为噬菌体载体或粘粒载体,可以使用pwe15、m13、λmbl3、λmbl4、λ
ⅸ
ii、λashii、λapii、λt10、λt11、charon4a和charon21a等,而作为质粒载体,可以使用基于pbr、puc、pbluescriptii、pgem、ptz、pcl、pet等的载体。具体来说,所述载体可以是基于ptz的载体,但不限于此。
[0049]
在本发明的一个特定实施方式中,用于分泌靶蛋白的表达载体通过在ptz-d1g1载体(包括韩国专利号10-1038126的启动子的变体)的基础上,将编码由seq id no:1、seq id no:2或seq id no:3的氨基酸序列组成的蛋白分泌因子的核酸序列与编码靶蛋白的基因可操作连接来制备(实施例4)。
[0050]
所述表达载体还可以包括编码由seq id no:6、seq id no:7、seq id no:8、seq id no:9或seq id no:10的氨基酸序列组成的蛋白分泌因子的核酸序列。
[0051]
本发明的另一个方面提供了一种转化细胞,其中将所述表达载体引入到宿主细胞中。
[0052]
本发明的“表达载体”如上所述。
[0053]
当在本文中使用时,术语“转化”是指将包括编码靶多肽的多核苷酸的载体引入到宿主细胞中的过程,从而允许所述多核苷酸编码的蛋白质在所述宿主细胞中表达。
[0054]
只要所述转化的多核苷酸可以在宿主细胞中表达,则它是被插入到宿主细胞的染色体中并位于其中还是位于染色体外并不重要,两种情况都可以包括。此外,所述多核苷酸包括编码靶多肽的dna和rna。所述多核苷酸可以以任何形式引入,只要它可以被引入到宿主细胞中并在其中表达即可。例如,所述多核苷酸可以以表达盒的形式引入到宿主细胞中,所述表达盒是包括自身表达所必需的所有元件的基因构建物。所述表达盒常规上可以包括与所述多核苷酸可操作连接的启动子、转录终止信号、核糖体结合结构域和翻译终止信号。
[0055]
转化本发明的载体的方法包括将核酸引入到细胞中的任何方法,并且可以通过根据宿主细胞来选择本领域中已知的适合的标准技术来进行。例如,转化可以通过粒子轰击、电穿孔、磷酸钙(capo4)沉淀、氯化钙(cacl2)沉淀、微注射、聚乙二醇(peg)技术、deae-葡聚糖技术、阳离子脂质体技术、乙酸锂-dmso技术来进行,但方法不限于此。
[0056]
当在本文中使用时,术语“宿主细胞”是指具有本发明的蛋白分泌因子的活性的核酸分子被引入到其中并且可以在其中充当信号肽的真核细胞。所述宿主细胞可以包括例如公知的真核宿主,例如酵母、昆虫细胞如草地贪夜蛾(spodoptera frupperda)和动物细胞例如cho、cos1、cos7、bsc1、bsc40和bmt10,但不限于此。
[0057]
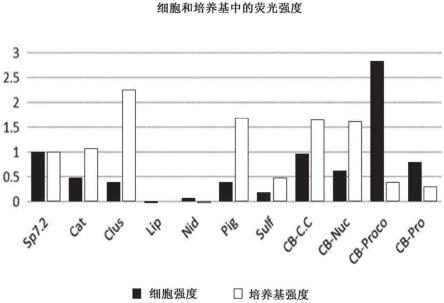
在本发明中,所述宿主细胞的实例可以是动物宿主细胞,并且具体来说,它可以是中华仓鼠卵巢细胞(cho细胞),但不限于此。
[0058]
在本发明的一个特定实施方式中,将在重组蛋白的生产中广泛使用的中华仓鼠卵巢(cho)细胞用作宿主细胞(实施例4)。
[0059]
当在本文中使用时,术语“转化体”是指转化的动物细胞,其中包括由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的信号肽和靶蛋白的表达载体被引入到作为宿主细胞的cho细胞中。
[0060]
在本发明的一个特定实施方式中,证实了所述转化体提高了作为靶蛋白的派姆单抗(即抗体)的轻链和重链的表达水平(实施例4)。
[0061]
本发明的另一方面提供了一种生产靶蛋白的方法,所述方法包括:
[0062]
i)培养包含用于分泌靶蛋白的表达载体的转化细胞,所述表达载体包括表达盒,其中编码由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子的核酸序列和编码靶蛋白的基因被可操作连接;和
[0063]
ii)从培养的细胞的培养基或培养上清液回收所述靶蛋白。
[0064]
本发明的“蛋白分泌因子”、“靶蛋白”、“可操作连接”、“表达盒”、“用于分泌靶蛋白的表达载体”、“宿主细胞”和“转化体”如上所述。
[0065]
当在本文中使用时,术语“培养”是指将转化细胞在适合的人工控制的环境条件下生长的过程。在本发明中,所述使用cho细胞作为宿主细胞生产靶蛋白的方法可以使用本领域中广泛已知的方法来进行。具体来说,所述培养可以通过分批过程、补料分批或重复补料分批过程以连续的方式进行,但不限于此。
[0066]
用于培养的培养基应该以适合的方式满足特定细胞株的需求。可以在本发明中使用的碳源可以包括糖和碳水化合物例如葡萄糖、蔗糖、乳糖、果糖、麦芽糖、淀粉和纤维素,油类和脂肪例如大豆油、葵花籽油、蓖麻油和椰子油,脂肪酸例如棕榈酸、硬脂酸和亚油酸,醇类例如乙醇,以及有机酸例如葡萄糖酸、乙酸和丙酮酸,但不限于此。这些物质可以单独或混合使用。
[0067]
可以在本发明中使用的氮源可以包括蛋白胨、酵母提取物、肉提取物、麦芽提取物、玉米浆、脱脂豆饼和尿素或无机化合物,例如硫酸铵、氯化铵、磷酸铵、碳酸铵和硝酸铵,但不限于此。这些氮源也可以单独或混合使用。
[0068]
可以在本发明中使用的磷源可以包括磷酸二氢钾或磷酸氢二钾或相应的含钠盐,但不限于此。此外,培养基可以含有生长所需的金属盐,例如硫酸镁或硫酸铁。最后,除了上述物质之外,还可以使用生长必需物质例如氨基酸和维生素。此外,在培养基中可以使用适合的前体。这些物质可以在培养期间以分批或连续方式适当地添加到培养基中。
[0069]
可以以适合的方式向培养基添加碱性化合物例如氢氧化钠、氢氧化钾或氨水或酸性化合物例如磷酸或硫酸,以调节培养基的ph。此外,可以使用消泡剂例如脂肪酸聚乙二醇酯来抑制泡沫的形成。为了将培养基维持在有氧状态下,可以将氧气或含氧气体注入到培养基中。培养基的温度通常可以是20℃至45℃,优选为25℃至40℃,但可以根据条件改变并且不限于此。
[0070]
在本发明的一个特定实施方式中,将重组表达载体(即pcb-sp7.2-pem、pcb-clus-pem、pcb-pig-pem和pcb-cc-pem)引入到cho宿主细胞(expicho-s
tm
细胞)中,并在30ml expicho表达培养基(cho表达培养基)中通过补料分批培养方法培养12天(实施例4)。
[0071]
本发明的用于生产靶蛋白的方法可以包括从培养基回收所述靶蛋白的步骤。当在
本文中使用时,术语“回收”是从培养基获得靶蛋白的过程,并且可以使用本领域中已知的方法例如离心、过滤、阴离子交换层析、结晶、hplc等来进行,但方法不限于此。
[0072]
所述回收步骤可以包括纯化过程,并且本领域技术人员可以根据需要在各种不同的已知纯化过程中选择并使用。例如,可以通过常规的层析方法例如免疫亲和层析、受体亲和层析、疏水相互作用层析、凝集素亲和层析、尺寸排阻层析、阳离子或阴离子交换层析、高效液相层析(hplc)和反相hplc,将宿主细胞与培养基或宿主细胞的培养上清液分离。此外,当所需蛋白质是带有特定标签、标记物或螯合组成部分的融合蛋白时,它可以通过特异性结合配偶体或药物来纯化。所述纯化的蛋白质可以被切割成所需蛋白质区域,例如除去所述分泌因子,或者它可以保持原样。包括额外氨基酸的所需形式的蛋白质可以通过在切割过程中切割所述融合蛋白来生产。
[0073]
本发明的由seq id no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5的氨基酸序列组成的蛋白分泌因子可以是在所述靶蛋白的n-端切割位点处准确切割的分泌因子。
[0074]
所述信号肽位于待生产的重组蛋白的n-端区域处,并且当所述靶蛋白被转运时,信号肽被信号肽酶降解。然而,由于错误切割问题,现有的蛋白分泌因子常常可能降低靶蛋白的质量。所述“错误切割”是指信号肽未在正确位置处完全降解,并且信号肽序列部分保留在靶蛋白的n-端处的现象。
[0075]
在本发明的一个特定实施方式中,使用纯化的靶蛋白,通过q-tof ms质谱仪确认了蛋白分泌因子(信号肽)的切割。结果,证实了在预测的切割位点处观察到了100%切割。
[0076]
因此,包含本发明的蛋白分泌因子(信号肽)的表达载体通过重组蛋白的高效表达和分泌提高了靶蛋白的生产率,并且可以是解决错误切割问题的强大遗传工具。
[0077]
[有利效果]
[0078]
本发明的蛋白分泌因子即信号肽可以通过高水平表达显著提高重组蛋白的生产率,并且预计可以用作强大的遗传工具,其可以通过在切割位点处100%切割来解决常规信号肽的错误切割问题。
附图说明
[0079]
图1是使用signalp4.1预测信号肽的图。
[0080]
图2是通过瞬时表达确认信号肽-mcherry的表达水平的图。
[0081]
图3是示出了用于位点特异性整合的载体图谱的图。
[0082]
图4是比较了在位点特异性整合细胞中mcherry的表达水平的图。
[0083]
图5是示出了质量数据的图,证实了与sp7.2和clus融合的抗pd-1抗体的切割。
具体实施方式
[0084]
在下文中,将通过实施例更详细地描述本发明。然而,提供这些实施例仅仅是出于说明的目的,而本发明的范围不打算限于这些实施例或受这些实施例限制。
[0085]
实施例1.源自于cho细胞的新的信号肽序列的制备
[0086]
1-1.cho hcp质量分析
[0087]
将四种类型(adh、bsa、pho和enl)的masspreptm蛋白质消化物标准品添加到如下
所述用胰蛋白酶处理的cho细胞培养基(dxb11)。在所述四种类型的masspreptm蛋白质消化物标准品中,pho被用作内标,用于计算每种宿主细胞蛋白(hcp)的浓度。使用2d lc(高ph rp/低ph rp)-q-tof(udmse)方法分析每个样品的宿主细胞蛋白(hcp)。
[0088]
对于每个级分来说,通过直接进样到q-tof ms中的2d柱中来获得ms数据(udmse)。使用proteinlynx全球服务器(plgs,ver.3.0.2)软件将以上述方式获得的10个级分的ms数据(udmse)合并成一个数据。然后,使用每个样品的合并数据和中华仓鼠蛋白质数据库来鉴定hcp,并使用pho作为内标计算每种hcp的浓度。
[0089]
1-2.从cho hcp数据选择信号肽
[0090]
将蛋白质以高浓度的顺序排列,并从cho基因组数据库(http://chogenome.org)确认每种蛋白质的氨基酸序列。将由此获得的氨基酸序列输入到signalp4.1服务器(http://www.cbs.dtu.dk/services/signalp/)中,以预测分泌蛋白和信号肽序列的存在(表1、图1和表4)。
[0091]
[表1]
[0092]
通过signalp4.1预测的hcp分泌蛋白
[0093]
[0094][0095]
实施例2.通过瞬时表达选择cho衍生的高效信号肽
[0096]
2-1.用于瞬时表达的重组蛋白表达载体的制备
[0097]
为了确认在实施例1中选择的10种信号肽是否可以用作通用分泌因子,选择mcherry(pmcherry载体,clontech,632522)蛋白作为靶蛋白。
[0098]
编码mcherry蛋白的基因的多核苷酸序列示出在表2中。
[0099]
[表2]
[0100]
[0101][0102]
在编码mcherry蛋白的基因的基础上,使用从cho hcp质量数据鉴定到的信号肽序列和含有kpni/xhoi的引物进行pcr,并构建通过10种信号肽序列表达的mcherry。
[0103]
当所述信号肽的长度长时,将引物分成两个,并进行两次pcr。将含有10种信号肽序列的mcherry pcr产物用kpni和xhoi切割,然后克隆到pcdna3.1( )(invitrogen,目录号v790-20)中以构建表达载体。
[0104]
另外,为了用作阳性对照,以相同的方式制备了与作为已知分泌因子的sp7.2信号肽(韩国专利公开出版物10-2015-0125402a)融合的mcherry蛋白表达载体。所述sp7.2信号肽的序列示出在表3中。
[0105]
[表3]
[0106][0107][0108]
[表4]
[0109]
[0110]
[0111]
[0112]
[0113]
[0114]
[0115]
[0116]
[0117][0118]
2-2.瞬时表达
[0119]
按照cho-s细胞系amaxa 4d-核转染剂方案,将由10种信号肽表达的每种mcherry表达载体转染(1ml)。然后,在第2和第6天,测量细胞内荧光和从培养基分泌的荧光蛋白的荧光值(图3)。
[0120]
在细胞内荧光的情况下,使用facs(accuri)来测量以直方图表示的比阴性对照(空载体,pmaxgfp)更高的部分的平均值。
[0121]
在分泌到培养基中的荧光蛋白的荧光值的情况下,在第2和第6天取样100μl,然后离心以便只获得上清液,并使用多波长读板器在587/610nm处测量荧光。
[0122]
确认了具有在培养基中测量到的高荧光值的信号肽是cat、cc、nuc、clus和pig。此
外,选择显示出比阳性对照sp7.2(sp7.2被用作阳性对照)更高的表达的四种分泌因子(clus、pig、nuc和cc)和一种在细胞中具有高荧光值的信号肽(proco)作为阴性对照。
[0123]
实施例3.通过位点特异性整合进行的表达的比较
[0124]
3-1.用于位点特异性整合的表达载体的构建
[0125]
将包括在实施例2中选择的5种信号肽(clus、pig、nuc、cc和proco)和对照sp7.2的mcherry序列一致地插入到cho基因组的特定位点中,以定量比较表达水平(图4和5)。
[0126]
所述插入位点被设定在hprt位点处,同源臂序列和sgrna序列参考j.s lee等,2015,“由crispr/cas9和同源性指导的dna修复途径介导的cho细胞中的位点特异性整合”(site-specific integration in cho cells mediated by crispr/cas9 and homology-directed dna repair pathway),sci.rep.,5来设计。
[0127]
在5'同源臂的情况下,使用含有bg1ⅱ和nrui酶位点的引物以及作为模板的cho-s基因组进行pcr。然后,将它克隆到用bg1ii/nrui消化的pcdna3.1( )载体中。
[0128]
在3'同源臂的情况下,使用含有sali位点的每个引物以及作为模板的cho-s基因组进行pcr,然后与用5'同源臂插入的载体一起进行sali单切,并将它克隆到neor基因的下游中(pcdna3.1_hprt)。
[0129]
为了确认只有那些已经历同源重组的片段被插入到基因组中,在5'同源臂的上游区域中构建了cmy-gfp-bhg pa片段并插入到spei和bg1ⅱ中(pcdna3.1_g_hprt)用于双重选择。
[0130]
在gfp片段的情况下,首先使用ncoi/xbai将它插入到pcdna3.1( )载体的mcs中,然后使用含有spei和bg1ii限制性位点的引物进行pcr。然后,使用bg1ii位点将spei插入到含有同源区的载体(pcdna_hprt)中。
[0131]
使用完成的pcdna3.1_g_hprt载体,用kpni和xhoi切下含有信号肽序列的mcherry基因序列,并将它插入到mcs区中。
[0132]
结果,构建了含有表达盒的基于pcdna3.1的表达载体,所述表达盒采取cmv-egfp-pa-5'hprt同源臂-cmv-信号肽候选物-mcherry-bgh pa-neor选择标记盒-3'hprt同源臂的形式。
[0133]
3-2.位点特异性整合
[0134]
使用crispr-cas9进行敲入,以便将6种类型的用于在hprt位点中进行位点特异性整合的载体插入到cho-s基因组中。将240ng sgrna、1,250ng cas9蛋白和1μg供体载体与核转染溶液独立混合,以制备50μl混合物。
[0135]
首先将1x106个cho-s细胞溶解在50μl核转染试剂中,然后与前面制备的混合物混合,然后对最终的100μl混合物进行电穿孔。
[0136]
在进行电穿孔后,将所述混合物与0.5ml培养基混合,添加到2.5ml培养基,并在6孔板中在36.5℃和5%co2下培养。
[0137]
2天后,在含有zeneticin(0.5mg/l)的cd cho培养基中进行选择,然后将细胞传代培养直至恢复90%的活力。
[0138]
在恢复90%的活力后,将4ml细胞一式两份在6孔板中以3x105个细胞/ml的浓度进行培养,并每2至3天测量vi-cell和培养基的荧光值(587nm/610nm)(图5)。
[0139]
结果,证实了与对照sp7.2相比,cc、clus和pig分泌肽显示出更高的表达。
[0140]
实施例4.抗pd-1抗体的表达和质量分析
[0141]
4-1.用于生产抗pd-1抗体的表达载体的制备
[0142]
在通过位点特异性整合比较了信号肽的表达能力后,表达了与包括显示出高表达的cc、clus和pig在内的4种类型的信号肽(cc、pig、clus和sp7.2)融合的抗pd-1抗体。使用派姆单抗抗体序列作为靶蛋白。
[0143]
合成了对应于轻链和重链的氨基酸序列的dna序列,随后通过重叠pcr产生了与每个信号肽序列融合的序列。
[0144]
在轻链的情况下,将氨基酸序列用bamhi和xhoi限制,并且在重链的情况下,将氨基酸序列用asci和noti限制,然后将抗体插入到ptz-d1g1载体中,所述载体是pcdna3.1( )的变体(包括韩国专利号10-1038126b1的启动子)。
[0145]
pcb_sp7.2_pem
[0146]
'(n-端)-[bamhi限制性位点-信号肽(seq id no:33)-pem轻链(seq id no:58)-xhoi限制性位点]-(c-端)'/'(n-端)-[asci限制性位点-信号肽(seq id no:33)-pem重链(seq id no:59)-noti限制性位点]-(c-端)'
[0147]
pcb_clus_pem
[0148]
'(n-端)-[bamhi限制性位点-信号肽(seq id no:4)-pem轻链(seq id no:58)-xhoi限制性位点]-(c-端)'/'(n-端)-[asci限制性位点-信号肽(seq id no:4)-pem重链(seq id no:59)-noti限制性位点]-(c-端)'
[0149]
pcb_cc_pem
[0150]
'(n-端)-[bamhi限制性位点-信号肽(seq id no:2)-pem轻链(seq id no:58)-xhoi限制性位点]-(c-端)'/'(n-端)-[asci限制性位点-信号肽(seq id no:2)-pem重链(seq id no:59)-noti限制性位点]-(c-端)'
[0151]
pcb_pig_pem
[0152]
'(n-端)-[bamhi限制性位点-信号肽(seq id no:5)-pem轻链(seq id no:58)-xhoi限制性位点]-(c-端)'/'(n-端)-[asci限制性位点-信号肽(seq id no:5)-pem重链(seq id no:59)-noti限制性位点]-(c-端)'
[0153]
4-2.抗pd1抗体的表达
[0154]
将制备的重组表达载体pcb-sp7.2-pem、pcb-clus-pem、pcb-pig-pem和pcb-cc-pem引入到expicho-s
tm
细胞(thermo fisher scientific)中,并在expicho表达培养基(thermo fisher scientific;30ml)中培养12天(补料分批培养;第1天和第5天补料),以表达融合多肽(即派姆单抗)。
[0155]
4-3.抗pd1抗体的纯化和质量分析
[0156]
通过蛋白a对通过重组载体的表达生产的融合多肽进行纯化。具体来说,将回收的培养液用0.22μm滤器过滤,然后将装填有蛋白a树脂的柱(hitrap mss,ge healthcare,11-0034-93)安装在akta
tm avant25(ge healthcare life sciences)上,并使pbs缓冲液流过以平衡柱。
[0157]
在将过滤的培养液进样到柱中后,使pbs缓冲液再次流过以清洗柱。在柱的清洗完成后,将洗脱缓冲液(柠檬酸盐缓冲液,ph 3.5)流过柱以洗脱靶蛋白。使用amicon ultra过滤装置(mwco 30k,merck)和离心机将洗脱液浓缩。在进行浓缩后,使用pbs进行缓冲液交
换。
[0158]
所述融合多肽的定量分析通过使用uv分光光度计(g113a,agilent technologies)测量280nm和340nm处的吸光值,并使用下述计算公式来进行。每种材料的消光系数是使用氨基酸序列计算的理论值(1.404)。
[0159][0160]
(*消光系数(0.1%):它是在假设蛋白质浓度为0.1%(1g/l),并且一级序列上的所有半胱氨酸均被氧化以形成二硫键的情况下,在280nm处的理论吸光值。通过protparam工具(https://web.expasy.org/protparam/)计算)
[0161]
使用q-tof ms,将所述纯化的靶蛋白用于确认在蛋白质的n-端处信号肽的错误切割的存在(图6)。在稀释至1mg/ml的浓度后,将所述蛋白质用pngasef处理,然后用6m胍和dtt处理,然后载样到q-tof ms上(rmm-mt-001:acquity uplc q-tof synapt g2(waters))。
[0162]
结果,确认了在预测的切割位点处观察到100%切割。
[0163]
基于所述结果,作为本发明的cho细胞衍生的蛋白分泌因子的信号肽通过提高重组蛋白的表达水平来提高生产率,并通过经质量分析确认在预测的切割位点处观察到100%切割,暗示了本发明的信号肽可能是强大的遗传工具,其可以解决作为现有蛋白分泌因子的问题的错误切割。
[0164]
尽管已参考特定说明性实施方式描述了本发明,但是本发明所属领域的技术人员会理解,在不背离本发明的技术精神或本质特征的情况下,本发明可以以其他特定形式体现。因此,上述实施方式在所有方面均被认为是说明性而不是限制性的。此外,本发明的范围由权利要求书而不是具体实施方式来定义,并且应当理解,源自于本发明的含义和范围的所有修改或变化及其等同物均包含在权利要求书的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。